为了提高数据流水线的性能,您可以将某些转换操作推送到 BigQuery(而非 Apache Spark)。转换推送是一项设置,可让 Cloud Data Fusion 数据流水线中的操作作为执行引擎推送到 BigQuery。因此,系统会将操作及其数据传输到 BigQuery,并在 BigQuery 中执行操作。
转换推送可提升包含多个复杂 JOIN 运算或其他受支持转换的流水线的性能。在 BigQuery 中执行某些转换的速度可能比在 Spark 中执行更快。
不受支持的转换和所有预览转换均在 Spark 中执行。
支持的转换
Cloud Data Fusion 6.5.0 版及更高版本提供了转换推送功能,但以下部分转换仅在较高版本中受支持。
JOIN 次操作
Cloud Data Fusion 6.5.0 版及更高版本中的
JOIN操作支持转换推送。支持基本(按键)和高级
JOIN操作。联接必须有且仅有两个输入阶段,才能在 BigQuery 中执行。
配置为将一个或多个输入加载到内存中的联接在 Spark 中执行,而不是在 BigQuery 中执行,但以下情况除外:
- 联接的任何输入是否已向下推送。
- 如果您将联接配置为在 SQL 引擎中执行(请参阅要强制执行的阶段选项)。
BigQuery 接收器
Cloud Data Fusion 6.7.0 及更高版本中的 BigQuery Sink 支持转换推送。
当 BigQuery Sink 紧随在 BigQuery 中执行的阶段时,将记录写入 BigQuery 的操作会直接在 BigQuery 中执行。
如需提高此接收器的性能,您需要满足以下条件:
- 服务账号必须有权在 BigQuery Sink 使用的相应数据集中创建和更新表。
- 用于转换推送和 BigQuery Sink 的数据集必须存储在同一位置。
- 操作必须是以下其中一项:
Insert(不支持Truncate Table选项)UpdateUpsert
GROUP BY 汇总
Cloud Data Fusion 6.7.0 及更高版本中的 GROUP BY 汇总支持转换推送。
BigQuery 中的 GROUP BY 汇总适用于以下操作:
AvgCollect List(系统会从输出数组中移除 null 值)Collect Set(系统会从输出数组中移除 null 值)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
在以下情况下,BigQuery 中会执行 GROUP BY 汇总:
- 它紧随已推送的阶段。
- 您将其配置为在 SQL 引擎中执行(请参阅要强制执行的阶段选项)。
删除重复的汇总
转换推送功能可用于 Cloud Data Fusion 6.7.0 及更高版本中的去重汇总,适用于以下操作:
- 未指定过滤操作
ANY(所需字段的非 null 值)MIN(指定字段的最小值)MAX(指定字段的最大值)
不支持以下操作:
FIRSTLAST
在以下情况下,SQL 引擎中会执行去重聚合:
- 它紧随已推送的阶段。
- 您将其配置为在 SQL 引擎中执行(请参阅要强制执行的阶段选项)。
BigQuery 来源下推
Cloud Data Fusion 6.8.0 及更高版本提供了 BigQuery 源代码推送功能。
当 BigQuery 来源紧随与 BigQuery 推断兼容的阶段时,流水线可以在 BigQuery 中执行所有兼容的阶段。
Cloud Data Fusion 会复制在 BigQuery 中执行流水线所需的记录。
使用 BigQuery 源代码下推时,系统会保留表分区和分片属性,以便您使用这些属性优化进一步的操作(例如联接)。
其他要求
如需使用 BigQuery 源代码下推功能,必须满足以下要求:
为 BigQuery 转换下推配置的服务账号必须拥有读取 BigQuery 来源数据集中表的权限。
BigQuery 来源中使用的“数据集”和为转换下推配置的数据集必须存储在同一位置。
窗口汇总
转换推送功能适用于 Cloud Data Fusion 6.9 及更高版本中的窗口汇总。BigQuery 中的窗口聚合适用于以下操作:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
在以下情况下,BigQuery 中会执行窗口汇总:
- 它紧随已推送的阶段。
- 您将其配置为在 SQL Engine 中执行(请参阅要强制推送的阶段选项)。
Wrangler 过滤器推送
Cloud Data Fusion 6.9 及更高版本提供了 Wrangler 过滤器推送功能。
使用 Wrangler 插件时,您可以推送过滤条件(称为 Precondition 操作),以便在 BigQuery(而非 Spark)中执行。
仅在 Preconditions(也于版本 6.9 中发布)的 SQL 模式下支持过滤器下推。在此模式下,该插件接受 ANSI 标准 SQL 中的前提条件表达式。
如果使用 SQL 模式来设置前提条件,则 Wrangler 插件会停用指令和用户定义的指令,因为 SQL 模式不支持前提条件。
启用转换推送后,具有多个输入的 Wrangler 插件不支持前提条件的 SQL 模式。如果与多个输入搭配使用,则系统会在 Spark 中执行包含 SQL 过滤条件的此 Wrangler 阶段。
在以下情况下,BigQuery 会执行过滤器:
- 它紧随已推送的阶段。
- 您将其配置为在 SQL Engine 中执行(请参阅要强制推送的阶段选项)。
指标
如需详细了解 Cloud Data Fusion 为在 BigQuery 中执行的流水线部分提供的指标,请参阅 BigQuery 推送式流水线指标。
何时使用转换推送
在 BigQuery 中执行转换涉及以下步骤:
- 将记录写入 BigQuery,以便处理流水线中的受支持阶段。
- 在 BigQuery 中执行受支持的阶段。
- 在执行受支持的转换后从 BigQuery 读取记录,除非后跟 BigQuery Sink。
根据数据集的大小,可能会产生大量的网络开销,这可能会对启用转换推送的总体流水线执行时间产生负面影响。
由于网络开销,我们建议在以下情况下进行转换推送:
- 按顺序执行多项受支持的操作(无需在阶段之间执行步骤)。
- 与 Spark 相比,BigQuery 执行转换所带来的性能提升大于数据传输到 BigQuery 和可能从 BigQuery 传输出去的延迟时间。
工作原理
运行使用转换推送功能的流水线时,Cloud Data Fusion 会在 BigQuery 中执行受支持的转换阶段。流水线中的所有其他阶段均在 Spark 中执行。
执行转换时:
Cloud Data Fusion 会将输入数据集加载到 BigQuery(通过将记录写入 Cloud Storage,然后执行 BigQuery 加载作业)。
然后,使用 SQL 语句将
JOIN操作和受支持的转换作为 BigQuery 作业执行。如果在作业执行后需要进一步处理,可以将记录从 BigQuery 导出到 Spark。不过,如果启用了尝试直接复制到 BigQuery 接收器选项,并且 BigQuery 接收器位于在 BigQuery 中执行的阶段之后,系统会直接将记录写入目标 BigQuery 接收器表。
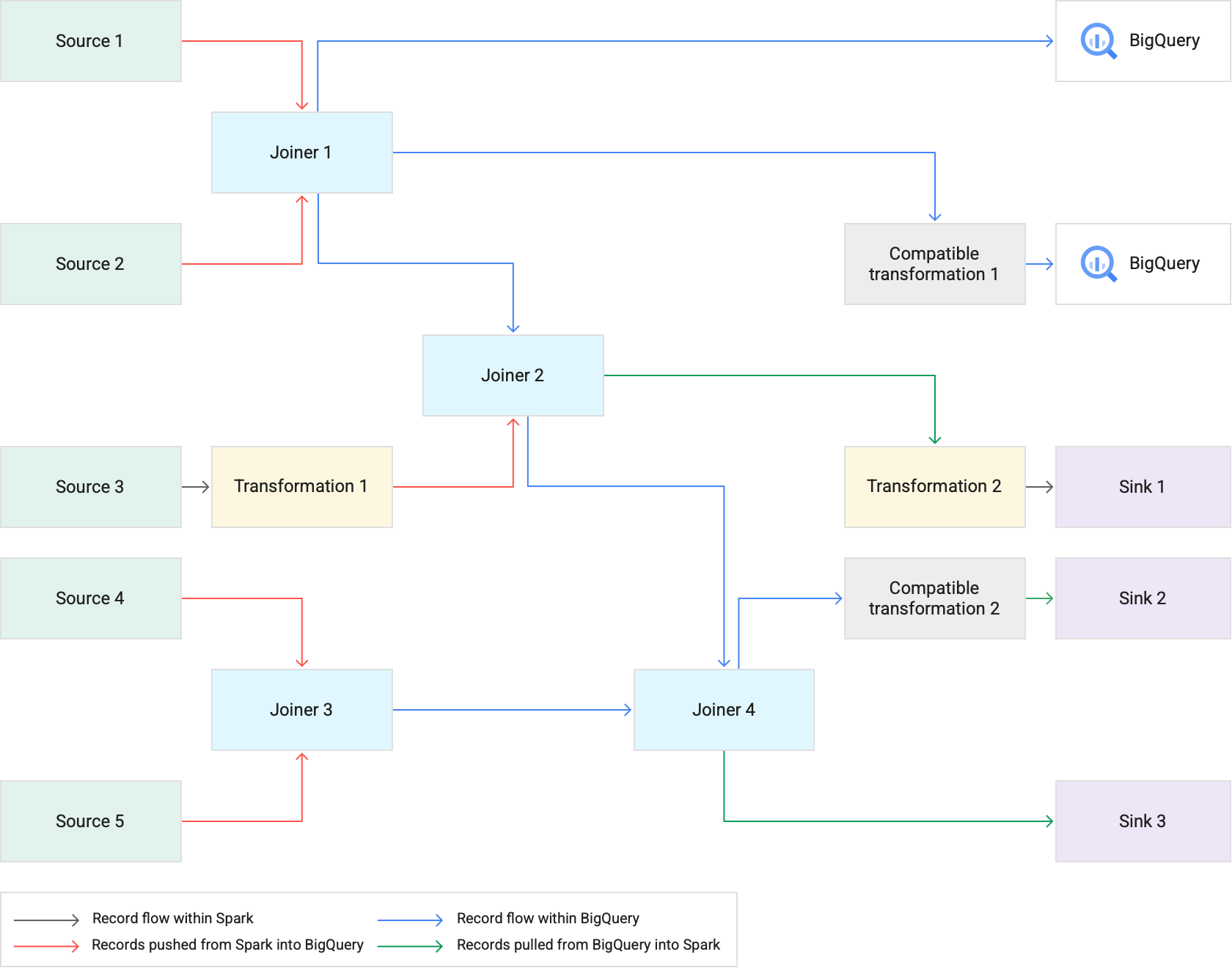
下图显示了转换推送如何在 BigQuery(而非 Spark)中执行受支持的转换。
最佳做法
调整集群和执行程序大小
如需优化流水线中的资源管理,请执行以下操作:
为工作负载使用适当数量的集群工作器(节点)。换句话说,通过充分利用实例的可用 CPU 和内存,充分利用供应的 Dataproc 集群,同时受益于 BigQuery 执行大型作业的速度。
使用自动扩缩集群来提高流水线的并行性。
在流水线执行期间从 BigQuery 推送或拉取记录的调整资源配置。
建议:尝试增加执行程序资源的 CPU 核心数(不超过工作器节点使用的 CPU 核心数)。执行程序会在数据进出 BigQuery 的序列化和反序列化步骤期间优化 CPU 使用率。如需了解详情,请参阅调整集群大小。
在 BigQuery 中执行转换的好处在于,您的流水线可以在较小的 Dataproc 集群上运行。如果联接是流水线中资源最多的操作,则您可以尝试使用较小的集群大小,因为繁重的 JOIN 操作现在会在 BigQuery 中执行),从而降低总体计算费用。
使用 BigQuery Storage Read API 更快地检索数据
BigQuery 执行转换后,您的流水线可能还有其他阶段需要在 Spark 中执行。在 Cloud Data Fusion 6.7.0 及更高版本中,转换推送支持 BigQuery Storage Read API,这有助于缩短延迟时间,并加快对 Spark 的读取操作。这可以缩短整个流水线的执行时间。
该 API 会并行读取记录,因此我们建议您相应地调整执行器大小。如果在 BigQuery 中执行资源密集型操作,请减少为执行器分配的内存,以提高流水线运行时的并行性(请参阅调整集群和执行器大小)。
BigQuery Storage Read API 默认处于停用状态。您可以在安装了 Scala 2.12 的执行环境(包括 Dataproc 2.0 和 Dataproc 1.5)中启用它。
考虑数据集大小
在 JOIN 操作中考虑数据集的大小。对于生成大量输出记录的 JOIN 操作(例如,类似于交叉 JOIN 操作的操作),生成的数据集大小可能大于输入数据集。此外,请考虑在整体流水线性能发生这些记录进行额外的 Spark 处理(例如转换或接收器)时,将这些记录拉取回 Spark 的开销。
缓解偏差数据
对严重偏斜数据执行 JOIN 操作可能会导致 BigQuery 作业超出资源利用率限制,从而导致 JOIN 操作失败。为避免这种情况,请前往 Joiner 插件设置,然后在偏差输入阶段字段中识别偏差输入。这样,Cloud Data Fusion 就可以以一种方式排列输入,从而降低 BigQuery 语句超出限制的风险。