デフォルトでは、Cloud Data Fusion はお客様のコンテンツを保存時に暗号化します。暗号化は Cloud Data Fusion が行うため、ユーザー側での作業は必要ありません。このオプションは、Google のデフォルトの暗号化と呼ばれます。
暗号鍵を管理する場合は、Cloud KMS の顧客管理の暗号鍵(CMEK)を、Cloud Data Fusion などの CMEK 統合サービスで使用できます。Cloud KMS 鍵を使用すると、保護レベル、ロケーション、ローテーション スケジュール、使用とアクセスの権限、暗号境界を制御できます。 Cloud KMS を使用すると、鍵の使用状況を追跡すること、監査ログを表示すること、鍵のライフサイクルを管理することが可能です。 データを保護する対称鍵暗号鍵(KEK)は Google が所有して管理するのではなく、ユーザーが Cloud KMS でこれらの鍵を制御および管理します。
CMEK を使用してリソースを設定した後は、Cloud Data Fusion リソースへのアクセスは、Google のデフォルトの暗号化を使用する場合と同様です。暗号化オプションの詳細については、顧客管理の暗号鍵(CMEK)をご覧ください。
Cloud Data Fusion は、Instance リソースの Cloud KMS 鍵の使用状況の追跡をサポートしています。
CMEK によって、テナント プロジェクトの Google 内部リソースに書き込まれるデータと、Cloud Data Fusion パイプラインによって書き込まれるデータを管理できます。たとえば、次のようなものがあります。
- パイプライン ログとメタデータ
- Dataproc クラスタ メタデータ
- さまざまな Cloud Storage、BigQuery、Pub/Sub、Spanner のデータシンクやアクション、ソース
Cloud Data Fusion のリソース
CMEK をサポートする Cloud Data Fusion プラグインのリストについては、サポートされているプラグインをご覧ください。
Cloud Data Fusion は、Dataproc クラスタの CMEK をサポートしています。Cloud Data Fusion は、パイプラインで使用する一時的な Dataproc クラスタを作成し、パイプラインが完了するとクラスタを削除します。CMEK は、以下に書き込まれるクラスタ メタデータを保護します。
- クラスタ VM にアタッチされた永続ディスク(PD)
- 自動作成された、またはユーザーが作成した Dataproc ステージング バケットに書き込まれたジョブドライバの出力とその他のメタデータ
CMEK を設定する
Cloud KMS 鍵を作成する
Cloud Data Fusion インスタンスを含む Google Cloud プロジェクト、または別のユーザー プロジェクトで Cloud KMS 鍵を作成します。Cloud KMS キーリングの場所は、インスタンスを作成するリージョンと一致する必要があります。Cloud Data Fusion は常に特定のリージョンに関連付けられているため、マルチリージョンまたはグローバル リージョン鍵をインスタンス レベルで指定することはできません。
鍵のリソース名を取得する
REST API
次のコマンドを使用して、作成した鍵のリソース名を取得します。
projects/PROJECT_ID/locations/REGION/keyRings/KEY_RING_NAME/cryptoKeys/KEY_NAME
以下を置き換えます。
- PROJECT_ID: Cloud Data Fusion インスタンスをホストするお客様のプロジェクト
- REGION: ロケーションに近い Google Cloud リージョン(
us-east1など) - KEY_RING_NAME: 暗号鍵をグループ化するキーリングの名前
- KEY_NAME: Cloud KMS 鍵名
Console
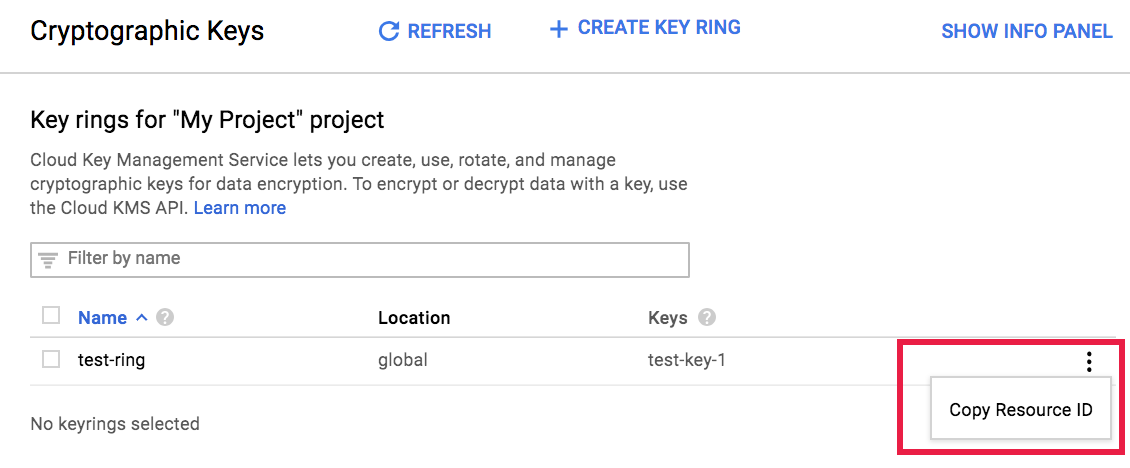
[鍵管理] ページに移動します。
鍵の横にあるその他()をクリックします。
Copy Resource Name: リソース名をクリップボードにコピーします。
プロジェクトのサービス アカウントを更新して、鍵を使用する
作成した鍵を使用するようにプロジェクトのサービス アカウントを設定するには:
必須: Cloud KMS 暗号鍵の暗号化 / 復号のロール(
roles/cloudkms.cryptoKeyEncrypterDecrypter)を Cloud Data Fusion サービス エージェントに付与します。(特定のリソースのサービス アカウントへのロールの付与をご覧ください)。このアカウントの形式は次のとおりです。service-PROJECT_NUMBER@gcp-sa-datafusion.iam.gserviceaccount.comCloud Data Fusion サービス エージェントに Cloud KMS 暗号鍵の暗号化 / 復号のロールを付与すると、Cloud Data Fusion で CMEK を使用してテナント プロジェクトに保存されている顧客データを暗号化できるようになります。
必須: Cloud KMS 暗号鍵の暗号化 / 復号のロールを Compute Engine サービス エージェントに付与します(Cloud Storage サービス アカウントへの Cloud KMS 鍵の割り当てをご覧ください)。このアカウントには、デフォルトで Compute Engine サービス エージェントのロールが付与されます。このアカウントの形式は次のとおりです。
service-PROJECT_NUMBER@compute-system.iam.gserviceaccount.comCompute Engine サービス エージェントに Cloud KMS 暗号鍵の暗号化 / 復号のロールを付与すると、Cloud Data Fusion で CMEK を使用して、パイプラインで実行されている Dataproc クラスタによって書き込まれた永続ディスク(PD)メタデータを暗号化できます。
必須: Cloud KMS 暗号鍵の暗号化 / 復号のロールを Cloud Storage サービス エージェントに付与します(Cloud Storage サービス エージェントへの Cloud KMS 鍵の割り当てをご覧ください)。このサービス エージェントの形式は次のとおりです。
service-PROJECT_NUMBER@gs-project-accounts.iam.gserviceaccount.comこのロールを Cloud Storage サービス エージェントに付与すると、Cloud Data Fusion は CMEK を使用して、パイプライン情報とデータを保存してキャッシュに保存する Cloud Storage バケットと、Dataproc クラスタのステージング バケットに書き込まれるデータと、パイプラインで使用されるプロジェクト内のその他の Cloud Storage バケットを暗号化できます。
必須: Cloud KMS 暗号鍵の暗号化 / 復号のロールを Google Cloud Dataproc サービス エージェントに付与します。このサービス エージェントの形式は次のとおりです。
service-PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com省略可: パイプラインで BigQuery リソースを使用している場合は、Cloud KMS 暗号鍵の暗号化/復号のロールを BigQuery サービス アカウントに付与します(暗号化と復号の権限を付与するをご覧ください)。このアカウントの形式は次のとおりです。
bq-PROJECT_NUMBER@bigquery-encryption.iam.gserviceaccount.com省略可: パイプラインで Pub/Sub リソースを使用している場合は、Cloud KMS 暗号鍵の暗号化/復号のロールを Pub/Sub サービス アカウントに付与します(顧客管理の暗号鍵の使用をご覧ください)。このアカウントの形式は次のとおりです。
service-PROJECT_NUMBER@gcp-sa-pubsub.iam.gserviceaccount.com省略可: パイプラインで Spanner リソースを使用している場合は、Cloud KMS 暗号鍵の暗号化 / 復号のロールを Spanner サービス アカウントに付与します。このアカウントの形式は次のとおりです。
service-PROJECT_NUMBER@gcp-sa-spanner.iam.gserviceaccount.com
CMEK を使用して Cloud Data Fusion インスタンスを作成する
CMEK は、Cloud Data Fusion バージョン 6.5.0 以降のすべてのエディションで使用できます。
REST API
顧客管理の暗号鍵を使用してインスタンスを作成するには、次の環境変数を設定します。
export PROJECT=PROJECT_ID export LOCATION=REGION export INSTANCE=INSTANCE_ID export DATA_FUSION_API_NAME=datafusion.googleapis.com export KEY=KEY_NAME以下を置き換えます。
- PROJECT_ID: Cloud Data Fusion インスタンスをホストするお客様のプロジェクト
- REGION: ロケーションに近い Google Cloud リージョン(例:
us-east1) - INSTANCE_ID: Cloud Data Fusion インスタンスの名前
- KEY_NAME: CMEK 鍵の完全なリソース名
次のコマンドを実行して、Cloud Data Fusion インスタンスを作成します。
curl -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://$DATA_FUSION_API_NAME/v1/projects/$PROJECT/locations/$LOCATION/instances?instance_id=INSTANCE -X POST -d '{"description": "CMEK-enabled CDF instance created through REST.", "type": "BASIC", "cryptoKeyConfig": {"key_reference": "$KEY"} }'
Console
Cloud Data Fusion のページに移動します。
[インスタンス]、[インスタンスを作成] の順にクリックします。
[詳細オプション] で、[顧客管理の暗号鍵(CMEK)を使用する] を選択します。
[顧客管理の暗号鍵を選択] フィールドで、鍵のリソース名を選択します。
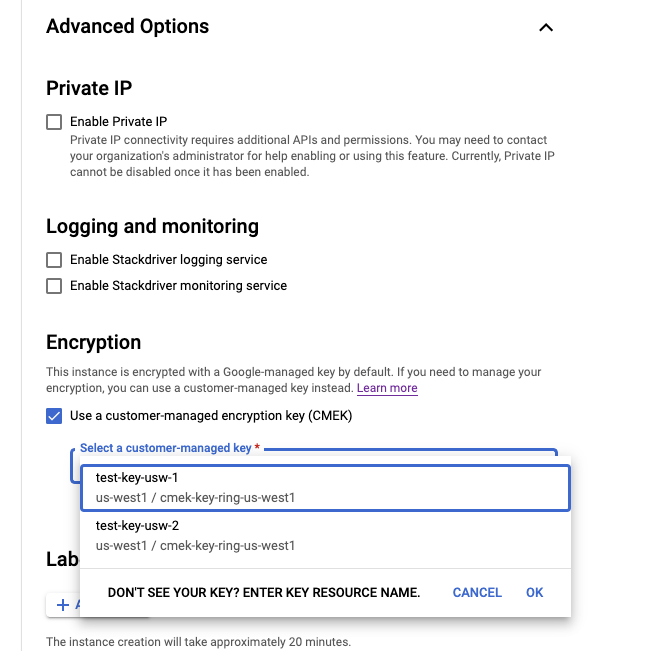
インスタンスの詳細をすべて入力したら、[作成] をクリックします。インスタンスを使用する準備が整うと、[インスタンス] ページに表示されます。
インスタンスで CMEK が有効になっているかどうかを確認する
Console
インスタンスの詳細を表示します。
In the Google Cloud console, go to the Cloud Data Fusion page.
Click Instances, and then click the instance's name to go to the Instance details page.
CMEK が有効になっている場合、[暗号鍵] フィールドに [利用可能] と表示されます。
CMEK が無効になっている場合、[暗号鍵] フィールドに [利用不可] と表示されます。
サポートされているプラグインで CMEK を使用する
暗号鍵の名前を設定する際には、次の形式を使用します。
projects/PROJECT_ID/locations/REGION/keyRings/KEY_RING_NAME/cryptoKeys/KEY_NAME

CMEK をサポートする Cloud Data Fusion プラグインの鍵の動作を次の表に示します。
| サポートされているプラグイン | 鍵の動作 |
|---|---|
| Cloud Data Fusion のシンク | |
| Cloud Storage | プラグインによって作成されたバケットに書き込まれたデータを暗号化します。バケットがすでに存在する場合、この値は無視されます。 |
| Cloud Storage の複数ファイル | プラグインによって作成されたバケットに書き込まれたデータを暗号化します。 |
| BigQuery | プラグインによって作成されたバケット、データセット、テーブルに書き込まれたデータを暗号化します。 |
| BigQuery の複数テーブル | プラグインによって作成されたバケット、データセット、テーブルに書き込まれたデータを暗号化します。 |
| Pub/Sub | プラグインによって作成されたトピックに書き込まれたデータを暗号化します。トピックがすでに存在する場合、この値は無視されます。 |
| Spanner | プラグインによって作成されたデータベースに書き込まれたデータを暗号化します。データベースがすでに存在する場合、この値は無視されます。 |
| Cloud Data Fusion のアクション | |
|
Cloud Storage の作成 Cloud Storage のコピー Cloud Storage の移動 Cloud Storage 完了ファイル マーカー |
プラグインによって作成されたバケットに書き込まれたデータを暗号化します。バケットがすでに存在する場合、この値は無視されます。 |
| BigQuery の実行 | プラグインがクエリ結果を保存するために作成するデータセットまたはテーブルに書き込まれたデータを暗号化します。これは、クエリ結果を BigQuery テーブルに保存する場合にのみ適用されます。 |
| Cloud Data Fusion のソース | |
| BigQuery ソース | プラグインによって作成されたバケットに書き込まれたデータを暗号化します。バケットがすでに存在する場合、この値は無視されます。 |
| Cloud Data Fusion SQL エンジン | |
| BigQuery Pushdown Engine | プラグインによって作成されたバケット、データセット、テーブルに書き込まれたデータを暗号化します。 |
Dataproc クラスタ メタデータで CMEK を使用する
事前に作成されたコンピューティング プロファイルは、インスタンス作成時に提供された CMEK 鍵を使用して、永続ディスク(PD)と、パイプラインで実行中の Dataproc クラスタによって書き込まれたステージング バケット メタデータを暗号化します。次のいずれかの方法で、別の鍵を変更して使用できます。
- 推奨: 新しい Dataproc コンピューティング プロファイルを作成します(Enterprise Edition のみ)。
- 既存の Dataproc コンピューティング プロファイルを編集します(Developer Edition、Basic Edition、Enterprise Edition)。
Console
Cloud Data Fusion インスタンスを開きます。
In the Google Cloud console, go to the Cloud Data Fusion page.
To open the instance in the Cloud Data Fusion Studio, click Instances, and then click View instance.
[システム管理者] > [構成] をクリックします。
[System Compute Profiles] プルダウンをクリックします。
[新しいプロファイルを作] をクリックし、[Dataproc] を選択します。
[Profile label]、[Profile name]、[Description] に、プロファイル ラベル、プロファイル名、説明をそれぞれ入力します。
デフォルトでは、Cloud Data Fusion によってエフェメラル クラスタが作成されるたびに、Dataproc がステージング バケットと一時バケットを作成します。Cloud Data Fusion は、コンピューティング プロファイル内の引数として Dataproc ステージング バケットを渡すことをサポートしています。ステージング バケットを暗号化するには、CMEK 対応バケットを作成し、コンピューティング プロファイルで Dataproc に引数として渡します。
デフォルトでは、Cloud Data Fusion は Dataproc で使用される依存関係をステージングするための Cloud Storage バケットを自動作成します。プロジェクトの既存の Cloud Storage バケットを使用する場合は、次の手順を行います。
[General Settings] セクションの [Cloud Storage Bucket] フィールドに、既存の Cloud Storage バケットを入力します。
Cloud KMS 鍵のリソース ID を取得します。[General Settings] セクションの [Encryption Key Name] フィールドに、リソース ID を入力します。
[作成] をクリックします。
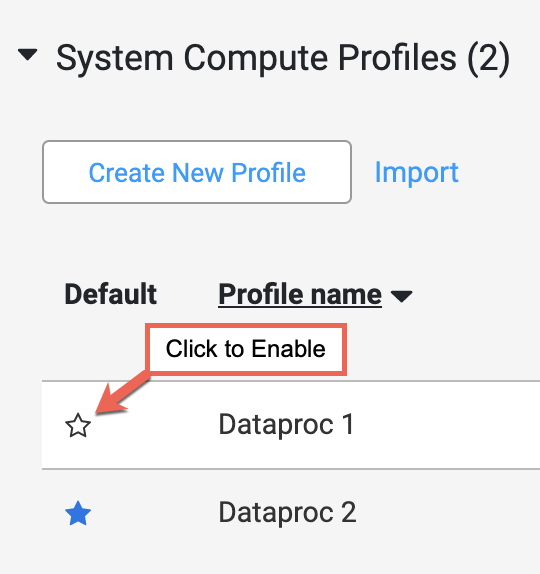
[Configuration] タブの [System Compute Profiles] セクションに複数のプロファイルが一覧表示されている場合は、新しく作成した Dataproc プロファイルをデフォルトのプロファイルにします。それには、プロファイル名のフィールドにポインタを合わせて、表示される星をクリックします。
他のリソースで CMEK を使用する
提供された CMEK 鍵は、Cloud Data Fusion インスタンスの作成時にシステム設定に設定されます。Cloud Storage、BigQuery、Pub/Sub、Spanner シンクなどのパイプライン シンクによって新しく作成されたリソースに書き込まれたデータを暗号化するために使用されます。
この鍵は、新しく作成されたリソースにのみ適用されます。パイプラインの実行前にリソースがすでに存在する場合は、それら既存のリソースに CMEK 鍵を手動で適用する必要があります。
CMEK 鍵は、次のいずれかの方法で変更できます。
- ランタイム引数を使用します。
- Cloud Data Fusion システム設定を使用します。
ランタイム引数
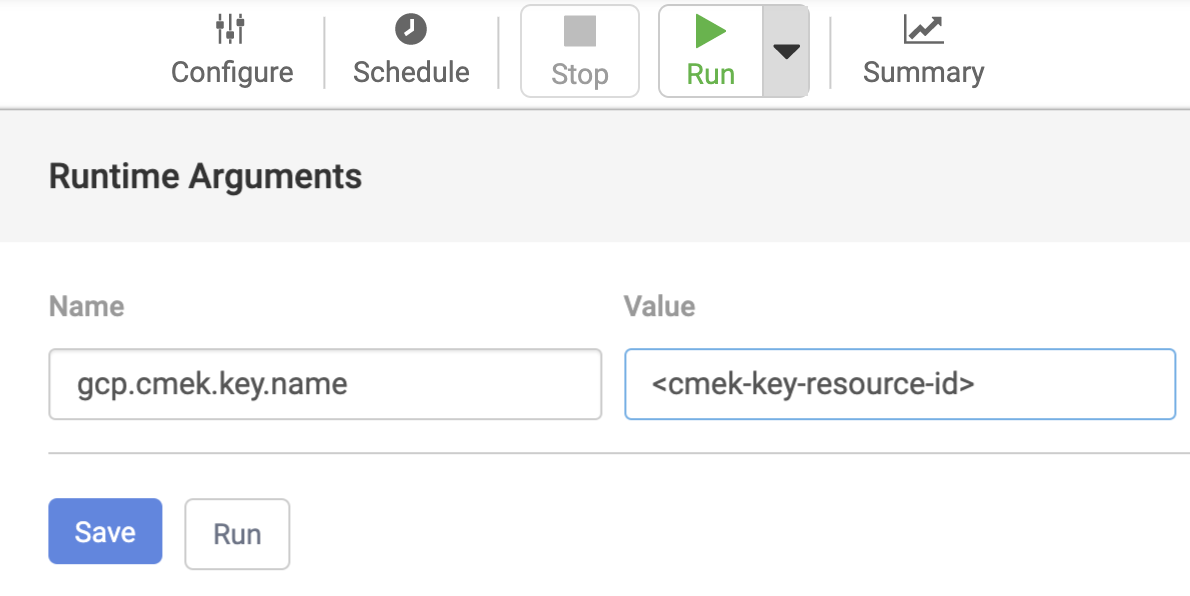
- Cloud Data Fusion の [Pipeline Studio] ページで、[Run] ボタンの右側にあるプルダウン矢印をクリックします。
- [名前] フィールドに「
gcp.cmek.key.name」と入力します。 - [Value] フィールドに、鍵のリソース ID を入力します。
[保存] をクリックします。
ここで設定したランタイム引数は、現在のパイプラインの実行にのみ適用されます。
設定
- Cloud Data Fusion UI で [SYSTEM ADMIN] をクリックします。
- [Configuration] タブをクリックします。
- [System Preferences] プルダウンをクリックします。
- [Edit System Preferences] をクリックします。
- [Key] フィールドに「
gcp.cmek.key.name」と入力します。 - [Value] フィールドに、鍵のリソース ID を入力します。
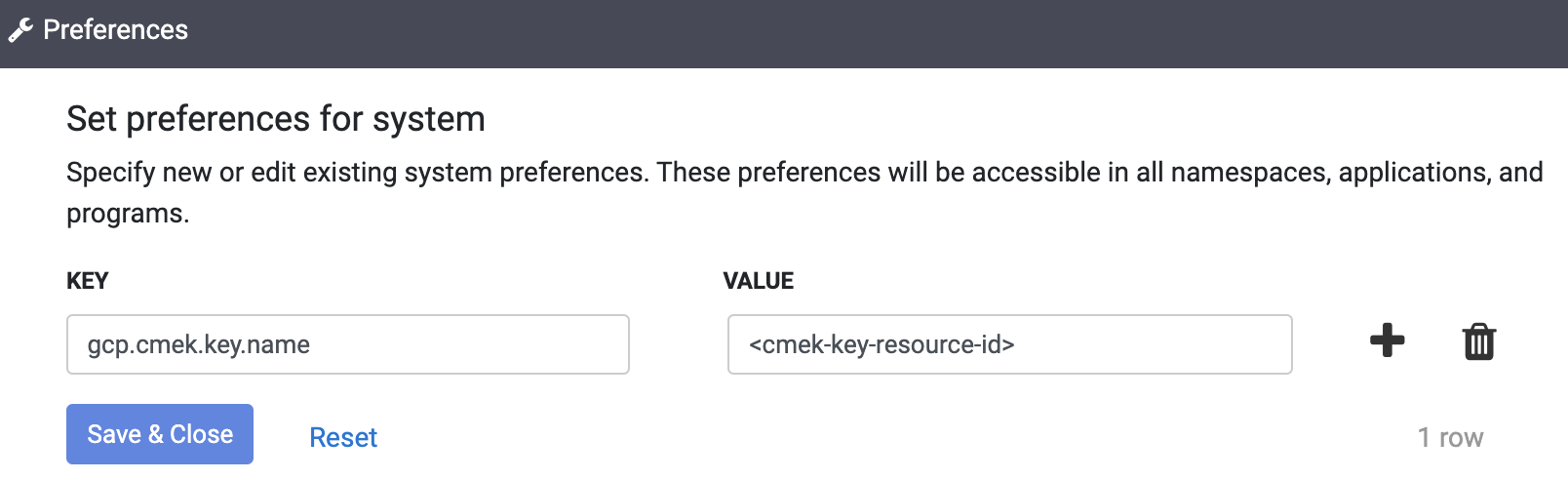
- [保存して閉じる] をクリックします。