Blob Storage 转移作业简介
借助适用于 Azure Blob Storage 的 BigQuery Data Transfer Service,您可以自动安排和管理从 Azure Blob Storage 和 Azure Data Lake Storage Gen2 到 BigQuery 的周期性加载作业。
支持的文件格式
BigQuery Data Transfer Service 目前支持从 Blob Storage 加载数据,格式如下:
- 逗号分隔值(CSV)
- JSON(以换行符分隔)
- Avro
- Parquet
- ORC
支持的压缩类型
适用于 Blob Storage 的 BigQuery Data Transfer Service 支持加载压缩数据。BigQuery Data Transfer Service 支持的压缩类型与 BigQuery 加载作业支持的压缩类型相同。如需了解详情,请参阅加载压缩和未压缩的数据。
转移前提条件
如需从 Blob Storage 数据源加载数据,请先收集以下内容:
- 源数据的 Blob Storage 账号名称、容器名称和数据路径(可选)。数据路径字段是可选的;它用于匹配常见对象前缀和文件扩展名。如果省略数据路径,则会转移容器中的所有文件。
- Azure 共享访问签名 (SAS) 令牌,用于授予对数据源的读取权限。如需详细了解如何创建 SAS 令牌,请参阅共享访问签名 (SAS)。
转移运行时参数化
Blob Storage 数据路径和目标表都可以参数化,以便您能够从按日期整理的容器加载数据。Blob Storage 转移使用的参数与 Cloud Storage 转移使用的参数相同。如需了解详情,请参阅转移作业中的运行时参数。
Azure Blob 转移作业的数据注入
在设置 Azure Blob 转移作业时,您可以在转移作业配置中选择写入偏好设置来指定数据加载到 BigQuery 的方式。
有两种类型的写入偏好设置:增量转移和截断的转移。增量转移
具有 APPEND 或 WRITE_APPEND 写入偏好设置的转移作业配置(也称为增量转移),将从上次成功转移到 BigQuery 目标表后,以增量方式附加新数据。如果转移作业配置使用 APPEND 写入偏好设置运行,BigQuery Data Transfer Service 会过滤自上次转移作业成功运行以来修改的文件。为了确定文件的修改时间,BigQuery Data Transfer Service 会查看文件元数据中的“上次修改时间”属性。例如,BigQuery Data Transfer Service 会查看 Cloud Storage 文件中的 updated 时间戳属性。如果 BigQuery Data Transfer Service 发现任何文件的“上次修改时间”出现在上次成功转移的时间戳之后,则 BigQuery Data Transfer Service 会以增量转移方式转移这些文件。
为了演示增量转移的工作原理,请考虑以下 Cloud Storage 转移示例。用户于 2023-07-01T00:00Z 在 Cloud Storage 存储桶中创建了一个名为 file_1 的文件。file_1 的 updated 时间戳是文件的创建时间。然后,用户从 Cloud Storage 存储桶创建增量转移,安排成从 2023-07-01T03:00Z 起每天 03:00Z 运行一次。
- 在 2023-07-01T03:00Z,首次转移作业开始运行。由于这是此配置的首次转移作业运行,因此 BigQuery Data Transfer Service 会尝试将与源 URI 匹配的所有文件加载到目标 BigQuery 表中。转移作业运行成功,且 BigQuery Data Transfer Service 成功将
file_1加载到目标 BigQuery 表中。 - 下一次转移作业运行 (2023-07-02T03:00Z) 检测不到
updated时间戳属性晚于上次转移作业成功运行 (2023-07-01T03:00Z) 的文件。转移作业运行成功,但不会将任何其他数据加载到目标 BigQuery 表中。
上面的示例展示了 BigQuery Data Transfer Service 如何查看源文件的 updated 时间戳属性,以确定是否对源文件进行了任何更改,并在检测到任何更改时转移这些更改。
按照相同的示例,假设用户于 2023-07-03T00:00Z 在 Cloud Storage 存储桶中创建了另一个名为 file_2 的文件。file_2 的 updated 时间戳是文件的创建时间。
- 下一次转移作业运行(时间 2023-07-03T03:00Z)检测到
file_2的updated时间戳晚于上一次转移作业成功运行 (2023-07-01T03:00Z)。假设转移作业运行因暂时性错误而失败。在这种情况下,file_2不会加载到目标 BigQuery 表中。上一次成功的转移作业运行时间戳仍为 2023-07-01T03:00Z。 - 下一次转移作业运行(时间 2023-07-04T03:00Z)检测到
file_2的updated时间戳晚于上次转移作业成功运行 (2023-07-01T03:00Z)。这次,转移作业运行成功完成且没有出现问题,因此成功将file_2加载到目标 BigQuery 表中。 - 下一次转移作业运行(时间 2023-07-05T03:00Z)检测不到
updated时间戳晚于上一次转移作业成功运行 (2023-07-04T03:00Z) 的文件。转移作业运行成功,但不会将任何其他数据加载到目标 BigQuery 表中。
上面的示例显示,转移作业失败时,没有任何文件转移到 BigQuery 目标表。任何文件更改都将在下一次转移作业成功运行时转移。转移作业失败后的任何后续成功转移作业都不会导致重复数据。如果转移作业失败,您还可以选择在计划安排的时间之外手动触发转移作业。
截断的转移
具有 MIRROR 或 WRITE_TRUNCATE 写入偏好设置的转移作业配置(也称为截断的转移)会在每次转移作业运行期间,使用与源 URI 匹配的所有文件中的数据来覆盖 BigQuery 目标表中的数据。MIRROR 用于覆盖目标表中数据的新副本。如果目标表使用分区修饰器,则转移作业运行只会覆盖指定分区中的数据。具有分区修饰器的目标表的格式为 my_table${run_date},例如 my_table$20230809。
一天内重复相同的增量转移或截断的转移不会导致重复数据。但是,如果您运行多个会影响同一 BigQuery 目标表的转移作业配置,则可能会导致 BigQuery Data Transfer Service 重复转移数据。
Blob Storage 数据路径的通配符支持
您可以通过在数据路径中指定一个或多个星号 (*) 通配符来选择拆分为多个文件的源数据。
虽然可以在数据路径中使用多个通配符,但仅使用单个通配符时,可以进行一些优化:
- 每次转移运行的最大文件数存在较高的限制。
- 通配符可跨目录边界起效。例如,数据路径
my-folder/*.csv将与my-folder/my-subfolder/my-file.csv文件匹配。
Blob Storage 数据路径示例
以下是 Blob Storage 转移的有效数据路径示例。请注意,数据路径不能以 / 开头。
示例:单个文件
如需将单个文件从 Blob Storage 加载到 BigQuery,请指定 Blob Storage 文件名:
my-folder/my-file.csv
示例:所有文件
如需将 Blob Storage 容器中的所有文件加载到 BigQuery 中,请将数据路径设置为单个通配符:
*
示例:具有相同前缀的文件
如需从 Blob Storage 加载具有共同前缀的所有文件,请指定共同前缀,可以带通配符,也可以不带通配符:
my-folder/
或
my-folder/*
示例:具有类似路径的文件
如需加载 Blob Storage 中具有相似路径的所有文件,请指定共同前缀和后缀:
my-folder/*.csv
仅使用单个通配符时,该通配符会跨目录起效。在此示例中,系统将选择 my-folder 中的每个 CSV 文件以及 my-folder 的每个子文件夹中的每个 CSV 文件。
示例:路径末尾的通配符
请考虑以下数据路径:
logs/*
将会选择以下所有文件:
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
示例:路径开头的通配符
请考虑以下数据路径:
*logs.csv
将会选择以下所有文件:
logs.csv
system/logs.csv
some-application/logs.csv
不会选择以下文件:
metadata.csv
system/users.csv
some-application/output.csv
示例:多个通配符
通过使用多个通配符,您可以更好地控制文件选择,但会降低限制。使用多个通配符时,每个通配符仅跨越一个子目录。
请考虑以下数据路径:
*/*.csv
系统会同时选择以下两个文件:
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
不会选择以下文件:
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
共享访问签名 (SAS)
Azure SAS 令牌用于代表您访问 Blob Storage 数据。按照以下步骤为转移作业创建 SAS 令牌:
- 创建或使用现有的 Blob Storage 用户来访问 Blob Storage 容器的存储账号。
在存储账号级层创建 SAS 令牌。如需使用 Azure 门户创建 SAS 令牌,请执行以下操作:
- 对于允许的服务,请选择 Blob。
- 对于允许的资源类型,选择容器和对象。
- 对于允许的权限,选择读取和列出。
- SAS 令牌的默认到期时间为 8 小时。设置适用于转移作业时间表的到期时间。
- 请勿在允许的 IP 地址字段中指定任何 IP 地址。
- 对于允许的协议,选择仅限 HTTPS。
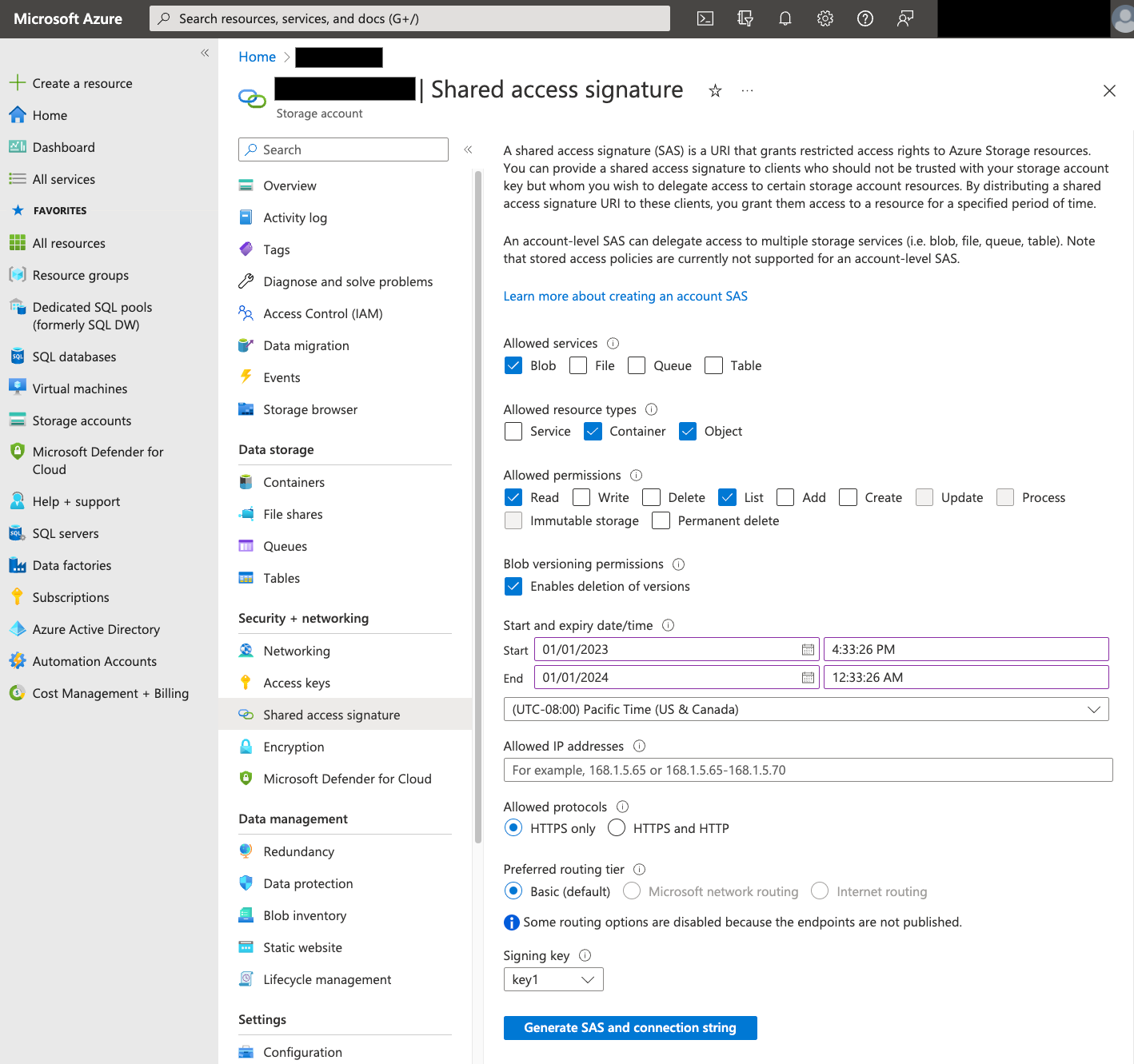
创建 SAS 令牌后,记下返回的 SAS 令牌值。配置转移作业时需要此值。
IP 限制
如果您使用 Azure Storage 防火墙限制对 Azure 资源的访问,则必须将 BigQuery Data Transfer Service 工作器使用的 IP 范围添加到允许的 IP 列表。
如需将 IP 范围作为允许的 IP 添加到 Azure Storage 防火墙,请参阅 IP 限制。
一致性考虑因素
文件添加到 Blob Storage 容器后,可能需要大约 5 分钟,该文件才能在 BigQuery Data Transfer Service 中可用。
控制出站流量费用的最佳做法
如果目标表配置不当,则从 Blob Storage 转移可能会失败。配置不当的可能原因包括:
- 目标表不存在。
- 表架构未定义。
- 表架构与正在转移的数据不兼容。
为了避免额外的 Blob Storage 出站流量费用,请先使用较小但有代表性的文件子集来测试转移作业。确保此测试在数据大小和文件计数中都很小。
请务必注意,在从 Blob Storage 传输文件之前,数据路径的前缀匹配会发生,但通配符匹配在 Google Cloud内部进行。这种差异会增加转移到Google Cloud 但未加载到 BigQuery 的文件的 Blob Storage 出站流量费用。
例如,假设有以下数据路径:
folder/*/subfolder/*.csv
以下两个文件都转移到 Google Cloud,因为它们的前缀为 folder/:
folder/any/subfolder/file1.csv
folder/file2.csv
但是,只有 folder/any/subfolder/file1.csv 文件会加载到 BigQuery 中,因为它与完整的数据路径匹配。
价格
如需了解详情,请参阅 BigQuery Data Transfer Service 价格。
您还可以使用此服务在 Google 外部产生费用。如需了解详情,请参阅 Blob Storage 价格。
配额和限制
BigQuery Data Transfer Service 使用加载作业将 Bolb Storage 数据加载到 BigQuery 中。加载作业的所有 BigQuery 配额和限制均适用于周期性 Blob Storage 转移作业,同时还需额外注意以下限制:
| 限制 | 默认值 |
|---|---|
| 每次加载作业转移运行的大小上限 | 15 TB |
| 当 Bolb Storage 数据路径包含 0 或 1 个通配符时每次转移运行的最大文件数 | 1000 万个文件 |
| 当 Bolb Storage 数据路径包含 2 个或更多通配符时每次转移运行的最大文件数 | 1 万个文件 |
后续步骤
- 详细了解如何设置 Blob Storage 转移。
- 详细了解转移作业中的运行时参数。
- 详细了解 BigQuery Data Transfer Service。