Next '24에서 공개된 최신 제품 출시, 데모, 교육을 확인하세요. 시작하기
탄소 발자국
클라우드의 탄소 배출량을 측정하고 보고하며 감축합니다.
보고서 및 공개 문구에 위치 기반 및 시장 기반 탄소 배출량 데이터 모두 포함
대시보드와 차트를 사용하여 탄소 통계 시각화
클라우드 애플리케이션 및 인프라의 탄소 배출량 감소
이점
탄소 발자국의 정확한 측정
탄소 발자국의 정확한 측정
Google Cloud 사용량에서 파생된 위치 기반 및 시장 기반 배출량을 확인하여 클라우드 애플리케이션과 관련된 배출량을 투명하게 공개합니다.
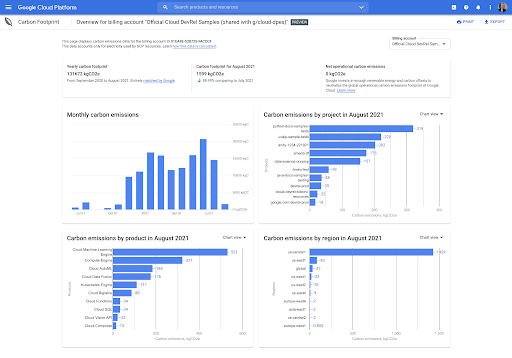
클라우드 프로젝트의 세분화된 탄소 배출량 프로필 추적
클라우드 프로젝트의 세분화된 탄소 배출량 프로필 추적
프로젝트, 제품, 리전별로 시간에 따른 클라우드 탄소 배출량을 모니터링하여 IT팀 및 개발자에게 탄소 발자국을 개선하는 데 도움이 되는 측정항목을 제공할 수 있습니다.
주요 특징
주요 특징
[신규] 위치 기반 및 시장 기반 배출량의 이중 보고
콘솔 내 대시보드 및 BigQuery Export에서는 범위 1 및 범위 3 배출량 외에 범위 2 시장 기반 및 범위 2 위치 기반 배출량 데이터를 모두 제공합니다.
전기 관련(범위 2) 배출량에 대한 시장 기반 데이터만 보고하는 것과 달리 이중 보고는 다양한 사용 사례에 대해 더 높은 투명성과 포괄적인 통계를 제공합니다.
콘솔 내 대시보드
대시보드 데이터 요약에는 계정의 관련 Google Cloud 서비스 사용과 연결된 세 가지 범위에서 위치 기반 탄소 배출량과 시장 기반 탄소 배출량을 모두 개략적으로 확인할 수 있습니다.
자동화되고 세분화된 BigQuery로 내보내기
데이터 분석을 수행하거나, 커스텀 대시보드와 보고서를 만들거나, 조직의 탄소 배출량 계산 도구에 데이터를 포함하기 위해 탄소 발자국 데이터를 BigQuery로 내보낼 수 있습니다.
사용 가능한 기간에 대해 선택한 결제 계정의 Google Cloud 서비스, 프로젝트, 리전, 월별로 탄소 배출량을 자세히 살펴보고 분석할 수 있습니다.
위치 기반 배출량 감소 추정치
탄소 발자국 데이터는 미사용 프로젝트 추천자와 통합되어 유휴 상태의 프로젝트를 삭제하여 얻을 수 있는 위치 기반 탄소 배출량 감소 추정치를 제공합니다.
탄소 발자국 방법의 제3자 검토
Google은 탄소 발자국 방법이 GHG 프로토콜에 따라 Google Cloud 제품의 탄소 배출량을 계산하고 할당하는 데 합당하고 적절하다는 결론을 도출한 지속가능성 컨설팅 관련 제3자 전문가의 검토서를 게시했습니다.
고객
고객이 환경에 미치는 영향을 줄이도록 지원
Google Cloud는 고객이 지속 가능성 목표를 달성할 수 있도록 고객과 협력하고 있습니다.



새로운 소식
최신 탄소 관련 뉴스 및 이벤트 확인
Google Cloud 뉴스레터를 신청하여 제품 업데이트, 행사 정보, 특별 이벤트 등의 소식을 받아보세요.



문서
문서
탄소 배출량 내보내기
원하는 내용을 찾을 수 없으신가요?
가격 책정
가격 책정
탄소 발자국이 모든 Google Cloud 고객에게 무료로 제공됩니다.
탄소 배출량 데이터를 BigQuery로 내보내면 수수료를 최소화할 수 있습니다. 예상 비용에 대한 자세한 내용은 스토리지 및 쿼리 비용 예측을 참조하세요.
파트너
데이터, 보고 및 컨설팅 파트너
Google Cloud 탄소 배출량 데이터를 일반적으로 사용하는 탄소 계산 도구와 통합할 수 있습니다. 또한 Google은 배출량 및 환경 데이터를 전문적으로 취급하는 조직과 협력하고 있습니다.
탄소 배출량 보고 또는 컨설팅
다음 파트너들이 전사적인 탄소 배출량을 보고하고 탄소 정보 공개를 준비하는 데 도움이 될 수 있습니다.




데이터 및 시각화
다음 파트너들은 환경에 미치는 영향, 위험, 기회를 더 잘 이해하는 데 도움이 되는 데이터와 도구를 제공합니다.














