Empreinte carbone
Mesurez, consignez et réduisez vos émissions de carbone liées au cloud
Inclure des données sur les émissions de carbone basées sur la localisation et sur le marché dans les rapports et les communiqués
Visualiser les insights sur les émissions de carbone grâce aux tableaux de bord et aux graphiques
Réduire les émissions des applications et de l'infrastructure cloud
Avantages
Mesurez précisément votre empreinte carbone
Mesurez précisément votre empreinte carbone
Consultez les émissions basées sur la localisation et sur le marché provenant de votre utilisation de Google Cloud, et bénéficiez de transparence sur les émissions associées à vos applications cloud.
Suivre le profil précis des émissions des projets cloud
Suivre le profil précis des émissions des projets cloud
Surveillez l'évolution de vos émissions cloud au fil du temps par projet, produit et région. Vous obtenez ainsi des métriques qui permettent aux équipes informatiques et aux développeurs d'améliorer leur empreinte carbone.
Partager une méthodologie détaillée avec les réviseurs
Notre méthodologie de calcul détaillée est publiée afin que les évaluateurs et les équipes de signalement puissent vérifier que leurs données d'émission respectent le protocole GHG.
Principales fonctionnalités
Principales fonctionnalités
[NOUVEAU] Double rapport des émissions basées sur la localisation et sur le marché
Dans le tableau de bord intégré à la console et dans BigQuery Export, nous fournissons à la fois les données sur les émissions de scope 2 basées sur les marchés et les données sur les émissions de scope 2 basées sur la localisation, en plus des émissions de scope 1 et de scope 3.
Comparé à la simple déclaration de données basées sur le marché pour les émissions liées à l'électricité (scope 2), le double rapport offre une transparence accrue et des insights plus complets pour vos différents cas d'utilisation.
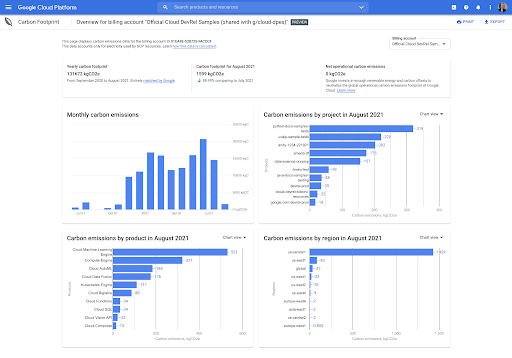
Tableau de bord intégré à la console
Le récapitulatif des données du tableau de bord vous donne un aperçu global des émissions de carbone basées sur la localisation et basées sur le marché, des trois scopes associés à l'utilisation des services Google Cloud couverts pour votre compte.
Exportations automatisées et précises vers BigQuery
Vous pouvez exporter vos données Empreinte carbone vers BigQuery afin de les analyser, créer des tableaux de bord et des rapports personnalisés, ou les inclure dans les outils de comptabilité des émissions de votre organisation.
Vous pouvez approfondir et analyser vos émissions de carbone en fonction du service Google Cloud, du projet, de la région et du mois pour le compte de facturation sélectionné, au cours de tous les mois disponibles.
Estimations de réduction des émissions basées sur la localisation
Les données Empreinte carbone sont intégrées à l'outil de recommandation de projets sans surveillance, qui vous fournit une estimation des réductions d'émissions potentielles en cas de suppression des projets inactifs.
Examen par des tiers de la méthodologie de l'outil Empreinte carbone
Nous avons publié une déclaration d'avis réalisée par des experts tiers en conseil en développement durable. Celle-ci estime que la méthodologie Empreinte carbone est appropriée et raisonnable pour calculer et allouer les émissions de Google Cloud, conformément au protocole GGH.
Clients
Aider les clients à réduire leur impact environnemental
Google Cloud collabore avec ses clients pour les aider à atteindre leurs propres objectifs de développement durable.



Nouveautés
Recevoir les dernières actualités et événements sur les émissions de carbone
Inscrivez-vous à la newsletter Google Cloud pour recevoir des informations sur les produits et événements, des offres spéciales et bien plus encore.



Documentation
Documentation
Tarification
Tarifs
L'outil Empreinte carbone est fourni gratuitement à tous les clients Google Cloud.
L'exportation de vos données sur les émissions de carbone vers BigQuery entraîne des frais minimaux. Pour vous faire une idée des frais qui vous sont facturés, consultez la section Estimer les coûts du stockage et des requêtes.
Partenaires
Partenaires pour les données, les rapports et les conseils
Vous pouvez intégrer vos données d'émission Google Cloud dans des outils de comptabilité carbone populaires. Nous travaillons également avec des entreprises spécialisées dans les émissions et les données environnementales.
Rapports ou conseils sur les émissions
Ces partenaires peuvent vous aider à rapporter les émissions à l'échelle de l'entreprise et à préparer les communiqués.




Données et visualisation
Ces partenaires fournissent des données et des outils vous permettant de mieux comprendre votre impact environnemental, vos risques et vos opportunités.



Passez à l'étape suivante
Profitez de 300 $ de crédits gratuits et de plus de 20 produits Always Free pour commencer à créer des applications sur Google Cloud.
Vous avez besoin d'aide pour démarrer ?
Contacter le service commercialFaites appel à un partenaire de confiance
Trouvez un partenairePoursuivez vos recherches
Voir tous les produits











