Huella de carbono
Mide, informa y reduce las emisiones de carbono de la nube
Incluye en los informes y divulgaciones datos de emisiones de carbono basadas en la ubicación y en el mercado.
Visualiza las estadísticas de carbono usando paneles y gráficos
Reduce las emisiones de las aplicaciones y la infraestructura de nube
Beneficios
Mide con precisión tu huella de carbono
Mide con precisión tu huella de carbono
Visualiza las emisiones basadas en la ubicación y en el mercado que se derivan del uso de Google Cloud, lo que brinda transparencia sobre las emisiones asociadas con tus aplicaciones en la nube.
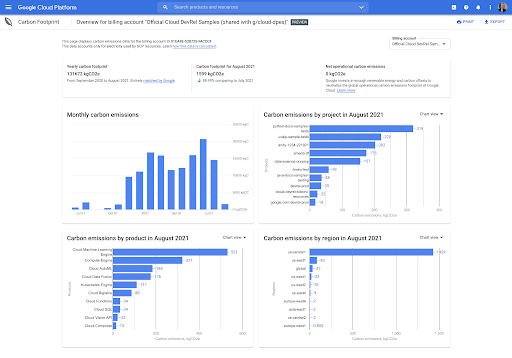
Haz un seguimiento del perfil detallado de emisiones de los proyectos en la nube
Haz un seguimiento del perfil detallado de emisiones de los proyectos en la nube
Supervisa las emisiones de nube a lo largo del tiempo por proyecto, producto y región; esto brinda a los equipos de TI y a los desarrolladores métricas que los pueden ayudar a reducir su huella de carbono.
Comparte una metodología detallada con los revisores
Nuestra metodología de cálculo detallada se publica para que los revisores y los equipos de informes puedan verificar que sus datos de emisiones cumplan con el Protocolo de gas de efecto invernadero.
Características clave
Características clave
[NUEVO] Informe dual de emisiones basadas en la ubicación y en el mercado
En el panel en la consola y en BigQuery Export, proporcionamos datos de emisiones de alcance 2 basados en el mercado y de alcance 2 basados en la ubicación, además de emisiones de alcance 1 y alcance 3.
En comparación con informar solo datos basados en el mercado para emisiones relacionadas con la electricidad (alcance 2), los informes dobles ofrecen más transparencia y estadísticas integrales para tus diferentes casos de uso.
Panel en la consola
El resumen de datos del panel te proporciona una descripción general de las emisiones de carbono basadas en la ubicación y en el mercado de los 3 alcances asociados con el uso de los servicios cubiertos de Google Cloud para tu cuenta.
Exportaciones automatizadas y detalladas a BigQuery
Puedes exportar tus datos de Huella de carbono a BigQuery para realizar análisis de datos, crear informes y paneles personalizados, o incluir datos en las herramientas de contabilidad de emisiones de tu organización.
Puedes analizar con mayor profundidad tus emisiones de carbono según el servicio de Google Cloud, el proyecto, la región y el mes de la cuenta de facturación seleccionada en todos los meses disponibles.
Estimaciones de reducción de emisiones basadas en la ubicación
Los datos de Huella de carbono se integran en el recomendador de proyectos sin actividad, que te proporciona estimaciones de las reducciones de emisiones basadas en la ubicación que podrías lograr si quitas los proyectos inactivos.
Revisión de terceros de la metodología de Huella de carbono
Publicamos una revisión de expertos externos en asesoría de sustentabilidad, en la que se concluye que la metodología de Huella de carbono es una forma razonable y adecuada de calcular y asignar las emisiones de los productos de Google Cloud según el Protocolo de GEI.
Clientes
Ayudamos a los clientes a reducir el impacto ambiental
Google Cloud trabaja con nuestros clientes para ayudarlos a alcanzar sus propios objetivos de sustentabilidad.



Novedades
Conoce las noticias y los eventos más recientes sobre los informes de emisiones de carbono
Regístrate para recibir los boletines informativos de Google Cloud con información sobre actualizaciones de productos, eventos, ofertas especiales y mucho más.



Documentación
Documentación
Precios
Precios
Huella de carbono se proporciona sin cargo a todos los clientes de Google Cloud.
Si exportas tus datos de emisiones de carbono a BigQuery, se te cobrarán tarifas mínimas. Para tener una idea de los cargos que debes esperar, consulta Estima los costos de almacenamiento y búsquedas.
Socios
Informes, datos y socios de asesoramiento
Puedes integrar tus datos de emisiones de Google Cloud en herramientas populares de contabilidad de carbono. También nos asociamos con organizaciones especializadas en datos ambientales y de emisiones.
Asesoramiento o informes sobre emisiones
Estos socios pueden ayudarte a generar informes sobre las emisiones en toda la empresa y preparar divulgaciones sobre el carbono.




Datos y visualización
Estos socios proporcionan datos y herramientas para ayudarte a comprender mejor tu impacto ambiental, tus riesgos y tus oportunidades.



Da el siguiente paso
Comienza a desarrollar en Google Cloud con el crédito gratis de $300 y los más de 20 productos del nivel Siempre gratuito.
¿Necesitas ayuda para comenzar?
Comunicarse con VentasTrabaja con un socio confiable
Buscar un socioSigue explorando
Ver todos los productos











