Neuigkeiten und Ereignisse
Neuigkeiten und Ereignisse
- Lesen Sie, warum Google im Gartner®-Bericht „Magic Quadrant™ for AI Infrastructure“ als einer der führenden Anbieter eingestuft wurde.Lesen Sie den Bericht und erfahren Sie, warum der AI Hypercomputer hinsichtlich Ausführung und Vision am weitesten vorne liegt.
- Aktuelle Neuigkeiten zu TPUsMelden Sie sich für unsere Mailingliste an, um als Erstes über neue TPU-Einführungen und Veranstaltungen informiert zu werden.
- Ihre Entwickler mit einer globalen Community verbindenUnsere Google Cloud × NVIDIA-Community hat gerade die Marke von 100.000 Mitgliedern überschritten. Hier können sich Entwickler austauschen, ihr Wissen teilen und von anderen lernen.
Die Zukunft der KI-Infrastruktur
Die Zukunft der KI-Infrastruktur
AI Hypercomputer ist eine Architektur, die speziell entwickelte Hardware, offene Software und flexible Verbrauchsmodelle kombiniert. Die einzelnen Komponenten wurden sorgfältig eingebunden, um gut mit den anderen zusammenzuarbeiten und so Leistung, Kosten und Entwicklerproduktivität zu verbessern.

Intelligenteres und schnelleres Training
Intelligenteres und schnelleres Training
Modelle in Wochen statt Monaten erstellen. Mit dem Trainings-Stack von Google können Sie Entwicklung und Tests beschleunigen, ohne die Leistung zu beeinträchtigen.

LLMs schneller trainieren und abstimmen
Mit der TPU 8t und der von Google DeepMind mitentwickelten Software, die in Open-Source-Frameworks integriert ist – von Pathways bis Pallas (Training) und von Ray bis Agent Sandbox (Abstimmung) – können Sie LLMs 36 % schneller entwickeln und die Produktivität (Goodput) jedes Beschleunigers um bis zu 97 % steigern. Wir wissen auch, dass es nicht die eine Lösung für alle gibt. Deshalb arbeiten wir eng mit NVIDIA zusammen, um die neuesten GPUs anzubieten. Google Cloud wird zu den ersten Anbietern gehören, die Instanzen auf Basis der NVIDIA Vera Rubin NVL72 der nächsten Generation bereitstellen, sobald diese im Laufe dieses Jahres verfügbar werden.
Leistungsstarke Modelle mit proprietären Daten trainieren
Mit der Gemini Enterprise Agent Platform und BigQuery können Sie Modelle mit proprietären Daten 16-mal schneller trainieren, indem Sie Ihre Datenbestände, die ML-Entwicklung und Beschleuniger an einem Ort zusammenführen. Beide werden vom AI Hypercomputer unterstützt, unabhängig davon, ob Sie G4-VMs oder Ironwood-TPUs verwenden.
Adaptive physische Agenten mit MuJoCo-Warp erstellen
GPU-basierte Simulationen mit MuJoCo-Warp von DeepMind ausführen – bis zu 100-mal schneller als mit dem Standard-MuJoCo. Anschließend können Sie mit synthetischen Medien von Veo, Genie und Nano Banana unmögliche, riskante oder teure Grenzfälle simulieren oder Petabyte an realen Sensordaten in BigQuery aufnehmen. Hier erfahren Sie mehr über das Erstellen physischer Agenten in Google Cloud.
Schnelle, effiziente Inferenz
Schnelle, effiziente Inferenz
Sie erhalten validierte Modellprofile sowie vollständig integrierte Google- und Open-Source-Software, um die Reaktionsfähigkeit von Anwendungen zu verbessern und gleichzeitig Komplexität und Verschwendung zu reduzieren.
LLMs mit nahezu latenzfreier Bereitstellung
Dank eingebundener Inferenztechnologien können Sie Ihren Kunden nützliche, reaktionsschnelle Dienste anbieten. Mit GKE Inference Gateway lässt sich die Zeit bis zum ersten Token um 71 % verkürzen. Mit llm-d für die disaggregierte Bereitstellung können bis zu 120.000 Tokens pro Sekunde bereitgestellt werden. Und mit Rapid Cache und TPU 8i lassen sich Modelle fünfmal schneller laden, sodass der Arbeitsspeicher genau dort zur Verfügung steht, wo er benötigt wird.
Vordefinierte Modelle für visuelle Daten, Wahrnehmung und Medien bereitstellen
Klassische ML-Modelle lassen sich 70 % schneller bereitstellen, wenn Sie eines der über 200 Modelle auf der Gemini Enterprise Agent Platform verwenden. Dabei können Sie zwischen TPU und GPU wählen, einschließlich A5X-VMs (NVIDIA Vera Rubin) und TPU 8i, sobald diese im Laufe des Jahres verfügbar sind.
KI-Agenten sicher und kosteneffizient bereitstellen
In der GKE Agent Sandbox können Sie Asichergentenschwärme sicher bereitstellen. Dabei stehen pro Sekunde bis zu 300 Sandboxes zur Verfügung. Sie können sie bei Bedarf umgehend pausieren oder fortsetzen, sodass Sie nie für inaktive Agenten bezahlen.
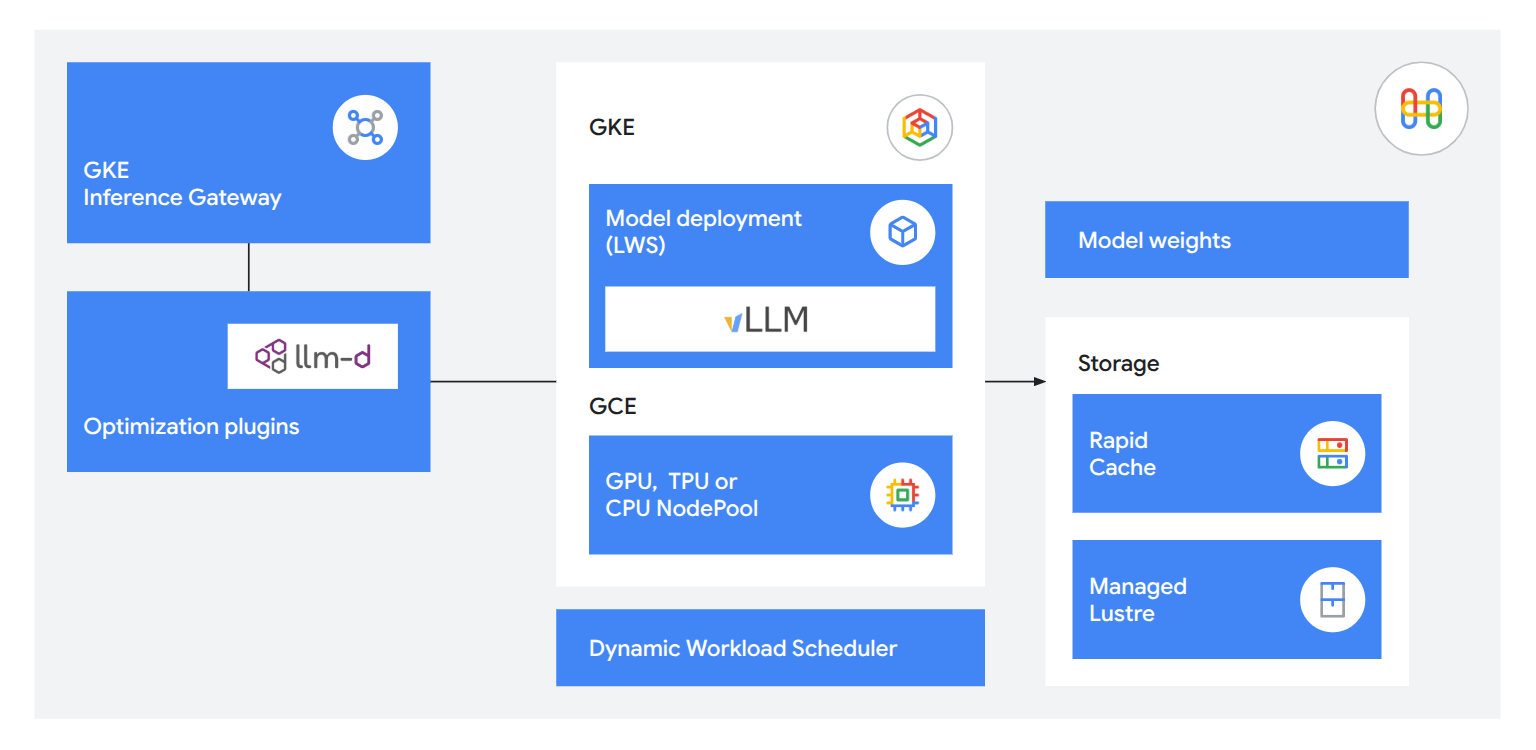
Flexibler, offener und zuverlässiger Betrieb
Flexibler, offener und zuverlässiger Betrieb
Sie können jedes Framework oder jeden Accelerator in Hybrid- und Multi-Cloud-Umgebungen mit automatisierter Clusterwartung und ‑verwaltung für Exascale-Anforderungen verwenden.

Zwischen TPUs und GPUs wechseln, ohne Code neu zu schreiben
TorchTPU bietet nativen PyTorch-Support, sodass Entwickler die TPU-Lernkurve überspringen und den besten verfügbaren Beschleuniger ohne komplexe Code-Neuschreibungen verwenden können.
KI in jeder Umgebung und in nahezu jeder Größenordnung bereitstellen
GKE basiert auf dem Open-Source-System Kubernetes und bietet Ihnen Multicloud-Portabilität in Unternehmensdimensionen. Es unterstützt bis zu 130.000 Knoten und lässt sich nativ in die Agent Platform und Google Distributed Cloud für hybride Bereitstellungen einbinden.
Clusterwartung mit erweiterten Clusterdiagnose- und Beobachtbarkeitstools automatisieren
Jeder Beschleuniger auf AI Hypercomputer wird durch Cluster Director-Funktionen unterstützt, darunter ein Zustandsbericht vor der Bereitstellung, 360-Grad-Dashboards zur Beobachtbarkeit und fortlaufende Zustandsprüfungen.
Multicloud-Arbeitslasten in wenigen Minuten statt Wochen verbinden
Mit Cross-Cloud Network, einem Netzwerk-Backbone, dem über 65 % der Fortune-100-Unternehmen vertrauen und der monatlich über 27 Exabyte an Daten überträgt, können Sie Dienste in verschiedenen Clouds ohne Verzögerungen verbinden.
Beschleunigerkapazität nach Bedarf
Unsere flexiblen Verbrauchsmodelle bieten Ihnen mehrere Möglichkeiten, die Kosten für Beschleuniger zu planen und zu senken. Mit Spot-VMs können Sie bis zu 91 % bei Batch- oder fehlertoleranten Jobs sparen, mit dem Dynamic Workload Scheduler bis zu 50 % bei Jobs mit flexiblem Startdatum und mit Rabatten für zugesicherte Nutzung bis zu 50 %.
Für den Einsatz von KI-Agenten geeignete Systeme
Für den Einsatz von KI-Agenten geeignete Systeme
Sie können die Leistungsgrenzen ausreizen und Energie verantwortungsbewusst nutzen, während Sie auf der Infrastruktur aufbauen, auf die Google und führende KI-Labore vertrauen.
KI-Roadmap auf einer vertrauenswürdigen Grundlage umsetzen
Google Cloud unterstützt 9 von 10 der führenden KI-Labore und 70 % der finanzierten KI-Start-ups. Wenn Sie AI Hypercomputer verwenden, nutzen Sie Rechenzentren, die allein im Dezember 2025 zuverlässig über 100 Milliarden Tokens für fast 350 Kunden verarbeitet haben.
Branchenführende Energieeffizienz
Die Rechenzentren von Google Cloud, einschließlich des AI Hypercomputers, bieten eine branchenführende Energieeffizienz und liefern sechsmal mehr Rechenleistung pro Stromeinheit als noch vor fünf Jahren. Dadurch bietet unsere TPU der 8. Generation ein 80 % besseres Preis-Leistungs-Verhältnis und ist 20 % energieeffizienter als die vorherige Generation.
Auswirkungen auf das Stromnetz und die Gemeinden reduzieren
Wir verpflichten uns dazu, 100 % des Stroms, den unsere Rechenzentren verbrauchen, und alle neuen Infrastrukturkosten, die direkt durch unser Wachstum entstehen, zu bezahlen. Arbeiten Sie mit uns zusammen, damit die Kosten für Ihre KI-Ambitionen nicht auf die lokalen Haushalte und Unternehmen abgewälzt werden. In den kommenden Jahren werden wir neue Energiequellen und Infrastruktur für unsere Modelle finanzieren und weiterhin in alternative Energiequellen wie fortschrittliche Kernenergie, Geothermie und Langzeitspeicher investieren.
Ihr wertvollstes geistiges Eigentum von Siliziumchips bis zum Edge-Netzwerk schützen
Die Titanium-Architektur mit den eigens entwickelten Titan-Chips bietet eine überprüfbare Hardware-Root-of-Trust-Komponente und Zero-Trust-Sicherheit. Eine unabhängige Analyse von cloudvulndb.org zeigt, dass unsere Systeme bis zu 70% weniger kritische Sicherheitslücken aufweisen als andere führende Clouds.
Unterstützt die weltweit führenden Innovatoren










Weitere Informationen zum AI Hypercomputer
- IDC: Business Value of AI HypercomputerIn diesem IDC-Bericht wird der tatsächliche Kundennutzen von AI Hypercomputer für KI-Arbeitslasten untersucht. Im vollständigen Bericht finden Sie Kundendaten, die eine ROI-Verbesserung von 353 %, 55% effizientere IT-Teams und 67% weniger ungeplante Ausfallzeiten bei Anwendungen/Arbeitslasten belegen.
Lesezeit: 5 Minuten
Bericht lesen - Google wird im Gartner® Magic Quadrant for Strategic Cloud Platform Services als einer der führenden Anbieter eingestuftZum achten Mal in Folge hat Gartner® Google im Gartner-Bericht „Magic Quadrant™ for Strategic Cloud Platform Services“ unter den führenden Anbietern genannt. Dieses Jahr hat Google jedoch einen wichtigen Meilenstein erreicht: Das Unternehmen wird nun als Vorreiter in Sachen umfassende Vision unter allen Anbietern eingestuft.
Lesezeit: 5 Minuten
Ergebnisse aufrufen - Google wurde im Bericht „The Forrester Wave™: AI Infrastructure Solutions, Q4 2025“ als einer der führenden Anbieter eingestuftGoogle erhielt die höchste Punktzahl aller Anbieter in der Kategorie „Aktuelles Angebot“ und die höchstmögliche Punktzahl in 16 von 19 Bewertungskriterien, darunter: Vision, Architektur, Training, Inferenz, Effizienz und Sicherheit.
Lesezeit: 5 Minuten
Ergebnisse aufrufen
- Ersten Inferenz-Stack entwerfen und bereitstellenSie lernen die wichtigsten Komponenten einer Inferenzlösung in Google Cloud kennen, darunter GKE, Cloud TPUs, TensorFlow, PyTorch, JAX und Keras.
2-stündiger Kurs
Am Kurs teilnehmen - vLLM in GKE verwenden, um die Inferenz von Gemma 3 27B bereitzustellenIn dieser Anleitung wird gezeigt, wie Sie ein Gemma 3 27B-LLM (Large Language Model) mit dem vLLM-Bereitstellungs-Framework bereitstellen und verfügbar machen. Sie stellen Gemma 3 auf einer einzelnen virtuellen A4-Maschine (VM) in Google Kubernetes Engine (GKE) bereit.
15-Minuten-Anleitung
Anleitung lesen - Gemma 3 in einem A4-GKE-Cluster abstimmenIn dieser Anleitung wird beschrieben, wie Sie ein Gemma 3-LLM (Large Language Model) in einem GKE-Cluster mit mehreren Knoten und mehreren GPUs in Google Cloud abstimmen. Dieser Cluster verwendet eine virtuelle A4-Maschine (VM) mit 8 NVIDIA B200-GPUs.
15-Minuten-Anleitung
Anleitung lesen
- Qwen2 in einem A4-Slurm-Cluster trainierenIn dieser Anleitung wird beschrieben, wie Sie ein Large Language Model (LLM) in einem Slurm-Cluster mit mehreren Knoten und mehreren GPUs in Google Cloud trainieren. Das in dieser Anleitung verwendete Modell basiert auf einem Qwen2-Modell mit 1,5 Milliarden Parametern. Der Slurm-Cluster verwendet zwei virtuelle Maschinen (VMs) vom Typ „a4-highgpu-8g“, die jeweils 8 NVIDIA B200-GPUs haben.
15-Minuten-Anleitung
Anleitung lesen - Qwen2-7B-Instruct mit vLLM auf TPUs bereitstellenIn dieser Anleitung wird das Modell Qwen/Qwen2-7B-Instruct mit dem vLLM TPU-Bereitstellungs-Framework auf einer v6e TPU-VM bereitgestellt.
15-Minuten-Anleitung
Anleitung lesen
- WichtigHier finden Sie die gesamte verfügbare Dokumentation zu AI Hypercomputer, einschließlich Anleitungen zu Architektur, Bereitstellung, Verwaltung, Tests und Optimierung.Gesamte Dokumentation lesen
- TrainingsempfehlungenHier erfahren Sie mehr über Ihre Beschleunigungsoptionen, empfohlene Verbrauchsmodelle und Speicherdienste, die Sie beim Vortraining von Modellen verwenden können.
Lesezeit: 15 Minuten
Dokumentation lesen - Empfehlungen für InferenzHier erfahren Sie mehr über die Beschleunigeroptionen, empfohlene Nutzungsmodelle und den Speicherdienst, der für die Inferenz verwendet werden soll.
Lesezeit: 15 Minuten
Dokumentation lesen
Analystenmeinungen
- IDC: Business Value of AI HypercomputerIn diesem IDC-Bericht wird der tatsächliche Kundennutzen von AI Hypercomputer für KI-Arbeitslasten untersucht. Im vollständigen Bericht finden Sie Kundendaten, die eine ROI-Verbesserung von 353 %, 55% effizientere IT-Teams und 67% weniger ungeplante Ausfallzeiten bei Anwendungen/Arbeitslasten belegen.
Lesezeit: 5 Minuten
Bericht lesen - Google wird im Gartner® Magic Quadrant for Strategic Cloud Platform Services als einer der führenden Anbieter eingestuftZum achten Mal in Folge hat Gartner® Google im Gartner-Bericht „Magic Quadrant™ for Strategic Cloud Platform Services“ unter den führenden Anbietern genannt. Dieses Jahr hat Google jedoch einen wichtigen Meilenstein erreicht: Das Unternehmen wird nun als Vorreiter in Sachen umfassende Vision unter allen Anbietern eingestuft.
Lesezeit: 5 Minuten
Ergebnisse aufrufen - Google wurde im Bericht „The Forrester Wave™: AI Infrastructure Solutions, Q4 2025“ als einer der führenden Anbieter eingestuftGoogle erhielt die höchste Punktzahl aller Anbieter in der Kategorie „Aktuelles Angebot“ und die höchstmögliche Punktzahl in 16 von 19 Bewertungskriterien, darunter: Vision, Architektur, Training, Inferenz, Effizienz und Sicherheit.
Lesezeit: 5 Minuten
Ergebnisse aufrufen
Anleitungen
- Ersten Inferenz-Stack entwerfen und bereitstellenSie lernen die wichtigsten Komponenten einer Inferenzlösung in Google Cloud kennen, darunter GKE, Cloud TPUs, TensorFlow, PyTorch, JAX und Keras.
2-stündiger Kurs
Am Kurs teilnehmen - vLLM in GKE verwenden, um die Inferenz von Gemma 3 27B bereitzustellenIn dieser Anleitung wird gezeigt, wie Sie ein Gemma 3 27B-LLM (Large Language Model) mit dem vLLM-Bereitstellungs-Framework bereitstellen und verfügbar machen. Sie stellen Gemma 3 auf einer einzelnen virtuellen A4-Maschine (VM) in Google Kubernetes Engine (GKE) bereit.
15-Minuten-Anleitung
Anleitung lesen - Gemma 3 in einem A4-GKE-Cluster abstimmenIn dieser Anleitung wird beschrieben, wie Sie ein Gemma 3-LLM (Large Language Model) in einem GKE-Cluster mit mehreren Knoten und mehreren GPUs in Google Cloud abstimmen. Dieser Cluster verwendet eine virtuelle A4-Maschine (VM) mit 8 NVIDIA B200-GPUs.
15-Minuten-Anleitung
Anleitung lesen
- Qwen2 in einem A4-Slurm-Cluster trainierenIn dieser Anleitung wird beschrieben, wie Sie ein Large Language Model (LLM) in einem Slurm-Cluster mit mehreren Knoten und mehreren GPUs in Google Cloud trainieren. Das in dieser Anleitung verwendete Modell basiert auf einem Qwen2-Modell mit 1,5 Milliarden Parametern. Der Slurm-Cluster verwendet zwei virtuelle Maschinen (VMs) vom Typ „a4-highgpu-8g“, die jeweils 8 NVIDIA B200-GPUs haben.
15-Minuten-Anleitung
Anleitung lesen - Qwen2-7B-Instruct mit vLLM auf TPUs bereitstellenIn dieser Anleitung wird das Modell Qwen/Qwen2-7B-Instruct mit dem vLLM TPU-Bereitstellungs-Framework auf einer v6e TPU-VM bereitgestellt.
15-Minuten-Anleitung
Anleitung lesen
Dokumentation
- WichtigHier finden Sie die gesamte verfügbare Dokumentation zu AI Hypercomputer, einschließlich Anleitungen zu Architektur, Bereitstellung, Verwaltung, Tests und Optimierung.Gesamte Dokumentation lesen
- TrainingsempfehlungenHier erfahren Sie mehr über Ihre Beschleunigungsoptionen, empfohlene Verbrauchsmodelle und Speicherdienste, die Sie beim Vortraining von Modellen verwenden können.
Lesezeit: 15 Minuten
Dokumentation lesen - Empfehlungen für InferenzHier erfahren Sie mehr über die Beschleunigeroptionen, empfohlene Nutzungsmodelle und den Speicherdienst, der für die Inferenz verwendet werden soll.
Lesezeit: 15 Minuten
Dokumentation lesen



















