This page describes how Cloud TPU works with Google Kubernetes Engine (GKE), including terminology, the benefits of Tensor Processing Units (TPUs), and workload scheduling considerations. TPUs are Google's custom-developed, application-specific integrated circuits (ASICs) for accelerating ML workloads that use frameworks such as TensorFlow, PyTorch, and JAX.
This page is for Platform admins and operators and Data and AI specialists who run machine learning (ML) models that have characteristics such as being large-scale, long-running, or dominated by matrix computations. To learn more about common roles and example tasks that we reference in Google Cloud content, see Common GKE user roles and tasks.
Before reading this page, ensure that you're familiar with how ML accelerators work. For details, see Introduction to Cloud TPU.
Benefits of using TPUs in GKE
GKE provides full support for TPU node and node pool lifecycle management, including creating, configuring, and deleting TPU VMs. GKE also supports Spot VMs and using reserved Cloud TPU. For more information, see Cloud TPU consumption options.
Benefits of using TPUs in GKE include:
- Consistent operational environment: You can use a single platform for all machine learning and other workloads.
- Automatic upgrades: GKE automates version updates, which reduces operational overhead.
- Load balancing: GKE distributes the load, thus reducing latency and improving reliability.
- Responsive scaling: GKE automatically scales TPU resources to meet the needs of your workloads.
- Resource management: With Kueue, a Kubernetes-native job queuing system, you can manage resources across multiple tenants within your organization using queuing, preemption, prioritization, and fair sharing.
- Sandboxing options: GKE Sandbox helps to protect your workloads with gVisor. For more information, see GKE Sandbox.
Benefits of using TPU Trillium
Trillium is Google's sixth-generation TPU. Trillium has the following benefits:
- Trillium increases compute performance per chip compared to TPU v5e.
- Trillium increases the High Bandwidth Memory (HBM) capacity and bandwidth, and also increases the Interchip Interconnect (ICI) bandwidth over TPU v5e.
- Trillium is equipped with third-generation SparseCore, a specialized accelerator for processing ultra-large embeddings common in advanced ranking and recommendation workloads.
- Trillium is over 67% more energy-efficient than TPU v5e.
- Trillium can scale up to 256 TPUs in a single high-bandwidth, low-latency TPU slice.
- Trillium supports collection scheduling. Collection scheduling lets you declare a group of TPUs (single-host and multi-host TPU slice node pools) to ensure high availability for the demands of your inference workloads.
On all technical surfaces like APIs and logs, and in specific parts of the
GKE documentation, we use v6e or TPU Trillium (v6e) to refer
to Trillium TPUs. To learn more about the benefits of Trillium, read the
Trillium announcement blog post. To
start your TPU setup, see Plan TPUs in GKE.
Terminology related to TPUs in GKE
This page uses the following terminology related to TPUs:
- TPU type: the Cloud TPU type, like v5e.
- TPU slice node: a Kubernetes node represented by a single VM that has one or more interconnected TPU chips.
- TPU slice node pool: a group of Kubernetes nodes within a cluster that all have the same TPU configuration.
- TPU topology: the number and physical arrangement of the TPU chips in a TPU slice.
- Atomic: GKE treats all the interconnected nodes as a single unit. During scaling operations, GKE scales the entire set of nodes to 0 and creates new nodes. If a machine in the group fails or terminates, GKE recreates the entire set of nodes as a new unit.
- Immutable: you can't manually add new nodes to the set of interconnected nodes. However, you can create a new node pool that has the TPU topology that you want and schedule workloads on the new node pool.
Types of TPU slice node pools
GKE supports two types of TPU node pools:
The TPU type and topology determine whether your TPU slice node can be multi-host or single-host. We recommend:
- For large-scale models, use multi-host TPU slice nodes.
- For small-scale models, use single-host TPU slice nodes.
- For large-scale training or inferencing, use Pathways. Pathways simplifies large-scale machine learning computations by enabling a single JAX client to orchestrate workloads across multiple large TPU slices. For more information, see Pathways.
Multi-host TPU slice node pools
A multi-host TPU slice node pool is a node pool that contains two or more
interconnected TPU VMs. Each VM has a TPU device connected to it. The TPUs in
a multi-host TPU slice are connected over a high speed interconnect (ICI). After
a multi-host TPU slice node pool is created, you can't add nodes to it. For
example, you can't create a v4-32
node pool and then later add a Kubernetes node (TPU VM) to the node pool. To add
a TPU slice to a GKE cluster, you must create a new node pool.
The VMs in a multi-host TPU slice node pool are treated as a single atomic unit. If GKE is unable to deploy one node in the slice, no nodes in the TPU slice node are deployed.
If a node within a multi-host TPU slice requires repairing, GKE shuts down all VMs in the TPU slice, forcing eviction of all the Kubernetes Pods in the workload. After all VMs in the TPU slice are up and running, the Kubernetes Pods can be scheduled on the VMs in the new TPU slice.
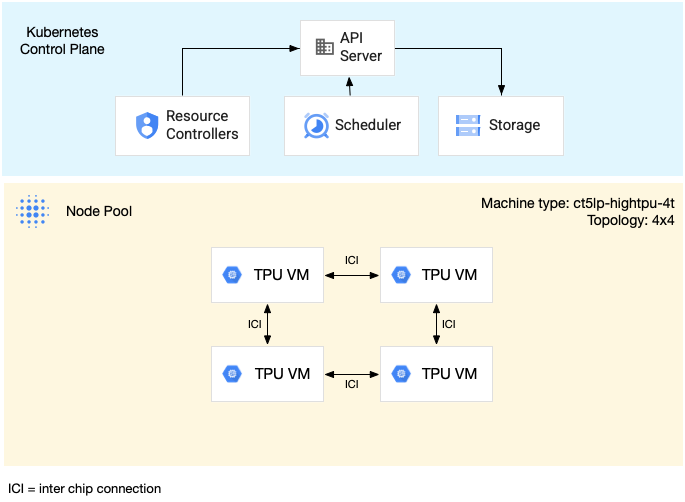
The following diagram shows a v5litepod-16 (v5e) multi-host TPU slice. This
TPU slice has four VMs. Each VM in the TPU slice has four TPU v5e chips
connected with high-speed interconnects (ICI), and each TPU v5e chip has one
TensorCore:
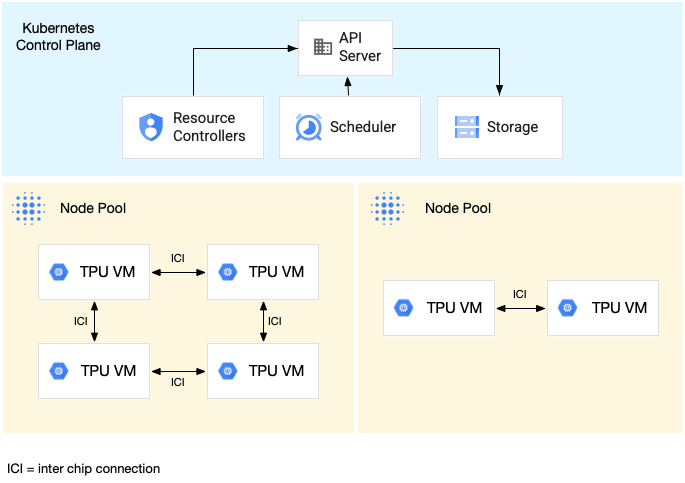
The following diagram shows a GKE cluster that contains one TPU
v5litepod-16 (v5e) TPU slice (topology: 4x4) and one TPU v5litepod-8 (v5e)
slice (topology: 2x4):
Single-host TPU slice node pools
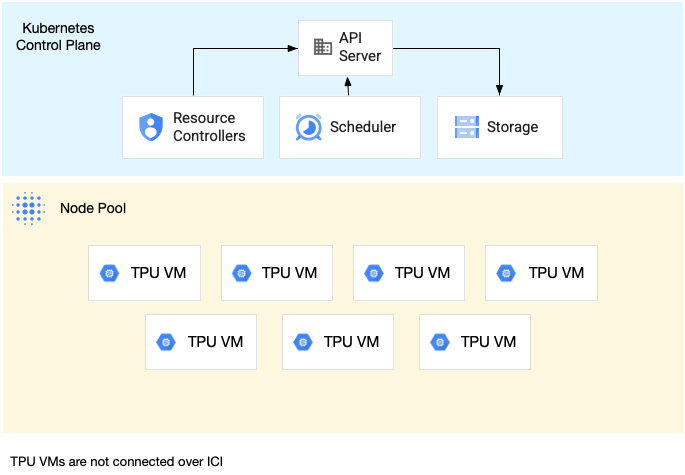
A single-host slice node pool is a node pool that contains one or more independent TPU VMs. Each VM has a TPU device connected to it. While the VMs within a single-host slice node pool can communicate over the Data Center Network (DCN), the TPUs attached to the VMs are not interconnected.
The following diagram shows an example of a single-host TPU slice that contains
seven v4-8 machines:
Characteristics of TPUs in GKE
TPUs have unique characteristics that require special planning and configuration.
TPU consumption
To optimize resource utilization and cost while balancing workload performance, GKE supports the following TPU consumption options:
- Flex-start: to secure resources for up to seven days, with GKE automatically allocating the hardware on a best-effort basis based on availability. For more information, see About GPU and TPU provisioning with flex-start provisioning mode.
- Spot VMs: to provision Spot VMs, you can get significant discounts, but Spot VMs can be preempted at any time, with a 30-second warning. For more information, see Spot VMs.
- Future reservation for up to 90 days (in calendar mode): to provision TPU resources for up to 90 days, for a specified time period. For more information, see Request TPUs with future reservation in calendar mode.
- TPU reservations: to request a future reservation for one year or longer.
To choose the consumption option that meets your workload requirements, see About accelerator consumption options for AI/ML workloads in GKE.
Before using TPUs in GKE, choose the consumption option that best fits your workload requirements.
Topology
The topology defines the physical arrangement of TPUs within a TPU slice. GKE provisions a TPU slice in two- or three-dimensional topologies, depending on the TPU version. You specify a topology as the number of TPU chips in each dimension as follows:
For TPU v4 and v5p scheduled in multi-host TPU slice node pools, you define the
topology in 3-tuples ({A}x{B}x{C}), for example 4x4x4. The product of
{A}x{B}x{C} defines the number of TPU chips in the node pool. For example, you
can define small topologies that have fewer than 64 TPU chips with topology
forms such as 2x2x2, 2x2x4, or 2x4x4. If you use larger topologies that
have more than 64 TPU chips, the values you assign to {A}, {B}, and {C} must
meet the following conditions:
- {A}, {B}, and {C} must be multiples of four.
- The largest topology supported for v4 is
12x16x16and v5p is16x16x24. - The assigned values must keep the A ≤ B ≤ C
pattern. For example,
4x4x8or8x8x8.
Machine type
Machine types that support TPU resources follow a naming convention that
includes the TPU version and the number of TPU chips per node slice, such as
ct<version>-hightpu-<node-chip-count>t. For example, the machine type
ct5lp-hightpu-1t supports TPU v5e and contains just one TPU chip.
Privileged mode
If you use GKE versions earlier than 1.28, you must configure
your containers with special capabilities to access TPUs. In Standard
mode clusters, you can use privileged mode to grant this access. Privileged mode
overrides many of the other security settings in the securityContext. For
details, see Run containers without privileged mode.
Versions 1.28 and later don't require privileged mode or special capabilities.
How TPUs in GKE work
Kubernetes resource management and prioritization treat VMs on TPUs the same as
other VM types. To request TPU chips, use the resource name google.com/tpu:
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
When using TPUs in GKE, consider the following TPU characteristics:
- A VM can access up to 8 TPU chips.
- A TPU slice contains a fixed number of TPU chips, with the number depending on the TPU machine type that you choose.
- The number of requested
google.com/tpumust be equal to the total number of available TPU chips on the TPU slice node. Any container in a GKE Pod that requests TPUs must consume all the TPU chips in the node. Otherwise, your Deployment fails because GKE can't partially consume TPU resources. Consider the following scenarios:- The machine type
ct5lp-hightpu-4twith a2x4topology contains two TPU slice nodes with four TPU chips each, for a total of eight TPU chips. With this machine type, you: - Can't deploy a GKE Pod that requires eight TPU chips on the nodes in this node pool.
- Can deploy two Pods that require four TPU chips each, each Pod on one of the two nodes in this node pool.
- TPU v5e with topology 4x4 has 16 TPU chips in four nodes. The GKE Autopilot workload that selects this configuration must request four TPU chips in each replica, for one to four replicas.
- The machine type
- In Standard clusters, multiple Kubernetes Pods can be scheduled on a VM, but only one container in each Pod can access the TPU chips.
- To create kube-system Pods, such as kube-dns, each Standard cluster must have at least one non-TPU slice node pool.
- By default, TPU slice nodes have the
google.com/tputaint which prevents non-TPU workloads from being scheduled on the TPU slice nodes. Workloads that don't use TPUs are run on non-TPU nodes, freeing up compute on TPU slice nodes for code that uses TPUs. Note that the taint does not guarantee that TPU resources are fully utilized. - GKE collects the logs emitted by containers running on TPU slice nodes. To learn more, see Logging.
- TPU utilization metrics, such as runtime performance, are available in Cloud Monitoring. To learn more, see Observability and metrics.
- You can sandbox your TPU workloads with GKE Sandbox. GKE Sandbox works with TPU models v4 and later. To learn more, see GKE Sandbox.
How collection scheduling works
In TPU Trillium, you can use collection scheduling to group TPU slice nodes. Grouping these TPU slice nodes makes it easier to adjust the number of replicas to meet the workload demand. Google Cloud controls software updates to ensure that sufficient slices within the collection are always available to serve traffic.
TPU Trillium supports collection scheduling for single-host and multi-host node pools that run inference workloads. The following describes how collection scheduling behavior depends on the type of TPU slice that you use:
- Multi-host TPU slice: GKE groups multi-host TPU slices to form a collection. Each GKE node pool is a replica within this collection. To define a collection, create a multi-host TPU slice and assign a unique name to the collection. To add more TPU slices to the collection, create another multi-host TPU slice node pool with the same collection name and workload type.
- Single-host TPU slice: GKE considers the entire single-host TPU slice node pool as a collection. To add more TPU slices to the collection, you can resize the single-host TPU slice node pool.
Collection scheduling has the following limitations:
- You can only schedule collections for TPU Trillium.
- You can define collections only during node pool creation.
- Spot VMs are not supported.
- Collections that contain multi-host TPU slice node pools must use the same machine type, topology, and version for all node pools within the collection.
You can configure collection scheduling in the following scenarios:
- When creating a TPU slice node pool in GKE Standard
- When deploying workloads on GKE Autopilot
- When creating a cluster that enables node auto-provisioning
What's next
To learn how to set up Cloud TPU in GKE, see the following pages:
- Plan TPUs in GKE to start your TPU setup
- Deploy TPU workloads in GKE Autopilot
- Deploy TPU workloads in GKE Standard
- Learn about best practices for using Cloud TPU for your ML tasks
- Video: Build large-scale machine learning on Cloud TPU with GKE
- Serve Large Language Models with KubeRay on TPUs
- Learn about Sandboxing GPU workloads with GKE Sandbox