En este documento, se describe cómo configurar el recopilador de OpenTelemetry para recopilar métricas estándar de Prometheus y, luego, informarlas a Google Cloud Managed Service para Prometheus. El recopilador de OpenTelemetry es un agente que puedes implementar tú mismo y configurar para exportar al servicio administrado para Prometheus. La configuración es similar a la ejecución de Managed Service para Prometheus con la recopilación implementada de forma automática.
Puedes elegir el recopilador de OpenTelemetry en lugar de la recopilación autoimplementada por los siguientes motivos:
- El recopilador de OpenTelemetry te permite enrutar tus datos de telemetría a varios backends configurando diferentes exportadores en tu canalización.
- El recopilador también admite señales de métricas, registros y seguimientos, por lo que, cuando lo usas, puedes controlar los tres tipos de señales en un agente.
- El formato de datos independiente del proveedor de OpenTelemetry (el protocolo de OpenTelemetry o OTLP) es compatible con un ecosistema sólido de bibliotecas y componentes de recopilador conectables. Esto permite una variedad de opciones de personalización para recibir, procesar y exportar tus datos.
La ventaja relativa de estos beneficios es que ejecutar un recopilador de OpenTelemetry requiere un enfoque de implementación y mantenimiento autoadministrado. El enfoque que elijas dependerá de tus necesidades específicas, pero en este documento, ofrecemos lineamientos recomendados para configurar el recopilador de OpenTelemetry con el servicio administrado para Prometheus como backend.
Antes de comenzar
En esta sección, se describe la configuración necesaria para las tareas descritas en este documento.
Configura proyectos y herramientas
Si deseas usar Google Cloud Managed Service para Prometheus, necesitas los siguientes recursos:
Un Google Cloud proyecto con la API de Cloud Monitoring habilitada
Si no tienes un Google Cloud proyecto, haz lo siguiente:
En la consola de Google Cloud , ve a Proyecto nuevo:
En el campo Nombre del proyecto, ingresa un nombre para tu proyecto y, luego, haz clic en Crear.
Ve a facturación:
Selecciona el proyecto que acabas de crear si aún no está seleccionado en la parte superior de la página.
Se te solicitará que elijas un perfil de pagos existente o que crees uno nuevo.
La API de Monitoring está habilitada de forma predeterminada para proyectos nuevos.
Si ya tienes un proyecto Google Cloud , asegúrate de que la API de Monitoring esté habilitada:
Ve a API y servicios:
Selecciona tu proyecto.
Haga clic en Habilitar API y servicios.
Busca “Monitoring”.
En los resultados de la búsqueda, haz clic en "API de Cloud Monitoring".
Si no se muestra "API habilitada", haz clic en el botón Habilitar.
Un clúster de Kubernetes. Si no tienes un clúster de Kubernetes, sigue las instrucciones en la Guía de inicio rápido para GKE.
También necesitas las siguientes herramientas de línea de comandos:
gcloudkubectl
Las herramientas gcloud y kubectl forman parte de la CLI de Google Cloud. Para obtener información sobre cómo instalarlos, consulta Administra los componentes de la CLI de Google Cloud. Para ver los componentes de la CLI de gcloud que instalaste, ejecuta el siguiente comando:
gcloud components list
Configura tu entorno
Para evitar ingresar repetidamente el ID del proyecto o el nombre del clúster, realiza la siguiente configuración:
Configura las herramientas de línea de comandos como se indica a continuación:
Configura gcloud CLI para hacer referencia al ID de tu proyecto deGoogle Cloud :
gcloud config set project PROJECT_ID
Configura la CLI de
kubectlpara usar tu clúster:kubectl config set-cluster CLUSTER_NAME
Para obtener más información sobre estas herramientas, consulta lo siguiente:
Configura un espacio de nombres
Crea el espacio de nombres NAMESPACE_NAME de Kubernetes para los recursos que crees como parte de la aplicación de ejemplo:
kubectl create ns NAMESPACE_NAME
Verifica las credenciales de la cuenta de servicio
Si tu clúster de Kubernetes tiene habilitada la federación de identidades para cargas de trabajo para GKE, puedes omitir esta sección.
Cuando se ejecuta en GKE, el servicio administrado para Prometheus recupera credenciales de forma automática del entorno en función de la cuenta de servicio predeterminada de Compute Engine. La cuenta de servicio predeterminada tiene los permisos necesarios, monitoring.metricWriter y monitoring.viewer, de forma predeterminada. Si no usas Workload Identity Federation for GKE y ya quitaste cualquiera de esos roles de la cuenta de servicio de nodo predeterminada, tendrás que volver a agregar esos permisos faltantes antes de continuar.
Configura una cuenta de servicio para Workload Identity Federation for GKE
Si tu clúster de Kubernetes no tiene habilitada la federación de identidades para cargas de trabajo para GKE, puedes omitir esta sección.
El servicio administrado para Prometheus captura datos de métricas mediante la API de Cloud Monitoring. Si tu clúster usa Workload Identity Federation for GKE, debes otorgar permiso a tu cuenta de servicio de Kubernetes a la API de Monitoring. En esta sección, se describe lo siguiente:
- Crea una Google Cloud cuenta de servicio dedicada,
gmp-test-sa. - Vincula la cuenta de servicio Google Cloud a la cuenta de servicio de Kubernetes predeterminada en un espacio de nombres de prueba,
NAMESPACE_NAME. - Otorgar el permiso necesario a la cuenta de servicio de Google Cloud
Crea y vincula la cuenta de servicio
Este paso aparece en varios lugares en la documentación del servicio administrado para Prometheus. Si ya realizaste este paso como parte de una tarea anterior, no es necesario que lo repitas. Ve a la sección Autoriza la cuenta de servicio.
Con la siguiente secuencia de comandos, se crea la cuenta de servicio gmp-test-sa y se la vincula a la cuenta de servicio de Kubernetes predeterminada en el espacio de nombres NAMESPACE_NAME:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Si usas un espacio de nombres o una cuenta de servicio de GKE diferentes, ajusta los comandos de forma adecuada.
Autoriza la cuenta de servicio
Los grupos de permisos relacionados se recopilan en roles y se otorgan los roles a una principal, en este ejemplo, la cuenta de servicio de Google Cloud. Para obtener más información sobre las funciones de Monitoring, consulta Control de acceso.
Con el siguiente comando, se otorga a la cuenta de servicio Google Cloud ,gmp-test-sa, las funciones de la API de Monitoring que necesita para escribir datos de métricas.
Si ya otorgaste a la cuenta de servicio Google Cloud un rol específico como parte de la tarea anterior, no necesitas volver a hacerlo.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Depura la configuración de Workload Identity Federation for GKE
Si tienes problemas para lograr que Workload Identity Federation for GKE funcione, consulta la documentación para verificar la configuración de Workload Identity Federation for GKE y la Guía de solución de problemas de la federación de Workload Identity Federation for GKE.
Como los errores tipográficos y de copia parcial son las fuentes de errores más comunes en la configuración de Workload Identity Federation for GKE, recomendamos usar las variables editables y los íconos de copiar y pegar en los que se puede hacer clic incorporados en las muestras de código de estas instrucciones.
Workload Identity Federation for GKE en entornos de producción
En el ejemplo descrito en este documento, se vincula la cuenta de servicio Google Cloud a la cuenta de servicio de Kubernetes predeterminada y se le otorga a la cuenta de servicio Google Cloudtodos los permisos necesarios para usar la API de Monitoring.
En un entorno de producción, se recomienda usar un enfoque más detallado, con una cuenta de servicio para cada componente, cada una con permisos mínimos. Si deseas obtener más información sobre la configuración de cuentas de servicio para la administración de Workload Identity, consulta Usa Workload Identity Federation for GKE.
Configura el recopilador de OpenTelemetry
En esta sección, se explica cómo configurar y usar el recopilador de OpenTelemetry para recopilar métricas de una aplicación de ejemplo y enviar los datos a Google Cloud Managed Service para Prometheus. Para obtener información detallada sobre la configuración, consulta las siguientes secciones:
El recopilador de OpenTelemetry es análogo al objeto binario del agente de Managed Service para Prometheus. La comunidad de OpenTelemetry publica versiones con regularidad, que incluyen el código fuente, los objetos binarios y las imágenes de contenedor.
Puedes implementar estos artefactos en VMs o clústeres de Kubernetes mediante las prácticas recomendadas predeterminadas o puedes usar el compilador de recopilador para compilar tu propio recopilador que consiste solo en un componentes que necesitas. Para compilar un recopilador para usar con el Servicio administrado para Prometheus, necesitas los siguientes componentes:
- El exportador de Managed Service para Prometheus, que escribe tus métricas en Managed Service para Prometheus.
- Un receptor para recopilar tus métricas. En este documento, se supone que usas el receptor de OpenTelemetry o Prometheus, pero el exportador de Managed Service para Prometheus es compatible con cualquier receptor de métricas de OpenTelemetry.
- Procesadores para agrupar por lotes y marcar tus métricas para incluir identificadores de recursos importantes según tu entorno.
Estos componentes se habilitan mediante un archivo de configuración que se pasa al recopilador con la marca --config.
En las siguientes secciones, se analiza cómo configurar cada uno de estos componentes con más detalle. En este documento, se describe cómo ejecutar el recopilador en GKE y en otro lugar.
Configura e implementa el recopilador
Ya sea que ejecutes tu recopilación en Google Cloud o en otro entorno, aún puedes configurar el recopilador de OpenTelemetry para exportar al servicio administrado para Prometheus. La mayor diferencia estará en cómo configurar el recopilador. En entornos que no son deGoogle Cloud , puede haber un formato adicional de los datos de métricas que se necesita a fin de que sean compatibles con Managed Service para Prometheus. Sin embargo, en Google Cloud, el recopilador puede detectar automáticamente gran parte de este formato.
Ejecuta el recopilador de OpenTelemetry en GKE
Puedes copiar la siguiente configuración en un archivo llamado config.yaml para configurar el recopilador de OpenTelemetry en GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
La configuración anterior usa el receptor de Prometheus y el exportador de servicios administrados para Prometheus a fin de recopilar los extremos de las métricas en los Pods de Kubernetes y exportaresas métricas a Managed Service para Prometheus. Los procesadores de canalizaciones formatean y agrupan los datos por lotes.
Para obtener más detalles sobre lo que hace cada parte de esta configuración, junto con las opciones de configuración de diferentes plataformas, consulta las siguientes secciones detalladas sobre recopilar métricas y agregar procesadores.
Cuando uses una configuración de Prometheus existente con el receptor prometheus del colector de OpenTelemetry, reemplaza cualquier carácter de signo de dólar único, 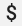 , por caracteres dobles,
, por caracteres dobles, 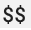 , para evitar activar la sustitución de variable de entorno. Para obtener más información, consulta Recopila métricas de Prometheus.
, para evitar activar la sustitución de variable de entorno. Para obtener más información, consulta Recopila métricas de Prometheus.
Puedes modificar esta configuración según tu entorno, proveedor y las métricas que desees extraer, pero la configuración de ejemplo es un punto de partida recomendado para ejecutar en GKE.
Ejecuta el recopilador de OpenTelemetry fuera de Google Cloud
Ejecutar el recopilador de OpenTelemetry fuera de Google Cloud, como local o en otros proveedores de servicios en la nube, es similar a ejecutar el recopilador en GKE. Sin embargo, es menos probable que las métricas que recopilas incluyan de forma automática los datos que mejor los formatean para Managed Service para Prometheus. Por lo tanto, debes tener especial cuidado a fin de configurar el recopilador para formatear las métricas a fin de que sean compatibles con el servicio administrado para Prometheus.
Puedes copiar la siguiente configuración en un archivo llamado config.yaml para configurar el recopilador de OpenTelemetry para la implementación en un clúster de Kubernetes que no sea de GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
Esta configuración hace lo siguiente:
- Configura una configuración de copia de Kubernetes Service Discovery para Prometheus. Para obtener más información, consulta cómo recopilar métricas de Prometheus.
- Establece manualmente los atributos de recursos
cluster,namespaceylocation. Para obtener más información sobre los atributos de recursos, incluida la detección de recursos para Amazon EKS y Azure AKS, consulta Cómo detectar atributos de recursos. - Establece la opción
projecten el exportadorgooglemanagedprometheus. Para obtener más información sobre el exportador, consulta Configura el exportador degooglemanagedprometheus.
Cuando uses una configuración de Prometheus existente con el receptor prometheus del colector de OpenTelemetry, reemplaza cualquier carácter de signo de dólar único, , por caracteres dobles, , para evitar activar la sustitución de variable de entorno. Para obtener más información, consulta Recopila métricas de Prometheus.
Si deseas obtener información sobre las prácticas recomendadas para configurar el recopilador en otras nubes, consulta Amazon EKS o Azure AKS.
Implementa la aplicación de ejemplo
La aplicación de ejemplo emite la métrica de contador example_requests_total y la métrica de histograma example_random_numbers (entre otras) en su puerto metrics.
El manifiesto para este ejemplo define tres réplicas
Para implementar la aplicación de ejemplo, ejecuta el siguiente comando:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Crea tu configuración de recopilador como un ConfigMap
Después de crear tu configuración y colocarla en un archivo llamado config.yaml, usa ese archivo para crear un ConfigMap de Kubernetes basado en tu archivo config.yaml.
Cuando se implementa el recopilador, se activa el ConfigMap y carga el archivo.
Para crear un ConfigMap llamado otel-config con tu configuración, usa el siguiente comando:
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
Implementa el recopilador
Crea un archivo llamado collector-deployment.yaml con el siguiente contenido.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
Para crear la implementación del recopilador en tu clúster de Kubernetes, ejecuta el siguiente comando:
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
Una vez que se inicia el Pod, se recopilan la aplicación de ejemplo y genera informes de las métricas del servicio administrado de Prometheus.
Si deseas obtener información sobre cómo consultar tus datos, visita Consulta mediante Cloud Monitoring o Consulta mediante Grafana.
Proporciona credenciales de forma explícita
Cuando se ejecuta en GKE, el recopilador de OpenTelemetry recupera de forma automática las credenciales del entorno en función de la cuenta de servicio del nodo.
En clústeres de Kubernetes que no son de GKE, las credenciales deben proporcionarse de forma explícita al Recopilador de OpenTelemetry mediante marcas o la variable de entorno GOOGLE_APPLICATION_CREDENTIALS.
Configura el contexto en tu proyecto de destino:
gcloud config set project PROJECT_ID
Crear una cuenta de servicio:
gcloud iam service-accounts create gmp-test-sa
En este paso, se crea la cuenta de servicio que puedes haber creado ya en las instrucciones de Workload Identity Federation for GKE.
Otorga permisos obligatorios a la cuenta de servicio:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Crea y descarga una clave para la cuenta de servicio:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Agrega el archivo de claves como un secreto a tu clúster que no es de GKE:
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Abre el recurso de implementación de OpenTelemetry para editarlo:
kubectl -n NAMESPACE_NAME edit deployment otel-collector
Agrega el texto que se muestra en negrita al recurso:
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...Guarda el archivo y cierra el editor. Después de aplicar el cambio, los Pods se vuelven a crear y comienzan a autenticarse en el backend de la métrica con la cuenta de servicio determinada.
Recopila métricas de Prometheus
En esta sección y la posterior, se proporciona información de personalización adicional para usar el recopilador de OpenTelemetry. Esta información puede ser útil en ciertas situaciones, pero ninguna es necesaria para ejecutar el ejemplo descrito en Configura el recopilador de OpenTelemetry.
Si tus aplicaciones ya exponen extremos de Prometheus, el recopilador de OpenTelemetry puede recopilar esos extremos con el mismo formato de configuración de scraping que usarías con cualquier configuración estándar de Prometheus. Para ello, habilita el receptor de Prometheus en la configuración de recopilador.
Una configuración del receptor de Prometheus para los Pods de Kubernetes podría tener el siguiente aspecto:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
Esta es una configuración de scraping basada en el descubrimiento de servicios que puedes modificar según sea necesario para recopilar tus aplicaciones.
Cuando uses una configuración de Prometheus existente con el receptor prometheus del colector de OpenTelemetry, reemplaza cualquier carácter de signo de dólar único, , por caracteres dobles, , para evitar activar la sustitución de variable de entorno. Esto es especialmente importante para el valor replacement dentro de la sección relabel_configs. Por ejemplo, si tienes la siguiente sección relabel_config:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
Luego, reescríbela de la siguiente manera:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
Para obtener más información, consulta la documentación de OpenTelemetry.
A continuación, te recomendamos que uses procesadores para dar formato a tus métricas. En muchos casos, se deben usar procesadores para dar formato correctamente a tus métricas.
Agrega procesadores
Los procesadores de OpenTelemetry modifican los datos de telemetría antes de que se exporten. Puedes usar los siguientes procesadores para asegurarte de que tus métricas se escriban en un formato compatible con Managed Service para Prometheus.
Detecta atributos de recursos
El exportador del Servicio administrado para Prometheus para OpenTelemetry usa el recurso supervisado prometheus_target a fin de identificar de manera inquívoca los datos de series temporales. El exportador analiza los campos de recursos supervisados requeridos a partir de los atributos de recursos en los puntos de datos de la métrica.
Los campos y los atributos de los que se extraen los valores son los siguientes:
- project_id: detectado de forma automática mediante credenciales predeterminadas de la aplicación,
gcp.project.idoprojecten la configuración del exportador (consulta Configura el exportador) - ubicación:
location,cloud.availability_zone,cloud.region - clúster:
cluster,k8s.cluster_name - espacio de nombres:
namespace,k8s.namespace_name - job:
service.name+service.namespace - instancia :
service.instance.id
Si no se configuran estas etiquetas en valores únicos, se pueden generar errores de “serie temporal duplicada” cuando se exporta a Managed Service para Prometheus. En muchos casos, los valores se pueden detectar automáticamente para estas etiquetas, pero, en algunos casos, es posible que debas asignarlos tú mismo. En el resto de esta sección, se describen estas situaciones.
El receptor de Prometheus establece automáticamente el atributo service.name según el atributo job_name en la configuración de la recopilación y el atributo service.instance.id según el atributo instance del destino de la recopilación. El receptor también establece k8s.namespace.name cuando se usa role: pod en la configuración de scraping.
Cuando sea posible, propaga los otros atributos automáticamente con el procesador de detección de recursos. Sin embargo, según tu entorno, es posible que algunos atributos no se detecten automáticamente. En este caso, puedes usar otros procesadores para insertar estos valores de forma manual o analizarlos a partir de las etiquetas de métricas. En las siguientes secciones, se ilustran las configuraciones para detectar recursos en varias plataformas.
GKE
Cuando ejecutas OpenTelemetry en GKE, debes habilitar el procesador de detección de recursos para completar las etiquetas de recursos. Asegúrate de que tus métricas no contengan ya ninguna de las etiquetas de recursos reservadas. Si esto es inevitable, consulta Evita los conflictos de atributos de recursos cambiando el nombre de los atributos.
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
Esta sección se puede copiar directamente en tu archivo de configuración y reemplazar la sección processors si ya existe.
Amazon EKS
El detector de recursos de EKS no completa automáticamente los atributos cluster o namespace. Puedes proporcionar estos valores de forma manual con el procesador de recursos, como se muestra en el siguiente ejemplo:
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
También puedes convertir estos valores de etiquetas de métricas con el procesador groupbyattrs (consulta Mueve etiquetas de métricas a etiquetas de recursos a continuación).
Azure AKS
El detector de recursos de AKS no completa automáticamente los atributos cluster o namespace. Puedes proporcionar estos valores de forma manual con el procesador de recursos, como se muestra en el siguiente ejemplo:
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
También puedes convertir estos valores de etiquetas de métricas con el procesador groupbyattrs. Consulta Cómo mover etiquetas de métricas a etiquetas de recursos.
Entornos locales y ajenos a la nube
Con entornos locales o ajenos a la nube, es probable que no puedas detectar ninguno de los atributos de recursos necesarios de forma automática. En este caso, puedes emitir estas etiquetas en tus métricas y moverlas a atributos de recursos (consulta Mueve etiquetas de métricas a etiquetas de recursos) o configurar de forma manual todos los atributos de recursos como se muestra en el siguiente ejemplo:
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
En Crea la configuración de recopilador como un ConfigMap, se describe cómo usar la configuración. En esa sección, se supone que colocaste tu configuración en un archivo llamado config.yaml.
El atributo de recurso project_id aún se puede establecer automáticamente cuando se ejecuta el recopilador con credenciales predeterminadas de la aplicación.
Si tu recopilador no tiene acceso a las credenciales predeterminadas de la aplicación, consulta Configura project_id.
Como alternativa, puedes configurar manualmente los atributos de recursos que necesites en una variable de entorno, OTEL_RESOURCE_ATTRIBUTES, con una lista de pares clave-valor separados por comas, por ejemplo:
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
Luego, usa el procesador de detección de recursos env para establecer los atributos de recursos:
processors:
resourcedetection:
detectors: [env]
Evita los conflictos de atributos de recursos mediante el cambio de nombre de los atributos
Si tus métricas ya contienen etiquetas que entran en conflicto con los atributos de recursos obligatorios (como location, cluster o namespace), cámbiales el nombre para evitar el conflicto. La convención de Prometheus es agregar el prefijo exported_ al nombre de la etiqueta. Para agregar este prefijo, usa el procesador de transformación.
La siguiente configuración de processors cambia el nombre de cualquier posible conflicto y resuelve cualquier clave en conflicto de la métrica:
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
Mueve etiquetas de métricas a etiquetas de recursos
En algunos casos, es posible que tus métricas registren intencionalmente etiquetas como namespace porque tu exportador supervisa varios espacios de nombres. Por ejemplo, cuando se ejecuta el exportador kube-state-metrics.
En este caso, estas etiquetas se pueden mover a atributos de recursos con el procesador groupbyattrs:
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
En el ejemplo anterior, dada una métrica con las etiquetas namespace, cluster o location, esas etiquetas se convertirán en los atributos de recursos correspondientes.
Limita las solicitudes a la API y el uso de memoria
Otros dos procesadores, el procesador por lotes y el procesador del limitador de memoria, te permiten limitar el consumo de recursos de tu recopilador.
Procesamiento por lotes
Las solicitudes por lotes te permiten definir cuántos datos enviar en una sola solicitud. Ten en cuenta que Cloud Monitoring tiene un límite de 200 series temporales por solicitud. Habilita el procesador por lotes con los siguientes parámetros de configuración:
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
Límite de memoria
Recomendamos habilitar el procesador del límite de memoria para evitar que el recopilador falle en momentos de alta capacidad de procesamiento. Habilita el procesamiento con los siguientes parámetros de configuración:
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
Configura el exportador googlemanagedprometheus
De forma predeterminada, el uso del exportador googlemanagedprometheus en GKE no requiere ninguna configuración adicional. En muchos casos de uso, solo necesitas habilitarlo con un bloque vacío en la sección exporters:
exporters: googlemanagedprometheus:
Sin embargo, el exportador proporciona algunos parámetros de configuración opcionales. En las siguientes secciones, se describen los demás parámetros de configuración.
Configura project_id
Para asociar tu serie temporal con un proyecto de Google Cloud , el recurso supervisado deprometheus_targetdebe tener establecido el valor deproject_id.
Cuando se ejecuta OpenTelemetry en Google Cloud, el exportador de Managed Service para Prometheus establece de forma predeterminada este valor según las credenciales predeterminadas de la aplicación que encuentra. Si no hay credenciales disponibles o quieres anular el proyecto predeterminado, tienes dos opciones:
- Establece
projecten la configuración del exportador - Agrega un atributo de recurso
gcp.project.ida tus métricas.
Te recomendamos que utilices el valor predeterminado (sin configurar) para project_id en lugar de establecerlo de forma explícita, cuando sea posible.
Establece project en la configuración del exportador
En el siguiente extracto de configuración, se envían métricas a Managed Service para Prometheus en el proyecto Google Cloud MY_PROJECT:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
El único cambio con respecto a los ejemplos anteriores es la nueva línea project: MY_PROJECT.
Esta configuración es útil si sabes que cada métrica que llega a través de este recopilador debe enviarse a MY_PROJECT.
Establece el atributo de recurso gcp.project.id
Puedes configurar la asociación del proyecto por métrica agregando un atributo de recurso gcp.project.id a tus métricas. Establece el valor del atributo en el nombre del proyecto con el que se debe asociar la métrica.
Por ejemplo, si tu métrica ya tiene una etiqueta project, esta etiqueta se puede mover a un atributo de recurso y se le puede cambiar el nombre a gcp.project.id mediante los procesadores en la configuración del recopilador, como se muestra en el siguiente ejemplo:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
Configura las opciones del cliente
El exportador googlemanagedprometheus usa clientes de gRPC para Managed Service de Prometheus. Por lo tanto, hay parámetros de configuración
opcionales disponibles para configurar el cliente de gRPC:
compression: Habilita la compresión gzip para las solicitudes de gRPC, que es útil para minimizar las tarifas de transferencia de datos cuando se envían desde otras nubes hacia el servicio administrado para Prometheus (valores válidos:gzip).user_agent: Anula la cadena de usuario-agente enviada en las solicitudes a Cloud Monitoring; solo se aplica a las métricas. La configuración predeterminada es el número de versión y compilación de tu recopilador de OpenTelemetry, por ejemplo,opentelemetry-collector-contrib 0.128.0.endpoint: Establece el extremo al que se enviarán los datos de métricas.use_insecure: Si es verdadero, usa gRPC como transporte de comunicación. Solo tiene efecto cuando el valor deendpointno es "".grpc_pool_size: Establece el tamaño del grupo de conexiones en el cliente de gRPC.prefix: Configura el prefijo de métricas que se envían a Managed Service para Prometheus. La configuración predeterminada esprometheus.googleapis.com. No cambies este prefijo; esto hace que las métricas no se puedan consultar con PromQL en la IU de Cloud Monitoring.
En la mayoría de los casos, no es necesario cambiar estos valores predeterminados. Sin embargo, puedes cambiarlos para adaptarlos a circunstancias especiales.
Todos estos parámetros de configuración se establecen en un bloque metric en la sección del exportador googlemanagedprometheus, como se muestra en el siguiente ejemplo:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
Próximos pasos
- Usa PromQL en Cloud Monitoring para consultar las métricas de Prometheus.
- Usa Grafana para consultar métricas de Prometheus.
- Configura el recopilador de OpenTelemetry como un agente de sidecar en Cloud Run.
-
En la página Administración de métricas de Cloud Monitoring, se proporciona información que puede resultar útil para controlar el importe que inviertes en las métricas facturables sin afectar la observabilidad. En la página Administración de métricas, se proporciona la siguiente información:
- Volúmenes de transferencia para la facturación basada en bytes y de muestra, en todos los dominios de métricas y en cada métrica individual
- Datos sobre etiquetas y cardinalidad de métricas
- Cantidad de lecturas para cada métrica
- Uso de métricas en políticas de alertas y paneles personalizados
- Tasa de errores de escritura de métricas
También puedes usar la página Administración de métricas para excluir las métricas innecesarias, de modo que te ahorrarás el costo de su transferencia. Para obtener más información sobre la página Administración de métricas, consulta Visualiza y administra el uso de métricas.