本文档介绍如何设置 OpenTelemetry 收集器以爬取标准 Prometheus 指标并将这些指标报告给 Google Cloud Managed Service for Prometheus。OpenTelemetry 收集器是一种代理,您可以自行部署并将其配置为导出到 Managed Service for Prometheus。设置方式与使用自行部署的收集运行 Managed Service for Prometheus 类似。
您可能会出于以下原因选择 OpenTelemetry 收集器,而不是自行部署的收集:
- 借助 OpenTelemetry 收集器,您可以通过在流水线中配置不同的导出器,将遥测数据路由到多个后端。
- 该收集器还支持来自指标、日志和跟踪记录的信号,因此使用该收集器可以在一个代理中处理所有三种信号类型。
- OpenTelemetry 与供应商无关的数据格式(OpenTelemetry 协议 [OTLP])支持强大的库和可插入收集器组件生态系统。这样便可以通过一系列自定义选项来接收、处理和导出数据。
这些优势的代价是,运行 OpenTelemetry 收集器需要一种自行管理的部署和维护方法。选择哪种方法取决于您的特定需求,但在本文档中,我们提供了有关使用 Managed Service for Prometheus 作为后端配置 OpenTelemetry 收集器的推荐准则。
准备工作
本部分介绍本文档中描述的任务所需的配置。
设置项目和工具
要使用 Google Cloud Managed Service for Prometheus,您需要以下资源:
启用了 Cloud Monitoring API 的 Google Cloud 项目。
如果您没有 Google Cloud 项目,请执行以下操作:
在 Google Cloud 控制台中,前往新建项目:
在项目名称字段中,为您的项目输入一个名称,然后点击创建。
转到结算:
在页面顶部选择您刚刚创建的项目(如果尚未选择)。
系统会提示您选择现有付款资料或创建新的付款资料。
默认情况下,新项目会启用 Monitoring API。
如果您已有 Google Cloud 项目,请确保已启用 Monitoring API:
转到 API 和服务:
选择您的项目。
点击启用 API 和服务。
搜索“Monitoring”。
在搜索结果中,点击“Cloud Monitoring API”。
如果未显示“API 已启用”,请点击启用按钮。
Kubernetes 集群。如果您没有 Kubernetes 集群,请按照 GKE 快速入门中的说明进行操作。
您还需要以下命令行工具:
gcloudkubectl
gcloud 和 kubectl 工具是 Google Cloud CLI 的一部分。如需了解如何安装这些工具,请参阅管理 Google Cloud CLI 组件。如需查看已安装的 gcloud CLI 组件,请运行以下命令:
gcloud components list
配置您的环境
为避免重复输入您的项目 ID 或集群名称,请执行以下配置:
按如下方式配置命令行工具:
配置 gcloud CLI 以引用您的Google Cloud 项目的 ID:
gcloud config set project PROJECT_ID
配置
kubectlCLI 以使用集群:kubectl config set-cluster CLUSTER_NAME
如需详细了解这些工具,请参阅以下内容:
设置命名空间
为您在示例应用中创建的资源创建 NAMESPACE_NAME Kubernetes 命名空间:
kubectl create ns NAMESPACE_NAME
验证服务账号凭据
如果您的 Kubernetes 集群已启用 Workload Identity Federation for GKE,则可以跳过此部分。
在 GKE 上运行时,Managed Service for Prometheus 会自动根据 Compute Engine 默认服务账号从环境中检索凭据。默认情况下,默认服务账号具有必要的权限 monitoring.metricWriter 和 monitoring.viewer。如果您未使用 Workload Identity Federation for GKE,并且之前从默认节点服务账号中移除了任一角色,则必须重新添加这些缺少的权限,然后才能继续。
为 Workload Identity Federation for GKE 配置服务账号
如果您的 Kubernetes 集群未启用 Workload Identity Federation for GKE,则可以跳过此部分。
Managed Service for Prometheus 使用 Cloud Monitoring API 捕获指标数据。如果您的集群使用的是 Workload Identity Federation for GKE,则必须向您的 Kubernetes 服务账号授予 Monitoring API 权限。本节介绍以下内容:
- 创建专用Google Cloud 服务账号
gmp-test-sa。 - 将 Google Cloud 服务账号绑定到测试命名空间
NAMESPACE_NAME中的默认 Kubernetes 服务账号。 - 向 Google Cloud 服务账号授予必要的权限。
创建和绑定服务账号
此步骤显示在 Managed Service for Prometheus 文档中的多个位置。如果您在执行先前的任务时已经执行此步骤,则无需重复执行。请直接跳到向服务账号授权。
以下命令序列会创建 gmp-test-sa 服务账号并将其绑定到 NAMESPACE_NAME 命名空间中的默认 Kubernetes 服务账号:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
如果您使用的是其他 GKE 命名空间或服务账号,请适当调整命令。
向服务账号授权
相关权限组已收集到多个角色中,您可以将这些角色授予主账号(在此示例中为 Google Cloud服务账号)。如需详细了解 Monitoring 角色,请参阅访问权限控制。
以下命令会向 Google Cloud 服务账号 gmp-test-sa 授予写入指标数据所需的 Monitoring API 角色。
如果您在执行先前的任务时已经为 Google Cloud 服务账号授予了特定角色,则无需再次执行此操作。
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
调试 Workload Identity Federation for GKE 配置
如果您在使 Workload Identity Federation for GKE 正常工作时遇到问题,请参阅验证 Workload Identity Federation for GKE 设置的文档和 Workload Identity Federation for GKE 故障排除指南。
由于拼写错误和部分复制粘贴是配置 Workload Identity Federation for GKE 时最常见的错误来源,因此我们强烈建议使用这些说明中代码示例中嵌入的可编辑变量和可点击复制粘贴图标。
生产环境中的 Workload Identity Federation for GKE
本文档中所述的示例将 Google Cloud 服务账号绑定到默认 Kubernetes 服务账号,并为 Google Cloud服务账号授予使用 Monitoring API 所需的所有权限。
在生产环境中,您可能需要使用更精细的方法,其中每个组件对应一个服务账号,并且每个服务账号都具有最小的权限。如需详细了解如何为工作负载身份管理配置服务账号,请参阅使用 Workload Identity Federation for GKE。
设置 OpenTelemetry 收集器
本部分将指导您设置和使用 OpenTelemetry 收集器从示例应用中爬取指标,并将数据发送到 Google Cloud Managed Service for Prometheus。如需了解详细的配置信息,请参阅以下部分:
OpenTelemetry 收集器类似于 Managed Service for Prometheus 代理二进制文件。OpenTelemetry 社区会定期发布各个版本,包括源代码、二进制文件和容器映像。
您可以使用最佳实践默认值在虚拟机或 Kubernetes 集群上部署这些工件,也可以使用收集器构建器构建仅包含所需组件的收集器。如需构建可与 Managed Service for Prometheus 搭配使用的收集器,您需要以下组件:
- Managed Service for Prometheus 导出器,用于将指标写入 Managed Service for Prometheus。
- 用于爬取指标的接收器。本文档假定您使用的是 OpenTelemetry Prometheus 接收器,但 Managed Service for Prometheus 导出器可与任何 OpenTelemetry 指标接收器兼容。
- 处理器,用于批量处理和标记指标,以便根据您的环境添加重要的资源标识符。
这些组件是使用配置文件启用的,而配置文件会通过 --config 标志传递给收集器。
以下各部分将更详细地讨论如何配置每个组件。本文档介绍如何在 GKE 和其他位置运行收集器。
配置和部署收集器
无论您是在 Google Cloud 上还是在其他环境中执行收集操作,都可以将 OpenTelemetry 收集器配置为导出到 Managed Service for Prometheus。最大的区别在于如何配置收集器。在非Google Cloud 环境中,可能需要进行额外的指标数据格式设置,以便与 Managed Service for Prometheus 兼容。不过,在 Google Cloud上,收集器可以自动检测到大部分此类格式。
在 GKE 上运行 OpenTelemetry 收集器
您可以将以下配置复制到名为 config.yaml 的文件中,以在 GKE 上设置 OpenTelemetry 收集器:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
上述配置使用 Prometheus 接收器和 Managed Service for Prometheus 导出器来爬取 Kubernetes Pod 上的指标端点,并将这些指标导出到 Managed Service for Prometheus。流水线处理器会对数据进行格式设置和批处理。
如需详细了解此配置的每个部分的功能以及不同平台的配置,请参阅以下有关爬取指标和添加处理器的详细部分。
将现有的 Prometheus 配置与 OpenTelemetry 收集器的 prometheus 接收器搭配使用时,请将所有单个美元符号字符 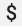 替换为双字符
替换为双字符 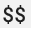 ,以免触发环境变量替换。如需了解详情,请参阅爬取 Prometheus 指标。
,以免触发环境变量替换。如需了解详情,请参阅爬取 Prometheus 指标。
您可以根据环境、提供商和要爬取的指标修改此配置,但建议使用此示例配置在 GKE 上运行。
在 Google Cloud外部运行 OpenTelemetry 收集器
在 Google Cloud外部(例如在本地或使用其他云服务提供商)运行 OpenTelemetry 收集器与在 GKE 上运行收集器类似。但是,您爬取的指标不太可能自动包含最适合 Managed Service for Prometheus 的格式的数据。因此,您必须格外注意配置收集器设置指标的格式,使其与 Managed Service for Prometheus 兼容。
您可以将以下配置复制到名为 config.yaml 的文件中,以在非 GKE Kubernetes 集群上设置要部署的 OpenTelemetry 收集器:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
此配置会执行以下操作:
- 为 Prometheus 设置 Kubernetes 服务发现爬取配置。如需了解详情,请参阅爬取 Prometheus 指标。
- 手动设置
cluster、namespace和location资源属性。如需详细了解资源属性(包括 Amazon EKS 和 Azure AKS 的资源检测),请参阅检测资源属性。 - 在
googlemanagedprometheus导出器中设置project选项。如需详细了解该导出器,请参阅配置googlemanagedprometheus导出器。
将现有的 Prometheus 配置与 OpenTelemetry 收集器的 prometheus 接收器搭配使用时,请将所有单个美元符号字符 替换为双字符 ,以免触发环境变量替换。如需了解详情,请参阅爬取 Prometheus 指标。
如需了解在其他云上配置收集器的最佳实践,请参阅 Amazon EKS 或 Azure AKS。
部署示例应用
示例应用在其 metrics 端口上发出 example_requests_total 计数器指标和 example_random_numbers 直方图指标(以及其他指标)。本示例的清单定义了三个副本。
要部署示例应用,请运行以下命令:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
将收集器配置创建为 ConfigMap
创建配置并将其放入名为 config.yaml 的文件中后,可使用该文件根据 config.yaml 文件创建 Kubernetes ConfigMap。部署收集器后,它会装载 ConfigMap 并加载文件。
如需使用配置创建名为 otel-config 的 ConfigMap,请使用以下命令:
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
部署收集器
创建一个包含以下内容的 collector-deployment.yaml 文件:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
运行以下命令,在 Kubernetes 集群中创建收集器部署:
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
pod 启动后,会爬取示例应用,并将指标报告给 Managed Service for Prometheus。
如需了解查询数据的方法,请参阅使用 Cloud Monitoring 进行查询或使用 Grafana 进行查询。
明确提供凭据
在 GKE 上运行时,OpenTelemetry 收集器会根据节点的服务账号自动从环境中检索凭据。在非 GKE Kubernetes 集群中,必须使用标志或 GOOGLE_APPLICATION_CREDENTIALS 环境变量将凭据明确提供给 OpenTelemetry Collector。
将上下文设置为目标项目:
gcloud config set project PROJECT_ID
创建服务账号:
gcloud iam service-accounts create gmp-test-sa
此步骤会创建您可能已在 Workload Identity Federation for GKE 说明中创建的服务账号。
向服务账号授予所需权限:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
创建并下载服务账号的密钥:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
将密钥文件作为 Secret 添加到非 GKE 集群:
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
打开 OpenTelemetry Deployment 资源以进行修改:
kubectl -n NAMESPACE_NAME edit deployment otel-collector
将粗体显示的文本添加到资源:
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...保存该文件并关闭编辑器。应用更改后,系统会重新创建 pod 并使用给定服务账号向指标后端进行身份验证。
爬取 Prometheus 指标
本部分和后续部分提供了有关使用 OpenTelemetry 收集器的其他自定义信息。在某些情况下,此信息可能很有用,但不需要此信息也可以运行设置 OpenTelemetry 收集器中所述的示例。
如果您的应用已在公开 Prometheus 端点,则 OpenTelemetry 收集器可以使用与任何标准 Prometheus 配置搭配使用的爬取配置格式爬取这些端点。为此,请在收集器配置中启用 Prometheus 接收器。
Kubernetes pod 的 Prometheus 接收器配置可能如下所示:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
这是一个基于服务发现的爬取配置,您可以根据需要进行修改以爬取应用。
将现有的 Prometheus 配置与 OpenTelemetry 收集器的 prometheus 接收器搭配使用时,请将所有单个美元符号字符 替换为双字符 ,以免触发环境变量替换。这对于 relabel_configs 部分中的 replacement 值尤为重要。举例来说,如果您有如下 relabel_config 部分:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
请将其重写为:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
如需了解详情,请参阅 OpenTelemetry 文档。
接下来,我们强烈建议您使用处理器来设置指标的格式。在许多情况下,必须使用处理器来正确设置指标的格式。
添加处理器
OpenTelemetry 处理器会在导出遥测数据之前先对其进行修改。您可以使用以下处理器来确保以与 Managed Service for Prometheus 兼容的格式写入指标。
检测资源属性
适用于 OpenTelemetry 的 Managed Service for Prometheus 导出器使用 prometheus_target 监控的资源来唯一标识时序数据点。导出器会从指标数据点的资源属性中解析所需的受监控资源字段。爬取值的字段和属性包括:
- project_id:由导出器配置中的应用默认凭据、
gcp.project.id或project自动检测(请参阅配置导出器) - 位置:
location、cloud.availability_zone、cloud.region - 集群:
cluster、k8s.cluster_name - 命名空间:
namespace、k8s.namespace_name - 作业:
service.name+service.namespace - 实例:
service.instance.id
如果未能将这些标签设置为唯一值,则在导出到 Managed Service for Prometheus 时,可能会出现“重复时序”错误。 在许多情况下,系统可以自动检测这些标签的值,但在某些情况下,您可能需要自行进行映射。本部分的其余内容将介绍这些情况。
Prometheus 接收器会根据爬取配置中的 job_name 自动设置 service.name 属性,并根据爬取目标的 instance 自动设置 service.instance.id 属性。当在爬取配置中使用 role: pod 时,接收器还会设置 k8s.namespace.name。
尽可能使用资源检测处理器自动填充其他属性。但是,根据您的环境,可能无法自动检测某些属性。在这种情况下,您可以使用其他处理器手动插入这些值,或从指标标签中解析这些值。以下部分介绍了用于在各种平台上检测资源的配置。
GKE
在 GKE 上运行 OpenTelemetry 时,您需要启用资源检测处理器以填充资源标签。请确保您的指标不包含任何预留的资源标签。如果无法避免,请参阅重命名属性以避免资源属性冲突。
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
您可以将此部分直接复制到配置文件中,并替换 processors 部分(如果已存在)。
Amazon EKS
EKS 资源检测器不会自动填写 cluster 或 namespace 属性。您可以使用资源处理器手动提供这些值,如以下示例所示:
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
您还可以使用 groupbyattrs 处理器从指标标签转换这些值(请参阅下面的将指标标签移动到资源标签)。
Azure AKS
AKS 资源检测器不会自动填写 cluster 或 namespace 属性。您可以使用资源处理器手动提供这些值,如以下示例所示:
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
您还可以使用 groupbyattrs 处理器从指标标签转换这些值;请参阅将指标标签移动到资源标签。
本地环境和非云环境
使用本地或非云环境时,您可能无法自动检测任何必要的资源属性。在这种情况下,您可以在指标中发出这些标签,并将其移动到资源属性(请参阅将指标标签移动到资源标签),或手动设置所有资源属性,如以下示例所示:
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
将收集器配置创建为 ConfigMap 部分介绍了如何使用配置。该部分假定您已将配置放入名为 config.yaml 的文件中。
在使用应用默认凭据运行收集器时,系统仍然可以自动设置 project_id 资源属性。如果您的收集器没有访问应用默认凭证的权限,请参阅设置 project_id。
或者,您也可以在环境变量 OTEL_RESOURCE_ATTRIBUTES 中使用键值对的英文逗号分隔列表手动设置所需的资源属性,例如:
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
然后,使用 env 资源检测器处理器设置资源属性:
processors:
resourcedetection:
detectors: [env]
通过重命名属性避免资源属性冲突
如果您的指标已包含与所需资源属性(例如 location、cluster 或 namespace)冲突的标签,请重命名它们以避免冲突。Prometheus 的惯例是将前缀 exported_ 添加到标签名称中。如需添加此前缀,请使用转换处理器。
以下 processors 配置将重命名任何潜在的冲突,并解决指标中存在任何冲突键的问题:
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
将指标标签移至资源标签
在某些情况下,您的指标可能会有意报告标签,例如 namespace,因为导出器正在监控多个命名空间。例如,在运行 kube-state-metrics 导出器时。
在这种情况下,您可以使用 groupbyattrs 处理器将这些标签移动到资源属性:
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
在上面的示例中,如果给定具有 namespace、cluster 或 location 标签的指标,这些标签将转换为匹配的资源属性。
限制 API 请求数和内存用量
其他两个处理器(批处理器和内存限制器处理器)可让您限制收集器的资源消耗量。
批处理
通过批量请求,您可以定义在单个请求中要发送的数据点的数量。请注意,Cloud Monitoring 对每个请求有 200 个时序的限制。使用以下设置启用批处理器:
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
内存限制
我们建议启用内存限制器处理器,以防止收集器在高吞吐量情况下崩溃。使用以下设置启用处理功能:
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
配置 googlemanagedprometheus 导出器
默认情况下,在 GKE 上使用 googlemanagedprometheus 导出器无需进行额外配置。对于许多用例,您只需在 exporters 部分中使用空白块即可启用该功能:
exporters: googlemanagedprometheus:
不过,导出器确实提供了一些可选的配置设置。以下部分介绍了其他配置设置。
设置 project_id
如需将时序与 Google Cloud 项目关联,prometheus_target 监控的资源必须设置 project_id。
在 Google Cloud上运行 OpenTelemetry 时,Managed Service for Prometheus 导出器默认会根据其找到的应用默认凭证设置此值。如果没有可用的凭证,或者您想替换默认项目,则有如下两种方法:
- 在导出器配置中设置
project - 向您的指标添加
gcp.project.id资源属性。
我们强烈建议您尽可能使用 project_id 的默认(未设置)值,而不是明确设置该值。
在导出器配置中设置 project
以下配置摘录会将指标发送到 Google Cloud 项目 MY_PROJECT 中的 Managed Service for Prometheus:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
与前面的示例唯一不同的是,添加了一个新行 project: MY_PROJECT。如果您知道通过此收集器传入的每个指标都应发送到 MY_PROJECT,则此设置会很有用。
设置 gcp.project.id 资源属性
您可以通过向指标添加 gcp.project.id 资源属性,按指标设置项目关联。将该属性的值设置为指标应关联到的项目的名称。
例如,如果您的指标已具有标签 project,则可以将此标签移至资源属性,并使用收集器配置中的处理器重命名为 gcp.project.id,如以下示例所示:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
设置客户端选项
googlemanagedprometheus 导出器使用 gRPC 客户端来运行 Managed Service for Prometheus。因此,您可以选择设置来配置 gRPC 客户端:
compression:为 gRPC 请求启用 gzip 压缩,这在将数据从其他云发送到 Managed Service for Prometheus时有助于最大限度地减少数据传输费用(有效值:gzip)。user_agent:替换发送到 Cloud Monitoring 的请求的用户代理字符串;仅适用于指标。默认为 OpenTelemetry 收集器的 build 号和版本号,例如opentelemetry-collector-contrib 0.128.0。endpoint:设置要将指标数据发送到的端点。use_insecure:如果为 true,则使用 gRPC 作为通信传输机制。仅当endpoint值不是 "" 时才会生效。grpc_pool_size:设置 gRPC 客户端中连接池的大小。prefix:配置发送到 Managed Service for Prometheus 的指标的前缀。默认值为prometheus.googleapis.com。 请勿更改此前缀,否则会导致无法使用 Cloud Monitoring 界面中的 PromQL 查询指标。
在大多数情况下,您无需更改这些值,保留其默认值即可。不过,如果有特殊情况需要的话,您也可以进行更改。
所有这些设置均在 googlemanagedprometheus 导出器部分的 metric 块下进行设置,如以下示例所示:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
后续步骤
- 在 Cloud Monitoring 中使用 PromQL 查询 Prometheus 指标。
- 使用 Grafana 查询 Prometheus 指标。
- 在 Cloud Run 中将 OpenTelemetry 收集器设置为边车代理。
-
Cloud Monitoring 指标管理页面提供的信息可帮助您控制在收费指标上支出的金额,而不会影响可观测性。指标管理页面报告以下信息:
- 针对指标网域中基于字节和基于样本的结算以及各个指标的注入量。
- 有关标签和指标基数的数据。
- 每个指标的读取次数。
- 指标在提醒政策和自定义信息中心内的使用。
- 指标写入错误率。
您还可以使用指标管理来排除不需要的指标,从而免除注入这些指标的费用。 如需详细了解指标管理页面,请参阅查看和管理指标使用情况。