AI 基礎架構的未來
AI 基礎架構的未來
AI Hypercomputer 是一種結合專用硬體、開放式軟體和彈性計費模式的架構。各項元件都經過精心整合,可順暢運作,進而提升效能、降低成本及提高開發人員工作效率。

更聰明快速的訓練
更聰明快速的訓練
不必耗費數月,只要數週內就能建構模型。運用 Google 的訓練堆疊,即可加快開發和測試速度,同時兼顧效能。

加快大型語言模型的訓練和調整速度
使用專屬資料,以更聰明的方式訓練輕量級模型
結合資料資產、機器學習開發和加速器,在 BigQuery 中使用 Gemini Enterprise Agent Platform,以專屬資料訓練模型,速度可提升 16 倍。無論使用 G4 VM 或 Ironwood TPU,兩者皆由 AI Hypercomputer 提供支援。
使用 MuJoCo-Warp 建構自動調整式實體代理
在 DeepMind 的 MuJoCo-Warp 上執行 GPU 模擬,速度比標準 MuJoCo 快 100 倍。接著,使用 Veo、Genie 和 Nano Banana 的合成媒體,模擬不可能、有風險或成本高昂的極端情況,或在 BigQuery 中擷取數 PB 的實際感應器資料。如要進一步瞭解如何在 Google Cloud 建構實體代理,請按這裡。
回應迅速且有效率的推論
回應迅速且有效率的推論
取得經過驗證的模型設定檔,以及完全整合的 Google 和開放式軟體,以更精簡的方式提升應用程式回應速度,減少資源浪費。
以趨近於零的延遲時間提供大型語言模型
運用整合式推論技術,為客戶提供實用且反應迅速的服務。透過 GKE Inference Gateway 將首個詞元生成時間 (TTFT) 縮短 71%,並利用 llm-d 進行解耦式推論 (disaggregated serving),每秒可處理多達 12 萬個詞元;此外,搭配使用 Rapid Cache 與 TPU 8i 可將模型載入速度提升 5 倍,確保工作記憶體能精準發揮效用。
提供預先建構的視覺、感知和媒體模型
Gemini Enterprise Agent Platform 提供超過 200 個模型,可讓您選擇 TPU 或 GPU (包括今年稍晚推出的 A5X VM (NVIDIA Vera Rubin) 和 TPU 8i),以快 70% 的速度部署傳統機器學習模型。
以安全且符合成本效益的方式提供代理服務
在 GKE Agent Sandbox 中安全地提供大量代理,每秒可佈建多達 300 個沙箱,並視需要立即暫停和恢復,因此您不必為閒置的代理付費。
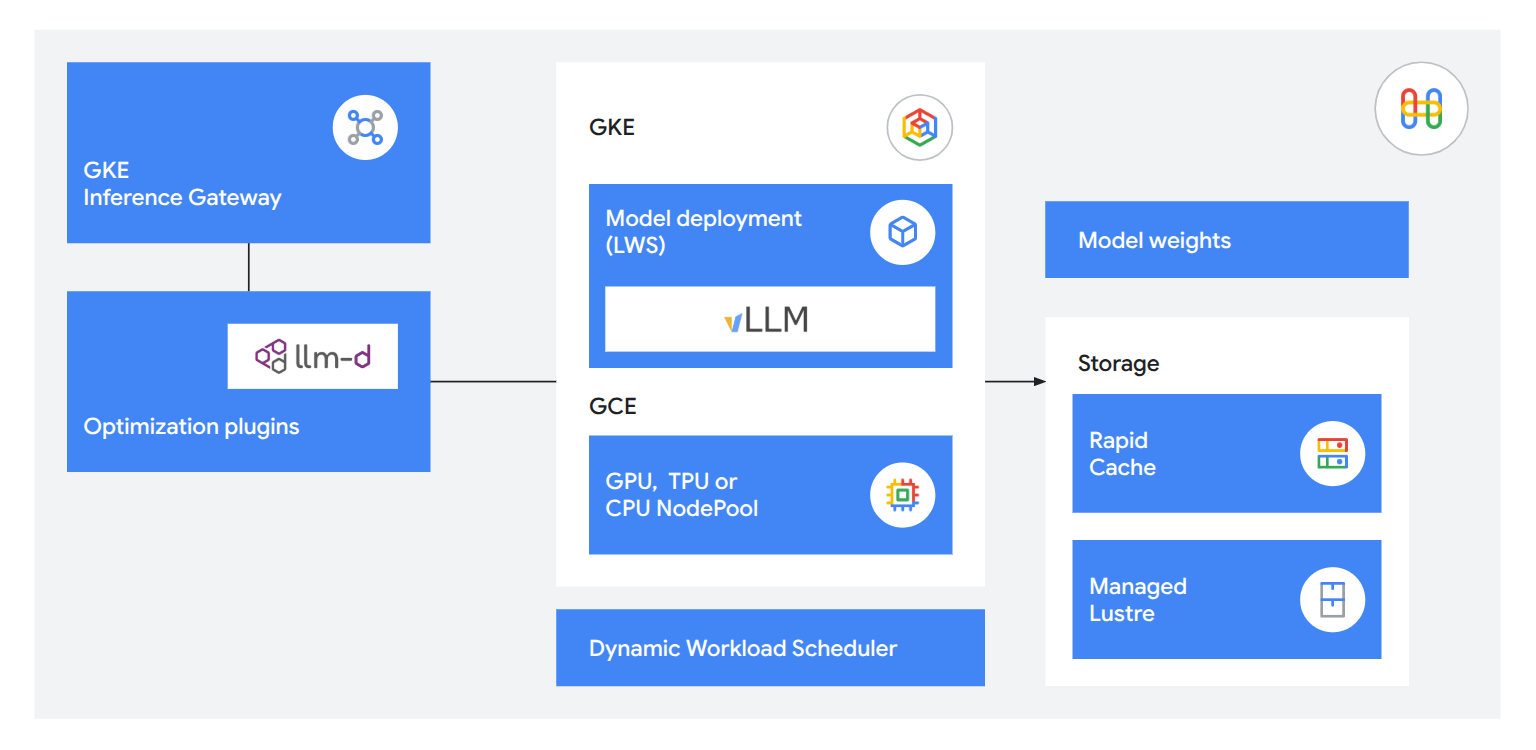
彈性、開放、可靠的作業
彈性、開放、可靠的作業
在混合雲和多雲端環境中,使用任何架構或加速器,並透過自動化叢集維護和管理功能,輕鬆處理超大規模的工作負載。

無須重寫程式碼,即可在 TPU 和 GPU 之間切換
TorchTPU 提供原生 PyTorch 支援,讓開發人員不必學習 TPU 的相關知識,即可使用最優質的加速器,不必重寫複雜的程式碼。
在任何環境部署 AI,幾乎不受規模限制
GKE 以開放原始碼 Kubernetes 為基礎,可讓您在多雲端環境中具備企業規模的可攜性,最多可容納 130,000 個節點。此外,GKE 還能與 Agent Platform 和 Google Distributed Cloud 原生整合,方便您進行混合部署。
運用進階叢集診斷和觀測工具,自動執行叢集維護作業
AI Hypercomputer 上的每個加速器都支援 Cluster Director 功能,包括部署前健康狀態檢查、360 度觀測資訊主頁,和全天候健康狀態檢查。
幾分鐘內就能連線多雲端工作負載,不必耗費數週
您可以使用 Cross-Cloud Network 跨雲端連結各項服務,不必擔心連線延遲。這款骨幹網路受到超過 65% 的《財富》雜誌百大企業信賴,每月處理的資料量超過 27 EB。
隨心所欲取得加速器容量
我們提供彈性的計費模式,讓您能以多種方式排定加速器使用時間,藉此降低成本。使用 Spot VM 處理批次或容錯工作,最多可省下 91% 的費用;使用 Dynamic Workload Scheduler 處理開始日期有彈性的工作,最多可省下 50% 的費用;註冊承諾使用折扣,最多可省下 50% 的費用。
支援代理的系統
支援代理的系統
Google 和前沿 AI 研究室都信賴這項基礎架構,您可盡情調度資源,同時兼顧效能和能源使用效率
以值得信賴的基礎降低 AI 藍圖的風險
全球頂尖的 AI 研究室中,有 9 成選擇 Google Cloud,此外,有 70% 已獲融資的 AI 新創公司也是我們的合作夥伴。只要在 AI Hypercomputer 上進行部署,就能使用極其可靠的資料中心,光是 2025 年 12 月,這些中心就已為近 350 位客戶處理超過 1,000 億個詞元。
達到領先業界的能源效率
減少對電網和社群的影響
從晶片到邊緣,保護最寶貴的 IP
我們的 Titanium 架構採用特製的 Titan 晶片,提供可驗證的硬體信任根和零信任安全機制。cloudvulndb.org 的獨立分析顯示,我們的系統發生重大安全漏洞的頻率,比其他一流雲端服務低 70%。
為全球頂尖創新者提供助力










進一步瞭解 AI Hypercomputer
- 《IDC: The Business Value of AI Hypercomputer》這份 IDC 報告探討了 AI Hypercomputer 在 AI 工作負載方面對客戶造成的實際效益。歡迎閱讀完整報告,查看客戶資料,瞭解 AI Hypercomputer 如何將投資報酬率提高 353%、IT 團隊效率提升 55%,以及減少 67% 的應用程式/工作負載非預期停機時間。
閱讀時間:5 分鐘
閱讀報告 - 《Gartner® Magic Quadrant for Strategic Cloud Platform Services》報告,將 Google 評選為領導品牌。Gartner® 連續八年在《Gartner Magic Quadrant™ for Strategic Cloud Platform Services》報告中,將 Google 評選為領導品牌。不過,今年更是寫下了重大里程碑:Google 在「願景完整度」方面位居領先地位。
閱讀時間:5 分鐘
查看結果 - 在 2025 年第 4 季的《The Forrester Wave™: AI Infrastructure Solutions》報告中,Google 獲評為領導品牌Google 在「現有產品/服務」類別獲得最高分,在所有受評廠商中脫穎而出,並在 19 項評選標準中,有 16 項獲得最高分,包括願景、架構、訓練、推論、效率和安全性等。
閱讀時間:5 分鐘
查看結果
- 設計及部署您的第一個推論堆疊瞭解組成 Google Cloud 推論解決方案的必要元件,包括 GKE、Cloud TPU、TensorFlow、PyTorch、JAX 和 Keras。
2 小時課程
參加課程 - 在 GKE 使用 vLLM 提供 Gemma 3 27B 推論服務本教學課程會說明如何使用 vLLM 服務框架,部署及提供 Gemma 3 27B 大型語言模型 (LLM) 服務。您將學會在 Google Kubernetes Engine (GKE) 的單一 A4 虛擬機器 (VM) 執行個體上部署 Gemma 3。
15 分鐘指南
參加教學課程 - 在 A4 GKE 叢集上微調 Gemma 3本教學課程會說明如何在 Google Cloud 的多節點、多 GPU GKE 叢集上,微調 Gemma 3 大型語言模型 (LLM)。此叢集使用 A4 虛擬機器 (VM) 執行個體,配備 8 個 NVIDIA B200 GPU。
15 分鐘指南
參加教學課程
- 在 A4 Slurm 叢集上訓練 Qwen2本教學課程會說明如何在 Google Cloud 的多節點、多 GPU Slurm 叢集上訓練大型語言模型 (LLM)。本教學課程使用的模型是以擁有 15 億個參數的 Qwen2 模型為基礎。Slurm 叢集使用兩部 a4-highgpu-8g 虛擬機器 (VM),每部 VM 都有 8 個 NVIDIA B200 GPU。
15 分鐘指南
參加教學課程 - 在 TPU 上使用 vLLM 提供 Qwen2-7B-Instruct 服務本教學課程將在 v6e TPU VM 上,使用 vLLM TPU 服務框架,提供 Qwen/Qwen2-7B-Instruct 模型。
15 分鐘指南
參加教學課程
分析師洞察
- 《IDC: The Business Value of AI Hypercomputer》這份 IDC 報告探討了 AI Hypercomputer 在 AI 工作負載方面對客戶造成的實際效益。歡迎閱讀完整報告,查看客戶資料,瞭解 AI Hypercomputer 如何將投資報酬率提高 353%、IT 團隊效率提升 55%,以及減少 67% 的應用程式/工作負載非預期停機時間。
閱讀時間:5 分鐘
閱讀報告 - 《Gartner® Magic Quadrant for Strategic Cloud Platform Services》報告,將 Google 評選為領導品牌。Gartner® 連續八年在《Gartner Magic Quadrant™ for Strategic Cloud Platform Services》報告中,將 Google 評選為領導品牌。不過,今年更是寫下了重大里程碑:Google 在「願景完整度」方面位居領先地位。
閱讀時間:5 分鐘
查看結果 - 在 2025 年第 4 季的《The Forrester Wave™: AI Infrastructure Solutions》報告中,Google 獲評為領導品牌Google 在「現有產品/服務」類別獲得最高分,在所有受評廠商中脫穎而出,並在 19 項評選標準中,有 16 項獲得最高分,包括願景、架構、訓練、推論、效率和安全性等。
閱讀時間:5 分鐘
查看結果
教學課程
- 設計及部署您的第一個推論堆疊瞭解組成 Google Cloud 推論解決方案的必要元件,包括 GKE、Cloud TPU、TensorFlow、PyTorch、JAX 和 Keras。
2 小時課程
參加課程 - 在 GKE 使用 vLLM 提供 Gemma 3 27B 推論服務本教學課程會說明如何使用 vLLM 服務框架,部署及提供 Gemma 3 27B 大型語言模型 (LLM) 服務。您將學會在 Google Kubernetes Engine (GKE) 的單一 A4 虛擬機器 (VM) 執行個體上部署 Gemma 3。
15 分鐘指南
參加教學課程 - 在 A4 GKE 叢集上微調 Gemma 3本教學課程會說明如何在 Google Cloud 的多節點、多 GPU GKE 叢集上,微調 Gemma 3 大型語言模型 (LLM)。此叢集使用 A4 虛擬機器 (VM) 執行個體,配備 8 個 NVIDIA B200 GPU。
15 分鐘指南
參加教學課程
- 在 A4 Slurm 叢集上訓練 Qwen2本教學課程會說明如何在 Google Cloud 的多節點、多 GPU Slurm 叢集上訓練大型語言模型 (LLM)。本教學課程使用的模型是以擁有 15 億個參數的 Qwen2 模型為基礎。Slurm 叢集使用兩部 a4-highgpu-8g 虛擬機器 (VM),每部 VM 都有 8 個 NVIDIA B200 GPU。
15 分鐘指南
參加教學課程 - 在 TPU 上使用 vLLM 提供 Qwen2-7B-Instruct 服務本教學課程將在 v6e TPU VM 上,使用 vLLM TPU 服務框架,提供 Qwen/Qwen2-7B-Instruct 模型。
15 分鐘指南
參加教學課程












