Treinar, ajustar e disponibilize em um supercomputador de IA
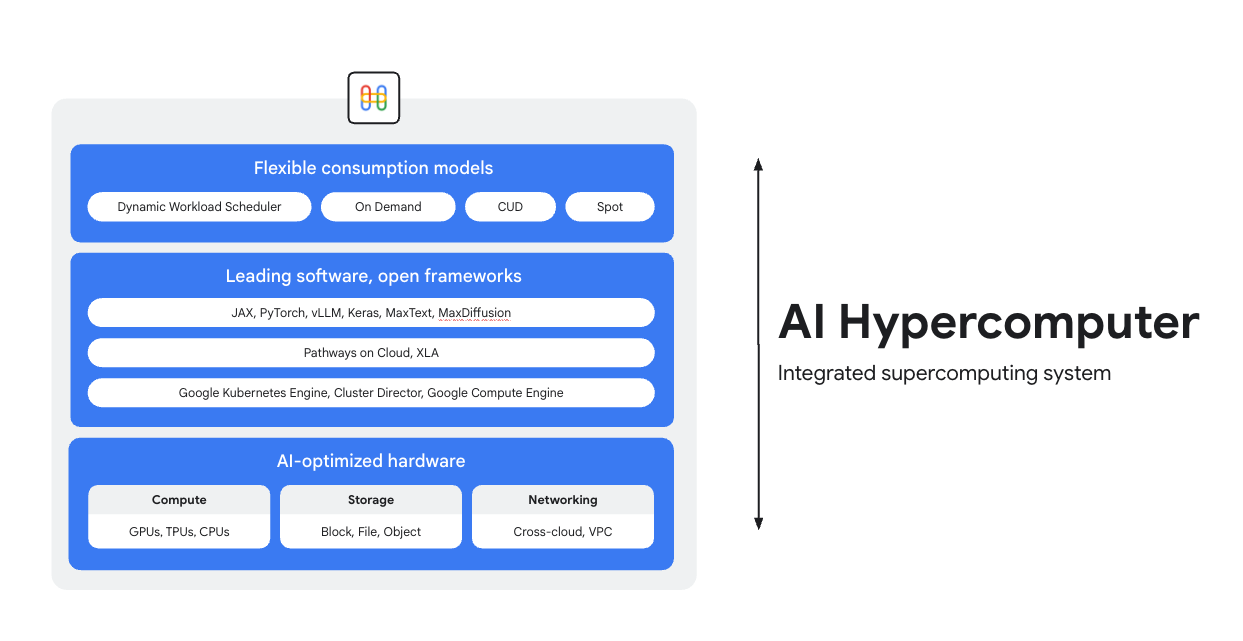
O Hipercomputador de IA é o sistema de supercomputação integrado em todas as cargas de trabalho de IA no Google Cloud. Ele é composto por hardware, software e modelos de consumo projetados para simplificar a implantação de IA, melhorar a eficiência no nível do sistema e otimizar custos.
Visão geral
Hardware otimizado por IA
Escolha entre opções de computação (incluindo aceleradores de IA), armazenamento e rede otimizadas para objetivos granulares no nível da carga de trabalho, seja para maior capacidade de processamento, menor latência, menor tempo para resultados ou menor TCO. Saiba mais sobre: Cloud TPUs, Cloud GPUs, além das novidades em armazenamento e rede.
Software líder, frameworks abertos
Aproveite ao máximo seu hardware com o software líder do setor, integrado a frameworks, bibliotecas e compiladores abertos para tornar o desenvolvimento, a integração e o gerenciamento de IA mais eficientes.
- Suporte para PyTorch, JAX, Keras, vLLM, Megatron-LM, NeMo Megatron, MaxText, MaxDiffusion e muito mais.
- A integração profunda com o compilador XLA permite a interoperabilidade entre diferentes aceleradores, enquanto o Pathways no Cloud permite usar o mesmo ambiente de execução distribuído que alimenta a infraestrutura interna de treinamento e inferência em grande escala do Google.
- Tudo isso pode ser implantado no ambiente de sua escolha, seja o Google Kubernetes Engine, o Cluster Director ou o Google Compute Engine.
Modelos de consumo flexíveis
As opções de consumo flexíveis permitem que os clientes escolham custos fixos com descontos por compromisso de uso ou modelos dinâmicos sob demanda para atender às necessidades dos negócios.O Dynamic Workload Scheduler e as VMs spot ajudam você a conseguir a capacidade necessária sem alocação excessiva.Além disso, as ferramentas de otimização de custos do Google Cloud automatizam a utilização de recursos para reduzir as tarefas manuais dos engenheiros.
Disponibilize modelos em escala de maneira econômica
Maximizar a relação preço-desempenho e a confiabilidade para cargas de trabalho de inferência
A inferência está se tornando mais diversificada e complexa, evoluindo em três áreas principais:
- Primeiro, a forma como interagimos com a IA está mudando. Agora as conversas têm um contexto muito mais longo e diversificado.
- Em segundo lugar, o raciocínio sofisticado e a inferência em várias etapas estão tornando os modelos de Mixture-of-Experts (MoE) mais comuns. Isso está redefinindo como a memória e a computação são escalonadas da entrada inicial à saída final.
- Por fim, fica claro que o valor real não é apenas sobre tokens brutos por dólar, mas sobre a utilidade da resposta. O modelo tem a experiência certa? Ela respondeu corretamente a uma pergunta comercial crítica? Por isso, acreditamos que os clientes precisam de melhores medições, com foco no custo total das operações do sistema, e não no preço dos processadores.
Conheça os recursos de inferência de IA
- O que é inferência de IA? Nosso guia completo sobre tipos, comparações e casos de uso
- Execute as receitas de inferência de práticas recomendadas com o Início rápido de inferência do GKE
- Faça um curso sobre inferência de IA no Cloud Run
- Assista este vídeo sobre o segredo para uma inferência de IA econômica
- Descubra como acelerar as cargas de trabalho de inferência de IA
IA transforma fãs de esportes em designers de uniformes
A PUMA fez uma parceria com o Google Cloud para usar a infraestrutura de IA integrada (Hipercomputador de IA), o que permitiu que a empresa usasse o Gemini para comandos de usuários junto com o Dynamic Workload Scheduler para escalonar dinamicamente a inferência em GPUs, reduzindo drasticamente os custos e o tempo de geração.
Impacto:
- Eles reduziram o tempo de geração do uniforme de IA de 2 a 5 minutos para apenas 30 segundos. Isso transformou a plataforma em uma experiência rápida e verdadeiramente interativa que manteve os usuários engajados.
- Em apenas 10 dias, os fãs criaram 180 mil uniformes e deram 1,7 milhão de avaliações.
- O projeto mostrou uma nova maneira de a PUMA se conectar com a comunidade. Ela foi além de um simples relacionamento entre marca e consumidor, transformando os fãs em cocriadores ativos e fornecendo à empresa insights diretos e em tempo real sobre os desejos criativos dos consumidores mais apaixonados.



Tutoriais
Maximizar a relação preço-desempenho e a confiabilidade para cargas de trabalho de inferência
A inferência está se tornando mais diversificada e complexa, evoluindo em três áreas principais:
- Primeiro, a forma como interagimos com a IA está mudando. Agora as conversas têm um contexto muito mais longo e diversificado.
- Em segundo lugar, o raciocínio sofisticado e a inferência em várias etapas estão tornando os modelos de Mixture-of-Experts (MoE) mais comuns. Isso está redefinindo como a memória e a computação são escalonadas da entrada inicial à saída final.
- Por fim, fica claro que o valor real não é apenas sobre tokens brutos por dólar, mas sobre a utilidade da resposta. O modelo tem a experiência certa? Ela respondeu corretamente a uma pergunta comercial crítica? Por isso, acreditamos que os clientes precisam de melhores medições, com foco no custo total das operações do sistema, e não no preço dos processadores.
Outros recursos
Conheça os recursos de inferência de IA
- O que é inferência de IA? Nosso guia completo sobre tipos, comparações e casos de uso
- Execute as receitas de inferência de práticas recomendadas com o Início rápido de inferência do GKE
- Faça um curso sobre inferência de IA no Cloud Run
- Assista este vídeo sobre o segredo para uma inferência de IA econômica
- Descubra como acelerar as cargas de trabalho de inferência de IA
Exemplos de clientes
IA transforma fãs de esportes em designers de uniformes
A PUMA fez uma parceria com o Google Cloud para usar a infraestrutura de IA integrada (Hipercomputador de IA), o que permitiu que a empresa usasse o Gemini para comandos de usuários junto com o Dynamic Workload Scheduler para escalonar dinamicamente a inferência em GPUs, reduzindo drasticamente os custos e o tempo de geração.
Impacto:
- Eles reduziram o tempo de geração do uniforme de IA de 2 a 5 minutos para apenas 30 segundos. Isso transformou a plataforma em uma experiência rápida e verdadeiramente interativa que manteve os usuários engajados.
- Em apenas 10 dias, os fãs criaram 180 mil uniformes e deram 1,7 milhão de avaliações.
- O projeto mostrou uma nova maneira de a PUMA se conectar com a comunidade. Ela foi além de um simples relacionamento entre marca e consumidor, transformando os fãs em cocriadores ativos e fornecendo à empresa insights diretos e em tempo real sobre os desejos criativos dos consumidores mais apaixonados.
Executar treinamento e pré-treinamento de IA em grande escala
Treinamento de IA avançado, escalonável e eficiente
As cargas de trabalho de treinamento precisam ser executadas como jobs altamente sincronizados em milhares de nós em clusters fortemente acoplados. Um único nó degradado pode interromper um job inteiro, atrasando o tempo de lançamento no mercado. Você vai precisar:
- Garantir que o cluster seja configurado rapidamente e ajustado para a carga de trabalho em questão
- Prever falhas e solucionar problemas rapidamente
- A continuar com uma carga de trabalho, mesmo quando ocorrem falhas
Queremos que os clientes possam implantar e escalonar cargas de trabalho de treinamento com facilidade no Google Cloud.
Treinamento de IA avançado, escalonável e eficiente
Para criar um cluster de IA, comece com um dos nossos tutoriais:
- Criar um cluster Slurm com GPUs (VMs A4) e o Cluster Toolkit
- Criar um cluster do GKE com o Cluster Director para GKE ou o Cluster Toolkit
A Moloco criou uma plataforma de veiculação de anúncios para processar bilhões de solicitações diárias
A Moloco contou com a pilha totalmente integrada do Hipercomputador de IA para escalonar automaticamente em hardware avançado, como TPUs e GPUs, o que liberou os engenheiros da Moloco. Além disso, a integração com a plataforma de dados líder do setor do Google criou um sistema coeso e completo para cargas de trabalho de IA.
Depois de lançar os primeiros modelos de aprendizado profundo, a Moloco teve um crescimento e uma lucratividade exponenciais, multiplicando por cinco o tamanho da empresa em 2,5 anos e alcançando
- treinamento de modelos 10 vezes mais rápido com TPUs do Cloud no GKE, além de uma redução de 4 vezes nos custos de treinamento
- Escalonado para atender a mais de 1.000 usuários internos, dando a eles acesso a um sistema de machine learning em escala planetária que os ajuda a encontrar um crescimento lucrativo com base nos próprios dados


AssemblyAI
A AssemblyAI usa o Google Cloud para treinar modelos com rapidez e em grande escala

A LG AI Research reduziu drasticamente os custos e acelerou o desenvolvimento, ao mesmo tempo em que cumpria os rigorosos requisitos de segurança e residência de dados

A Anthropic anunciou planos para acessar até 1 milhão de TPUs para treinar e veicular modelos do Claude, o que vale dezenas de bilhões de dólares. Mas como eles são executados no Google Cloud? Assista a este vídeo para saber como a Anthropic está ampliando os limites computacionais da IA em escala com o GKE.
Tutoriais
Treinamento de IA avançado, escalonável e eficiente
As cargas de trabalho de treinamento precisam ser executadas como jobs altamente sincronizados em milhares de nós em clusters fortemente acoplados. Um único nó degradado pode interromper um job inteiro, atrasando o tempo de lançamento no mercado. Você vai precisar:
- Garantir que o cluster seja configurado rapidamente e ajustado para a carga de trabalho em questão
- Prever falhas e solucionar problemas rapidamente
- A continuar com uma carga de trabalho, mesmo quando ocorrem falhas
Queremos que os clientes possam implantar e escalonar cargas de trabalho de treinamento com facilidade no Google Cloud.
Outros recursos
Treinamento de IA avançado, escalonável e eficiente
Para criar um cluster de IA, comece com um dos nossos tutoriais:
- Criar um cluster Slurm com GPUs (VMs A4) e o Cluster Toolkit
- Criar um cluster do GKE com o Cluster Director para GKE ou o Cluster Toolkit
Exemplos de clientes
A Moloco criou uma plataforma de veiculação de anúncios para processar bilhões de solicitações diárias
A Moloco contou com a pilha totalmente integrada do Hipercomputador de IA para escalonar automaticamente em hardware avançado, como TPUs e GPUs, o que liberou os engenheiros da Moloco. Além disso, a integração com a plataforma de dados líder do setor do Google criou um sistema coeso e completo para cargas de trabalho de IA.
Depois de lançar os primeiros modelos de aprendizado profundo, a Moloco teve um crescimento e uma lucratividade exponenciais, multiplicando por cinco o tamanho da empresa em 2,5 anos e alcançando
- treinamento de modelos 10 vezes mais rápido com TPUs do Cloud no GKE, além de uma redução de 4 vezes nos custos de treinamento
- Escalonado para atender a mais de 1.000 usuários internos, dando a eles acesso a um sistema de machine learning em escala planetária que os ajuda a encontrar um crescimento lucrativo com base nos próprios dados
AssemblyAI
A AssemblyAI usa o Google Cloud para treinar modelos com rapidez e em grande escala
A LG AI Research reduziu drasticamente os custos e acelerou o desenvolvimento, ao mesmo tempo em que cumpria os rigorosos requisitos de segurança e residência de dados
A Anthropic anunciou planos para acessar até 1 milhão de TPUs para treinar e veicular modelos do Claude, o que vale dezenas de bilhões de dólares. Mas como eles são executados no Google Cloud? Assista a este vídeo para saber como a Anthropic está ampliando os limites computacionais da IA em escala com o GKE.
Implantar e orquestrar aplicativos de IA
Use o principal software de orquestração de IA e frameworks abertos para oferecer experiências baseadas em IA
O Google Cloud fornece imagens que contêm sistemas operacionais, frameworks, bibliotecas e drivers comuns. O Hipercomputador de IA otimiza essas imagens pré-configuradas para oferecer suporte às suas cargas de trabalho de IA.
- Frameworks e bibliotecas de IA e ML: use imagens Docker da camada de software de aprendizado profundo (DLSL) para executar modelos de ML como NeMO e MaxText em um cluster do Google Kubernetes Engine (GKE).
- Implantação de cluster e orquestração de IA: você pode implantar suas cargas de trabalho de IA em clusters do GKE, clusters do Slurm ou instâncias do Compute Engine. Para mais informações, consulte Visão geral da criação de VMs e clusters
Conheça os recursos de software
- O Pathways on Cloud é um sistema projetado para permitir a criação de sistemas de machine learning em grande escala, com várias tarefas e ativados esparsamente
- Otimize sua produtividade de ML usando nossas receitas de Goodput
- Agendar cargas de trabalho do GKE com o Agendamento com reconhecimento de topologia
- Teste uma das nossas receitas de comparativo de mercado para executar os modelos DeepSeek, Mixtral, Llama e GPT em GPUs
- Escolha uma opção de consumo para receber e usar recursos de computação com mais eficiência
Priceline: ajuda para os viajantes criarem experiências únicas
"Com a ajuda do Google Cloud na incorporação da IA generativa, podemos criar um concierge de viagens personalizado em nosso chatbot. Queremos ajudar nossos clientes a ir muito além do simples planejamento de uma viagem, proporcionando uma experiência de viagem única”. Martin Brodbeck, CTO, Priceline




Tutoriais
Use o principal software de orquestração de IA e frameworks abertos para oferecer experiências baseadas em IA
O Google Cloud fornece imagens que contêm sistemas operacionais, frameworks, bibliotecas e drivers comuns. O Hipercomputador de IA otimiza essas imagens pré-configuradas para oferecer suporte às suas cargas de trabalho de IA.
- Frameworks e bibliotecas de IA e ML: use imagens Docker da camada de software de aprendizado profundo (DLSL) para executar modelos de ML como NeMO e MaxText em um cluster do Google Kubernetes Engine (GKE).
- Implantação de cluster e orquestração de IA: você pode implantar suas cargas de trabalho de IA em clusters do GKE, clusters do Slurm ou instâncias do Compute Engine. Para mais informações, consulte Visão geral da criação de VMs e clusters
Outros recursos
Conheça os recursos de software
- O Pathways on Cloud é um sistema projetado para permitir a criação de sistemas de machine learning em grande escala, com várias tarefas e ativados esparsamente
- Otimize sua produtividade de ML usando nossas receitas de Goodput
- Agendar cargas de trabalho do GKE com o Agendamento com reconhecimento de topologia
- Teste uma das nossas receitas de comparativo de mercado para executar os modelos DeepSeek, Mixtral, Llama e GPT em GPUs
- Escolha uma opção de consumo para receber e usar recursos de computação com mais eficiência
Exemplos de clientes
Priceline: ajuda para os viajantes criarem experiências únicas
"Com a ajuda do Google Cloud na incorporação da IA generativa, podemos criar um concierge de viagens personalizado em nosso chatbot. Queremos ajudar nossos clientes a ir muito além do simples planejamento de uma viagem, proporcionando uma experiência de viagem única”. Martin Brodbeck, CTO, Priceline
Perguntas frequentes
Como o Hipercomputador de IA se compara ao uso de serviços de nuvem individuais?
Embora os serviços individuais ofereçam recursos específicos, o Hipercomputador de IA fornece um sistema integrado em que hardware, software e modelos de consumo são projetados para funcionar de maneira ideal juntos. Essa integração oferece eficiências no nível do sistema em desempenho, custo e tempo de lançamento no mercado que são mais difíceis de alcançar ao reunir serviços diferentes. Ele simplifica a complexidade e oferece uma abordagem holística para a infraestrutura de IA.
O Hipercomputador de IA pode ser usado em um ambiente híbrido ou multicloud?
Sim, o Hipercomputador de IA foi projetado para ser flexível. Tecnologias como o Cross-Cloud Interconnect oferecem conectividade de alta largura de banda a data centers no local e outras nuvens, facilitando estratégias de IA híbridas e multicloud. Operamos com padrões abertos e integramos softwares de terceiros conhecidos para que você possa criar soluções que abrangem vários ambientes e mudar de serviço quando quiser.
Como o Hipercomputador de IA aborda a segurança para cargas de trabalho de IA?
A segurança é um aspecto essencial do Hipercomputador de IA. Ele se beneficia do modelo de segurança em várias camadas do Google Cloud. Os recursos específicos incluem microcontroladores de segurança Titan (garantindo que os sistemas sejam inicializados a partir de um estado confiável), firewall RDMA (para rede de confiança zero entre TPUs/GPUs durante o treinamento) e integração com soluções como Model Armor para segurança de IA. Eles são complementados por políticas e princípios robustos de segurança de infraestrutura, como o framework de IA segura.
Qual é a maneira mais fácil de usar o Hipercomputador de IA como infraestrutura?
- Se você não quiser gerenciar VMs, recomendamos começar com o Google Kubernetes Engine (GKE)
- Se você precisar usar vários programadores ou não puder usar o GKE, recomendamos o uso do Cluster Director
- Se você quiser ter controle total sobre sua infraestrutura, a única maneira de conseguir isso é trabalhando diretamente com VMs. Para isso, o Compute Engine é a melhor opção.
Ele só é útil para cargas de trabalho grandes/de alta escala?
Não. O Hipercomputador de IA pode ser usado para cargas de trabalho de qualquer tamanho. Cargas de trabalho menores ainda aproveitam todos os benefícios de um sistema integrado, como eficiência e implantação simplificada. O Hipercomputador de IA também oferece suporte aos clientes à medida que os negócios deles crescem, desde pequenos experimentos e provas de conceito até implantações de produção em grande escala.
O Hipercomputador de IA é a maneira mais fácil de começar a usar cargas de trabalho de IA no Google Cloud?
Para a maioria dos clientes, uma plataforma de IA gerenciada como a Vertex AI é a maneira mais fácil de começar a usar a IA, porque ela tem todas as ferramentas, modelos e modelos integrados. Além disso, a Vertex AI é alimentada pelo Hipercomputador de IA nos bastidores de uma forma otimizada para você. A Vertex AI é a maneira mais fácil de começar porque é a experiência mais simples. Se você preferir configurar e otimizar cada componente da sua infraestrutura, poderá acessar os componentes do Hipercomputador de IA como infraestrutura e montá-los de acordo com suas necessidades.
Como o Hipercomputador de IA é um sistema combinável, há muitas opções. Você tem práticas recomendadas para cada caso de uso?
Sim, estamos criando uma biblioteca de receitas no GitHub. Você também pode usar o Cluster Toolkit para projetos de cluster pré-criados.
Quais são as opções disponíveis quando uso o Hipercomputador de IA como IaaS?
Hardware otimizado por IA
Armazenamento
- Treinamento: o Managed Lustre é ideal para treinamentos de IA exigentes com alta capacidade de processamento e capacidade em escala de PB. O GCS Fuse (opcionalmente com o Anywhere Cache) atende a necessidades de maior capacidade com latência mais relaxada. Ambos se integram ao GKE e ao Cluster Director.
- Inferência: o GCS Fuse com o Anywhere Cache oferece uma solução simples. Para um desempenho maior, considere o Hyperdisk ML. Se você usar o Managed Lustre para treinamento na mesma zona, ele também poderá ser usado para inferência.
Rede
- Treinamento: aproveite tecnologias como a rede RDMA em VPCs e o Cloud Interconnect e o Cross-Cloud Interconnect de alta largura de banda para transferência rápida de dados.
- Inferência: utilize soluções como o gateway de inferência do GKE e o Cloud Load Balancing aprimorado para veiculação de baixa latência. O Model Armor pode ser integrado para segurança da IA.
Computação: acesse as TPUs do Google Cloud (Trillium), GPUs da NVIDIA (Blackwell) e CPUs (Axion). Isso permite a otimização com base nas necessidades específicas da carga de trabalho para capacidade de processamento, latência ou TCO.
Software e frameworks abertos líderes
- Frameworks e bibliotecas de ML: PyTorch, JAX, TensorFlow, Keras, vLLM, JetStream, MaxText, LangChain, Hugging Face, NVIDIA (CUDA, NeMo, Triton) e muitas outras opções de código aberto e de terceiros.
- Compiladores, ambientes de execução e ferramentas: XLA (para desempenho e interoperabilidade), Pathways no Cloud, treinamento multislice, Cluster Toolkit (para blueprints de cluster pré-criados) e muitas outras opções de código aberto e de terceiros.
- Orquestração: Google Kubernetes Engine (GKE), Cluster Director (para Slurm, Kubernetes não gerenciado, programadores BYO) e Google Compute Engine (GCE).
Modelos de consumo:
- Sob demanda: pagamento por uso.
- Descontos por compromisso de uso (CUDs): economize significativamente (até 70%) em compromissos de longo prazo.
- VMs do Spot: ideais para jobs em lote tolerantes a falhas, oferecendo grandes descontos (até 91%).
- Dynamic Workload Scheduler (DWS): economize até 50% em jobs em lote/tolerantes a falhas.











