Addestra, ottimizza ed esegui l'erogazione su un supercomputer AI
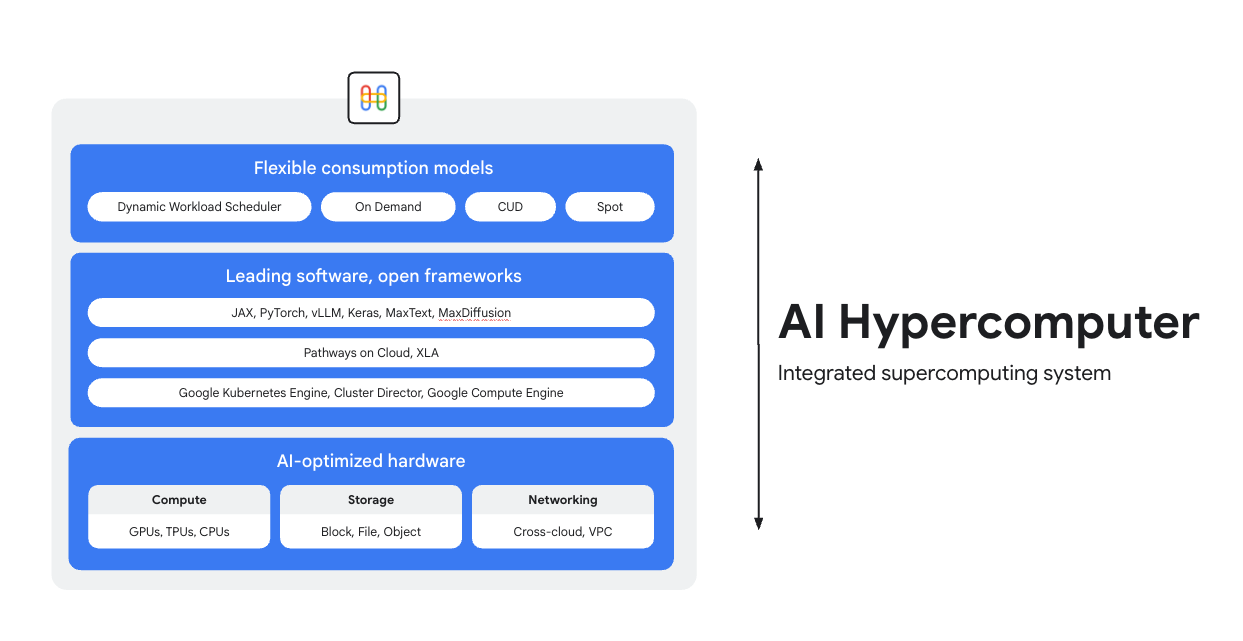
AI Hypercomputer è il sistema di supercomputing integrato alla base di ogni workload AI su Google Cloud. È composto da hardware, software e modelli di consumo progettati per semplificare il deployment dell'AI, migliorare l'efficienza a livello di sistema e ottimizzare i costi.
Panoramica
Hardware ottimizzato con l'IA
Scegli tra le opzioni di computing (inclusi gli acceleratori di AI), archiviazione e networking ottimizzate per gli obiettivi granulari a livello di workload, che si tratti di un maggiore throughput, una minore latenza, un time-to-results più rapido o un TCO più basso. Scopri di più su: Cloud TPU, Cloud GPU, oltre alle ultime novità in materia di archiviazione e networking.
Software leader del settore, framework aperti
Ottieni di più dal tuo hardware con un software leader del settore, integrato con framework aperti, librerie e compilatori per rendere più efficienti lo sviluppo, l'integrazione e la gestione dell'AI.
- Supporto per PyTorch, JAX, Keras, vLLM, Megatron-LM, NeMo Megatron, MaxText, MaxDiffusion e molti altri.
- L'integrazione profonda con il compilatore XLA consente l'interoperabilità tra diversi acceleratori, mentre Pathways su Cloud consente di utilizzare lo stesso runtime distribuito che alimenta l'infrastruttura interna di addestramento e inferenza su larga scala di Google.
- Tutto questo è implementabile nell'ambiente che preferisci, che si tratti di Google Kubernetes Engine, Cluster Director o Google Compute Engine.
Modelli di consumo flessibili
Le opzioni di consumo flessibili consentono ai clienti di scegliere costi fissi con sconti per impegno di utilizzo o modelli on demand dinamici per soddisfare le loro esigenze aziendali. Dynamic Workload Scheduler e le VM Spot possono aiutarti a ottenere la capacità di cui hai bisogno senza esagerare con l'allocazione. Inoltre, gli strumenti di ottimizzazione dei costi di Google Cloud aiutano ad automatizzare l'utilizzo delle risorse per ridurre le attività manuali per i tecnici.
Gestisci i modelli in modo economico su larga scala
Massimizza il rapporto prezzo/prestazioni e l'affidabilità per i workload di inferenza
L'inferenza sta diventando rapidamente più diversificata e complessa, evolvendosi in tre aree principali:
- Innanzitutto, sta cambiando il modo in cui interagiamo con l'AI. Ora le conversazioni hanno un contesto molto più lungo e diversificato.
- In secondo luogo, il ragionamento sofisticato e l'inferenza in più fasi stanno rendendo più comuni i modelli Mixture-of-Experts (MoE). Questo sta ridefinendo il modo in cui la memoria e il calcolo vengono scalati dall'input iniziale all'output finale.
- Infine, è chiaro che il vero valore non riguarda solo i token grezzi per dollaro, ma l'utilità della risposta. Il modello ha le competenze giuste? Ha risposto correttamente a una domanda aziendale cruciale? Ecco perché riteniamo che i clienti abbiano bisogno di misurazioni migliori, che si concentrino sul costo totale delle operazioni di sistema, non sul prezzo dei processori.
Esplora le risorse di inferenza AI
- Che cos'è l'inferenza AI? La nostra guida completa a tipi, confronti e casi d'uso
- Esegui le best practice per le formule di inferenza con GKE Inference Quickstart
- Segui un corso sull'inferenza AI su Cloud Run
- Guarda questo video sul segreto per un'inferenza AI conveniente
- Scopri come accelerare i workload di inferenza AI
L'AI trasforma i tifosi in designer di kit sportivi
PUMA ha stretto una partnership con Google Cloud per la sua infrastruttura di AI integrata (AI Hypercomputer), che le consente di utilizzare Gemini per i prompt degli utenti insieme a Dynamic Workload Scheduler per scalare dinamicamente l'inferenza sulle GPU, riducendo drasticamente i costi e i tempi di generazione.
Impatto:
- Hanno ridotto il tempo di generazione del kit AI da 2-5 minuti a soli 30 secondi. Ciò ha trasformato la piattaforma in un'esperienza veloce e davvero interattiva che ha mantenuto gli utenti coinvolti.
- In soli 10 giorni, i fan hanno creato 180.000 kit e hanno espresso 1,7 milioni di valutazioni.
- Il progetto ha dimostrato un nuovo modo per PUMA di entrare in contatto con la sua community. È andata oltre il semplice rapporto brand-consumatore trasformando con successo i fan in co-creatori attivi, fornendo all'azienda informazioni dirette e in tempo reale sui desideri creativi dei suoi consumatori più appassionati.



Procedure
Massimizza il rapporto prezzo/prestazioni e l'affidabilità per i workload di inferenza
L'inferenza sta diventando rapidamente più diversificata e complessa, evolvendosi in tre aree principali:
- Innanzitutto, sta cambiando il modo in cui interagiamo con l'AI. Ora le conversazioni hanno un contesto molto più lungo e diversificato.
- In secondo luogo, il ragionamento sofisticato e l'inferenza in più fasi stanno rendendo più comuni i modelli Mixture-of-Experts (MoE). Questo sta ridefinendo il modo in cui la memoria e il calcolo vengono scalati dall'input iniziale all'output finale.
- Infine, è chiaro che il vero valore non riguarda solo i token grezzi per dollaro, ma l'utilità della risposta. Il modello ha le competenze giuste? Ha risposto correttamente a una domanda aziendale cruciale? Ecco perché riteniamo che i clienti abbiano bisogno di misurazioni migliori, che si concentrino sul costo totale delle operazioni di sistema, non sul prezzo dei processori.
Risorse aggiuntive
Esplora le risorse di inferenza AI
- Che cos'è l'inferenza AI? La nostra guida completa a tipi, confronti e casi d'uso
- Esegui le best practice per le formule di inferenza con GKE Inference Quickstart
- Segui un corso sull'inferenza AI su Cloud Run
- Guarda questo video sul segreto per un'inferenza AI conveniente
- Scopri come accelerare i workload di inferenza AI
Esempi di clienti
L'AI trasforma i tifosi in designer di kit sportivi
PUMA ha stretto una partnership con Google Cloud per la sua infrastruttura di AI integrata (AI Hypercomputer), che le consente di utilizzare Gemini per i prompt degli utenti insieme a Dynamic Workload Scheduler per scalare dinamicamente l'inferenza sulle GPU, riducendo drasticamente i costi e i tempi di generazione.
Impatto:
- Hanno ridotto il tempo di generazione del kit AI da 2-5 minuti a soli 30 secondi. Ciò ha trasformato la piattaforma in un'esperienza veloce e davvero interattiva che ha mantenuto gli utenti coinvolti.
- In soli 10 giorni, i fan hanno creato 180.000 kit e hanno espresso 1,7 milioni di valutazioni.
- Il progetto ha dimostrato un nuovo modo per PUMA di entrare in contatto con la sua community. È andata oltre il semplice rapporto brand-consumatore trasformando con successo i fan in co-creatori attivi, fornendo all'azienda informazioni dirette e in tempo reale sui desideri creativi dei suoi consumatori più appassionati.
Esegui addestramento e preaddestramento dell'AI su larga scala
Addestramento su IA potente, scalabile ed efficiente
I workload di addestramento devono essere eseguiti come job altamente sincronizzati su migliaia di nodi in cluster strettamente accoppiati. Un singolo nodo degradato può interrompere un intero job, ritardando il time-to-market. Devi:
- Assicurarti che il cluster sia configurato rapidamente e ottimizzato per il workload in questione
- Prevedi gli errori e risolvili rapidamente
- e continua a lavorare con un workload, anche quando si verificano errori
Vogliamo rendere estremamente semplice per i clienti eseguire il deployment e la scalabilità dei workload di addestramento su Google Cloud.
Addestramento su IA potente, scalabile ed efficiente
Per creare un cluster AI, inizia con uno dei nostri tutorial:
- Crea un cluster Slurm con GPU (VM A4) e Cluster Toolkit
- Crea un cluster GKE con Cluster Director per GKE o Cluster Toolkit
Moloco ha creato una piattaforma di pubblicazione di annunci per elaborare miliardi di richieste giornaliere
Moloco si è affidata allo stack completamente integrato di AI Hypercomputer per scalare automaticamente su hardware avanzato come TPU e GPU, il che ha liberato gli ingegneri di Moloco, mentre l'integrazione con la piattaforma di dati leader del settore di Google ha creato un sistema coeso ed end-to-end per i workload di AI.
Dopo aver lanciato i suoi primi modelli di deep learning, Moloco ha registrato una crescita e una redditività esponenziali, quintuplicando i risultati in 2 anni e mezzo.
- Addestramento dei modelli 10 volte più rapido con le TPU Cloud su GKE, oltre a una riduzione dei costi di addestramento pari a 4 volte
- Scalato per servire oltre 1000 utenti interni, dando loro accesso a un sistema di machine learning su scala planetaria che li aiuta a trovare una crescita redditizia dai propri dati


AssemblyAI
AssemblyAI utilizza Google Cloud per addestrare i modelli in modo rapido e su larga scala

LG AI Research ha ridotto drasticamente i costi e accelerato lo sviluppo rispettando al contempo i rigorosi requisiti di sicurezza e residenza dei dati

Anthropic ha annunciato l'intenzione di accedere a un massimo di 1 milione di TPU per addestrare e distribuire i modelli Claude, per un valore di decine di miliardi di dollari. Ma come vengono eseguite su Google Cloud? Guarda questo video per scoprire come Anthropic si sta spingendo oltre i limiti del computing dell'AI su larga scala con GKE.
Procedure
Addestramento su IA potente, scalabile ed efficiente
I workload di addestramento devono essere eseguiti come job altamente sincronizzati su migliaia di nodi in cluster strettamente accoppiati. Un singolo nodo degradato può interrompere un intero job, ritardando il time-to-market. Devi:
- Assicurarti che il cluster sia configurato rapidamente e ottimizzato per il workload in questione
- Prevedi gli errori e risolvili rapidamente
- e continua a lavorare con un workload, anche quando si verificano errori
Vogliamo rendere estremamente semplice per i clienti eseguire il deployment e la scalabilità dei workload di addestramento su Google Cloud.
Risorse aggiuntive
Addestramento su IA potente, scalabile ed efficiente
Per creare un cluster AI, inizia con uno dei nostri tutorial:
- Crea un cluster Slurm con GPU (VM A4) e Cluster Toolkit
- Crea un cluster GKE con Cluster Director per GKE o Cluster Toolkit
Esempi di clienti
Moloco ha creato una piattaforma di pubblicazione di annunci per elaborare miliardi di richieste giornaliere
Moloco si è affidata allo stack completamente integrato di AI Hypercomputer per scalare automaticamente su hardware avanzato come TPU e GPU, il che ha liberato gli ingegneri di Moloco, mentre l'integrazione con la piattaforma di dati leader del settore di Google ha creato un sistema coeso ed end-to-end per i workload di AI.
Dopo aver lanciato i suoi primi modelli di deep learning, Moloco ha registrato una crescita e una redditività esponenziali, quintuplicando i risultati in 2 anni e mezzo.
- Addestramento dei modelli 10 volte più rapido con le TPU Cloud su GKE, oltre a una riduzione dei costi di addestramento pari a 4 volte
- Scalato per servire oltre 1000 utenti interni, dando loro accesso a un sistema di machine learning su scala planetaria che li aiuta a trovare una crescita redditizia dai propri dati
AssemblyAI
AssemblyAI utilizza Google Cloud per addestrare i modelli in modo rapido e su larga scala
LG AI Research ha ridotto drasticamente i costi e accelerato lo sviluppo rispettando al contempo i rigorosi requisiti di sicurezza e residenza dei dati
Anthropic ha annunciato l'intenzione di accedere a un massimo di 1 milione di TPU per addestrare e distribuire i modelli Claude, per un valore di decine di miliardi di dollari. Ma come vengono eseguite su Google Cloud? Guarda questo video per scoprire come Anthropic si sta spingendo oltre i limiti del computing dell'AI su larga scala con GKE.
Esegui il deployment e orchestra le applicazioni di AI
Sfrutta software di orchestrazione dell'AI e framework aperti leader del settore per offrire esperienze basate sull'AI
Google Cloud fornisce immagini che contengono sistemi operativi, framework, librerie e driver comuni. AI Hypercomputer ottimizza queste immagini preconfigurate per supportare i tuoi workload di AI.
- Framework e librerie di AI e ML: utilizza le immagini Docker Deep Learning Software Layer (DLSL) per eseguire modelli ML come NeMO e MaxText su un cluster Google Kubernetes Engine (GKE)
- Deployment del cluster e orchestrazione dell'AI: puoi eseguire il deployment dei tuoi workload di AI su cluster GKE, cluster Slurm o istanze Compute Engine; per ulteriori informazioni, vedi Panoramica della creazione di VM e cluster
Esplora le risorse software
- Pathways su Cloud è un sistema progettato per consentire la creazione di sistemi di machine learning su larga scala, multi-task e attivati in modo sparso
- Ottimizza la tua produttività ML sfruttando le nostre formule Goodput
- Pianifica i workload GKE con la Topology Aware Scheduling
- Prova una delle nostre ricette di benchmarking per l'esecuzione dei modelli DeepSeek, Mixtral, Llama e GPT su GPU
- Scegli un'opzione di consumo per ottenere e utilizzare le risorse di computing in modo più efficiente
Priceline: aiutare i viaggiatori a organizzare esperienze uniche
"Lavorare con Google Cloud per incorporare l'AI generativa ci consente di creare un Concierge di viaggio su misura all'interno del nostro chatbot. Vogliamo che i nostri clienti vadano oltre la pianificazione di un viaggio aiutandoli a rendere unica la loro esperienza di viaggio." Martin Brodbeck, CTO, Priceline




Procedure
Sfrutta software di orchestrazione dell'AI e framework aperti leader del settore per offrire esperienze basate sull'AI
Google Cloud fornisce immagini che contengono sistemi operativi, framework, librerie e driver comuni. AI Hypercomputer ottimizza queste immagini preconfigurate per supportare i tuoi workload di AI.
- Framework e librerie di AI e ML: utilizza le immagini Docker Deep Learning Software Layer (DLSL) per eseguire modelli ML come NeMO e MaxText su un cluster Google Kubernetes Engine (GKE)
- Deployment del cluster e orchestrazione dell'AI: puoi eseguire il deployment dei tuoi workload di AI su cluster GKE, cluster Slurm o istanze Compute Engine; per ulteriori informazioni, vedi Panoramica della creazione di VM e cluster
Risorse aggiuntive
Esplora le risorse software
- Pathways su Cloud è un sistema progettato per consentire la creazione di sistemi di machine learning su larga scala, multi-task e attivati in modo sparso
- Ottimizza la tua produttività ML sfruttando le nostre formule Goodput
- Pianifica i workload GKE con la Topology Aware Scheduling
- Prova una delle nostre ricette di benchmarking per l'esecuzione dei modelli DeepSeek, Mixtral, Llama e GPT su GPU
- Scegli un'opzione di consumo per ottenere e utilizzare le risorse di computing in modo più efficiente
Esempi di clienti
Priceline: aiutare i viaggiatori a organizzare esperienze uniche
"Lavorare con Google Cloud per incorporare l'AI generativa ci consente di creare un Concierge di viaggio su misura all'interno del nostro chatbot. Vogliamo che i nostri clienti vadano oltre la pianificazione di un viaggio aiutandoli a rendere unica la loro esperienza di viaggio." Martin Brodbeck, CTO, Priceline
Domande frequenti
Come si confronta AI Hypercomputer con l'utilizzo di singoli servizi cloud?
Mentre i singoli servizi offrono funzionalità specifiche, AI Hypercomputer fornisce un sistema integrato in cui hardware, software e modelli di consumo sono progettati per funzionare in modo ottimale insieme. Questa integrazione offre efficienze a livello di sistema in termini di prestazioni, costi e time-to-market più difficili da ottenere mettendo insieme servizi disparati. Semplifica la complessità e fornisce un approccio olistico all'infrastruttura di AI.
AI Hypercomputer può essere utilizzato in un ambiente ibrido o multi-cloud?
Sì, AI Hypercomputer è progettato pensando alla flessibilità. Tecnologie come Cross-Cloud Interconnect forniscono connettività a larghezza di banda elevata ai data center on-premise e ad altri cloud, facilitando le strategie di AI ibride e multi-cloud. Operiamo con standard aperti e integriamo software di terze parti popolari per consentirti di creare soluzioni che si estendono su più ambienti e di modificare i servizi a tuo piacimento.
In che modo AI Hypercomputer affronta la sicurezza per i workload di AI?
La sicurezza è un aspetto fondamentale di AI Hypercomputer. Sfrutta il modello di sicurezza a più livelli di Google Cloud. Le funzionalità specifiche includono microcontroller di sicurezza Titan (che garantiscono l'avvio dei sistemi da uno stato attendibile), RDMA Firewall (per la rete zero-trust tra TPU/GPU durante l'addestramento) e l'integrazione con soluzioni come Model Armor per la sicurezza dell'AI. Questi sono integrati da solide policy e principi di sicurezza dell'infrastruttura come il Secure AI Framework.
Qual è il modo più semplice per utilizzare AI Hypercomputer come infrastruttura?
- Se non vuoi gestire le VM, ti consigliamo di iniziare a usare Google Kubernetes Engine (GKE)
- Se devi utilizzare più scheduler o non puoi utilizzare GKE, ti consigliamo di utilizzare Cluster Director
- Se vuoi avere il controllo completo sulla tua infrastruttura, l'unico modo per ottenerlo è lavorare direttamente con le VM e, per questo, Compute Engine è la soluzione migliore
È utile solo per i workload di grandi dimensioni o su larga scala?
No. AI Hypercomputer può essere utilizzato per workload di qualsiasi dimensione. Anche i workload di dimensioni più ridotte possono sfruttare tutti i vantaggi di un sistema integrato, come l'efficienza e la semplificazione del deployment. AI Hypercomputer supporta inoltre i clienti man mano che le loro attività si espandono, dai piccoli proof-of-concept e dagli esperimenti ai deployment di produzione su larga scala.
AI Hypercomputer è il modo più semplice per iniziare a utilizzare i workload di AI su Google Cloud?
Per la maggior parte dei clienti, una piattaforma di AI gestita come Vertex AI è il modo più semplice per iniziare a utilizzare l'AI perché include tutti gli strumenti, i modelli e i modelli. Inoltre, Vertex AI è basato su AI Hypercomputer in modo ottimizzato per te. Vertex AI è il modo più semplice per iniziare perché offre l'esperienza più semplice. Se preferisci configurare e ottimizzare ogni componente della tua infrastruttura, puoi accedere ai componenti di AI Hypercomputer come infrastruttura e assemblarli in modo da soddisfare le tue esigenze.
Poiché AI Hypercomputer è un sistema componibile, ci sono molte opzioni. Hai best practice per ogni caso d'uso?
Sì, stiamo creando una libreria di formule in GitHub. Puoi utilizzare Cluster Toolkit anche per i progetti di cluster predefiniti.
Quali sono le opzioni disponibili quando utilizzo AI Hypercomputer come IaaS?
Hardware ottimizzato con l'IA
Archiviazione
- Addestramento: Managed Lustre è ideale per l'addestramento AI impegnativo con throughput elevato e capacità su scala PB. GCS Fuse (facoltativamente con Anywhere Cache) è adatto a esigenze di capacità maggiori con una latenza più rilassata. Entrambi si integrano con GKE e Cluster Director.
- Inferenza: GCS Fuse con Anywhere Cache offre una soluzione semplice. Per prestazioni più elevate, prendi in considerazione Hyperdisk ML. Se si utilizza Managed Lustre per l'addestramento nella stessa zona, può essere utilizzato anche per l'inferenza.
Networking
- Addestramento: sfrutta tecnologie come il networking RDMA nei VPC e Cloud Interconnect e Cross-Cloud Interconnect a larghezza di banda elevata per un rapido trasferimento dei dati.
- Inferenza: utilizza soluzioni come GKE Inference Gateway e Cloud Load Balancing avanzato per la distribuzione a bassa latenza. Model Armor può essere integrato per la sicurezza dell'AI.
Calcolo: accedi a TPU Google Cloud (Trillium), GPU NVIDIA (Blackwell) e CPU (Axion). Ciò consente l'ottimizzazione in base alle esigenze specifiche del workload per quanto riguarda velocità effettiva, latenza o TCO.
Software leader del settore e framework aperti
- Framework e librerie ML: PyTorch, JAX, TensorFlow, Keras, vLLM, JetStream, MaxText, LangChain, Hugging Face, NVIDIA (CUDA, NeMo, Triton) e molte altre opzioni open source e di terze parti.
- Compilatori, runtime e strumenti: XLA (per prestazioni e interoperabilità), Pathways su Cloud, addestramento multislice, Cluster Toolkit (per blueprint di cluster predefiniti) e molte altre opzioni open source e di terze parti.
- Orchestrazione: Google Kubernetes Engine (GKE), Cluster Director (per Slurm, Kubernetes non gestito, scheduler BYO) e Google Compute Engine (GCE).
Modelli di consumo:
- On demand: pagamento a consumo.
- Sconti per impegno di utilizzo (CUD): risparmia in modo significativo (fino al 70%) per gli impegni a lungo termine.
- VM spot: ideali per job batch a tolleranza di errore, offrono sconti elevati (fino al 91%).
- Dynamic Workload Scheduler (DWS): risparmia fino al 50% per i job batch/a tolleranza di errore.











