L'avenir de l'infrastructure d'IA
L'avenir de l'infrastructure d'IA
AI Hypercomputer est une architecture qui combine du matériel conçu sur mesure, des logiciels ouverts et des modèles de consommation flexibles. Chaque composant est soigneusement intégré pour fonctionner en synergie, ce qui améliore vos performances, réduit vos coûts et augmente la productivité des développeurs.

Entraînement plus rapide et plus intelligent
Entraînement plus rapide et plus intelligent
Créez des modèles en quelques semaines, et non en plusieurs mois. Utilisez la pile d'entraînement de Google pour accélérer le développement et les tests sans sacrifier les performances.

Entraîner et adapter des LLM plus rapidement
Développez des LLM 36 % plus rapidement et gagnez jusqu'à 97 % de productivité (Goodput) sur chaque accélérateur grâce aux TPU 8t, associés à des logiciels conçus en collaboration avec Google DeepMind et intégrés à des frameworks Open Source, de Pathways à Pallas (entraînement) et de Ray à Agent Sandbox (réglage).Nous savons également qu'il n'existe pas de solution unique. C'est pourquoi nous collaborons étroitement avec NVIDIA pour proposer les GPU les plus récents. Google Cloud fera partie des premiers à proposer des instances basées sur la nouvelle génération NVIDIA Vera Rubin NVL72 lorsqu'elle sera disponible dans le courant de l'année.
Entraîner des modèles légers plus intelligemment à l'aide de données propriétaires
Utilisez Gemini Enterprise Agent Platform avec BigQuery pour entraîner des modèles sur des données propriétaires 16 fois plus vite en combinant votre parc de données, le développement de ML et les accélérateurs en un seul et même endroit. Les deux sont basés sur AI Hypercomputer, que vous utilisiez des VM G4 ou des TPU Ironwood.
Créer des agents physiques adaptatifs avec MuJoCo-Warp
Exécutez des simulations basées sur des GPU sur MuJoCo-Warp de DeepMind, jusqu'à 100 fois plus rapidement qu'avec MuJoCo standard. Ensuite, simulez des cas particuliers impossibles, risqués ou coûteux à l'aide de supports synthétiques provenant de Veo, Genie et Nano Banana, ou ingérez des pétaoctets de données de capteurs réelles dans BigQuery. Pour en savoir plus sur la création d'agents physiques sur Google Cloud, cliquez ici.
Inférence réactive et efficace
Inférence réactive et efficace
Obtenez des profils de modèles validés, ainsi que des logiciels Google et ouverts entièrement intégrés pour améliorer la réactivité des applications avec moins de complexité et de gaspillage.
Diffuser des LLM avec une latence quasi nulle
Utilisez des technologies d'inférence intégrées pour fournir aux clients des services utiles et réactifs. Réduisez le délai d'émission du premier jeton de 71 % avec GKE Inference Gateway, traitez jusqu'à 120 000 jetons par seconde avec llm-d pour la diffusion désagrégée et chargez les modèles cinq fois plus rapidement avec Rapid Cache et TPU 8i pour que votre mémoire de travail soit exactement là où elle est nécessaire.
Mettre en service des modèles prédéfinis de vision, de perception et de médias
Déployez des modèles de ML classiques 70 % plus rapidement en utilisant l'un des modèles parmi plus de 200 disponibles sur Gemini Enterprise Agent Platform, en choisissant un TPU ou un GPU, y compris les VM A5X (NVIDIA Vera Rubin) et les TPU 8i lorsqu'ils seront disponibles plus tard cette année.
Exécuter des agents de manière sûre et économique
Exécutez des essaims d'agents de manière sécurisée dans GKE Agent Sandbox, en provisionnant jusqu'à 300 environnements en bac à sable par seconde, tout en les mettant en pause et en les réactivant selon vos besoins. Vous ne payez donc jamais pour des agents inactifs.
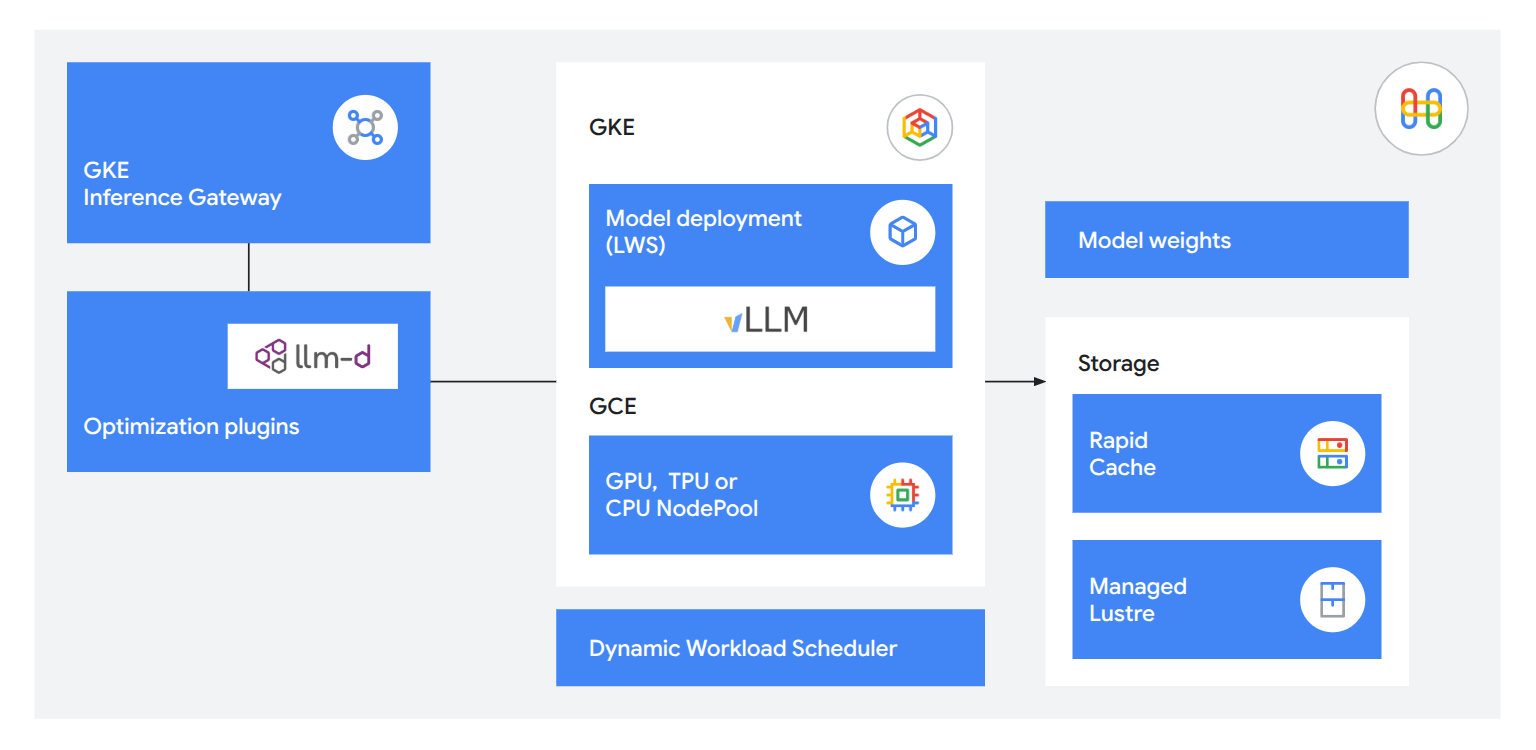
Opérations flexibles, ouvertes et fiables
Opérations flexibles, ouvertes et fiables
Utilisez n'importe quel framework ou accélérateur dans des environnements hybrides et multicloud avec une maintenance et une gestion automatisées des clusters adaptées à l'exascale.

Passer des TPU aux GPU sans réécrire le code
TorchTPU supprime la courbe d'apprentissage des TPU pour les développeurs en fournissant une prise en charge native de PyTorch. Vous pouvez ainsi utiliser l'accélérateur le plus adapté sans avoir à réécrire du code complexe.
Déployer l'IA dans n'importe quel environnement, à pratiquement n'importe quelle échelle
Basé sur Kubernetes Open Source, GKE vous offre une portabilité multicloud à l'échelle de l'entreprise, en prenant en charge jusqu'à 130 000 nœuds tout en s'intégrant de façon native à Agent Platform et Google Distributed Cloud pour les déploiements hybrides.
Automatiser la maintenance des clusters grâce à des outils avancés de diagnostic et d'observabilité
Chaque accélérateur d'AI Hypercomputer est compatible avec les capacités de Cluster Director, y compris un bilan de santé avant déploiement, des tableaux de bord d'observabilité à 360 degrés et des vérifications de l'état toujours activées.
Connecter des charges de travail multicloud en quelques minutes au lieu de plusieurs semaines
Connectez des services entre différents clouds sans latence grâce à Cross-Cloud Network, une infrastructure réseau de confiance utilisée par plus de 65 % des entreprises figurant dans la liste du Fortune 100 et qui traite plus de 27 exaoctets de données par mois.
Obtenir la capacité d'accélération adaptée à vos besoins
Nos modèles de consommation flexibles vous offrent plusieurs façons de planifier des accélérateurs et de réduire leur coût. Économisez jusqu'à 91% sur les jobs par lot ou tolérants aux pannes avec les VM Spot, jusqu'à 50% sur les jobs avec une date de début flexible grâce au programmeur de charge de travail dynamique, et jusqu'à 50% en vous inscrivant aux remises sur engagement d'utilisation.
Systèmes prêts pour les agents
Systèmes prêts pour les agents
Repousser les limites des performances et utiliser l'énergie de manière responsable à mesure que vous évoluez sur l'infrastructure de base à laquelle font confiance Google et les laboratoires d'IA de pointe
Réduire les risques de votre feuille de route IA sur une base fiable
Google Cloud prend en charge 9 des 10 principaux laboratoires d'IA et 70 % des start-up d'IA financées. En déployant sur AI Hypercomputer, vous utilisez des centres de données qui ont traité de manière fiable plus de 100 milliards de jetons pour près de 350 clients rien qu'en décembre 2025.
Atteindre une efficacité énergétique de référence dans l'industrie
Les centres de données de Google Cloud, y compris AI Hypercomputer, offrent une efficacité énergétique de pointe, avec une puissance de calcul six fois supérieure par unité d'électricité par rapport à il y a cinq ans. Cela permet à notre TPU de 8e génération d'offrir un rapport prix/performances 80% supérieur et une efficacité énergétique 20% supérieure à celle de la génération précédente.
Réduire votre impact sur le réseau et les communautés
Nous nous engageons à payer 100% de l'énergie utilisée par nos centres de données et tous les coûts d'infrastructure supplémentaires directement liés à notre croissance. Collaborez avec nous pour que les foyers et les entreprises locales ne fassent pas les frais de vos ambitions en matière d'IA. Au cours des prochaines années, nous allons financer de nouvelles sources d'énergie et infrastructures pour alimenter nos modèles, et continuer à investir dans des sources d'énergie alternatives comme le nucléaire avancé, la géothermie et le stockage longue durée.
Protéger votre propriété intellectuelle la plus précieuse, du silicium à la périphérie
L'architecture Titanium et ses puces Titan personnalisées offrent une racine de confiance matérielle vérifiable et une sécurité zéro confiance. Une analyse indépendante de cloudvulndb.org montre que nos systèmes présentent jusqu'à 70 % de failles critiques en moins que les autres principaux clouds.
Au service des plus grands innovateurs du monde










En savoir plus sur AI Hypercomputer
- IDC : la valeur commerciale d'AI HypercomputerCe rapport IDC explore l'impact réel d'AI Hypercomputer sur les charges de travail d'IA pour les clients. Lisez le rapport complet pour découvrir les données client illustrant une amélioration de 353% du ROI, une efficacité accrue de 55% des équipes informatiques et une réduction de 67% des temps d'arrêt non planifiés des applications/charges de travail.
Temps de lecture : 5 min
Lire le rapport - Gartner® désigne Google comme l'un des leaders dans son rapport "Magic Quadrant for Strategic Cloud Platform Services"Pour la huitième année consécutive, Gartner® a désigné Google comme l'un des leaders du marché dans son rapport "Magic Quadrant™ for Strategic Cloud Platform Services". Cette année marque toutefois une étape majeure : Google est désormais classé en tête en termes vision globale.
Temps de lecture : 5 min
Voir les résultats - Google figure parmi les leaders du marché dans le rapport "The Forrester Wave™: AI Infrastructure Solutions" (Solutions d'infrastructure d'IA) du quatrième trimestre 2025Google a obtenu le meilleur score de tous les fournisseurs dans la catégorie "Offre actuelle" et a reçu la note maximale dans 16 des 19 critères d'évaluation, y compris, mais sans s'y limiter à la vision, l'architecture, l'entraînement, l'inférence, l'efficacité et la sécurité.
Temps de lecture : 5 min
Voir les résultats
- Concevoir et déployer votre première pile d'inférenceDécouvrez les composants essentiels qui constituent une solution d'inférence sur Google Cloud, de GKE à Cloud TPU, en passant par TensorFlow, PyTorch, JAX et Keras.
Cours de 2 heures
Suivre le cours - Utiliser vLLM sur GKE pour diffuser l'inférence Gemma 3 27BCe tutoriel explique comment déployer et diffuser un grand modèle de langage (LLM) Gemma 3 27B avec le framework de diffusion vLLM. Vous déployez Gemma 3 sur une instance de machine virtuelle (VM) A4 unique sur Google Kubernetes Engine (GKE).
Guide de 15 minutes
Suivre le tutoriel - Ajuster Gemma 3 sur un cluster GKE A4Ce tutoriel explique comment affiner un grand modèle de langage (LLM) Gemma 3 sur un cluster GKE à nœuds et GPU multiples sur Google Cloud. Ce cluster utilise une instance de machine virtuelle (VM) A4 dotée de huit GPU NVIDIA B200.
Guide de 15 minutes
Suivre le tutoriel
- Entraîner Qwen2 sur un cluster Slurm A4Ce tutoriel explique comment entraîner un grand modèle de langage (LLM) sur un cluster Slurm à nœuds et GPU multiples sur Google Cloud. Le modèle que vous utilisez dans ce tutoriel est basé sur un modèle Qwen2 à 1,5 milliard de paramètres. Le cluster Slurm utilise deux machines virtuelles a4-highgpu-8g, chacune dotée de huit GPU NVIDIA B200.
Guide de 15 minutes
Suivre le tutoriel - Diffuser Qwen2-7B-Instruct avec vLLM sur des TPUCe tutoriel explique comment diffuser le modèle Qwen/Qwen2-7B-Instruct à l'aide du framework de diffusion vLLM TPU sur une VM TPU v6e.
Guide de 15 minutes
Suivre le tutoriel
- Commencer iciConsultez toute la documentation disponible sur AI Hypercomputer, y compris des conseils sur l'architecture, le déploiement, la gestion, les tests et l'optimisation.Lire toute la documentation
- Recommandations pour l'entraînementDécouvrez les options d'accélérateur, les modèles de consommation recommandés et les services de stockage à utiliser lors du pré-entraînement des modèles.
Temps de lecture : 15 min
Lire la documentation - Recommandations pour l'inférenceDécouvrez les options d'accélérateur, les modèles de consommation recommandés et le service de stockage à utiliser pour l'inférence.
Temps de lecture : 15 min
Lire la documentation
Insights d'analystes
- IDC : la valeur commerciale d'AI HypercomputerCe rapport IDC explore l'impact réel d'AI Hypercomputer sur les charges de travail d'IA pour les clients. Lisez le rapport complet pour découvrir les données client illustrant une amélioration de 353% du ROI, une efficacité accrue de 55% des équipes informatiques et une réduction de 67% des temps d'arrêt non planifiés des applications/charges de travail.
Temps de lecture : 5 min
Lire le rapport - Gartner® désigne Google comme l'un des leaders dans son rapport "Magic Quadrant for Strategic Cloud Platform Services"Pour la huitième année consécutive, Gartner® a désigné Google comme l'un des leaders du marché dans son rapport "Magic Quadrant™ for Strategic Cloud Platform Services". Cette année marque toutefois une étape majeure : Google est désormais classé en tête en termes vision globale.
Temps de lecture : 5 min
Voir les résultats - Google figure parmi les leaders du marché dans le rapport "The Forrester Wave™: AI Infrastructure Solutions" (Solutions d'infrastructure d'IA) du quatrième trimestre 2025Google a obtenu le meilleur score de tous les fournisseurs dans la catégorie "Offre actuelle" et a reçu la note maximale dans 16 des 19 critères d'évaluation, y compris, mais sans s'y limiter à la vision, l'architecture, l'entraînement, l'inférence, l'efficacité et la sécurité.
Temps de lecture : 5 min
Voir les résultats
Tutoriels
- Concevoir et déployer votre première pile d'inférenceDécouvrez les composants essentiels qui constituent une solution d'inférence sur Google Cloud, de GKE à Cloud TPU, en passant par TensorFlow, PyTorch, JAX et Keras.
Cours de 2 heures
Suivre le cours - Utiliser vLLM sur GKE pour diffuser l'inférence Gemma 3 27BCe tutoriel explique comment déployer et diffuser un grand modèle de langage (LLM) Gemma 3 27B avec le framework de diffusion vLLM. Vous déployez Gemma 3 sur une instance de machine virtuelle (VM) A4 unique sur Google Kubernetes Engine (GKE).
Guide de 15 minutes
Suivre le tutoriel - Ajuster Gemma 3 sur un cluster GKE A4Ce tutoriel explique comment affiner un grand modèle de langage (LLM) Gemma 3 sur un cluster GKE à nœuds et GPU multiples sur Google Cloud. Ce cluster utilise une instance de machine virtuelle (VM) A4 dotée de huit GPU NVIDIA B200.
Guide de 15 minutes
Suivre le tutoriel
- Entraîner Qwen2 sur un cluster Slurm A4Ce tutoriel explique comment entraîner un grand modèle de langage (LLM) sur un cluster Slurm à nœuds et GPU multiples sur Google Cloud. Le modèle que vous utilisez dans ce tutoriel est basé sur un modèle Qwen2 à 1,5 milliard de paramètres. Le cluster Slurm utilise deux machines virtuelles a4-highgpu-8g, chacune dotée de huit GPU NVIDIA B200.
Guide de 15 minutes
Suivre le tutoriel - Diffuser Qwen2-7B-Instruct avec vLLM sur des TPUCe tutoriel explique comment diffuser le modèle Qwen/Qwen2-7B-Instruct à l'aide du framework de diffusion vLLM TPU sur une VM TPU v6e.
Guide de 15 minutes
Suivre le tutoriel
Documentation
- Commencer iciConsultez toute la documentation disponible sur AI Hypercomputer, y compris des conseils sur l'architecture, le déploiement, la gestion, les tests et l'optimisation.Lire toute la documentation
- Recommandations pour l'entraînementDécouvrez les options d'accélérateur, les modèles de consommation recommandés et les services de stockage à utiliser lors du pré-entraînement des modèles.
Temps de lecture : 15 min
Lire la documentation - Recommandations pour l'inférenceDécouvrez les options d'accélérateur, les modèles de consommation recommandés et le service de stockage à utiliser pour l'inférence.
Temps de lecture : 15 min
Lire la documentation












