Entrena, ajusta y sirve en un superordenador de IA
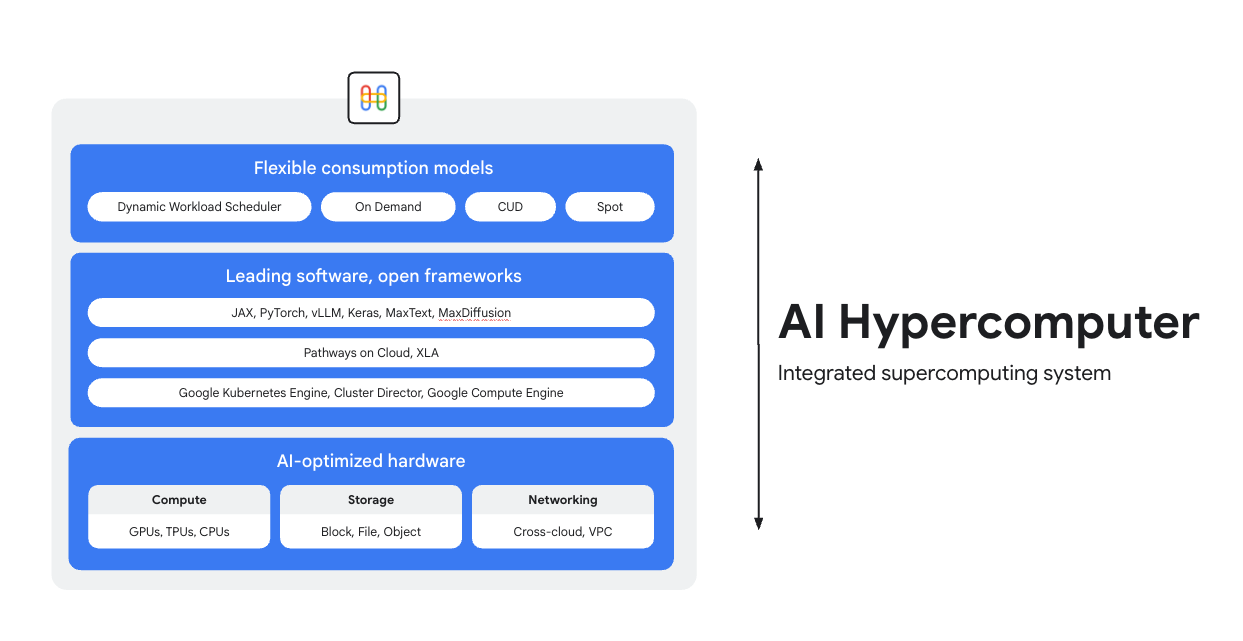
AI Hypercomputer es el sistema de supercomputación integrado que se encuentra detrás de todas las cargas de trabajo de IA en Google Cloud. Se compone de hardware, software y modelos de consumo diseñados para simplificar el despliegue de la IA, mejorar la eficiencia a nivel de sistema y optimizar los costes.
Información general
Hardware optimizado para IA
Elige entre opciones de computación (incluidos aceleradores de IA), almacenamiento y redes optimizadas para objetivos específicos a nivel de carga de trabajo, ya sea un mayor rendimiento, una latencia más baja, un tiempo de obtención de resultados más rápido o un menor coste total de propiedad. Consulta más información sobre: TPUs de Cloud, GPUs de Cloud y las últimas novedades en almacenamiento y redes.
Software líder, frameworks abiertos
Saca más partido a tu hardware con un software líder en el sector, integrado con frameworks, bibliotecas y compiladores abiertos para que el desarrollo, la integración y la gestión de la IA sean más eficientes.
- Compatibilidad con PyTorch, JAX, Keras, vLLM, Megatron-LM, NeMo Megatron, MaxText, MaxDiffusion y muchos más.
- La integración profunda con el compilador XLA permite la interoperabilidad entre distintos aceleradores, mientras que Pathways on Cloud te permite usar el mismo tiempo de ejecución distribuido que impulsa la infraestructura interna de entrenamiento e inferencia a gran escala de Google.
- Todo esto se puede desplegar en el entorno que prefieras, ya sea Google Kubernetes Engine, Cluster Director o Google Compute Engine.
Modelos de consumo flexibles
Las opciones de consumo flexibles permiten a los clientes elegir entre costes fijos con descuentos por uso comprometido o modelos dinámicos bajo demanda para satisfacer las necesidades de su negocio. Dynamic Workload Scheduler y las Spot VMs pueden ayudarte a obtener la capacidad que necesitas sin tener que asignar demasiadas tareas. Además, las herramientas de optimización de costes de Google Cloud ayudan a automatizar el uso de recursos para reducir las tareas manuales de los ingenieros.
Servir modelos a gran escala de forma rentable
Maximiza la relación precio-rendimiento y la fiabilidad de las cargas de trabajo de inferencia
La inferencia se está volviendo más diversa y compleja rápidamente, y está evolucionando en tres áreas principales:
- En primer lugar, está cambiando la forma en que interactuamos con la IA. Ahora las conversaciones tienen un contexto mucho más amplio y diverso.
- En segundo lugar, el razonamiento sofisticado y la inferencia multietapa están haciendo que los modelos de Mixture-of-Experts (MoE) sean más comunes. Esto está redefiniendo cómo se escalan la memoria y la computación desde la entrada inicial hasta la salida final.
- Por último, está claro que el valor real no se basa solo en el número de tokens por dólar, sino en la utilidad de la respuesta. ¿Tiene el modelo los conocimientos adecuados? ¿Ha respondido correctamente a una pregunta empresarial importante? Por eso creemos que los clientes necesitan mejores mediciones, que se centren en el coste total de las operaciones del sistema, no en el precio de sus procesadores.
Ver recursos de inferencia de IA
- ¿Qué es la inferencia de IA? Nuestra guía completa sobre tipos, comparaciones y casos prácticos
- Ejecuta recetas de inferencia de prácticas recomendadas con GKE Inference Quickstart
- Haz un curso sobre la inferencia de IA en Cloud Run
- Mira este vídeo sobre el secreto de la inferencia de IA rentable
- Descubre cómo acelerar las cargas de trabajo de inferencia de IA
La IA convierte a los fans del deporte en diseñadores de equipaciones
PUMA se ha asociado con Google Cloud para usar su infraestructura de IA integrada (AI Hypercomputer), lo que le permite usar Gemini para las peticiones de los usuarios junto con Dynamic Workload Scheduler para escalar dinámicamente la inferencia en las GPUs, lo que reduce drásticamente los costes y el tiempo de generación.
Impacto:
- Han reducido el tiempo de generación de kits de IA de 2 a 5 minutos a solo 30 segundos. De esta forma, la plataforma se convirtió en una experiencia rápida y verdaderamente interactiva que mantenía el interés de los usuarios.
- En solo 10 días, los fans crearon 180.000 kits y emitieron 1,7 millones de valoraciones.
- El proyecto demostró que PUMA podía conectar con su comunidad de una nueva forma. La marca fue más allá de una simple relación entre marca y consumidor, ya que consiguió que los fans se convirtieran en cocreadores activos, lo que proporcionó a la empresa información directa y en tiempo real sobre los deseos creativos de sus consumidores más apasionados.



Instrucciones
Maximiza la relación precio-rendimiento y la fiabilidad de las cargas de trabajo de inferencia
La inferencia se está volviendo más diversa y compleja rápidamente, y está evolucionando en tres áreas principales:
- En primer lugar, está cambiando la forma en que interactuamos con la IA. Ahora las conversaciones tienen un contexto mucho más amplio y diverso.
- En segundo lugar, el razonamiento sofisticado y la inferencia multietapa están haciendo que los modelos de Mixture-of-Experts (MoE) sean más comunes. Esto está redefiniendo cómo se escalan la memoria y la computación desde la entrada inicial hasta la salida final.
- Por último, está claro que el valor real no se basa solo en el número de tokens por dólar, sino en la utilidad de la respuesta. ¿Tiene el modelo los conocimientos adecuados? ¿Ha respondido correctamente a una pregunta empresarial importante? Por eso creemos que los clientes necesitan mejores mediciones, que se centren en el coste total de las operaciones del sistema, no en el precio de sus procesadores.
Otros recursos
Ver recursos de inferencia de IA
- ¿Qué es la inferencia de IA? Nuestra guía completa sobre tipos, comparaciones y casos prácticos
- Ejecuta recetas de inferencia de prácticas recomendadas con GKE Inference Quickstart
- Haz un curso sobre la inferencia de IA en Cloud Run
- Mira este vídeo sobre el secreto de la inferencia de IA rentable
- Descubre cómo acelerar las cargas de trabajo de inferencia de IA
Ejemplos de clientes
La IA convierte a los fans del deporte en diseñadores de equipaciones
PUMA se ha asociado con Google Cloud para usar su infraestructura de IA integrada (AI Hypercomputer), lo que le permite usar Gemini para las peticiones de los usuarios junto con Dynamic Workload Scheduler para escalar dinámicamente la inferencia en las GPUs, lo que reduce drásticamente los costes y el tiempo de generación.
Impacto:
- Han reducido el tiempo de generación de kits de IA de 2 a 5 minutos a solo 30 segundos. De esta forma, la plataforma se convirtió en una experiencia rápida y verdaderamente interactiva que mantenía el interés de los usuarios.
- En solo 10 días, los fans crearon 180.000 kits y emitieron 1,7 millones de valoraciones.
- El proyecto demostró que PUMA podía conectar con su comunidad de una nueva forma. La marca fue más allá de una simple relación entre marca y consumidor, ya que consiguió que los fans se convirtieran en cocreadores activos, lo que proporcionó a la empresa información directa y en tiempo real sobre los deseos creativos de sus consumidores más apasionados.
Ejecuta entrenamiento y preentrenamiento de IA a gran escala
Curso en IA potente, escalable y eficiente
Las cargas de trabajo de entrenamiento deben ejecutarse como tareas altamente sincronizadas en miles de nodos de clústeres estrechamente acoplados. Un solo nodo degradado puede interrumpir toda una tarea y retrasar el tiempo de lanzamiento al mercado. Haz lo siguiente:
- Asegurarte de que el clúster se configura rápidamente y se ajusta a la carga de trabajo en cuestión
- Predice los fallos y soluciona los problemas rápidamente.
- Y continúa con una carga de trabajo, incluso cuando se produzcan fallos
Queremos que los clientes puedan desplegar y escalar cargas de trabajo de entrenamiento en Google Cloud de forma muy sencilla.
Curso en IA potente, escalable y eficiente
Para crear un clúster de IA, empieza con uno de nuestros tutoriales:
- Crea un clúster de Slurm con GPUs (máquinas virtuales A4) y Cluster Toolkit
- Crea un clúster de GKE con Cluster Director para GKE o Cluster Toolkit.
Moloco creó una plataforma de publicación de anuncios para procesar miles de millones de solicitudes al día
Moloco se basó en la pila totalmente integrada de AI Hypercomputer para escalar automáticamente en hardware avanzado como las TPUs y las GPUs, lo que liberó a los ingenieros de Moloco. Además, la integración con la plataforma de datos líder del sector de Google creó un sistema cohesivo e integral para las cargas de trabajo de IA.
Tras lanzar sus primeros modelos de aprendizaje profundo, Moloco experimentó un crecimiento y una rentabilidad exponenciales, multiplicándose por 5 en 2,5 años.
- Entrenamiento de modelos 10 veces más rápido con las TPUs de Cloud en GKE, además de una reducción de 4 veces en los costes de entrenamiento
- Se ha escalado para dar servicio a más de 1000 usuarios internos, lo que les da acceso a un sistema de aprendizaje automático a escala planetaria que les ayuda a encontrar un crecimiento rentable a partir de sus propios datos.


AssemblyAI
AssemblyAI utiliza Google Cloud para entrenar modelos rápidamente y a escala

LG AI Research redujo drásticamente los costes y aceleró el desarrollo, al tiempo que cumplía los estrictos requisitos de seguridad y residencia de datos

Anthropic anunció sus planes de acceder a hasta 1 millón de TPUs para entrenar y servir modelos de Claude, lo que supone una inversión de decenas de miles de millones de dólares. Pero ¿cómo se ejecutan en Google Cloud? Mira este vídeo para ver cómo está ampliando Anthropic los límites computacionales de la IA a gran escala con GKE.
Instrucciones
Curso en IA potente, escalable y eficiente
Las cargas de trabajo de entrenamiento deben ejecutarse como tareas altamente sincronizadas en miles de nodos de clústeres estrechamente acoplados. Un solo nodo degradado puede interrumpir toda una tarea y retrasar el tiempo de lanzamiento al mercado. Haz lo siguiente:
- Asegurarte de que el clúster se configura rápidamente y se ajusta a la carga de trabajo en cuestión
- Predice los fallos y soluciona los problemas rápidamente.
- Y continúa con una carga de trabajo, incluso cuando se produzcan fallos
Queremos que los clientes puedan desplegar y escalar cargas de trabajo de entrenamiento en Google Cloud de forma muy sencilla.
Otros recursos
Curso en IA potente, escalable y eficiente
Para crear un clúster de IA, empieza con uno de nuestros tutoriales:
- Crea un clúster de Slurm con GPUs (máquinas virtuales A4) y Cluster Toolkit
- Crea un clúster de GKE con Cluster Director para GKE o Cluster Toolkit.
Ejemplos de clientes
Moloco creó una plataforma de publicación de anuncios para procesar miles de millones de solicitudes al día
Moloco se basó en la pila totalmente integrada de AI Hypercomputer para escalar automáticamente en hardware avanzado como las TPUs y las GPUs, lo que liberó a los ingenieros de Moloco. Además, la integración con la plataforma de datos líder del sector de Google creó un sistema cohesivo e integral para las cargas de trabajo de IA.
Tras lanzar sus primeros modelos de aprendizaje profundo, Moloco experimentó un crecimiento y una rentabilidad exponenciales, multiplicándose por 5 en 2,5 años.
- Entrenamiento de modelos 10 veces más rápido con las TPUs de Cloud en GKE, además de una reducción de 4 veces en los costes de entrenamiento
- Se ha escalado para dar servicio a más de 1000 usuarios internos, lo que les da acceso a un sistema de aprendizaje automático a escala planetaria que les ayuda a encontrar un crecimiento rentable a partir de sus propios datos.
AssemblyAI
AssemblyAI utiliza Google Cloud para entrenar modelos rápidamente y a escala
LG AI Research redujo drásticamente los costes y aceleró el desarrollo, al tiempo que cumplía los estrictos requisitos de seguridad y residencia de datos
Anthropic anunció sus planes de acceder a hasta 1 millón de TPUs para entrenar y servir modelos de Claude, lo que supone una inversión de decenas de miles de millones de dólares. Pero ¿cómo se ejecutan en Google Cloud? Mira este vídeo para ver cómo está ampliando Anthropic los límites computacionales de la IA a gran escala con GKE.
Despliega y orquesta aplicaciones de IA
Aprovecha el software de orquestación de IA líder y los frameworks abiertos para ofrecer experiencias basadas en la IA
Google Cloud proporciona imágenes que contienen sistemas operativos, frameworks, bibliotecas y controladores comunes. AI Hypercomputer optimiza estas imágenes preconfiguradas para que sean compatibles con tus cargas de trabajo de IA.
- Frameworks y bibliotecas de IA y aprendizaje automático: usa imágenes de Docker de Deep Learning Software Layer (DLSL) para ejecutar modelos de aprendizaje automático como NeMO y MaxText en un clúster de Google Kubernetes Engine (GKE).
- Despliegue de clústeres y orquestación de IA: puedes desplegar tus cargas de trabajo de IA en clústeres de GKE, clústeres de Slurm o instancias de Compute Engine. Para obtener más información, consulta la descripción general de la creación de VMs y clústeres.
Ver recursos de software
- Pathways on Cloud es un sistema diseñado para permitir la creación de sistemas de aprendizaje automático a gran escala, multitarea y con activación dispersa.
- Optimiza tu productividad de aprendizaje automático aprovechando nuestras recetas de Goodput
- Programa cargas de trabajo de GKE con Topology Aware Scheduling
- Prueba una de nuestras recetas de comparativas para ejecutar modelos de DeepSeek, Mixtral, Llama y GPT en GPUs
- Elige una opción de consumo para obtener y usar recursos de computación de forma más eficiente
Priceline: Ayudamos a los viajeros a seleccionar experiencias únicas
"Trabajar con Google Cloud para incorporar la IA generativa nos permite crear un servicio de conserjería de viajes a medida en nuestro bot de chat. Queremos que nuestros clientes no solo planteen viajes, sino que les ayuden a personalizar su experiencia de viaje única". Martin Brodbeck, director de tecnología de Priceline




Instrucciones
Aprovecha el software de orquestación de IA líder y los frameworks abiertos para ofrecer experiencias basadas en la IA
Google Cloud proporciona imágenes que contienen sistemas operativos, frameworks, bibliotecas y controladores comunes. AI Hypercomputer optimiza estas imágenes preconfiguradas para que sean compatibles con tus cargas de trabajo de IA.
- Frameworks y bibliotecas de IA y aprendizaje automático: usa imágenes de Docker de Deep Learning Software Layer (DLSL) para ejecutar modelos de aprendizaje automático como NeMO y MaxText en un clúster de Google Kubernetes Engine (GKE).
- Despliegue de clústeres y orquestación de IA: puedes desplegar tus cargas de trabajo de IA en clústeres de GKE, clústeres de Slurm o instancias de Compute Engine. Para obtener más información, consulta la descripción general de la creación de VMs y clústeres.
Otros recursos
Ver recursos de software
- Pathways on Cloud es un sistema diseñado para permitir la creación de sistemas de aprendizaje automático a gran escala, multitarea y con activación dispersa.
- Optimiza tu productividad de aprendizaje automático aprovechando nuestras recetas de Goodput
- Programa cargas de trabajo de GKE con Topology Aware Scheduling
- Prueba una de nuestras recetas de comparativas para ejecutar modelos de DeepSeek, Mixtral, Llama y GPT en GPUs
- Elige una opción de consumo para obtener y usar recursos de computación de forma más eficiente
Ejemplos de clientes
Priceline: Ayudamos a los viajeros a seleccionar experiencias únicas
"Trabajar con Google Cloud para incorporar la IA generativa nos permite crear un servicio de conserjería de viajes a medida en nuestro bot de chat. Queremos que nuestros clientes no solo planteen viajes, sino que les ayuden a personalizar su experiencia de viaje única". Martin Brodbeck, director de tecnología de Priceline
Preguntas frecuentes
¿En qué se diferencia AI Hypercomputer de usar servicios en la nube individuales?
Aunque los servicios individuales ofrecen funciones específicas, AI Hypercomputer proporciona un sistema integrado en el que el hardware, el software y los modelos de consumo están diseñados para funcionar de forma óptima en conjunto. Esta integración ofrece eficiencias a nivel de sistema en cuanto a rendimiento, costes y tiempo de lanzamiento al mercado que son más difíciles de conseguir combinando servicios independientes. Simplifica la complejidad y ofrece un enfoque holístico de la infraestructura de IA.
¿Se puede usar AI Hypercomputer en un entorno híbrido o multinube?
Sí, AI Hypercomputer se ha diseñado pensando en la flexibilidad. Tecnologías como Cross-Cloud Interconnect proporcionan conectividad de gran ancho de banda a centros de datos on-premise y otras nubes, lo que facilita las estrategias de IA híbrida y multinube. Trabajamos con estándares abiertos e integramos software popular de terceros para que puedas crear soluciones que abarquen varios entornos y cambiar de servicio cuando quieras.
¿Cómo aborda AI Hypercomputer la seguridad de las cargas de trabajo de IA?
La seguridad es un aspecto fundamental de AI Hypercomputer. Se beneficia del modelo de seguridad multicapa de Google Cloud. Entre las funciones específicas, se incluyen los microcontroladores de seguridad Titan (que garantizan que los sistemas se inicien desde un estado de confianza), el firewall RDMA (para redes de confianza cero entre TPUs o GPUs durante el entrenamiento) y la integración con soluciones como Model Armor para la seguridad de la IA. Todo esto se complementa con políticas y principios de seguridad de la infraestructura sólidos, como el marco de IA segura.
¿Cuál es la forma más sencilla de usar AI Hypercomputer como infraestructura?
- Si no quieres gestionar máquinas virtuales, te recomendamos que empieces con Google Kubernetes Engine (GKE).
- Si necesitas usar varios programadores o no puedes usar GKE, te recomendamos que uses Cluster Director.
- Si quieres tener un control total sobre tu infraestructura, la única forma de conseguirlo es trabajando directamente con máquinas virtuales, y para eso, Compute Engine es tu mejor opción.
¿Solo es útil para cargas de trabajo grandes o de gran escala?
No. AI Hypercomputer se puede usar con cargas de trabajo de cualquier tamaño. Las cargas de trabajo más pequeñas también se benefician de las ventajas de un sistema integrado, como la eficiencia y la simplificación de la implementación. AI Hypercomputer también ayuda a los clientes a escalar sus negocios, desde pequeñas pruebas de concepto y experimentos hasta implementaciones de producción a gran escala.
¿Es AI Hypercomputer la forma más sencilla de empezar a usar cargas de trabajo de IA en Google Cloud?
Para la mayoría de los clientes, una plataforma de IA gestionada como Vertex AI es la forma más sencilla de empezar a usar la IA, ya que incluye todas las herramientas, plantillas y modelos. Además, Vertex AI se basa en AI Hypercomputer, que se optimiza automáticamente en tu nombre. Vertex AI es la forma más sencilla de empezar, ya que ofrece la experiencia más simple. Si prefieres configurar y optimizar cada componente de tu infraestructura, puedes acceder a los componentes de AI Hypercomputer como infraestructura y ensamblarlos de forma que se adapten a tus necesidades.
Como AI Hypercomputer es un sistema modular, hay muchas opciones. ¿Tenéis prácticas recomendadas para cada caso práctico?
Sí, estamos creando una biblioteca de recetas en GitHub. También puedes usar Cluster Toolkit para obtener planos de clústeres predefinidos.
¿Qué opciones tengo disponibles cuando uso AI Hypercomputer como IaaS?
Hardware optimizado para IA
Almacenamiento
- Entrenamiento: Managed Lustre es ideal para el entrenamiento de IA exigente con un alto rendimiento y una capacidad de escala de petabytes. GCS Fuse (opcionalmente con Anywhere Cache) es adecuado para necesidades de mayor capacidad con una latencia más relajada. Ambos se integran con GKE y Cluster Director.
- Inferencia: GCS Fuse con Anywhere Cache ofrece una solución sencilla. Si quieres un mayor rendimiento, te recomendamos Hyperdisk ML. Si se usa Managed Lustre para el entrenamiento en la misma zona, también se puede usar para la inferencia.
Redes
- Entrenamiento: aprovecha tecnologías como las redes RDMA en VPCs y Cloud Interconnect y Cross-Cloud Interconnect de gran ancho de banda para transferir datos rápidamente.
- Inferencia: utiliza soluciones como GKE Inference Gateway y Cloud Load Balancing mejorado para ofrecer servicios con baja latencia. Model Armor se puede integrar para mejorar la seguridad de la IA.
Computación: accede a las TPUs de Google Cloud (Trillium), las GPUs de NVIDIA (Blackwell) y las CPUs (Axion). Esto permite optimizar el rendimiento, la latencia o el coste total de propiedad en función de las necesidades específicas de la carga de trabajo.
Software y frameworks de código abierto líderes
- Frameworks y bibliotecas de aprendizaje automático: PyTorch, JAX, TensorFlow, Keras, vLLM, JetStream, MaxText, LangChain, Hugging Face, NVIDIA (CUDA, NeMo, Triton) y muchas más opciones de código abierto y de terceros.
- Compiladores, runtimes y herramientas: XLA (para mejorar el rendimiento y la interoperabilidad), Pathways on Cloud, Multislice Training, Cluster Toolkit (para obtener diseños de clústeres predefinidos) y muchas más opciones de código abierto y de terceros.
- Orquestación: Google Kubernetes Engine (GKE), Cluster Director (para Slurm, Kubernetes no gestionado y programadores BYO) y Google Compute Engine (GCE).
Modelos de consumo:
- Bajo demanda: pago por uso.
- Descuentos por compromiso de uso (CUD): ahorra significativamente (hasta un 70 %) con compromisos a largo plazo.
- Máquinas virtuales de acceso puntual: ideales para tareas por lotes tolerantes a fallos, ya que ofrecen grandes descuentos (hasta el 91%).
- Dynamic Workload Scheduler (DWS): ahorra hasta un 50 % en tareas por lotes o tolerantes a fallos.











