Trainieren, abstimmen und bereitstellen auf einer AI Supercomputer-Architektur
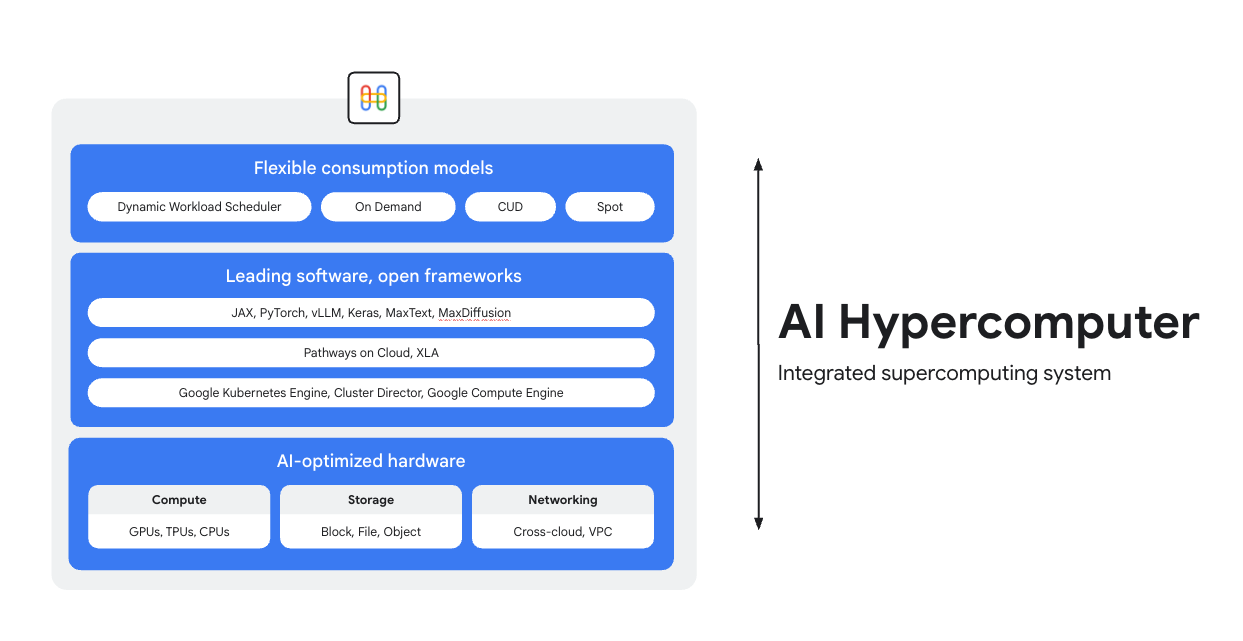
AI Hypercomputer ist das integrierte Supercomputing-System, das allen KI-Arbeitslasten in Google Cloud zugrunde liegt. Es besteht aus Hardware, Software und Verbrauchsmodellen, die die KI-Bereitstellung vereinfachen, die Effizienz auf Systemebene verbessern und die Kosten optimieren.
Überblick
KI-optimierte Hardware
Wählen Sie unter Computing- (einschließlich KI-Beschleuniger), Speicher- und Netzwerkoptionen, die für spezifische Ziele auf Arbeitslastebene optimiert sind (höherer Durchsatz, niedrigere Latenz, schnellere Ergebnisse oder niedrigere Gesamtbetriebskosten). Weitere Informationen zu Cloud TPUs, Cloud GPUs und den neuesten Entwicklungen in den Bereichen Speicher und Netzwerk.
Top-Software, offene Frameworks
Dank branchenführender, in offene Frameworks, Bibliotheken und Compiler eingebundener Software können Sie Ihre Hardware optimal nutzen und die KI-Entwicklung, ‑Einbindung und ‑Verwaltung effizienter gestalten.
- Unterstützung für PyTorch, JAX, Keras, vLLM, Megatron-LM, NeMo Megatron, MaxText, MaxDiffusion und viele weitere.
- Die enge Einbindung mit dem XLA-Compiler ermöglicht die Interoperabilität zwischen verschiedenen Beschleunigern. Mit Pathways on Cloud können Sie die verteilte Laufzeitumgebung verwenden, die auch die internen groß angelegten Trainings- und Inferenzinfrastrukturen von Google unterstützt.
- All das lässt sich in der Umgebung Ihrer Wahl bereitstellen, ob Google Kubernetes Engine, Cluster Director oder Google Compute Engine.
Flexible Nutzungsmodelle
Flexible Nutzungsoptionen ermöglichen es Kunden, feste Kosten mit Rabatten für zugesicherte Nutzung oder dynamischen On-Demand-Modellen zu wählen, um ihre geschäftlichen Anforderungen zu erfüllen.Dank dem Dynamic Workload Scheduler und Spot-VMs können Sie die benötigte Kapazität ohne Überhang erhalten.Außerdem helfen die Tools zur Kostenoptimierung von Google Cloud bei der Automatisierung der Ressourcennutzung, um manuelle Aufgaben zu reduzieren, die von Entwicklern ausgeführt werden müssten.
Funktionsweise
Modelle kosteneffizient im großen Maßstab bereitstellen
Preis-Leistungs-Verhältnis und Zuverlässigkeit für Inferenz-Arbeitslasten maximieren
Inferenz wird schnell vielfältiger und komplexer und entwickelt sich in drei Hauptbereichen weiter:
- Erstens: Die Art und Weise, wie wir mit KI interagieren, verändert sich. Gespräche haben jetzt einen viel längeren und vielfältigeren Kontext.
- Zweitens werden Modelle mit Mixture-of-Experts-Architektur (MoE) aufgrund ihrer komplexen Schlussfolgerungen und mehrstufigen Inferenz immer beliebter. Das verändert die Art und Weise, wie Speicher und Rechenleistung von der Eingabe bis zur Ausgabe skaliert werden.
- Außerdem ist klar, dass es nicht nur um die Anzahl der Tokens pro Dollar geht, sondern um die Nützlichkeit der Antwort. Verfügt das Modell über das erforderliche Fachwissen? Wurde eine wichtige Geschäftsfrage richtig beantwortet? Deshalb sind wir der Meinung, dass Kunden bessere Messwerte benötigen, die sich auf die Gesamtkosten des Systembetriebs konzentrieren und nicht auf den Preis der Prozessoren.
Ressourcen zur KI-Inferenz ansehen
- Was ist KI-Inferenz? Unser umfassender Leitfaden zu Typen, Vergleichen und Anwendungsfällen
- Best-Practice-Vorgaben für die Inferenz mit GKE Inference Quickstart ausführen
- Kurs zu KI-Inferenzen auf Cloud Run
- Video: Das Geheimnis kosteneffizienter KI-Inferenz
- KI-Inferenz-Workloads beschleunigen
KI macht Sportfans zu Trikotdesignern
PUMA hat sich für eine integrierte KI-Infrastruktur (AI Hypercomputer) von Google Cloud entschieden. So kann das Unternehmen Gemini für Nutzerprompts und Dynamic Workload Scheduler für die dynamische Skalierung von Inferenz auf GPUs nutzen, was Kosten und Generierungszeit erheblich reduziert.
Wirkung:
- Die Zeit für die Erstellung von KI-Kits wurde von 2–5 Minuten auf nur 30 Sekunden reduziert. So wurde die Plattform zu einer schnellen, interaktiven Umgebung, die Nutzer begeistert.
- In nur 10 Tagen erstellten Fans 180.000 Trikots und gaben 1,7 Millionen Bewertungen ab.
- Das Projekt eröffnete PUMA eine neue Möglichkeit, mit seiner Community in Kontakt zu treten. Das Unternehmen ging über eine einfache Beziehung zwischen Marke und Verbraucher hinaus und verwandelte Fans erfolgreich in aktive Co-Creatoren. So erhielt das Unternehmen direkte Einblicke in die kreativen Wünsche seiner leidenschaftlichsten Kunden.



Anleitungen
Preis-Leistungs-Verhältnis und Zuverlässigkeit für Inferenz-Arbeitslasten maximieren
Inferenz wird schnell vielfältiger und komplexer und entwickelt sich in drei Hauptbereichen weiter:
- Erstens: Die Art und Weise, wie wir mit KI interagieren, verändert sich. Gespräche haben jetzt einen viel längeren und vielfältigeren Kontext.
- Zweitens werden Modelle mit Mixture-of-Experts-Architektur (MoE) aufgrund ihrer komplexen Schlussfolgerungen und mehrstufigen Inferenz immer beliebter. Das verändert die Art und Weise, wie Speicher und Rechenleistung von der Eingabe bis zur Ausgabe skaliert werden.
- Außerdem ist klar, dass es nicht nur um die Anzahl der Tokens pro Dollar geht, sondern um die Nützlichkeit der Antwort. Verfügt das Modell über das erforderliche Fachwissen? Wurde eine wichtige Geschäftsfrage richtig beantwortet? Deshalb sind wir der Meinung, dass Kunden bessere Messwerte benötigen, die sich auf die Gesamtkosten des Systembetriebs konzentrieren und nicht auf den Preis der Prozessoren.
Weitere Ressourcen
Ressourcen zur KI-Inferenz ansehen
- Was ist KI-Inferenz? Unser umfassender Leitfaden zu Typen, Vergleichen und Anwendungsfällen
- Best-Practice-Vorgaben für die Inferenz mit GKE Inference Quickstart ausführen
- Kurs zu KI-Inferenzen auf Cloud Run
- Video: Das Geheimnis kosteneffizienter KI-Inferenz
- KI-Inferenz-Workloads beschleunigen
Kundenbeispiele
KI macht Sportfans zu Trikotdesignern
PUMA hat sich für eine integrierte KI-Infrastruktur (AI Hypercomputer) von Google Cloud entschieden. So kann das Unternehmen Gemini für Nutzerprompts und Dynamic Workload Scheduler für die dynamische Skalierung von Inferenz auf GPUs nutzen, was Kosten und Generierungszeit erheblich reduziert.
Wirkung:
- Die Zeit für die Erstellung von KI-Kits wurde von 2–5 Minuten auf nur 30 Sekunden reduziert. So wurde die Plattform zu einer schnellen, interaktiven Umgebung, die Nutzer begeistert.
- In nur 10 Tagen erstellten Fans 180.000 Trikots und gaben 1,7 Millionen Bewertungen ab.
- Das Projekt eröffnete PUMA eine neue Möglichkeit, mit seiner Community in Kontakt zu treten. Das Unternehmen ging über eine einfache Beziehung zwischen Marke und Verbraucher hinaus und verwandelte Fans erfolgreich in aktive Co-Creatoren. So erhielt das Unternehmen direkte Einblicke in die kreativen Wünsche seiner leidenschaftlichsten Kunden.
Umfangreiches KI-Training und Vortraining ausführen
Leistungsstarkes, skalierbares und effizientes KI-Training
Trainingsarbeitslasten müssen als hochgradig synchronisierte Jobs auf Tausenden von Knoten in eng gekoppelten Clustern ausgeführt werden. Ein einzelner beeinträchtigter Knoten kann einen gesamten Job stören und die Markteinführung verzögern. Folgende Schritte sind erforderlich:
- Der Cluster muss schnell eingerichtet und für die jeweilige Arbeitslast optimiert werden
- Ausfälle müssen vorhergesagt und schnell behoben werden
- Und auch bei Ausfällen müssen Arbeitslasten weiter ausgeführt werden
Wir möchten es Kunden so einfach wie möglich machen, Trainings-Workloads in Google Cloud bereitzustellen und zu skalieren.
Leistungsstarkes, skalierbares und effizientes KI-Training
Wenn Sie einen KI-Cluster erstellen möchten, sollten Sie sich eines unserer Tutorials ansehen:
- Slurm-Cluster mit GPUs (A4-VMs) und Cluster Toolkit erstellen
- GKE-Cluster mit Cluster Director for GKE oder Cluster Toolkit erstellen
Moloco entwickelte eine Plattform zur Anzeigenauslieferung, die Milliarden von Anfragen pro Tag verarbeitet.
Moloco nutzte den vollständig integrierten AI Hypercomputer-Stack, um automatisch auf fortschrittlicher Hardware wie TPUs und GPUs zu skalieren. So wurden die Ingenieure von Moloco entlastet. Die Integration mit der branchenführenden Datenplattform von Google schuf ein kohäsives End-to-End-System für KI-Arbeitslasten.
Nach der Einführung der ersten Deep-Learning-Modelle verzeichnete Moloco ein rasantes Wachstum und eine hohe Rentabilität. Das Unternehmen konnte seinen Umsatz in 2,5 Jahren verfünffachen.
- 10-mal schnelleres Modelltraining mit Cloud TPUs in GKE und 4-mal geringere Trainingskosten
- Skalierbar für über 1.000 interne Nutzer, die Zugriff auf ein Machine-Learning-System im planetaren Maßstab erhalten, mit dem sie aus ihren eigenen Daten profitables Wachstum erzielen können


AssemblyAI
AssemblyAI trainiert Modelle mit Google Cloud schnell und in großem Umfang

LG AI Research konnte Kosten drastisch senken und die Entwicklung beschleunigen, wobei strenge Anforderungen an Datensicherheit und Datenstandort eingehalten wurden.

Anthropic kündigte die Nutzung von bis zu 1 Million TPUs für das Training und die Bereitstellung von Claude-Modellen im Wert von mehreren zehn Milliarden US-Dollar an. Aber wie werden sie in Google Cloud ausgeführt? In diesem Video erfahren Sie, wie Anthropic mit GKE die Grenzen der KI-Rechenleistung im großen Maßstab verschiebt.
Anleitungen
Leistungsstarkes, skalierbares und effizientes KI-Training
Trainingsarbeitslasten müssen als hochgradig synchronisierte Jobs auf Tausenden von Knoten in eng gekoppelten Clustern ausgeführt werden. Ein einzelner beeinträchtigter Knoten kann einen gesamten Job stören und die Markteinführung verzögern. Folgende Schritte sind erforderlich:
- Der Cluster muss schnell eingerichtet und für die jeweilige Arbeitslast optimiert werden
- Ausfälle müssen vorhergesagt und schnell behoben werden
- Und auch bei Ausfällen müssen Arbeitslasten weiter ausgeführt werden
Wir möchten es Kunden so einfach wie möglich machen, Trainings-Workloads in Google Cloud bereitzustellen und zu skalieren.
Weitere Ressourcen
Leistungsstarkes, skalierbares und effizientes KI-Training
Wenn Sie einen KI-Cluster erstellen möchten, sollten Sie sich eines unserer Tutorials ansehen:
- Slurm-Cluster mit GPUs (A4-VMs) und Cluster Toolkit erstellen
- GKE-Cluster mit Cluster Director for GKE oder Cluster Toolkit erstellen
Kundenbeispiele
Moloco entwickelte eine Plattform zur Anzeigenauslieferung, die Milliarden von Anfragen pro Tag verarbeitet.
Moloco nutzte den vollständig integrierten AI Hypercomputer-Stack, um automatisch auf fortschrittlicher Hardware wie TPUs und GPUs zu skalieren. So wurden die Ingenieure von Moloco entlastet. Die Integration mit der branchenführenden Datenplattform von Google schuf ein kohäsives End-to-End-System für KI-Arbeitslasten.
Nach der Einführung der ersten Deep-Learning-Modelle verzeichnete Moloco ein rasantes Wachstum und eine hohe Rentabilität. Das Unternehmen konnte seinen Umsatz in 2,5 Jahren verfünffachen.
- 10-mal schnelleres Modelltraining mit Cloud TPUs in GKE und 4-mal geringere Trainingskosten
- Skalierbar für über 1.000 interne Nutzer, die Zugriff auf ein Machine-Learning-System im planetaren Maßstab erhalten, mit dem sie aus ihren eigenen Daten profitables Wachstum erzielen können
AssemblyAI
AssemblyAI trainiert Modelle mit Google Cloud schnell und in großem Umfang
LG AI Research konnte Kosten drastisch senken und die Entwicklung beschleunigen, wobei strenge Anforderungen an Datensicherheit und Datenstandort eingehalten wurden.
Anthropic kündigte die Nutzung von bis zu 1 Million TPUs für das Training und die Bereitstellung von Claude-Modellen im Wert von mehreren zehn Milliarden US-Dollar an. Aber wie werden sie in Google Cloud ausgeführt? In diesem Video erfahren Sie, wie Anthropic mit GKE die Grenzen der KI-Rechenleistung im großen Maßstab verschiebt.
KI-Anwendungen bereitstellen und orchestrieren
Mit führender KI-Orchestrierungssoftware und offenen Frameworks KI-basierte Lösungen bereitstellen
Google Cloud bietet Images mit gängigen Betriebssystemen, Frameworks, Bibliotheken und Treibern. AI Hypercomputer optimiert diese vorkonfigurierten Images, um Ihre KI-Arbeitslasten zu unterstützen.
- KI- und ML-Frameworks und ‑Bibliotheken: Mit Deep Learning Software Layer (DLSL)-Docker-Images können Sie ML-Modelle wie NeMO und MaxText in einem Google Kubernetes Engine (GKE)-Cluster ausführen.
- Clusterbereitstellung und KI-Orchestrierung: Sie können Ihre KI-Arbeitslasten in GKE-Clustern, Slurm-Clustern oder Compute Engine-Instanzen bereitstellen. Weitere Informationen finden Sie in der Übersicht zur VM- und Clustererstellung.
Software-Ressourcen ansehen
- Pathways on Cloud ist ein System, mit dem sich umfangreiche, auf mehreren Aufgaben basierende und spärlich aktivierte Machine-Learning-Systeme erstellen lassen.
- Mit unseren Goodput-Schemas können Sie Ihre ML-Produktivität optimieren.
- GKE-Arbeitslasten mit Topology Aware Scheduling planen
- Probieren Sie eines unserer Benchmarking-Schemas aus, um DeepSeek-, Mixtral-, Llama- und GPT-Modelle auf GPUs auszuführen.
- Wählen Sie eine Nutzungsoption aus, um Rechenressourcen effizienter zu beziehen und zu nutzen.
Priceline: Individuelle Reiseerlebnisse für Reisende ermöglichen
„Durch die Zusammenarbeit mit Google Cloud und das Einbinden von generativer KI können wir einen maßgeschneiderten Reise-Concierge als Teils unseres Chatbots anbieten. Wir möchten, dass alle Personen, die unseren Service nutzen, nicht einfach nur eine Reise planen, sondern ihr ganz persönliches und einzigartiges Reiseerlebnis gestalten können.“ Martin Brodbeck, CTO von Priceline




Anleitungen
Mit führender KI-Orchestrierungssoftware und offenen Frameworks KI-basierte Lösungen bereitstellen
Google Cloud bietet Images mit gängigen Betriebssystemen, Frameworks, Bibliotheken und Treibern. AI Hypercomputer optimiert diese vorkonfigurierten Images, um Ihre KI-Arbeitslasten zu unterstützen.
- KI- und ML-Frameworks und ‑Bibliotheken: Mit Deep Learning Software Layer (DLSL)-Docker-Images können Sie ML-Modelle wie NeMO und MaxText in einem Google Kubernetes Engine (GKE)-Cluster ausführen.
- Clusterbereitstellung und KI-Orchestrierung: Sie können Ihre KI-Arbeitslasten in GKE-Clustern, Slurm-Clustern oder Compute Engine-Instanzen bereitstellen. Weitere Informationen finden Sie in der Übersicht zur VM- und Clustererstellung.
Weitere Ressourcen
Software-Ressourcen ansehen
- Pathways on Cloud ist ein System, mit dem sich umfangreiche, auf mehreren Aufgaben basierende und spärlich aktivierte Machine-Learning-Systeme erstellen lassen.
- Mit unseren Goodput-Schemas können Sie Ihre ML-Produktivität optimieren.
- GKE-Arbeitslasten mit Topology Aware Scheduling planen
- Probieren Sie eines unserer Benchmarking-Schemas aus, um DeepSeek-, Mixtral-, Llama- und GPT-Modelle auf GPUs auszuführen.
- Wählen Sie eine Nutzungsoption aus, um Rechenressourcen effizienter zu beziehen und zu nutzen.
Kundenbeispiele
Priceline: Individuelle Reiseerlebnisse für Reisende ermöglichen
„Durch die Zusammenarbeit mit Google Cloud und das Einbinden von generativer KI können wir einen maßgeschneiderten Reise-Concierge als Teils unseres Chatbots anbieten. Wir möchten, dass alle Personen, die unseren Service nutzen, nicht einfach nur eine Reise planen, sondern ihr ganz persönliches und einzigartiges Reiseerlebnis gestalten können.“ Martin Brodbeck, CTO von Priceline
FAQs
Wie unterscheidet sich AI Hypercomputer von der Nutzung einzelner Cloud-Dienste?
Einzelne Dienste bieten zwar spezifische Funktionen, aber dennoch stellt die AI Hypercomputer-Architektur ein integriertes System bereit, bei dem Hardware, Software und Verbrauchsmodelle optimal aufeinander abgestimmt sind. Diese Einbindung ermöglicht Effizienz auf Systemebene in Bezug auf Leistung, Kosten und Markteinführungszeit – etwas, das durch das Zusammenfügen getrennter Dienste schwerer zu erreichen ist. Die Architektur vereinfacht die Komplexität und bietet einen ganzheitlichen Ansatz für die KI-Infrastruktur.
Kann AI Hypercomputer in einer Hybrid- oder Multi-Cloud-Umgebung verwendet werden?
Ja, AI Hypercomputer ist flexibel einsetzbar. Technologien wie Cross-Cloud Interconnect ermöglichen eine Konnektivität mit hoher Bandbreite zu lokalen Rechenzentren und anderen Clouds und erleichtern so hybride und Multi-Cloud-KI-Strategien. Wir arbeiten mit offenen Standards und binden gängige Drittanbieter-Software ein, damit Sie Lösungen entwickeln können, die mehrere Umgebungen umfassen, und Dienste nach Belieben anpassen können.
Wie sorgt AI Hypercomputer für die Sicherheit von KI-Arbeitslasten?
Sicherheit ist ein zentraler Aspekt der AI Hypercomputer-Architektur. Sie profitiert vom mehrschichtigen Sicherheitsmodell von Google Cloud. Zu den spezifischen Funktionen gehören Titan-Sicherheitsmikrocontroller (die dafür sorgen, dass Systeme aus einem vertrauenswürdigen Zustand heraus gestartet werden), die RDMA-Firewall (für Zero-Trust-Netzwerke zwischen TPUs/GPUs während des Trainings) und die Einbindung von Lösungen wie Model Armor zur Bereitstellung der KI-Sicherheit. Ergänzt werden diese Funktionen durch robuste Richtlinien und Grundsätze für die Infrastruktursicherheit, wie das Secure AI Framework.
Wie lässt sich AI Hypercomputer am einfachsten als Infrastruktur nutzen?
- Wenn Sie keine VMs verwalten möchten, empfehlen wir Ihnen, mit der Google Kubernetes Engine (GKE) zu beginnen.
- Wenn Sie mehrere Scheduler verwenden müssen oder GKE nicht nutzen können, empfehlen wir Cluster Director.
- Es gibt nur einen Weg, die vollständige Kontrolle über Ihre Infrastruktur zu haben, und das ist die direkte Arbeit mit VMs. Dafür ist die Compute Engine die beste Option.
Ist dies nur für große/hochskalierte Arbeitslasten nützlich?
Nein. AI Hypercomputer kann für Arbeitslasten jeder Größe verwendet werden. Auch kleinere Arbeitslasten profitieren von den Vorteilen integrierter Systeme, wie z. B. Effizienz und vereinfachte Bereitstellung. AI Hypercomputer unterstützt Kundenunternehmen auch bei der Skalierung ihrer Geschäfte, von kleinen Proof-of-Concepts und Experimenten bis hin zu groß angelegten Produktionsbereitstellungen.
Ist AI Hypercomputer der einfachste Weg, um mit KI-Arbeitslasten in Google Cloud zu beginnen?
Für die meisten Kundenunternehmen eignet sich eine verwaltete KI-Plattform wie Vertex AI am Besten als Einstieg in die KI, da sie alle Tools, Vorlagen und Modelle bietet. Außerdem nutzt Vertex AI in einer für Sie optimierten Weise die AI Hypercomputer-Architektur. Vertex AI ist der einfachste Einstieg, weil es die unkomplizierteste Lösung ist. Wenn Sie lieber jede einzelne Komponente Ihrer Infrastruktur selbst konfigurieren und optimieren möchten, können Sie auf die Komponenten von AI Hypercomputer als Infrastrukturelemente zugreifen und sie so zusammenstellen, dass sie Ihren Anforderungen entsprechen.
Da ein AI Hypercomputer ein zusammensetzbares System ist, gibt es viele Optionen. Haben Sie Best Practices für jeden Anwendungsfall?
Ja, wir erstellen eine Bibliothek mit Schemas in GitHub. Sie können auch das Cluster Toolkit für vordefinierte Cluster-Blueprints verwenden.
Welche Optionen habe ich, wenn ich AI Hypercomputer als IaaS verwende?
KI-optimierte Hardware
Speicher
- Training: Managed Lustre eignet sich ideal für anspruchsvolles KI-Training mit hohem Durchsatz und Kapazitäten im PB-Bereich. GCS Fuse (optional mit Anywhere Cache) eignet sich für größere Kapazitätsanforderungen mit einer höheren Latenz. Beide lassen sich in GKE und Cluster Director einbinden.
- Schlussfolgerung: GCS Fuse mit Anywhere Cache bietet eine einfache Lösung. Für eine höhere Leistung sollten Sie Hyperdisk ML in Betracht ziehen. Wenn Sie Managed Lustre für das Training in derselben Zone verwenden, können Sie es auch für die Inferenz nutzen.
Netzwerk
- Training: Nutzen Sie Technologien wie RDMA-Netzwerke in VPCs und Cloud Interconnect und Cross-Cloud Interconnect mit hoher Bandbreite für eine schnelle Datenübertragung.
- Inferenz: Nutzen Sie Lösungen wie das GKE Inference Gateway und erweitertes Cloud Load Balancing für die Bereitstellung mit geringer Latenz. Model Armor kann zur Bereitstellung der KI-Sicherheit eingebunden werden.
Compute: Sie haben Zugriff auf Google Cloud TPUs (Trillium), NVIDIA-GPUs (Blackwell) und CPUs (Axion). So können Sie die Optimierung an die spezifischen Anforderungen der Arbeitslast in Bezug auf Durchsatz, Latenz oder Gesamtkosten anpassen.
Top-Software und offene Frameworks
- ML-Frameworks und ‑Bibliotheken: PyTorch, JAX, TensorFlow, Keras, vLLM, JetStream, MaxText, LangChain, Hugging Face, NVIDIA (CUDA, NeMo, Triton) und viele weitere Open-Source- und Drittanbieteroptionen.
- Compiler, Laufzeiten und Tools: XLA (für Leistung und Interoperabilität), Pathways on Cloud, Multislice Training, Cluster Toolkit (für vordefinierte Cluster-Blueprints) und viele weitere Open-Source- und Drittanbieteroptionen.
- Orchestrierung: Google Kubernetes Engine (GKE), Cluster Director (für Slurm, nicht verwaltete Kubernetes-Cluster, BYO-Scheduler) und Google Compute Engine (GCE).
Nutzungsmodelle:
- On Demand: Pay as you go.
- Rabatte für zugesicherte Nutzung (CUDs): Bei langfristigen Zusicherungen können Sie bis zu 70 % sparen.
- Spot-VMs: Ideal für fehlertolerante Batchjobs, mit hohen Rabatten (bis zu 91 %).
- Dynamic Workload Scheduler (DWS): Bis zu 50 % Einsparungen bei Batch- und fehlertoleranten Jobs.











