Pub/Sub
Importa eventi per trasmetterli in flussi in BigQuery, data lake o database operativi.
I nuovi clienti ricevono 300 $ di crediti senza costi da spendere su Pub/Sub. Tutti i clienti ricevono fino a 10 GB senza costi al mese per l'importazione o la consegna dei messaggi, senza consumare i crediti.
Esegui il deployment di una soluzione di data warehouse di esempio per esplorare, analizzare e visualizzare i dati utilizzando BigQuery e Data Studio (precedentemente Looker Studio). Inoltre, applica l'AI generativa per riassumere i risultati dell'analisi.
Sistema di messaggistica o di coda autonomo, sicuro e scalabile
Distribuzione "at least once" di messaggi in ordine e in qualsiasi ordine con modalità pull e push
Proteggi i dati con controlli degli accessi granulari e crittografia sempre attiva

Vantaggi
Alta affidabilità resa semplice
Alta affidabilità resa semplice
Il monitoraggio della replica sincrona dei messaggi tra le zone e delle conferme di ricezione per messaggio garantisce la distribuzione affidabile su qualsiasi scala.
Nessuna pianificazione, automazione completa
Nessuna pianificazione, automazione completa
Scalabilità automatica e provisioning automatico senza partizioni eliminano la pianificazione e garantiscono che i carichi di lavoro siano production-ready dal primo giorno.
Base aperta e semplice per sistemi di dati in tempo reale
Base aperta e semplice per sistemi di dati in tempo reale
Un modo rapido e affidabile per inserire piccoli record in qualsiasi volume, un punto di ingresso per pipeline batch e in tempo reale che alimentano BigQuery, data lake e database operativi. Utilizzala con le pipeline ETL/ELT in Dataflow.
Funzionalità principali
Funzionalità principali
Analisi dei flussi di dati e connettori
L'integrazione nativa con Dataflow consente l'elaborazione e l'integrazione "exactly-once", significativa e affidabile di flussi di eventi in Java, Python e SQL.
Consegna in ordine su larga scala
L'ordinamento facoltativo in base alla chiave semplifica la logica dell'applicazione stateful senza sacrificare la scalabilità orizzontale. Non sono richieste partizioni.
Importazione di flussi di dati semplificata con integrazioni native
Importa flussi di dati da Pub/Sub direttamente in BigQuery o Cloud Storage con le nostre sottoscrizioni native.
Clienti
Impara dai clienti che utilizzano Pub/Sub


Novità
Novità
Iscriviti alle newsletter di Google Cloud per ricevere aggiornamenti sui prodotti, informazioni sugli eventi, offerte speciali e molto altro.



Documentazione
Documentazione
Casi d'uso
Casi d'uso
Analisi dei flussi
L'analisi dei flussi di dati di Google rende i dati più organizzati, utili e accessibili fin dal momento in cui vengono generati. Costruita su Pub/Sub insieme a Dataflow e BigQuery, la nostra soluzione per i flussi di dati fornisce le risorse necessarie per importare, elaborare e analizzare volumi variabili di dati in tempo reale per insight sull'attività commerciale in tempo reale. Questo provisioning astratto riduce la complessità e rende l'analisi dei flussi di dati accessibile sia ai data analyst che ai data engineer.
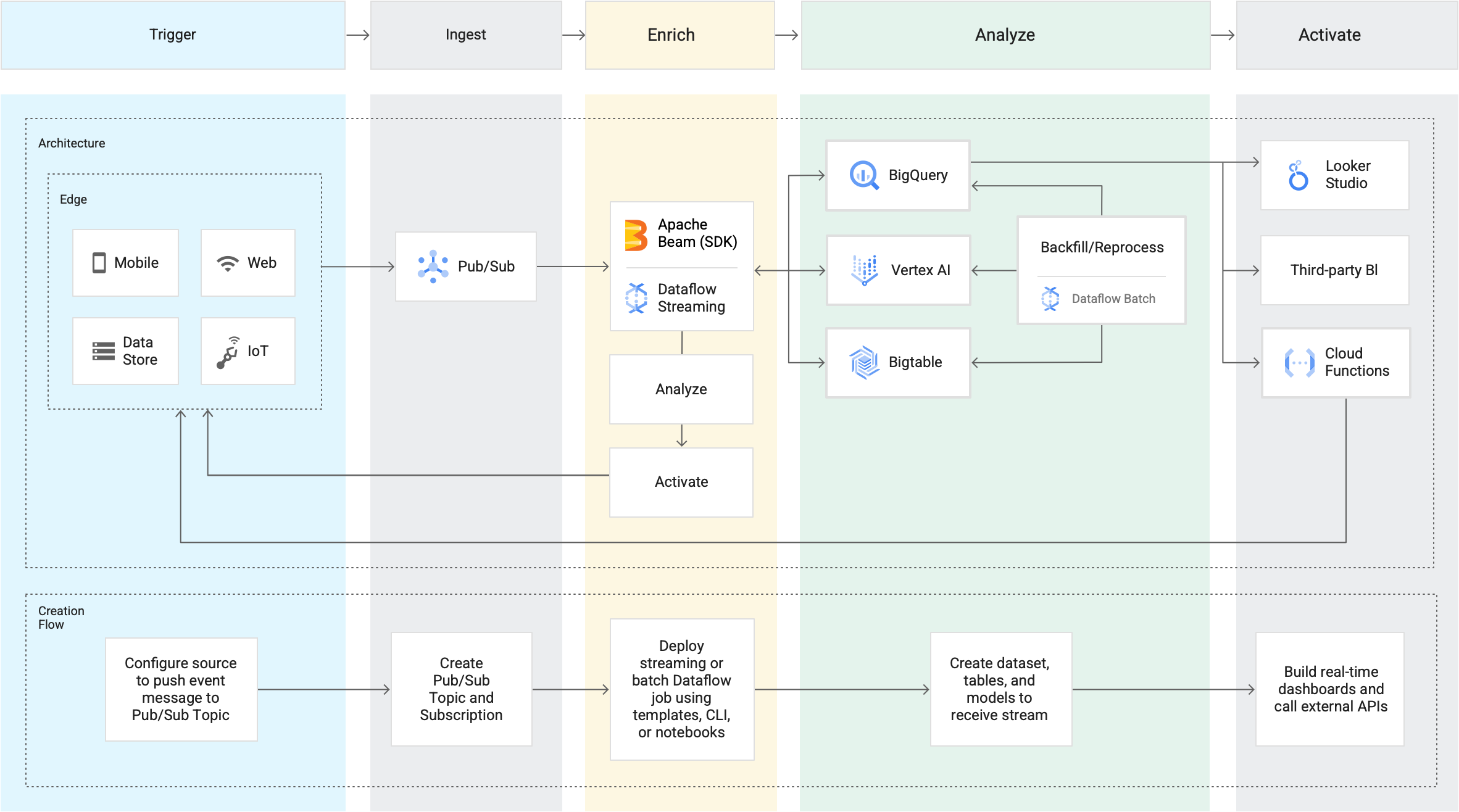
Integrazione di microservizi asincroni
Pub/Sub opera come middleware di messaggistica per l'integrazione di servizi tradizionali o come semplice mezzo di comunicazione per microservizi moderni. Le sottoscrizioni push consegnano gli eventi a webhook serverless su Cloud Functions, App Engine, Cloud Run o ambienti personalizzati su Google Kubernetes Engine o Compute Engine. La consegna pull a bassa latenza è disponibile quando l'esposizione ai webhook non è possibile o per una gestione efficiente di flussi a velocità effettiva più alta.
Tutte le funzionalità
Tutte le funzionalità
| Distribuzione "at-least-once" | Il monitoraggio della replica sincrona dei messaggi tra le zone e delle conferme di ricezione per messaggio garantisce la distribuzione "at-least-once" su qualsiasi scala. |
| Apri | Le API aperte e le librerie client in sette linguaggi supportano deployment di tipo ibrido e cross-cloud. |
| Elaborazione "exactly-once" | Dataflow supporta l'elaborazione "exactly-once", significativa e affidabile dei flussi di Pub/Sub. |
| Nessun provisioning, automazione completa | Pub/Sub non ha shard o partizioni. Devi solo impostare la tua quota, pubblicare e utilizzare i messaggi. |
| Sicurezza e conformità | Pub/Sub è un servizio conforme alla normativa HIPAA e offre controlli granulari degli accessi e crittografia end-to-end. |
| Integrazioni native di Google Cloud | Sfrutta l'integrazione con numerosi servizi come gli eventi di aggiornamento di Gmail e Cloud Storage e con Cloud Functions per il serverless computing basato su eventi. |
| Integrazioni con software open source o di terze parti | Pub/Sub fornisce integrazioni con prodotti di terze parti come Splunk e Datadog per i log e Striim e Informatica per l'integrazione di dati. In più, sono disponibili integrazioni di software open source tramite Confluent Cloud per Apache Kafka e Knative Eventing per i carichi di lavoro serverless basati su Kubernetes. |
| Cerca e riproduci | Riavvolgi in qualsiasi momento il tuo backlog o uno snapshot, permettendo di rielaborare i messaggi. Avanza rapidamente per eliminare i dati obsoleti. |
| Argomenti messaggi non recapitabili | Gli argomenti non recapitabili consentono di mettere da parte i messaggi che non possono essere elaborati dalle applicazioni del sottoscrittore per esaminarli ed eseguirne il debug offline, in modo che altri messaggi possano essere elaborati senza ritardi. |
| Filtri | Pub/Sub può filtrare i messaggi a seconda degli attributi per ridurre i volumi di consegna ai sottoscrittori. |
Prezzi
Prezzi
Il prezzo di Pub/Sub è calcolato su volumi di dati mensili. I primi 10 GB di dati mensili vengono offerti senza costi aggiuntivi.
Volume di dati mensile1 | Prezzo per TB2 |
|---|---|
Primi 10 GB | $ 0,00 |
Oltre 10 GB | $ 40,00 |
1Per informazioni più dettagliate sui prezzi, consulta la guida ai prezzi.
2 TB significa tebibyte, pari a 240 byte.
Se la valuta utilizzata per il pagamento è diversa da USD, si applicano i prezzi elencati nella tua valuta negli SKU di Cloud Platform.
Fai un passo avanti
Inizia a creare su Google Cloud con 300 $ di crediti senza costi e oltre 20 prodotti sempre senza costi.
Hai bisogno di aiuto per iniziare?
Contatta il team di venditaCollabora con un partner di fiducia
Trova un partnerContinua la navigazione
Visualizza tutti i prodotti


















