Backup e restauração do MySQL
Quando o inesperado acontece, sua empresa pode sofrer. Falhas de hardware, corrupção do banco de dados, erros de usuários e até mesmo ataques maliciosos podem criar risco de perda de dados. Os backups do banco de dados ajudam a recuperar e manter sua empresa funcionando, mesmo que algo dê errado. E os backups de banco de dados ajudam a atender aos requisitos de conformidade e auditoria permitindo restaurar o banco de dados para um ponto específico no passado.
O MySQL oferece várias opções para fazer backup dos bancos de dados, cada uma com diferentes pontos fortes. Escolha qualquer combinação de métodos que melhor atenda às suas necessidades.
Tipos de backup
Há duas maneiras principais de fazer backup de um banco de dados MySQL: física e lógica. O backup físico copia os arquivos de dados reais, e o backup lógico gera instruções, como CREATE TABLE e INSERT, que podem recriar os dados.
Backup físico
Um backup físico contém as cópias brutas de todos os arquivos e diretórios como eles se encontram no disco. Esse tipo de backup é adequado para bancos de dados grandes, porque copiar os arquivos brutos é muito mais rápido do que fazer um backup lógico.
Vantagens:
- Os backups físicos são simples e eficientes. Eles não precisam de muita memória ou muitos ciclos de CPU para serem executados
- Os backups físicos não exigem nenhum trabalho extra para gerar os arquivos brutos. Tudo o que você precisa fazer é copiar os arquivos brutos e diretórios para o local de backup
- Os backups físicos são mais rápidos de restaurar do que os backups lógicos, porque o MySQL não precisa recriar os objetos do banco de dados e importar os dados
Desvantagens:
- Os backups físicos geralmente ocupam muito mais espaço do que os backups lógicos porque contêm registros de transações, registros "undo" e outros, além dos espaços de tabela InnoDB (que são compartilhados e por arquivos table.ibd e geralmente têm espaço fragmentado)
- Os backups físicos nem sempre são portáteis em plataformas, sistemas operacionais e versões do MySQL
- Como os backups físicos copiam os arquivos brutos, se houver algum corrompido, eles também serão copiados para os arquivos de backup
Algumas ferramentas de backup físico comuns no ecossistema do MySQL
Backup lógico
Um backup lógico contém os dados no banco de dados em um formato que o MySQL pode interpretar como SQL ou como texto delimitado. Ele é uma representação do banco de dados como uma sequência de instruções SQL que podem ser executadas para recriar objetos do banco de dados e importar dados. Esse tipo de backup é adequado para pequenos bancos de dados, porque os backups lógicos podem levar muito mais tempo para restaurar do que restaurar um backup físico. Esse tipo de backup também é útil ao migrar de ou para serviços de banco de dados gerenciados na nuvem.
Vantagens:
- Os backups lógicos são muito flexíveis. Elas oferecem alta granularidade em operações de backup e restauração no nível do servidor (todos os bancos de dados), no nível do banco de dados (todas as tabelas em um banco de dados específico), no nível da tabela ou até mesmo no nível da linha (tabela) linhas correspondentes à condição WHERE especificada).
- Os backups lógicos são mais fáceis de restaurar. Basta canalizar o arquivo de backup para o cliente mysql e usar a instrução LOAD DATA ou o comando mysqlimport para carregar os arquivos delimitados por texto.
- Os backups lógicos podem ser executados remotamente a partir de uma máquina diferente, o que permite fazer backup e restaurar o banco de dados em uma rede. Isso é muito útil para bancos de dados na nuvem, como Google Cloud SQL, Amazon RDS e Microsoft Azure, em que os usuários não têm acesso direto à máquina virtual.
- Os backups lógicos ajudam a evitar que os dados sejam corrompidos. Os backups físicos podem ser corrompidos, o que pode passar despercebido até a verificação. Como os backups lógicos geralmente são arquivos de texto, é mais fácil analisá-los com um editor de texto e identificar qualquer corrupção. Os backups lógicos raramente são corrompidos.
- Ao contrário dos backups físicos, os backups lógicos são altamente portáteis entre plataformas, sistemas operacionais e versões do MySQL.
- Os backups lógicos são altamente compactáveis.
Desvantagens:
- A criação de backups lógicos é mais lenta, porque você precisa consultar o servidor MySQL para conseguir o esquema e as linhas e, em seguida, converter para um formato lógico
- Os backups lógicos também são mais lentos de restaurar, já que o MySQL precisa executar instruções SQL para criar a tabela, importar as linhas e recriar os índices
- Em comparação com backups físicos, os backups lógicos exigem mais recursos de servidor (CPU, RAM e E/S de disco) para operações de backup e restauração.
Algumas ferramentas de backup lógico comuns
Recuperação pontual (PITR)
Como o nome sugere, a recuperação pontual ajuda a recuperar uma instância para um momento específico. Por exemplo, se houver perda de dados devido a um erro, será possível recuperar um banco de dados no estado anterior a esse evento.
A PITR é um processo de duas etapas que depende de registros binários:
- Restaure um backup físico ou lógico completo para que o servidor fique no mesmo estado em que estava no backup
- Aplique os registros binários para reproduzir as alterações entre o horário do backup e o momento desejado
Os registros binários contêm alterações feitas na instância do banco de dados, como criação de tabela, inserção/atualização/exclusão de linha e outras. Por exemplo, digamos que seus backups diários sejam executados às 6h e você queira recuperar sua instância a qualquer momento até as 10h15. Para recuperar o estado às 10h15, primeiro restaure o backup completo das 6h e repita os eventos de registro binário das 6h até às 10h15. Isso levará o servidor ao estado desejado no momento desejado.
Os registros binários são necessários para replicação e PITR. Eles são tão importantes quanto os dados. É necessário fazer backup dos registros binários em tempo real para que eles sejam eficazes no seu planejamento de recuperação. É possível fazer o download deles com o comando mysqlbinlog.
Exemplo:
mysqlbinlog --host=<hostname> --port=<port> --user=<user> --password=<password> --read-from-remote-server --raw --stop-never <binlog_filename> |
O <binlog_filename> será o primeiro arquivo a ser transferido por download, e o mysqlbinlog alternará automaticamente para o próximo arquivo depois. Esses registros binários são gravados no diretório atual do servidor que executa o comando mysqlbinlog. É possível alterar o nome e o local do arquivo usando a opção --result-file. Também é possível usar a opção --stop-never para permitir que o binlog mysqlbinlog permaneça conectado ao servidor e faça o download de novas alterações à medida que elas forem gravadas.
Saiba mais no manual do mysqlbinlog sobre como se conectar a um servidor remoto e fazer o download dos registros binários enquanto eles são gravados.
Backup e restauração no Cloud SQL para MySQL
Como o serviço de banco de dados gerenciado do Google Cloud para MySQL, o Cloud SQL oferece backups automatizados e recuperação pontual para proteção de dados. Eles são ativados por padrão e necessários para ativar a alta disponibilidade (HA, na sigla em inglês) em uma instância do Cloud SQL para MySQL.
Qualquer backup do Cloud SQL é um tipo de backup físico, já que são snapshots capturados no Persistent Disk (PD). O Cloud SQL oferece a flexibilidade de fazer com que os backups aconteçam automaticamente ou sob demanda a qualquer momento. Ainda é possível fazer um backup lógico usando as ferramentas de backup lógicos padrão do MySQL, como mysqldump, mydumper, mysqlpump e outros, sem interferir nos backups gerenciados.
Vamos ver em mais detalhes como os backups do Cloud SQL funcionam.
Entendendo os snapshots do Cloud SQL
O Cloud SQL usa o Persistent Disk (PD) para armazenamento, e cada instância do Cloud SQL tem um disco de dados permanente anexado para armazenar os arquivos e diretórios do banco de dados.
O Cloud SQL usa snapshots de DP para backups. Esses snapshots se referem ao estado do disco de dados em um determinado momento. O primeiro snapshot de um DP é um snapshot completo que contém todos os dados no DP. Os snapshots subsequentes são incrementais e contêm apenas dados novos ou modificados desde o snapshot anterior. Pense nesses snapshots como cópias físicas gerenciadas pela nuvem de discos de dados permanentes, que são a base de todos os recursos de backup e restauração do Cloud SQL, incluindo a PITR.
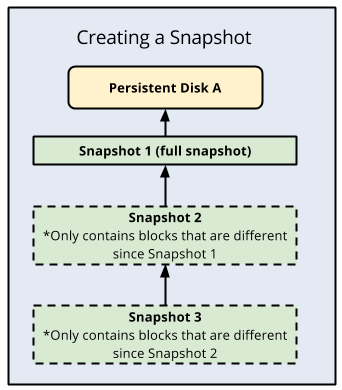
Backups do Cloud SQL
O Cloud SQL executa dois tipos de backups gerenciados: automatizados e sob demanda. Os dois tipos são armazenados no local multirregional mais próximo à instância por padrão. Por exemplo, se a instância do Cloud SQL estiver em us-central1, os backups serão armazenados na multirregião EUA por padrão. No entanto, um local padrão como a australia-southeast1 está fora de uma multirregião e será colocado na multirregião mais próxima, que é a Ásia. Também é possível escolher um local personalizado para os backups.
Backups automatizados
Os backups automatizados são feitos diariamente durante uma janela de quatro horas de sua escolha. O backup é iniciado durante essa janela e pode continuar fora desse período até ser concluído. É possível configurar quantos backups automáticos são retidos, de 1 a 365. A política de retenção padrão é reter os sete backups mais recentes.
Backups sob demanda
Também é possível criar backups sob demanda a qualquer momento. Eles são úteis se você precisar de um backup e não quiser esperar pela janela de backup. Além disso, ao contrário dos backups automatizados, os sob demanda não são excluídos automaticamente. Eles perduram até que você os exclua ou até que a instância deles seja excluída.
Como restaurar um backup do Cloud SQL
É possível restaurar um backup na mesma instância em que ele foi feito ou em uma instância diferente no mesmo projeto. A instância de destino não pode ser uma réplica de leitura nem ter réplicas de leitura no momento de restaurar o backup, já que as réplicas de leitura são cópias de uma instância primária e cria o risco de que as réplicas fiquem dessincronizadas com a principal. É possível adicionar réplicas de leitura posteriormente.
A restauração do backup cria um novo DP a partir desse snapshot de backup e o anexa à instância. O banco de dados começa a usar o novo disco e executa o processo padrão de recuperação de falhas do MySQL antes de ficar on-line como um banco de dados MySQL completo recém-restaurado do snapshot.
Restaurar para a mesma instância
A restauração de um backup na mesma instância retorna os dados para o estado em que estavam no momento do backup.
Restaurar para uma instância diferente
Ao usar um backup para restaurar para uma instância diferente, os dados na instância de destino são atualizados para o estado em que eles estavam na instância de origem no momento em que o backup foi feito.
Importante: a restauração de um backup substitui todos os dados atuais na instância de destino, incluindo os registros de recuperação pontual anteriores. Os dados substituídos não podem ser recuperados.
Recuperação pontual (PITR) do Cloud SQL
No Cloud SQL, a PITR sempre cria uma nova instância que herda as configurações da instância de origem, semelhante à operação de clone. Esse recurso requer que os backups automatizados e a recuperação pontual (registros binários) estejam ativados na instância de origem. A política de retenção padrão em registros binários é de sete dias, e é possível configurar o período de armazenamento entre 1 e 7 dias.
A PITR é alcançada criando uma nova instância a partir do backup da instância original e reproduzindo novamente os registros binários armazenados no disco de dados da instância original para o ponto especificado.
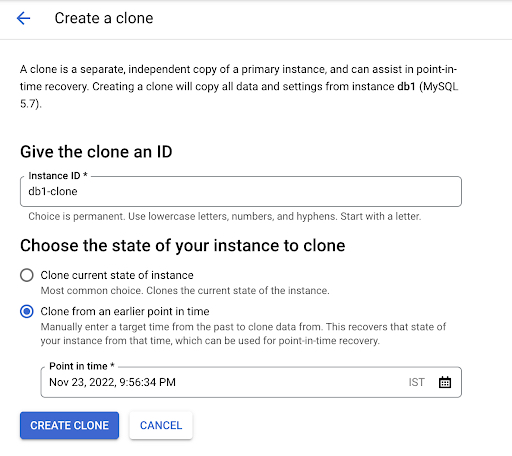
Ao executar a PITR no Cloud SQL, os clientes podem clonar o estado atual da instância ou um carimbo de data/hora no passado.
A IU para executar a PITR é semelhante a esta:
Produtos e serviços relacionados
O Google Cloud oferece um banco de dados MySQL gerenciado para atender às suas necessidades de negócios, desde a desativação de um data center local até a execução de aplicativos SaaS e a migração dos principais sistemas de negócios.
Vá além
Comece a criar no Google Cloud com US$ 300 em créditos e mais de 20 produtos do programa Sempre gratuito.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos


















