Backup e ripristino MySQL
Quando si verifica un imprevisto, la tua azienda può risentirne. Errori hardware, danneggiamento dei database, errori degli utenti e persino attacchi dannosi possono comportare il rischio di perdita di dati. I backup dei database ti aiutano a recuperare e a mantenere operativa la tua azienda, anche se si verifica un errore. E anche in assenza di problemi, i backup del database ti aiutano a soddisfare i requisiti di conformità e controllo permettendoti di ripristinare il tuo database in un punto precedente specifico.
MySQL supporta diverse opzioni per il backup dei tuoi database, ognuna con punti di forza diversi. Puoi scegliere qualsiasi combinazione di metodi più adatti alle tue esigenze.
Tipi di backup
Esistono due metodi principali per il backup di un database MySQL: fisico e logico. Il backup fisico copia i file di dati effettivi mentre il backup logico genera istruzioni come CREATE TABLE e INSERT che possono ricreare i dati.
Backup fisico
Un backup fisico contiene le copie non elaborate di tutti i file e di tutte le directory presenti sul disco. Questo tipo di backup è adatto a database di grandi dimensioni perché la copia dei file non elaborati è molto più rapida rispetto all'esecuzione di un backup logico.
Vantaggi:
- I backup fisici sono semplici ed efficienti; non richiedono molta memoria o molti cicli di CPU per l'esecuzione
- I backup fisici non richiedono lavoro aggiuntivo per generare i file non elaborati; tutto ciò che devi fare è copiare i file e le directory non elaborati nella posizione di backup
- Ripristino più veloce dei backup fisici rispetto ai backup logici perché MySQL non deve ricreare gli oggetti del database e importare i dati
Svantaggi:
- I backup fisici spesso richiedono molto più spazio rispetto ai backup logici perché contengono log delle transazioni, log di annullamento e altri elementi, oltre agli spazi delle tabelle InnoDB (che sono condivisi e per file table.ibd e di solito hanno spazio frammentato)
- I backup fisici non sono sempre portabili su piattaforme, sistemi operativi e versioni di MySQL
- Poiché i backup fisici copiano i file non elaborati, anche eventuali danneggiamenti sottostanti verranno copiati nei file di backup
Alcuni strumenti di backup fisici comuni in tutto l'ecosistema MySQL
Backup logico
Un backup logico contiene i dati nel database in un formato che MySQL può interpretare come SQL o come testo delimitato. È una rappresentazione del tuo database come una sequenza di istruzioni SQL che possono essere eseguite per ricreare oggetti di database e importare dati. Questo tipo di backup è adatto ai database di piccole dimensioni perché il ripristino dei backup logici può richiedere molto più tempo rispetto al ripristino di un backup fisico. Questo tipo di backup è utile anche durante la migrazione da o verso servizi di database gestiti nel cloud.
Vantaggi:
- I backup logici sono molto flessibili. Offrono un'elevata granularità delle operazioni di backup e ripristino a livello di server (tutti i database), a livello di database (tutte le tabelle di un determinato database), a livello di tabella o anche a livello di riga (righe di tabella corrispondenti alla condizione WHERE).
- È più semplice ripristinare i backup logici: è sufficiente inviare il file di backup al client mysql e utilizzare l'istruzione LOAD DATA o il comando mysqlimport per caricare i file con testo delimitato.
- I backup logici possono essere eseguiti da remoto da una macchina diversa, il che ti consente di eseguire il backup e il ripristino del tuo database su una rete. Questo è molto utile per i database cloud come Google Cloud SQL, Amazon RDS e Microsoft Azure in cui gli utenti non hanno accesso diretto alla macchina virtuale.
- I backup logici contribuiscono a evitare il danneggiamento dei dati. I backup fisici possono essere danneggiati, il che può passare inosservato fino alla verifica. Poiché i backup logici sono in genere file di testo, è più facile rivederli con un editor di testo e individuare eventuali danni. I backup logici raramente vengono danneggiati.
- A differenza dei backup fisici, i backup logici sono altamente portabili su piattaforme, sistemi operativi e versioni di MySQL.
- I backup logici sono altamente comprimibili.
Svantaggi:
- La creazione dei backup logici è più lenta, poiché devi eseguire query sul server MySQL per ottenere schema e righe, quindi eseguire la conversione in un formato logico
- Anche i backup logici sono più lenti da ripristinare, dal momento che MySQL deve eseguire istruzioni SQL per creare la tabella, importare le righe e ricreare gli indici
- Rispetto ai backup fisici, i backup logici richiedono più risorse del server (CPU, RAM e I/O del disco) per le operazioni di backup e ripristino
Alcuni strumenti di backup logici comuni
Recupero point-in-time (PITR)
Come suggerisce il nome, il recupero point-in-time ti aiuta a recuperare un'istanza in un momento specifico. Ad esempio, se un errore causa una perdita di dati, puoi ripristinare lo stato di un database prima che si verifichi l'errore.
Il PITR è un processo in due fasi, che si basa su log binari:
- Ripristina un backup fisico o logico completo per riportare il server nello stesso stato in cui si trovava al momento del backup
- Applica i log binari per riprodurre le modifiche tra il momento del backup e il momento desiderato
I log binari contengono le modifiche apportate all'istanza di database, come la creazione di una tabella, l'inserimento/aggiornamento/eliminazione di righe e altro. Ad esempio, supponiamo che i backup giornalieri vengano eseguiti alle 06:00 e che tu voglia poter ripristinare l'istanza in qualsiasi momento fino alle 10:15. Per ripristinare il tuo stato alle 10:15, dovrai ripristinare prima il backup completo a partire dalle 06:00, quindi ripetere gli eventi del log binario dalle 06:00 alle 10:15 AM. In questo modo verrà visualizzato lo stato del server al momento desiderato.
I log binari sono necessari per la replica e il PITR; sono importanti quanto i dati sottostanti. Devi eseguire il backup dei log binari in tempo reale per renderli efficaci nella pianificazione di ripristino e puoi scaricarli utilizzando il comando mysqlbinlog.
Ad esempio:
mysqlbinlog --host=<hostname> --port=<port> --user=<user> --password=<password> --read-from-remote-server --raw --stop-never <binlog_filename> |
<binlog_filename> sarà il primo file da scaricare, dopodiché mysqlbinlog passerà automaticamente ai file successivi. Questi log binari vengono scritti nella directory attuale del server che esegue il comando mysqlbinlog. Puoi modificare il nome e la posizione del file utilizzando l'opzione --result-file. Puoi anche utilizzare l'opzione --stop-never per consentire a mysqlbinlog binlog di rimanere connesso al server e scaricare nuove modifiche man mano che vengono scritte.
Puoi trovare ulteriori informazioni sul manuale di mysqlbinlog su come connettersi a un server remoto e scaricare i log binari man mano che vengono scritti.
Backup e ripristino in Cloud SQL per MySQL
Essendo il servizio di database gestito di Google Cloud per MySQL, Cloud SQL offre i backup automatici e il recupero point-in-time (PITR) per la protezione dei dati. Questi sono attivati per impostazione predefinita e sono obbligatori per abilitare l'alta disponibilità su un'istanza Cloud SQL per MySQL.
Qualsiasi backup di Cloud SQL è un tipo di backup fisico, poiché si tratta di snapshot acquisiti su Persistent Disk (PD). Cloud SQL offre la flessibilità necessaria per eseguire automaticamente i backup, altrimenti puoi eseguirli on demand in qualsiasi momento. Puoi comunque eseguire un backup logico utilizzando gli strumenti di backup logico standard MySQL come mysqldump, mydumper, mysqlpump e altri senza interferire con i backup gestiti.
Vediamo come funzionano i backup di Cloud SQL.
Informazioni sugli snapshot di Cloud SQL
Cloud SQL utilizza Persistent Disk (PD) per l'archiviazione e ogni istanza Cloud SQL ha un disco dati permanente collegato per l'archiviazione di directory e file di database.
Cloud SQL utilizza gli snapshot PD per i backup e questi snapshot si riferiscono allo stato del disco dati in un determinato momento. Il primo snapshot di un DP è uno snapshot completo che contiene tutti i dati nel PD. Gli snapshot successivi sono incrementali e contengono solo i nuovi dati o i dati modificati rispetto allo snapshot precedente. Puoi considerarli come copie fisiche dei dischi dati permanenti gestiti nel cloud e sono alla base di tutte le funzionalità di backup e ripristino di Cloud SQL, incluso il PITR.
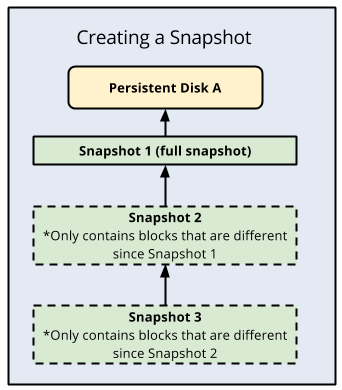
Backup di Cloud SQL
Cloud SQL esegue due tipi di backup gestiti: automatici e on demand. Entrambi i tipi sono archiviati per impostazione predefinita nella località a più regioni più vicina all'istanza. Ad esempio, se l'istanza Cloud SQL si trova nella regione us-central1, i tuoi backup vengono archiviati per impostazione predefinita negli Stati Uniti in più regioni. Tuttavia, una località predefinita come australia-southeast1 si trova al di fuori di più regioni e verrà inserita nella regione più vicina, ovvero asia. Puoi anche scegliere una località personalizzata per i backup.
Backup automatici
I backup automatici vengono effettuati ogni giorno in una finestra di 4 ore di tua scelta. Il backup inizia nella finestra di backup e potrebbe continuare al di fuori della finestra di backup fino al completamento. Puoi impostare il numero di backup automatici da conservare, da 1 a 365. Il criterio di conservazione predefinito prevede la conservazione dei 7 backup più recenti.
Backup on demand
Puoi anche creare backup on demand in qualsiasi momento. Sono utili se hai bisogno di eseguire un backup senza attendere la finestra di backup. Inoltre, a differenza dei backup automatici, i backup on demand non vengono eliminati automaticamente. Rimangono visibili finché non li elimini o finché la loro istanza non viene eliminata.
Ripristino di un backup di Cloud SQL
Puoi ripristinare un backup nella stessa istanza in cui è stato eseguito o in un'altra istanza dello stesso progetto. Tieni presente che l'istanza di destinazione non deve essere una replica di lettura, né dovrebbe avere repliche di lettura al momento del ripristino del backup, poiché le repliche di lettura sono copie di un'istanza principale e c'è il rischio che le repliche non vengano sincronizzate con quest'ultima. Puoi sempre aggiungere repliche di lettura in seguito.
Il ripristino del backup crea un nuovo DP dallo snapshot di backup e lo collega all'istanza. Il database inizia a utilizzare il nuovo disco ed esegue la procedura standard MySQL per il ripristino da un arresto anomalo prima di essere disponibile online come database MySQL a tutti gli effetti, appena ripristinato dallo snapshot.
Ripristino nella stessa istanza
Quando esegui il ripristino da un backup nella stessa istanza, i dati dell'istanza tornano allo stato in cui erano al momento del backup.
Ripristino in un'altra istanza
Quando esegui il ripristino da un backup in un'altra istanza, i dati dell'istanza di destinazione vengono aggiornati allo stato dell'istanza di origine al momento del backup.
Importante: il ripristino di un backup sovrascrive tutti i dati attuali nell'istanza di destinazione, inclusi i log di recupero point-in-time precedenti. I dati sovrascritti non possono essere recuperati.
Recupero point-in-time (PITR) di Cloud SQL
In Cloud SQL, il PITR crea sempre una nuova istanza che eredita le impostazioni dell'istanza di origine, in modo simile all'operazione di clonazione dell'istanza. Questa funzionalità richiede l'abilitazione sia dei backup automatici sia del recupero point-in-time (log binari) nell'istanza di origine. Il criterio di conservazione predefinito sui log binari è di 7 giorni e puoi configurare un periodo di conservazione compreso tra 1 e 7 giorni.
Il PITR si ottiene creando una nuova istanza dal backup dell'istanza originale e riproducendo i log binari archiviati sul disco dati dell'istanza originale nel punto specificato.
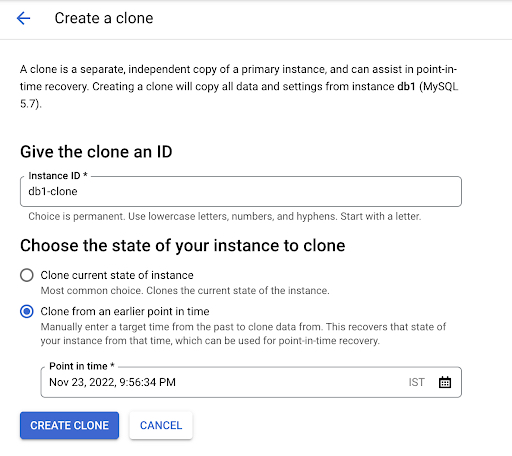
Quando eseguono il PITR in Cloud SQL, i clienti possono scegliere di clonare lo stato attuale dell'istanza o un timestamp precedente.
La UI per eseguire il PITR è simile all'esempio seguente.
Prodotti e servizi correlati
Google Cloud offre un database MySQL gestito che è stato creato per soddisfare le tue esigenze aziendali, dal ritiro del data center on-premise all'esecuzione di applicazioni SaaS, fino alla migrazione dei sistemi aziendali principali.
Fai il prossimo passo
Inizia a creare su Google Cloud con 300 $ di crediti gratuiti e oltre 20 prodotti Always Free.
Hai bisogno di aiuto per iniziare?
Contatta il team di venditaCollabora con un partner di fiducia
Trova un partnerContinua la navigazione
Visualizza tutti i prodotti


















