Sauvegarde et restauration MySQL
Lorsqu'un événement inattendu se produit, votre activité peut en pâtir. Une défaillance matérielle, la corruption d'une base de données, des erreurs utilisateur et même des attaques malveillantes peuvent entraîner un risque de perte de données. Les sauvegardes de base de données vous aident à récupérer et à assurer la continuité de votre activité, même en cas de problème. De plus, même en l'absence de problème, les sauvegardes de base de données vous aident à répondre aux exigences de conformité et d'audit en vous permettant de restaurer votre base de données à un moment précis.
MySQL accepte plusieurs options pour sauvegarder vos bases de données, chacune ayant ses propres points forts. Vous pouvez choisir la combinaison de méthodes la plus adaptée à vos besoins.
Types de sauvegarde
Il existe deux méthodes principales pour sauvegarder une base de données MySQL : physique et logique. La sauvegarde physique copie les fichiers de données réels, tandis que la sauvegarde logique génère des instructions telles que "CREATE TABLE" et "INSERT", permettant de recréer les données.
Sauvegarde physique
Une sauvegarde physique contient les copies brutes de tous les fichiers et répertoires présents sur le disque. Ce type de sauvegarde convient aux bases de données volumineuses, car il est beaucoup plus rapide de copier les fichiers bruts que d'effectuer une sauvegarde logique.
Avantages :
- Les sauvegardes physiques sont simples et efficaces. Leur exécution ne nécessite pas beaucoup de mémoire ni de cycles de processeur.
- Les sauvegardes physiques ne nécessitent aucun travail supplémentaire pour la génération des fichiers bruts : il vous suffit de copier les fichiers bruts et les répertoires vers l'emplacement de sauvegarde.
- Les sauvegardes physiques sont plus rapides à restaurer que les sauvegardes logiques, car MySQL n'a pas besoin de recréer les objets de base de données et d'importer les données.
Inconvénients :
- Les sauvegardes physiques prennent souvent beaucoup plus de place que les sauvegardes logiques, car elles contiennent des journaux de transactions, des journaux de rétablissement, etc., en plus des espaces de table InnoDB (qui sont des fichiers partagés et par table.ibd, et qui présentent généralement un espace fragmenté)
- Les sauvegardes physiques ne sont pas toujours portables entre les plates-formes, les systèmes d'exploitation et les versions de MySQL
- Étant donné que les sauvegardes physiques copient les fichiers bruts, toute corruption sous-jacente à ces fichiers sera également copiée dans les fichiers de sauvegarde.
Voici quelques outils de sauvegarde physique courants dans l'écosystème MySQL :
Sauvegarde logique
Une sauvegarde logique contient les données de la base de données sous une forme interprétable par MySQL, soit en tant que SQL, soit en tant que texte délimité. Il s'agit d'une représentation de votre base de données sous la forme d'une séquence d'instructions SQL pouvant être exécutées afin de recréer les objets de base de données et d'importer les données. Ce type de sauvegarde convient aux petites bases de données, car la restauration des sauvegardes logiques peut prendre beaucoup plus de temps que les sauvegardes physiques. Ce type de sauvegarde est également utile lors de la migration vers ou depuis des services de base de données gérés dans le cloud.
Avantages :
- Les sauvegardes logiques sont très flexibles. Elles offrent des niveaux de précision élevés pour les opérations de sauvegarde et de restauration au niveau du serveur (toutes les bases de données), au niveau de la base de données (toutes les tables d'une base de données particulière), au niveau d'une table ou même au niveau des lignes (lignes de table correspondant à une condition "WHERE" donnée).
- Les sauvegardes logiques sont plus faciles à restaurer. Il vous suffit de transférer le fichier de sauvegarde au client mysql, puis d'utiliser l'instruction "LOAD DATA" ou la commande mysqlimport pour charger les fichiers texte délimités.
- Les sauvegardes logiques peuvent s'exécuter à distance depuis un autre ordinateur, ce qui vous permet de sauvegarder et de restaurer votre base de données à travers un réseau. Cela est très utile pour les bases de données cloud telles que Google Cloud SQL, Amazon RDS et Microsoft Azure, où les utilisateurs n'ont pas d'accès direct à la machine virtuelle.
- Les sauvegardes logiques permettent d'éviter la corruption des données. Les sauvegardes physiques peuvent inclure des éléments corrompus qui peuvent passer inaperçus jusqu'à la validation. Les sauvegardes logiques étant généralement des fichiers texte, il est plus facile de les examiner à l'aide d'un éditeur de texte et d'identifier tout élément corrompu. Les sauvegardes logiques sont rarement corrompues.
- Contrairement aux sauvegardes physiques, les sauvegardes logiques sont hautement portables entre les plates-formes, les systèmes d'exploitation et les versions de MySQL.
- Les sauvegardes logiques peuvent être fortement compressées.
Inconvénients :
- La création de sauvegardes logiques est plus lente, car vous devez interroger le serveur MySQL pour obtenir le schéma et les lignes, puis convertir ces éléments dans un format logique.
- La restauration des sauvegardes logiques est également plus lente, car MySQL doit exécuter des instructions SQL pour créer la table, importer les lignes et recréer les index
- Par rapport aux sauvegardes physiques, les sauvegardes logiques nécessitent davantage de ressources serveur (processeur, mémoire RAM et E/S disque) pour les opérations de sauvegarde et de restauration
Voici quelques outils de sauvegarde logique courants :
Récupération à un moment précis (PITR)
Comme son nom l'indique, la récupération à un moment précis vous aide à récupérer l'état précédent d'une instance à un moment spécifique. Par exemple, en cas de perte de données due à une erreur, vous pouvez restaurer une base de données à l'état qui précède l'occurrence de l'erreur.
La récupération PITR est un processus en deux étapes qui repose sur les journaux binaires :
- Vous restaurez la totalité d'une sauvegarde physique ou logique pour rétablir l'état du serveur au moment de la sauvegarde.
- Vous appliquez les journaux binaires pour rejouer les modifications ayant eu lieu entre le moment de la sauvegarde et l'instant souhaité.
Les journaux binaires contiennent toutes les modifications apportées à l'instance de base de données, telles que des opérations de création de table, d'insertion/mise à jour/suppression de ligne, etc. Par exemple, supposons que vos sauvegardes quotidiennes s'exécutent à 06:00 et que vous souhaitiez pouvoir récupérer votre instance à tout moment jusqu'à 10:15. Pour récupérer l'état à 10:15, vous devez d'abord restaurer la sauvegarde complète réalisée à 06:00, puis rejouer les événements du journal binaire de 06:00 à 10:15. Le serveur pourra ainsi atteindre l'état souhaité au moment souhaité.
Les journaux binaires sont requis pour la réplication et la récupération à un moment précis. Ils sont aussi essentiels que les données sous-jacentes. Les journaux binaires doivent être sauvegardés en temps réel pour pouvoir être efficaces dans la planification de votre récupération. Vous pouvez les télécharger à l'aide de la commande mysqlbinlog.
Exemple :
mysqlbinlog --host=<hostname> --port=<port> --user=<user> --password=<password> --read-from-remote-server --raw --stop-never <binlog_filename> |
<binlog_filename> sera le premier fichier à télécharger, et mysqlbinlog passera ensuite automatiquement aux fichiers suivants. Ces journaux binaires sont écrits dans le répertoire actuel du serveur qui exécute la commande mysqlbinlog. Vous pouvez modifier le nom et l'emplacement des fichiers à l'aide de l'option --result-file. Vous pouvez également utiliser l'option --stop-never pour permettre au binlog de mysqlbinlog de rester connecté au serveur et de télécharger les nouvelles modifications à mesure qu'elles sont écrites.
Pour en savoir plus sur la connexion à un serveur distant et sur le téléchargement des journaux binaires au fur et à mesure de leur écriture, consultez le manuel de mysqlbinlog.
Sauvegarde et restauration dans Cloud SQL pour MySQL
En tant que service Google Cloud de base de données géré pour MySQL, Cloud SQL propose des sauvegardes automatisées et la récupération à un moment précis (PITR) pour la protection des données. Celles-ci sont activées par défaut et requises pour activer la haute disponibilité sur une instance Cloud SQL pour MySQL.
Toute sauvegarde Cloud SQL est une sauvegarde de type physique, car il s'agit d'instantanés capturés sur un disque persistant. Cloud SQL offre la flexibilité nécessaire pour effectuer des sauvegardes automatiques, mais vous pouvez aussi les exécuter à la demande à tout moment. Vous pouvez toujours effectuer une sauvegarde logique en utilisant les outils de sauvegarde logique standards de MySQL, tels que mysqldump, mydumper, mysqlpump, etc. sans que cela n'interfère avec vos sauvegardes gérées.
Examinons le fonctionnement des sauvegardes Cloud SQL.
Comprendre les instantanés Cloud SQL
Cloud SQL utilise un disque persistant pour le stockage, et chaque instance Cloud SQL est associée à un disque de données persistant pour stocker les fichiers et répertoires de base de données.
Cloud SQL utilise des instantanés de disque persistant pour les sauvegardes. Ces instantanés font référence à l'état du disque de données à un moment précis. Le premier instantané d'un disque persistant est un instantané complet, qui contient toutes les données du disque persistant. Les instantanés suivants sont incrémentiels et ne contiennent que les données nouvelles ou modifiées depuis l'instantané précédent. Vous pouvez considérer ces instantanés comme des copies physiques des disques de données persistants, gérées dans le cloud. Ils constituent la base de toutes les fonctionnalités de sauvegarde et de restauration de Cloud SQL, y compris la récupération à un moment précis.
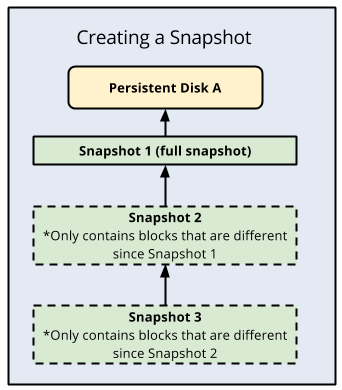
Sauvegardes Cloud SQL
Cloud SQL effectue deux types de sauvegardes gérées : les sauvegardes automatiques et les sauvegardes à la demande. Ces deux types sont stockés par défaut dans l'emplacement multirégional le plus proche de l'instance. Par exemple, si votre instance Cloud SQL se trouve dans la région us-central1, vos sauvegardes sont stockées par défaut dans l'emplacement multirégional des États-Unis. Cependant, un emplacement par défaut comme australia-southeast1 ne se trouve pas dans un emplacement multirégional, et sera placé dans l'emplacement multirégional le plus proche, à savoir asia. Vous pouvez également choisir un emplacement personnalisé pour vos sauvegardes.
Sauvegardes automatiques
Les sauvegardes automatiques sont effectuées quotidiennement, dans un intervalle de sauvegarde de quatre heures de votre choix. La sauvegarde commence pendant cet intervalle et peut se poursuivre au-delà, jusqu'à ce qu'elle se termine. Vous pouvez configurer le nombre de sauvegardes automatiques à conserver (de 1 à 365). La règle de conservation par défaut consiste à conserver les sept dernières sauvegardes.
Sauvegardes à la demande
Vous pouvez également créer à tout moment des sauvegardes à la demande. Cela est utile si vous avez besoin d'une sauvegarde et que vous ne souhaitez pas attendre l'intervalle de sauvegarde. De plus, contrairement aux sauvegardes automatiques, les sauvegardes à la demande ne sont pas automatiquement supprimées. Elles persistent jusqu'à ce que vous les supprimiez ou que leur instance soit supprimée.
Restaurer une sauvegarde Cloud SQL
Vous pouvez restaurer une sauvegarde sur l'instance où elle a été effectuée ou sur une autre instance du même projet. Notez que l'instance cible ne doit pas être une instance répliquée avec accès en lecture ni comporter une ou plusieurs instances répliquées avec accès en lecture au moment de la restauration de la sauvegarde. En effet, ces instances sont des copies d'une instance principale, ce qui crée donc un risque de désynchronisation des instances répliquées avec l'instance principale. Vous pourrez toujours ajouter ultérieurement des instances dupliquées avec accès en lecture.
La restauration de la sauvegarde crée un nouveau disque persistant à partir de l'instantané de sauvegarde et associe ce disque à l'instance. La base de données commence à utiliser le nouveau disque et effectue le processus standard de récupération après plantage avant de se rétablir en ligne comme base de données MySQL entièrement fonctionnelle, tout juste restaurée à partir de l'instantané.
Effectuer une restauration sur la même instance
Lorsque vous effectuez une restauration à partir d'une sauvegarde sur la même instance, les données de cette instance sont rétablies à l'état existant au moment de la sauvegarde.
Effectuer une restauration sur une autre instance
Lorsque vous effectuez une restauration à partir d'une sauvegarde sur une autre instance, les données de l'instance cible sont mises à jour selon l'état de l'instance source au moment de la sauvegarde.
Important : La restauration d'une sauvegarde écrase toutes les données actuelles de l'instance cible, y compris les précédents journaux de récupération à un moment précis. Les données écrasées ne peuvent pas être récupérées.
Récupération à un moment précis (PITR)
Dans Cloud SQL, la récupération PITR crée toujours une instance qui hérite des paramètres de l'instance source, de la même manière qu'une opération de clonage d'instance. Cette fonctionnalité nécessite d'activer à la fois les sauvegardes automatiques et la récupération à un moment précis (journaux binaires) sur l'instance source. La règle de conservation par défaut des journaux binaires est de sept jours, et vous pouvez configurer la durée de conservation sur une valeur allant de un à sept jours.
La récupération PITR est obtenue en créant une nouvelle instance à partir de la sauvegarde de l'instance d'origine, puis en rejouant les journaux binaires stockés sur le disque de données de l'instance d'origine jusqu'au point de restauration souhaité.
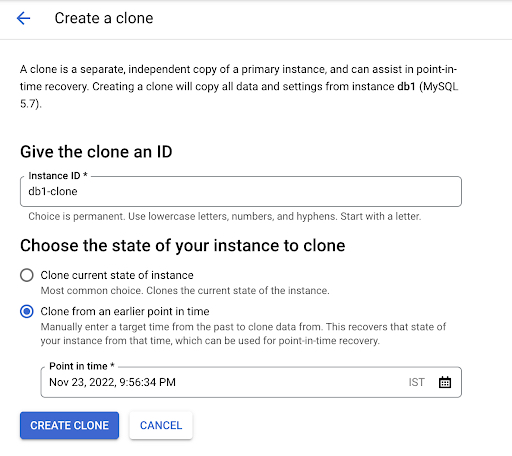
Lors de la récupération PITR dans Cloud SQL, les clients peuvent choisir de cloner soit l'état actuel de l'instance, soit l'état à un code temporel antérieur.
L'interface utilisateur permettant d'effectuer la récupération PITR se présente comme suit :
Produits et services associés
Google Cloud propose une base de données MySQL gérée conçue pour répondre aux besoins de votre entreprise, de la suppression de votre centre de données sur site à l'exécution d'applications SaaS, en passant par la migration de systèmes d'entreprise de base.
Passez à l'étape suivante
Profitez de 300 $ de crédits gratuits et de plus de 20 produits Always Free pour commencer à créer des applications sur Google Cloud.
Vous avez besoin d'aide pour démarrer ?
Contacter le service commercialFaites appel à un partenaire de confiance
Trouvez un partenairePoursuivez vos recherches
Voir tous les produits











