Copia de seguridad y restauración de MySQL
Cuando sucede un imprevisto, tu empresa puede sufrir daños. Los fallos de hardware, la corrupción de las bases de datos, los errores de usuario e incluso los ataques maliciosos pueden suponer un riesgo de pérdida de datos. Las copias de seguridad de las bases de datos te ayudan a recuperar tu negocio y a ponerlo en marcha, aunque se produzca algún problema. Además, cuando todo va bien, las copias de seguridad de las bases de datos te ayudarán a cumplir tus requisitos de auditoría y cumplimiento, ya que te permiten restaurar tu base de datos en un punto anterior.
MySQL admite varias opciones para crear una copia de seguridad de las bases de datos, cada una con distintos puntos fuertes. Puedes elegir la combinación de métodos que mejor se adapte a tus necesidades.
Backup.Types
Hay dos formas principales de crear una copia de seguridad de una base de datos MySQL: física y lógica, La copia de seguridad física copia los archivos de datos reales y la copia de seguridad lógica genera instrucciones como CREATE TABLE e INSERT que pueden recrear los datos.
Copia de seguridad física
Las copias de seguridad físicas contienen las copias sin procesar de todos los archivos y directorios que hay en el disco. Este tipo de copia de seguridad es adecuada para grandes bases de datos porque copiar los archivos sin procesar es mucho más rápido en comparación con las copias de seguridad lógicas.
Ventajas:
- Las copias de seguridad físicas son sencillas y eficientes; No necesitan mucha memoria ni muchos ciclos de CPU para ejecutarse
- Las copias de seguridad físicas no requieren trabajo adicional para generar los archivos sin procesar. Solo tienes que copiar los archivos y directorios sin procesar en la ubicación de copia de seguridad
- Las copias de seguridad físicas son más rápidas de restaurar que las copias de seguridad lógicas porque MySQL no tiene que volver a crear los objetos de base de datos ni importar los datos
Inconvenientes:
- Las copias de seguridad físicas suelen ocupar mucho más espacio que las lógicas porque contienen registros de transacciones, deshacen registros, etc., además de los espacios de tabla InnoDB (que se comparten y por archivos table.ibd y por lo general tienen espacio fragmentado)
- Las copias de seguridad físicas no siempre son portátiles en distintas plataformas, sistemas operativos y versiones de MySQL
- Dado que las copias de seguridad físicas copian los archivos sin procesar, si tienen algún daño subyacente, también se copiarán en los archivos de copia de seguridad.
Algunas herramientas habituales de copia de seguridad física del ecosistema de MySQL
Copia de seguridad lógica
Una copia de seguridad lógica contiene los datos de la base de datos en un formato que MySQL puede interpretar como SQL o como texto delimitado. Representa una base de datos como una secuencia de declaraciones SQL que se pueden ejecutar para recrear objetos de base de datos e importar datos. Este tipo de copia de seguridad es adecuada para bases de datos pequeñas porque las copias de seguridad lógicas pueden tardar considerablemente más tiempo en restaurarse que la restauración de una copia de seguridad física. Este tipo de copia de seguridad también resulta útil al migrar de servicios de bases de datos gestionados a la nube o desde ellos.
Ventajas:
- Las copias de seguridad lógicas son muy flexibles. Ofrecen una gran granularidad de operaciones de copia de seguridad y restauración a nivel de servidor (todas las bases de datos), a nivel de base de datos (todas las tablas en una base de datos determinada), a nivel de tabla o incluso a nivel de fila (filas en una tabla que coinciden con la condición WHERE especificada).
- Las copias de seguridad lógicas son más fáciles de restaurar: solo tienes que canalizar el archivo de copia de seguridad en el cliente MySQL y usar la declaración LOAD DATA o el comando mysqlimport para cargar los archivos delimitados por texto.
- Las copias de seguridad lógicas se pueden ejecutar de forma remota desde otra máquina, lo que permite crear copias de seguridad de las bases de datos y restaurarlas en una red. Esto resulta muy útil para bases de datos en la nube como Google Cloud SQL, Amazon RDS y Microsoft Azure en las que los usuarios no tienen acceso directo a la máquina virtual.
- Las copias de seguridad lógicas ayudan a evitar que se dañen los datos. Las copias de seguridad físicas pueden estar dañadas, y pueden pasar desapercibidas hasta la verificación. Las copias de seguridad lógicas suelen ser archivos de texto, por lo que es más fácil revisarlos con un editor de texto y detectar cualquier daño. Las copias de seguridad lógicas rara vez están dañadas.
- A diferencia de las copias de seguridad físicas, las copias de seguridad lógicas son muy portátiles en todas las plataformas, sistemas operativos y versiones de MySQL.
- Las copias de seguridad lógicas son muy comprimibles.
Inconvenientes:
- Las copias de seguridad lógicas son más lentas de crear, ya que se debe consultar el servidor MySQL para obtener el esquema y las filas y, a continuación, convertirlas a un formato lógico.
- Las copias de seguridad lógicas también son más lentas de restaurar, ya que MySQL necesita ejecutar declaraciones SQL para crear la tabla, importar las filas y reconstruir los índices
- En comparación con las copias de seguridad físicas, las lógicas requieren más recursos del servidor (CPU, RAM, E/S de disco) para las operaciones de copia de seguridad y restauración
Algunas herramientas habituales de copia de seguridad lógica
Recuperación a un momento dado (PITR)
Como sugiere el nombre, la recuperación a un momento dado te ayuda a recuperar una instancia a un momento dado. Por ejemplo, si un error provoca una pérdida de datos, puedes recuperar el estado de una base de datos antes de que se produjera el error.
PITR es un proceso de dos pasos que se basa en los registros binarios:
- Restaura una copia de seguridad física o lógica para que el servidor vuelva al estado que tenía cuando se hizo la copia de seguridad
- Aplica los registros binarios para volver a reproducir los cambios entre el momento de la copia de seguridad y el momento deseado
Los registros binarios contienen los cambios que se hayan hecho en la instancia de la base de datos, como crear una tabla, insertar, actualizar o eliminar una fila, entre otros. Por ejemplo, supongamos que tus copias de seguridad diarias se ejecutan a las 6:00 de la mañana y quieres poder recuperar tu instancia en cualquier momento hasta las 10:15. Para recuperar tu estado a las 10:15, primero tienes que restaurar la copia de seguridad completa desde las 6:00 y, a continuación, volver a reproducir los eventos de registro binario desde las 6:00 hasta las 10:15. Esto hará que el servidor tenga el estado que quieras en el momento deseado.
Se necesitan registros binarios para la replicación y el PITR; son tan importantes como los datos subyacentes. Para que los registros binarios sean eficaces en la planificación de la recuperación, debes crear una copia de seguridad de ellos en tiempo real. Además, puedes descargarlos con el comando mysqlbinlog.
Por ejemplo:
mysqlbinlog --host=<nombre de host> --port=<puerto> --user=<usuario> --password=<contraseña> --read-from-remote-server --raw --stop-never <binlog_filename> |
El archivo <binlog_filename> será el primero que se descargará y, después, mysqlbinlog cambiará automáticamente a los siguientes archivos. Esos registros binarios se escriben en el directorio actual del servidor que ejecuta el comando mysqlbinlog. Puedes cambiar el nombre y la ubicación del archivo con la opción --result-file. También puedes utilizar la opción --stop-never para permitir que el registro binario de mysqlbinlog esté conectado al servidor y descargue nuevos cambios a medida que se escriben.
Puedes obtener más información en el manual de mysqlbinlog sobre cómo conectarse a un servidor remoto y descargar los registros binarios tal como están escritos.
Crear copias de seguridad y restaurar en Cloud SQL para MySQL
Como es el servicio gestionado de bases de datos de Google Cloud para MySQL, Cloud SQL ofrece copias de seguridad automatizadas y sistemas de recuperación a un momento dado (PITR) para proteger los datos. Están habilitadas de forma predeterminada y son necesarias para habilitar la alta disponibilidad en una instancia de Cloud SQL para MySQL.
Las copias de seguridad de Cloud SQL son un tipo de copia de seguridad física, ya que son capturas que se realizan en Persistent Disk (PD). Cloud SQL ofrece la flexibilidad necesaria para que las copias de seguridad se realicen automáticamente. También puedes hacerlas bajo demanda en cualquier momento. Puedes seguir haciendo una copia de seguridad lógica usando las herramientas estándar de copia de seguridad lógica de MySQL, como mysqldump, mydumper, mysqlpump y otros, sin interferir con tus copias de seguridad gestionadas.
Veamos cómo funcionan las copias de seguridad de Cloud SQL.
Información sobre las capturas de Cloud SQL
Cloud SQL usa Persistent Disk (PD) para el almacenamiento, y cada instancia de Cloud SQL tiene un disco de datos persistente conectado para almacenar los archivos y directorios de la base de datos.
Cloud SQL utiliza capturas de disco persistente para crear copias de seguridad, que hacen referencia al estado del disco de datos en un momento dado. La primera captura de un disco persistente es una captura completa que contiene todos los datos del disco persistente. Las siguientes capturas son incrementales y solo contienen datos nuevos o modificados desde la captura anterior. Puedes considerar estas capturas como copias físicas gestionadas por la nube de discos de datos persistentes, y son la base de todas las funciones de copia de seguridad y restauración de Cloud SQL, como PITR.
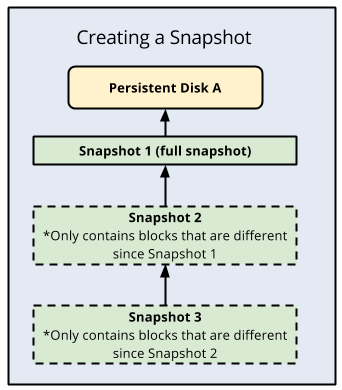
Copias de seguridad de Cloud SQL
Cloud SQL realiza dos tipos de copias de seguridad gestionadas: automáticas y bajo demanda. Ambos tipos están almacenados de forma predeterminada en la ubicación multirregional más cercana a la instancia. Por ejemplo, si tu instancia de Cloud SQL está en us-central1, las copias de seguridad se almacenan en la multirregión de EE. UU. de forma predeterminada. Sin embargo, una ubicación predeterminada como australia-southeast1 se encuentra fuera de una multirregión y se colocará en la multirregión más cercana, que es asia. También puedes elegir una ubicación personalizada para tus copias de seguridad.
Copias de seguridad automáticas
Las copias de seguridad automatizadas se realizan a diario durante el periodo de 4 horas que elijas. La copia de seguridad se inicia durante el periodo de la copia de seguridad y puede continuar fuera de este hasta que finalice. Puedes configurar cuántas copias de seguridad automatizadas se conservarán de 1 a 365. La política de retención predeterminada consiste en conservar las siete copias de seguridad más recientes.
Copias de seguridad bajo demanda
También puedes crear copias de seguridad bajo demanda en cualquier momento. Este método es útil si necesitas una copia de seguridad y no quieres esperar a que finalice la ventana. Además, a diferencia de las copias de seguridad automatizadas, las copias de seguridad bajo demanda no se eliminan automáticamente. Permanecen hasta que las elimines o hasta que se elimine su instancia.
Restaurar una copia de seguridad de Cloud SQL
Puedes restaurar una copia de seguridad en la misma instancia donde se hizo o en otra instancia del mismo proyecto. Ten en cuenta que la instancia de destino no debe ser una réplica de lectura en sí ni debería tener réplicas de lectura en el momento de restaurar la copia de seguridad, ya que las réplicas de lectura son copias de una instancia principal y crea el riesgo de que las réplicas se sincronicen con la principal. Siempre puedes añadir réplicas de lectura después.
Al restaurar la copia de seguridad se crea un nuevo disco persistente a partir de esa captura y se adjunta a la instancia. La base de datos empieza a usar el nuevo disco y realiza el proceso estándar de recuperación tras fallos de MySQL antes de conectarse a Internet como base de datos MySQL completa como una restauración de la captura.
Restaurar en la misma instancia
Al restaurar desde una copia de seguridad en la misma instancia, devuelves los datos sobre esa instancia al estado que tenía cuando se tomó para la copia de seguridad.
Restaurar en otra instancia
Cuando se restaura desde una copia de seguridad en una instancia diferente, se actualizan los datos en la instancia de destino al estado de la instancia de origen cuando se realizó la copia de seguridad.
Importante: Al restaurar una copia de seguridad, se sobrescriben todos los datos que hay en la instancia de destino, incluidos los registros de recuperación a un momento dado. Los datos sobrescritos no se pueden recuperar.
Recuperación a un momento dado de Cloud SQL (PITR)
En Cloud SQL, PITR siempre crea una nueva instancia que hereda la configuración de la instancia de origen, similar a la operación de clonar instancia. Esta función requiere que se habiliten las copias de seguridad automáticas y la recuperación a un momento dado (registros binarios) en la instancia de origen. La política de retención predeterminada de los registros binarios es de 7 días, aunque puedes configurar el periodo de retención para que esté comprendido entre 1 y 7 días.
Para conseguir PITR, se crea una nueva instancia a partir de la copia de seguridad de la instancia original y se vuelven a reproducir los registros binarios almacenados en el disco de datos de la instancia original hasta el punto especificado.
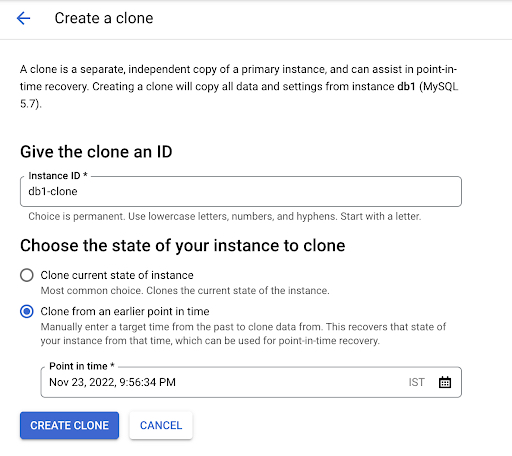
Al ejecutar PITR en Cloud SQL, los clientes pueden clonar el estado actual de la instancia o elegir una marca de tiempo en el pasado.
La UI para realizar el PITR se parece al siguiente.
Productos y servicios relacionados
Google Cloud ofrece una base de datos MySQL gestionada que se adapta a las necesidades de tu negocio, desde la retirada de tu centro de datos on‑premise, la ejecución de aplicaciones de software como servicio o la migración de sistemas empresariales fundamentales.
Ve un paso más allá
Empieza a crear en Google Cloud con 300 USD en crédito gratis y más de 20 productos Always Free.
¿Necesitas ayuda para empezar?
Contactar con VentasTrabaja con un partner de confianza
Buscar un partnerSigue explorando
Ver todos los productos











