MySQL – Sichern und Wiederherstellen
Unvorhergesehene Ereignisse können für Ihr Unternehmen darunter leiden. Hardwarefehler, Datenbankbeschädigungen, Nutzerfehler und sogar schädliche Angriffe können das Risiko eines Datenverlusts verursachen. Mit Datenbanksicherungen können Sie Ihr Unternehmen wiederherstellen und es am Laufen halten, selbst wenn es ein Problem gibt. Und wenn alles in Ordnung ist, können Sie mit Datenbanksicherungen Compliance- und Audit-Anforderungen erfüllen, da Sie Ihre Datenbank zu einem bestimmten Zeitpunkt in der Vergangenheit wiederherstellen können.
MySQL unterstützt mehrere Optionen zum Sichern Ihrer Datenbanken, jeweils mit unterschiedlichen Stärken. Sie können eine beliebige Kombination von Methoden auswählen, die Ihren Anforderungen am besten entspricht.
Sicherungstypen
Es gibt zwei Möglichkeiten, eine MySQL-Datenbank zu sichern: physisch und logisch. Die physische Sicherung kopiert die tatsächlichen Datendateien und die logische Sicherung generiert Anweisungen wie CREATE TABLE und INSERT, mit denen die Daten neu erstellt werden können.
Physische Sicherung
Eine physische Sicherung enthält die Rohkopien aller Dateien und Verzeichnisse, wie sie auf dem Laufwerk vorhanden sind. Diese Art der Sicherung eignet sich für große Datenbanken, da das Kopieren der Rohdateien viel schneller ist als eine logische Sicherung zu erstellen.
Vorteile:
- Physische Sicherungen sind unkompliziert und effizient. Sie benötigen nicht viel Arbeitsspeicher oder viele CPU-Zyklen zum Ausführen
- Physische Sicherungen erfordern keinen zusätzlichen Aufwand für das Generieren der Rohdateien. Kopieren Sie einfach die RAW-Dateien und -Verzeichnisse an den Speicherort
- Physische Sicherungen lassen sich schneller wiederherstellen als logische Sicherungen, da MySQL keine Datenbankobjekte neu erstellen und die Daten importieren muss.
Nachteile:
- Physische Sicherungen belegen oft viel mehr Speicherplatz als logische Sicherungen, da sie Transaktionslogs, rückgängig-Logs und andere enthalten – zusätzlich zu InnoDB-Tablespaces (die freigegeben sind und pro table.ibd-Dateien sind und meist einen fragmentierten Bereich haben).
- Physische Sicherungen sind nicht immer übertragbar über verschiedene Plattformen, Betriebssysteme und MySQL-Versionen hinweg.
- Da bei physischen Sicherungen die Rohdateien kopiert werden, gilt: wenn bei ihnen eine Beschädigung vorliegt, wird sie ebenfalls in die Sicherungsdateien übernommen.
Einige gängige Tools für physische Sicherungen für das gesamte MySQL-System
Logische Sicherung
Eine logische Sicherung enthält die Daten in der Datenbank in einer Form, die MySQL entweder als SQL oder als abgegrenzter Text interpretieren kann. Sie ist eine Darstellung Ihrer Datenbank als Sequenz von SQL-Anweisungen, die ausgeführt werden können, um Datenbankobjekte neu zu erstellen und Daten zu importieren. Diese Art der Sicherung eignet sich für kleine Datenbanken, da die Wiederherstellung logischer Sicherungen wesentlich länger dauern kann als die Wiederherstellung einer physischen Sicherung. Dieser Sicherungstyp ist auch nützlich, wenn Sie zu oder von verwalteten Datenbankdiensten in der Cloud migrieren.
Vorteile:
- Logische Sicherungen sind sehr flexibel. Sie bieten einen hohen Detaillierungsgrad bei Sicherungs- und Wiederherstellungsvorgängen auf Serverebene (alle Datenbanken), Datenbankebene (alle Tabellen in einer bestimmten Datenbank), Tabellenebene oder sogar auf Zeilenebene (Tabellen-Zeilen, die mit der angegebenen WHERE-Bedingung übereinstimmen).
- Logische Sicherungen lassen sich einfacher wiederherstellen. Senden Sie einfach die Sicherungsdatei an den mysql -Client und verwenden Sie die Anweisung LOAD DATA oder den Befehl „mysqlimport“, um die mit Trennzeichen versehenen Textdateien zu laden.
- Logische Sicherungen können remote von einem anderen Computer aus ausgeführt werden, sodass Sie Ihre Datenbank überall in einem Netzwerk sichern und wiederherstellen können. Dies ist sehr nützlich für Cloud-Datenbanken wie Google Cloud SQL, Amazon RDS und Microsoft Azure, in denen Nutzer keinen direkten Zugriff auf die virtuelle Maschine haben.
- Logische Sicherungen tragen zur Vermeidung von Beschädigung von Daten bei. Physische Sicherungen können beschädigt sein, was bis zur Verifizierung unbemerkt bleiben kann. Da logische Sicherungen normalerweise Textdateien sind, ist es einfacher, sie mit einem Texteditor zu prüfen und so mögliche Beschädigungen zu erkennen. Logische Sicherungen werden selten beschädigt.
- Im Gegensatz zu physischen Sicherungen sind logische Sicherungen über mehrere Plattformen, Betriebssysteme und MySQL-Versionen hinweg sehr portierbar.
- Logische Sicherungen sind hoch komprimierbar.
Nachteile:
- Logische Sicherungen werden langsamer erstellt, da Sie den MySQL-Server abfragen müssen, um das Schema und die Zeilen zu erhalten, und diese dann in ein logisches Format konvertieren müssen.
- Logische Sicherungen lassen sich auch langsamer wiederherstellen, da MySQL SQL-Anweisungen ausführen muss, um die Tabelle zu erstellen, die Zeilen zu importieren und die Indexe neu zu erstellen.
- Im Vergleich zu physischen Sicherungen benötigen logische Sicherungen mehr Serverressourcen (CPU, RAM und Laufwerks-E/A) für Sicherungs- und Wiederherstellungsvorgänge.
Einige gebräuchliche logische Sicherungstools
Wiederherstellung zu einem bestimmten Zeitpunkt
Wie der Name schon sagt, können Sie mit der Wiederherstellung zu einem bestimmten Zeitpunkt eine Instanz an einem bestimmten Zeitpunkt wiederherstellen. Wenn beispielsweise ein Fehler zu einem Datenverlust geführt hat, haben Sie die Möglichkeit, genau den Zustand der Datenbank wiederherzustellen, den sie zum Zeitpunkt vor Auftreten des Fehlers hatte.
PITR ist ein zweischrittiger Prozess, der auf binären Logs basiert:
- Stellen Sie eine vollständige physische oder logische Sicherung wieder her, um den Server auf den gleichen Stand wie zum Zeitpunkt der Sicherung zu bringen.
- Binäre Logs anwenden, um die Änderungen zwischen dem Zeitpunkt der Sicherung und dem gewünschten Zeitpunkt zu wiederholen
Binäre Logs enthalten alle Änderungen, die an der Datenbankinstanz vorgenommen wurden, z. B. Tabelle erstellen, Einfügen/Aktualisieren/Löschen von Zeilen und andere. Angenommen, Ihre täglichen Sicherungen werden um 6:00 Uhr ausgeführt und Sie möchten Ihre Instanz auf einen beliebigen Zeitpunkt vor 10:15 Uhr wiederherstellen. Wenn Sie Ihren Status von um 10:15 Uhr wiederherstellen möchten, müssen Sie zuerst die vollständige Sicherung von 6:00 Uhr wiederherstellen. Anschließend werden die binären Log-Ereignisse von 6:00 Uhr bis 10:15 Uhr wiedergegeben. Dadurch wird der Server in den gewünschten Status des gewünschten Zeitpunkts gebracht.
Binäre Logs sind für die Replikation und PITR erforderlich. Sie sind sie genauso wichtig wie die zugrunde liegenden Daten. Binäre Logs müssen in Echtzeit gesichert werden, damit sie bei Ihrer Wiederherstellungsplanung effektiv sind. Sie können sie mit dem Befehl „mysqlbinlog“ herunterladen.
Beispiel:
mysqlbinlog --host=<hostname> --port=<port> --user=<user> --password=<password> --read-from-remote-server --raw --stop-never <binlog_filename> |
<binlog_filename> wird die erste Datei sein, die heruntergeladen wird, und MySQLbinlog wechselt anschließend automatisch zur nächsten Datei(en). Diese binären Logs werden in das aktuelle Verzeichnis des Servers geschrieben, auf dem der Befehl „mysqlbinlog“ ausgeführt wird. Sie können den Dateinamen und den Speicherort mit der Option --result-file ändern. Sie können auch die Option --stop-never verwenden, damit mysqlbinlog binlog mit dem Server verbunden bleibt und damit neue Änderungen während sie geschrieben werden direkt heruntergeladen werden.
Weitere Informationen zum Herstellen einer Verbindung zu einem Remoteserver und zum Herunterladen der binären Logs während sie geschrieben werden, erhalten Sie im mysqlbinlog-Handbuch.
Sichern und Wiederherstellen in Cloud SQL for MySQL
Als verwalteter Google Cloud-Datenbankdienst für MySQL bietet Cloud SQL automatisierte Sicherungen und Wiederherstellung zu einem bestimmten Zeitpunkt (Point-in-Time-Recovery, PITR) für den Datenschutz. Diese sind standardmäßig aktiviert und erforderlich, um die Hochverfügbarkeit auf einer Cloud SQL for MySQL-Instanz zu aktivieren.
Jede Cloud SQL-Sicherung ist eine Art physische Sicherung, da es sich um Snapshots handelt, die auf einem nichtflüchtigen Speicher erstellt wurden. Cloud SQL bietet die Flexibilität, Sicherungen automatisch durchzuführen. Sie können sie aber auch jederzeit bei Bedarf ausführen. Sie können trotzdem eine logische Sicherung mit den Standard-MySQL-Tools für logische Sicherung, wie z. B. MySQLdump, mydumper, mysqlpump, erstellen, ohne die verwalteten Sicherungen zu beeinträchtigen.
Sehen wir uns nun an, wie die Sicherungen von Cloud SQL funktionieren.
Cloud SQL-Snapshots verstehen
Cloud SQL verwendet Persistent Disk (PD) zum Speichern und jede Cloud SQL-Instanz hat ein nichtflüchtiges Datenlaufwerk angehängt zum Speichern der Datenbankdateien und -verzeichnisse.
Cloud SQL verwendet PD-Snapshots für Sicherungen und diese Snapshots beziehen sich auf den Status des Datenlaufwerks zu einem bestimmten Zeitpunkt. Der erste Snapshot eines nichtflüchtigen Speichers ist ein vollständiger Snapshot, der alle Daten des nichtflüchtigen Speichers enthält. Die nachfolgenden Snapshots sind inkrementell und enthalten nur sämtliche neuen Daten oder geänderte Daten seit dem vorherigen Snapshot. Stellen Sie sich diese Snapshots als in der Cloud verwaltete physische Kopien nichtflüchtiger Datenlaufwerke vor. Sie bilden die Grundlage aller Sicherungs- und Wiederherstellungsfunktionen von Cloud SQL, einschließlich der PITR.
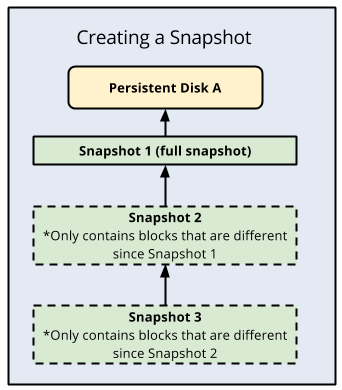
Cloud SQL-Sicherungen
Cloud SQL führt zwei Arten von verwalteten Sicherungen durch: automatisierte und On-Demand-Sicherungen. Beide Arten werden standardmäßig am nächstgelegenen multiregionalen Standort der Instanz gespeichert. Befindet sich Ihre Cloud SQL-Instanz beispielsweise in us-central1, werden Ihre Sicherungen standardmäßig am multiregionalen Standort "US" gespeichert. Standardspeicherorte wie beispielsweise australia-southeast1 liegen jedoch außerhalb eines multiregionalen Standorts und werden in der nächstgelegenen Multi-Region platziert, nämlich asia. Sie können auch einen benutzerdefinierten Speicherort für Ihre Sicherungen auswählen.
Automatische Sicherungen
Automatische Sicherungen werden täglich innerhalb eines vierstündigen Zeitraums durchgeführt, das Sie selbst festlegen. Die Sicherung beginnt innerhalb des Sicherungszeitraums und läuft weiter, bis sie abgeschlossen ist, möglicherweise dauert dies über den Sicherungszeitraum hinaus. Sie können konfigurieren, wie viele automatisierte Sicherungen beibehalten werden sollen, von 1 bis 365. Die standardmäßige Aufbewahrungsrichtlinie sieht vor, dass die sieben letzten Sicherungen aufbewahrt werden.
On-Demand-Sicherungen
Sie können auch jederzeit On-Demand-Sicherungen erstellen. Dies ist nützlich, wenn Sie eine Sicherung benötigen und nicht auf das Zeitfenster für die Sicherung warten möchten. Außerdem werden On-Demand-Sicherungen im Gegensatz zu automatischen Sicherungen nicht automatisch gelöscht. Sie bleiben erhalten, bis sie oder ihre Instanz gelöscht werden.
Cloud SQL-Sicherung wiederherstellen
Sie können eine Sicherung in derselben Instanz wiederherstellen, in der sie erstellt wurde, oder in einer anderen Instanz im selben Projekt. Beachten Sie, dass die Zielinstanz kein Lesereplikat sein sollte und auch keine Lese-Replikat(e) zur Zeit der Wiederherstellung der Sicherung haben sollte, da Lesereplikate Kopien der primären Instanz sind und so entsteht das Risiko, dass die Replikate nicht mehr mit der primären Instanz synchron sind. Sie können später jederzeit Lesereplikate hinzufügen.
Durch das Wiederherstellen der Sicherung wird aus diesem Sicherungs-Snapshot ein neuer nichtflüchtiger Speicher erstellt und der Instanz angehängt. Die Datenbank verwendet dann das neue Laufwerk und führt den standardmäßigen MySQL-Absturzwiederherstellungsprozess aus, bevor sie als vollwertige MySQL-Datenbank online geht, die frisch aus dem Snapshot wiederhergestellt wurde.
Gleiche Instanz wiederherstellen
Wenn Sie aus einer Sicherung die gesicherte Instanz wiederherstellen, werden die Daten in dieser Instanz in den Status zurückversetzt, den sie zum Zeitpunkt der Sicherung hatten.
Andere Instanz wiederherstellen
Wenn Sie aus einer Sicherung eine andere Instanz wiederherstellen, werden die Daten in der Zielinstanz in den Status versetzt, den die Quellinstanz zum Zeitpunkt der Sicherung hatte.
Wichtig: Durch das Wiederherstellen einer Sicherung werden alle aktuellen Daten auf der Zielinstanz überschrieben, einschließlich früherer Logs für die Wiederherstellung zu einem bestimmten Zeitpunkt. Überschriebene Daten können nicht wiederhergestellt werden.
Cloud SQL-Wiederherstellung zu einem bestimmten Zeitpunkt (Point-In-Time Recovery, PITR)
In Cloud SQL erstellt PITR immer eine neue Instanz, die die Einstellungen der Quellinstanz übernimmt, ähnlich wie beim Instanz-Klon-Vorgang. Für diese Funktion müssen sowohl automatische Sicherungen als auch die Wiederherstellung zu einem bestimmten Zeitpunkt (binäre Logs) für die Quellinstanz aktiviert sein. Die standardmäßige Aufbewahrungsrichtlinie für binäre Logs beträgt 7 Tage. Sie können eine Aufbewahrungsdauer von 1 bis 7 Tagen konfigurieren.
PITR wird erreicht, indem eine neue Instanz aus der Sicherung der ursprünglichen Instanz erstellt wird und die binären Logs, die auf dem Datenlaufwerk der ursprünglichen Instanz gespeichert sind, im Zustand des angegebenen Zeitpunkts wiedergegeben werden.
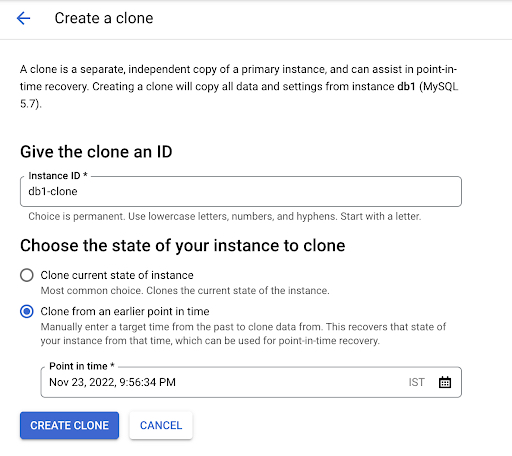
Beim Ausführen von PITR in Cloud SQL können Kunden entweder den aktuellen Status der Instanz klonen oder den Status eines Zeitstempels in der Vergangenheit klonen.
Die Benutzeroberfläche zur Durchführung der PITR sieht so aus.
Ähnliche Produkte und Dienste
Google Cloud bietet eine verwaltete MySQL-Datenbank, die auf Ihre geschäftlichen Anforderungen zugeschnitten ist – von der Stilllegung Ihres lokalen Rechenzentrums über die Ausführung von SaaS-Anwendungen bis hin zur Migration von Kerngeschäftssystemen.
Gleich loslegen
Profitieren Sie von einem Guthaben über 300 $, um Google Cloud und mehr als 20 „Immer kostenlos“ Produkte kennenzulernen.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partner arbeiten
Partner findenMehr ansehen
Alle Produkte ansehen











