Google Cloud Managed Service para Prometheus es la solución multicloud y entre proyectos totalmente gestionada de Google Cloudpara métricas de Prometheus y OpenTelemetry. Te permite monitorizar y recibir alertas a nivel global sobre tus cargas de trabajo con Prometheus y OpenTelemetry, sin tener que gestionar ni usar Prometheus manualmente a gran escala.
Managed Service para Prometheus recoge métricas de exportadores de Prometheus y te permite consultar los datos de forma global mediante PromQL, lo que significa que puedes seguir usando los paneles de control de Grafana, las alertas basadas en PromQL y los flujos de trabajo que ya tengas. Es compatible con entornos híbridos y multinube, puede monitorizar Kubernetes, máquinas virtuales y cargas de trabajo sin servidor en Cloud Run, conserva los datos durante 24 meses y mantiene la portabilidad al seguir siendo compatible con Prometheus upstream. También puedes complementar tu monitorización de Prometheus consultando más de 6500 métricas gratuitas en Cloud Monitoring, incluidas las métricas gratuitas del sistema de GKE, mediante PromQL.
En este documento se ofrece una descripción general del servicio gestionado. En otros documentos se explica cómo configurar y ejecutar el servicio. Para recibir novedades periódicas sobre nuevas funciones y lanzamientos, envía el formulario de registro opcional.
Descubre cómo usa The Home Depot Managed Service para Prometheus para obtener una observabilidad unificada en las 2200 tiendas que ejecutan clústeres de Kubernetes locales:
Descripción general del sistema
Google Cloud Managed Service para Prometheus te ofrece la familiaridad de Prometheus con el respaldo de la infraestructura global, multicloud y entre proyectos de Cloud Monitoring.
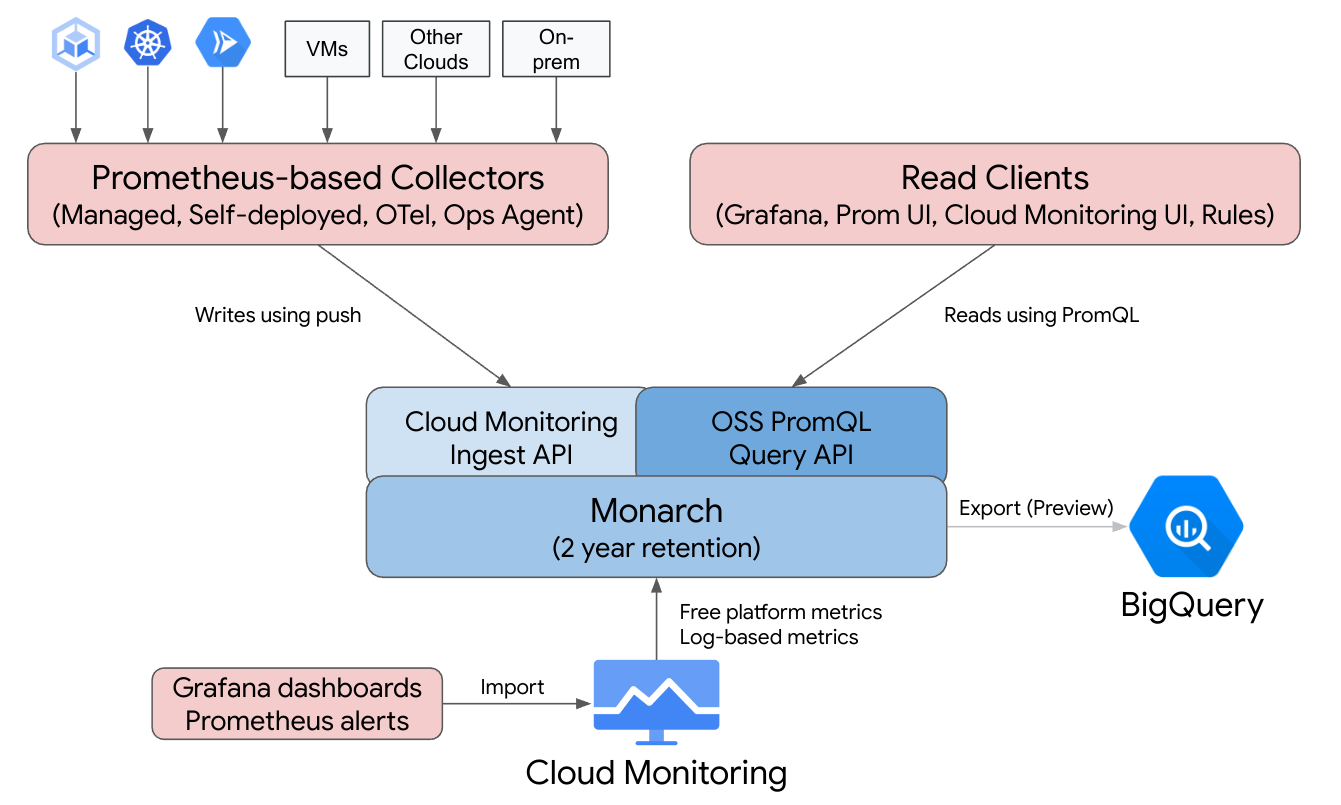
Managed Service para Prometheus se ha creado a partir de Monarch, el mismo almacén de datos escalable a nivel mundial que se usa para la monitorización de Google. Como Managed Service para Prometheus usa el mismo backend y las mismas APIs que Cloud Monitoring, tanto las métricas de Cloud Monitoring como las métricas ingeridas por Managed Service para Prometheus se pueden consultar mediante PromQL en Cloud Monitoring, Grafana o cualquier otra herramienta que pueda leer la API de Prometheus.
En una implementación estándar de Prometheus, la recogida de datos, la evaluación de consultas, la evaluación de reglas y alertas, y el almacenamiento de datos se gestionan en un solo servidor de Prometheus. Managed Service para Prometheus divide las responsabilidades de estas funciones en varios componentes:
- La recogida de datos se gestiona mediante recopiladores gestionados, recopiladores autodesplegados, el recopilador de OpenTelemetry o el agente de operaciones, que rastrean los exportadores locales y reenvían los datos recogidos a Monarch. Estos colectores se pueden usar en cargas de trabajo de Kubernetes, sin servidor y de máquinas virtuales tradicionales, y se pueden ejecutar en cualquier lugar, incluidos otros servicios en la nube y despliegues on-premise.
- Monarch se encarga de evaluar las consultas, que ejecuta consultas y combina resultados en todas las Google Cloud regiones y en hasta 3500 Google Cloud proyectos.
- La evaluación de reglas y alertas se lleva a cabo escribiendo alertas de PromQL en Cloud Monitoring, que se ejecutan completamente en la nube, o bien usando componentes de evaluador de reglas configurados y ejecutados localmente, que ejecutan reglas y alertas en el almacén de datos global de Monarch y reenvían las alertas activadas a Prometheus AlertManager.
- Monarch se encarga del almacenamiento de datos, que almacena todos los datos de Prometheus durante 24 meses sin coste adicional.
Grafana se conecta al almacén de datos global de Monarch en lugar de conectarse a servidores de Prometheus individuales. Si tienes configurados recopiladores de Managed Service para Prometheus en todas tus implementaciones, esta única instancia de Grafana te ofrece una vista unificada de todas tus métricas en todas tus nubes.
Recogida de datos
Puedes usar Managed Service para Prometheus de cuatro formas: con recogida de datos gestionada, con recogida de datos autodesplegada, con OpenTelemetry Collector o con Ops Agent.
Managed Service para Prometheus ofrece un operador para la recogida de datos gestionada en entornos de Kubernetes. Te recomendamos que uses la recogida gestionada, ya que elimina la complejidad de desplegar, escalar, fragmentar, configurar y mantener servidores Prometheus. La recogida gestionada se admite tanto en entornos de Kubernetes de GKE como en entornos de Kubernetes que no sean de GKE.
Con la recogida de datos autodesplegada, gestionas tu instalación de Prometheus como siempre. La única diferencia con Prometheus es que ejecutas el binario de sustitución de Managed Service para Prometheus en lugar del binario de Prometheus.
OpenTelemetry Collector se puede usar para raspar exportadores de Prometheus y enviar datos a Managed Service para Prometheus. OpenTelemetry admite una estrategia de un solo agente para todas las señales, en la que se puede usar un recolector para métricas (incluidas las métricas de Prometheus), registros y trazas en cualquier entorno.
Puedes configurar el agente de operaciones en cualquier instancia de Compute Engine para que raspe y envíe métricas de Prometheus al almacén de datos global. El uso de un agente simplifica enormemente la detección de VMs y elimina la necesidad de instalar, desplegar o configurar Prometheus en entornos de VMs.
Si tienes un servicio de Cloud Run que escribe métricas de Prometheus o métricas de OTLP, puedes usar un sidecar y Managed Service para Prometheus para enviar las métricas a Cloud Monitoring.
- Para recoger métricas de Prometheus de Cloud Run, usa el complemento de Prometheus.
- Para recoger métricas de OTLP de Cloud Run, usa el sidecar de OpenTelemetry.
Puedes ejecutar recopiladores gestionados, autodesplegados y de OpenTelemetry en despliegues locales y en cualquier nube. Los recolectores que se ejecutan fuera de Google Cloud envían datos a Monarch para almacenarlos a largo plazo y hacer consultas globales.
A la hora de elegir entre las opciones de recogida, ten en cuenta lo siguiente:
Colección gestionada:
- Es el método recomendado por Google para todos los entornos de Kubernetes.
- Se ha desplegado mediante la interfaz de usuario de GKE, la CLI de gcloud, la CLI de
kubectlo Terraform. - El operador de Kubernetes se encarga por completo del funcionamiento de Prometheus: generar configuraciones de raspado, escalar la ingestión, acotar las reglas a los datos correctos, etc.
- El raspado de datos y las reglas se configuran mediante recursos personalizados ligeros (CRs).
- Ideal para quienes prefieren una experiencia totalmente gestionada y con menos intervención.
- Migración intuitiva desde las configuraciones de prometheus-operator.
- Admite la mayoría de los casos prácticos de Prometheus.
- Asistencia completa del equipo de Google Cloud Asistencia Técnica.
Recogida con despliegue automático:
- Una sustitución directa del binario de Prometheus upstream.
- Puedes usar el mecanismo de implementación que prefieras, como prometheus-operator o la implementación manual.
- El raspado de datos se configura mediante los métodos que prefieras, como anotaciones u operador de Prometheus.
- El escalado y el particionado funcional se realizan manualmente.
- Ideal para integraciones rápidas en configuraciones más complejas. Puedes reutilizar tus configuraciones y ejecutar Prometheus y Managed Service para Prometheus en paralelo.
- Las reglas y las alertas suelen ejecutarse en servidores de Prometheus individuales, lo que puede ser preferible para las implementaciones perimetrales, ya que la evaluación de reglas local no genera tráfico de red.
- Puede admitir casos prácticos de cola larga que aún no sean compatibles con la colección gestionada, como las agregaciones locales para reducir la cardinalidad.
- Asistencia limitada del servicio técnico de Google Cloud .
El recopilador de OpenTelemetry:
- Un único recolector que puede recoger métricas (incluidas las de Prometheus) de cualquier entorno y enviarlas a cualquier backend compatible. También se puede usar para recoger registros y trazas, y enviarlos a cualquier backend compatible, incluidos Cloud Logging y Cloud Trace.
- Desplegado en cualquier entorno de Kubernetes o de computación, ya sea manualmente o con Terraform. Se puede usar para enviar métricas desde entornos sin estado, como Cloud Run.
- La extracción se configura mediante configuraciones similares a las de Prometheus en el receptor de Prometheus del recopilador.
- Admite patrones de recogida de métricas basados en push.
- Los metadatos se insertan desde cualquier nube mediante procesadores de detección de recursos.
- Las reglas y las alertas se pueden ejecutar mediante una política de alertas de Cloud Monitoring o el evaluador de reglas independiente.
- Es la opción más adecuada para los flujos de trabajo entre señales y las funciones como los ejemplares.
- Asistencia limitada del servicio técnico de Google Cloud .
El agente de operaciones:
- La forma más sencilla de recoger y enviar datos de métricas de Prometheus procedentes de entornos de Compute Engine, incluidas las distribuciones de Linux y Windows.
- Se despliega mediante la CLI de gcloud, la interfaz de Compute Engine o Terraform.
- El raspado se configura mediante configuraciones similares a las de Prometheus en el receptor Prometheus del agente, que se basa en OpenTelemetry.
- Las reglas y las alertas se pueden ejecutar mediante Cloud Monitoring o el evaluador de reglas independiente.
- Se incluye con agentes de registro opcionales y métricas de procesos.
- Asistencia completa del equipo de Google Cloud Asistencia Técnica.
Para empezar, consulta los artículos Empezar a utilizar la recogida gestionada, Empezar a utilizar colecciones desplegadas automáticamente, Empezar a usar el recopilador de OpenTelemetry o Empezar a usar el agente de operaciones.
Si usas el servicio gestionado fuera de Google Kubernetes Engine o Google Cloud, es posible que tengas que hacer alguna configuración adicional. Consulta Ejecutar la recogida gestionada fuera de Google Cloud, Ejecutar la recogida autodesplegada fuera deGoogle Cloud o Añadir procesadores de OpenTelemetry.
Evaluación de consultas
Managed Service para Prometheus admite cualquier interfaz de usuario de consulta que pueda llamar a la API de consulta de Prometheus, incluidas Grafana y la interfaz de usuario de Cloud Monitoring. Los paneles de control de Grafana que ya tengas seguirán funcionando cuando pases de Prometheus local a Managed Service para Prometheus, y podrás seguir usando PromQL en repositorios de software libre populares y en foros de la comunidad.
Puedes usar PromQL para consultar más de 6500 métricas gratuitas en Cloud Monitoring, incluso sin enviar datos a Managed Service for Prometheus. También puedes usar PromQL para consultar métricas de Kubernetes gratuitas, métricas personalizadas y métricas basadas en registros.
Para obtener información sobre cómo configurar Grafana para consultar datos de Managed Service para Prometheus, consulta Consultar con Grafana.
Para obtener información sobre cómo consultar métricas de Cloud Monitoring con PromQL, consulta PromQL en Cloud Monitoring.
Evaluación de reglas y alertas
Managed Service para Prometheus proporciona una canalización de alertas totalmente basada en la nube y un evaluador de reglas independiente. Ambos evalúan las reglas con todos los datos de Monarch a los que se puede acceder en un ámbito de métricas. Al evaluar las reglas en un ámbito de métricas de varios proyectos, no es necesario colocar todos los datos de interés en un único servidor de Prometheus o en un único proyecto de Google Cloud . Además, puedes definir permisos de gestión de identidades y accesos en grupos de proyectos.
Como todas las opciones de evaluación de reglas aceptan el formato estándar de Prometheus rule_files, puedes migrar fácilmente a Managed Service para Prometheus copiando y pegando reglas ya creadas o reglas que se encuentren en repositorios populares de código abierto. Si usas colectores autodesplegados, puedes seguir evaluando las reglas de grabación de forma local en tus colectores. Los resultados de las reglas de registro y de alerta se almacenan en Monarch, al igual que los datos de métricas recogidos directamente. También puedes migrar tus reglas de alertas de Prometheus a políticas de alertas basadas en PromQL en Cloud Monitoring.
Para obtener información sobre la evaluación de alertas con Cloud Monitoring, consulta Alertas de PromQL en Cloud Monitoring.
Para obtener información sobre la evaluación de reglas con la recogida gestionada, consulta Evaluación de reglas y alertas gestionadas.
Para evaluar las reglas con la recogida autodesplegada, el OpenTelemetry Collector y el agente de operaciones, consulta Evaluación de reglas y alertas autodesplegadas.
Para obtener información sobre cómo reducir la cardinalidad mediante reglas de registro en colectores autodesplegados, consulta Controles de costes y atribución.
Almacenamiento de datos
Todos los datos de Managed Service para Prometheus se almacenan durante 24 meses sin coste adicional.
Managed Service for Prometheus admite un intervalo de raspado mínimo de 5 segundos. Los datos se almacenan con la granularidad completa durante una semana. Después, se reduce el muestreo a puntos de 1 minuto durante las 5 semanas siguientes. Por último, se reduce el muestreo a puntos de 10 minutos y se almacenan durante el resto del periodo de conservación.
Managed Service for Prometheus no tiene ningún límite en cuanto al número de series temporales activas o al número total de series temporales.
Para obtener más información, consulta las cuotas y los límites en la documentación de Cloud Monitoring.
Facturación y cuotas
El servicio gestionado de Prometheus es un Google Cloud producto y se aplican cuotas de facturación y de uso.
Facturación
La facturación del servicio se basa principalmente en el número de muestras de métricas ingeridas en el almacenamiento. También se aplica un coste simbólico a las llamadas a la API de lectura. Managed Service para Prometheus no cobra por el almacenamiento ni la conservación de datos de métricas.
- Para consultar los precios actuales, ve a las secciones de Cloud Monitoring de la página Precios de Google Cloud Observability.
- Para estimar tu factura en función del número previsto de series temporales o de las muestras por segundo que esperas, consulta la pestaña Cloud Operations de la Google Cloud calculadora de precios.
- Para obtener consejos sobre cómo reducir la factura o determinar las fuentes de los costes elevados, consulta Controles de costes y atribución.
- Para obtener información sobre los motivos del modelo de precios, consulta Optimizar los costes de Google Cloud Managed Service for Prometheus.
- Para ver ejemplos de precios, consulta Datos de métricas cobrados por muestras ingeridas.
Cuotas
El servicio gestionado de Prometheus comparte cuotas de ingesta y lectura con Cloud Monitoring. La cuota de ingesta predeterminada es de 500 CPS por proyecto, con un máximo de 200 muestras en una sola llamada,lo que equivale a 100.000 muestras por segundo. La cuota de lectura predeterminada es de 100 CPS por ámbito de métricas.
Puede aumentar estas cuotas para admitir sus volúmenes de métricas y consultas. Para obtener información sobre cómo gestionar las cuotas y solicitar aumentos, consulta la página Trabajar con cuotas.
Términos del Servicio y cumplimiento
Managed Service para Prometheus forma parte de Cloud Monitoring y, por lo tanto, hereda determinados acuerdos y certificaciones de Cloud Monitoring, entre los que se incluyen los siguientes:
- Los Google Cloud términos del servicio
- El Acuerdo de Nivel de Servicio de Operaciones
- Niveles de cumplimiento de DISA (EE. UU.) y FedRAMP
- Compatibilidad con VPC-SC (Controles de Servicio de VPC)
Siguientes pasos
- Empieza a utilizar la recogida gestionada.
- Empieza a utilizar la recogida desplegada automáticamente.
- Empieza a usar OpenTelemetry Collector.
- Empieza a usar el Agente de operaciones.
- Usa PromQL en Cloud Monitoring para consultar métricas de Prometheus.
- Usa Grafana para consultar métricas de Prometheus.
- Consulta métricas de Cloud Monitoring con PromQL.
- Consulta las prácticas recomendadas y los diagramas de arquitectura.