このドキュメントでは、グラフにアノテーションとして表示できるイベントタイプについて説明します。イベントは、システムのオペレーションに影響する再起動やクラッシュなどのアクティビティです。イベントを表示すると、問題のトラブルシューティング時にさまざまなソースのデータの相関関係を把握できます。
イベントごとに、イベントをクエリする方法に関する情報と、リファレンスまたはトラブルシューティングのドキュメントへのリンクが提供されます。たとえば、ログの分析によってイベントが特定された場合、ログ エクスプローラまたはログベースのアラート ポリシーで使用できるクエリが提供されます。
グラフにアノテーションを追加するには、グラフを表示するダッシュボードまたはタブを構成します。たとえば、 Google Cloud コンソールの [ダッシュボード] ページに一覧表示されているほとんどのダッシュボードを構成して、イベントを表示できます。同様に、Compute Engine や Google Kubernetes Engine など、サービス固有の [オブザーバビリティ] タブを構成して、イベントを表示することもできます。構成情報については、ダッシュボードにイベントを表示するをご覧ください。
次のスクリーンショットは、ログエントリの分析によって特定された複数のイベントと、1 つの Service Health イベントが表示されているグラフを示しています。
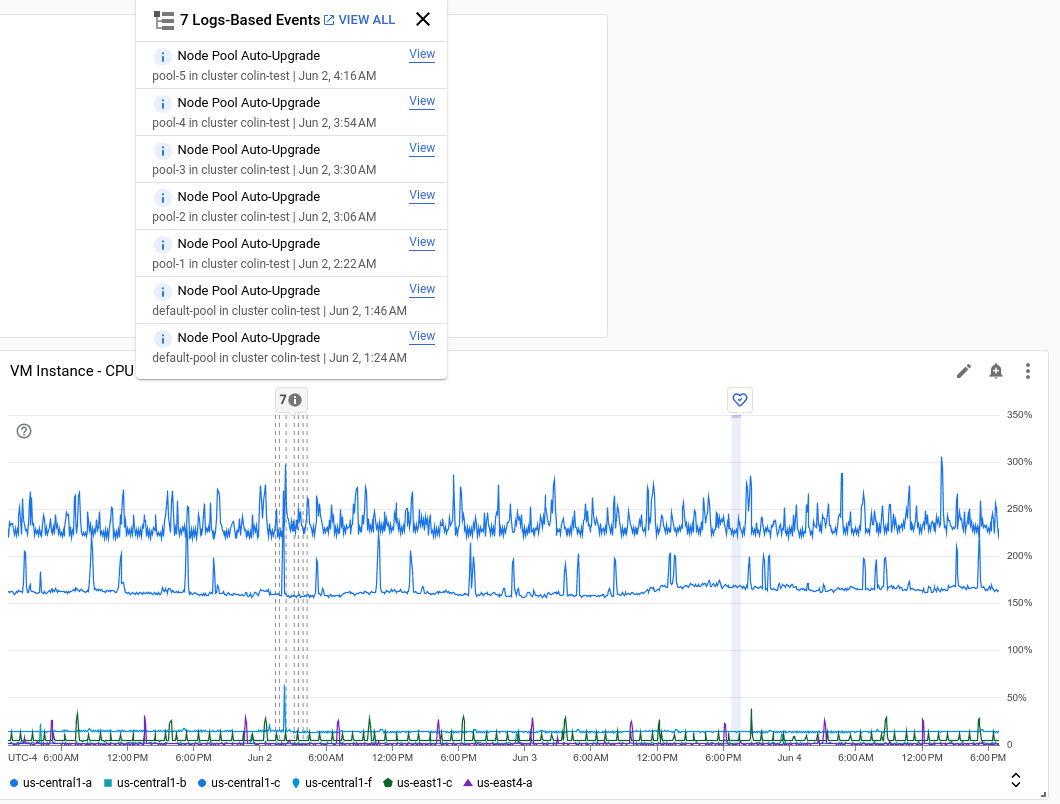
1 つのアノテーションで複数のイベントを一覧取得できます。前のスクリーンショットでは、GKE のデプロイメントのイベントが表示されています。
アラート イベントの種類
このセクションでは、ダッシュボードに表示されるアラート イベントタイプについて説明します。
対応待ちアラート
対応待ちアラート イベントは、グラフ化されたデータをインシデントの作成時に関連付ける際に役立ちます。対応待ちアラート イベントは、次の条件を満たす場合に表示されます。
- 対応するインシデントが、ダッシュボードで指定された期間中、対応待ちの状態だった。
- 対応するインシデントがクローズされていない。
ダッシュボードで指定された期間外に作成されたインシデントにはアノテーションが作成されず、表示されません。同様に、対応するインシデントが作成されてからダッシュボードで指定された期間内にクローズされた場合、対応待ちアラート イベントは表示されません。
対応待ちアラート イベントのツールチップには、次の情報が含まれます。
- アラート ポリシーの名前。
- 要約情報(利用可能な場合)。たとえば、この情報にしきい値と測定値が含まれる場合があります。
- インシデントの期間と、インシデントが作成された日時。
- 指標ラベルとリソースラベル。ツールチップに一部のラベルが表示されない場合があります。
- [表示] ボタン: インシデントの [詳細] ページを開きます。
Google Kubernetes Engine のイベントタイプ
このセクションでは、ダッシュボードに表示される Google Kubernetes Engine のイベントタイプについて説明します。
パッチ適用または更新された GKE ワークロード
このイベントタイプは、パフォーマンスの低下や他のパフォーマンスの問題と相関する可能性があるため、GKE ワークロードのデプロイや StatefulSet の変更のトラブルシューティングに役立ちます。このイベントタイプは、ワークロードが作成、更新、削除されたときに表示されます。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
log_id(cloudaudit.googleapis.com%2Factivity)
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.statefulsets.create OR io.k8s.apps.v1.statefulsets.patch OR
io.k8s.apps.v1.statefulsets.update OR io.k8s.apps.v1.statefulsets.delete OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete
)
-protoPayload.authenticationInfo.principalEmail=("system:addon-manager" OR "system:serviceaccount:kube-system:namespace-controller")
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.response.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.resourceName=~"namespaces/(kube-system|gmp-system|gmp-public|gke-gmp-system|istio-system)"
詳細については、ワークロードのデプロイの概要とオブザーバビリティ指標を表示するをご覧ください。
GKE Pod のクラッシュ
このイベントタイプは、GKE Pod のクラッシュを特定してトラブルシューティングする際に役立ちます。Pod のクラッシュは、メモリ不足またはアプリケーション エラーが原因で発生する可能性があります。このイベントタイプは、次のいずれかが発生した場合に表示されます。
- Pod のステータスが
CrashLoopBackoffである。 - Pod がゼロ以外の終了コードで終了する。
- Pod がメモリ不足の状態で終了する。
- Pod が強制排除される。
- readiness/liveliness プローブが失敗する。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
トラブルシューティングについては、トラブルシューティング: CrashLoopBackOff をご覧ください。
GKE Pod のスケジュール設定に失敗する
このイベントタイプは、ノードでスケジュールできない Pod を特定してトラブルシューティングする際に役立ちます。このイベントタイプは、次のいずれかの理由で Pod のスケジューリングが失敗した場合に表示されます。
- ノード CPU が不足している。
- ノードメモリの不足。
- taint または toleration のノードがない。
- ノードが Pod の最大数の上限に達している。
- ノードプールが最大サイズに達している。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
トラブルシューティングについては、トラブルシューティング: Pod をスケジュールできないをご覧ください。
GKE コンテナの作成に失敗する
このイベントタイプは、GKE コンテナの作成エラーを特定してトラブルシューティングする際に役立ちます。コンテナの作成は、ボリュームのマウントの失敗やイメージの pull の失敗などの理由で失敗する可能性があります。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
イメージの pull に関するトラブルシューティング情報については、イメージの pull のトラブルシューティングをご覧ください。
Pod オートスケーラーのスケールアップとスケールダウン
このイベントにより、ワークロードに対して実行中の Pod の数を増減する HorizontalPodAutoscaler の再スケーリングが可視化されます。詳細については、水平 Pod 自動スケーリングをご覧ください。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
クラスタ オートスケーラーのスケールアップとスケールダウン
このイベントにより、クラスタ オートスケーラーがクラスタのノードプール内のノード数をいつスケールアップまたはスケールダウンするかが可視化されます。詳細については、クラスタの自動スケーリングについてとクラスタのオートスケーラー イベントの表示をご覧ください。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
クラスタの作成と削除
このイベントは、GKE クラスタの作成と削除のアクションを追跡します。詳細については、Autopilot クラスタの作成、ゾーンクラスタの作成、クラスタの削除をご覧ください。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
クラスタの更新
このイベントは、GKE クラスタの更新を追跡します。更新には、コントロール プレーン バージョンの自動アップグレード、手動アップグレード、クラスタ構成の変更が含まれます。詳細については、クラスタまたはノードプールの手動アップグレードと Standard クラスタのアップグレードをご覧ください。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
ノードプールの更新
このイベントは、GKE ノードプールの更新を追跡します。更新には、ノードプール バージョンの自動アップグレード、手動アップグレード、構成の変更、サイズ変更が含まれます。詳細については、クラスタまたはノードプールの手動アップグレードと Standard クラスタのアップグレードをご覧ください。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Cloud Run のイベントタイプ
このセクションでは、ダッシュボードに表示される Cloud Run のイベントタイプについて説明します。
Cloud Run のデプロイ
このイベントタイプは、Cloud Run のデプロイの失敗を特定してトラブルシューティングする際に役立ちます。削除されたサービス アカウント、不適切な権限、コンテナのインポートの失敗、コンテナの起動の失敗などにより、デプロイが失敗することがあります。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
トラブルシューティングについては、トラブルシューティング: Cloud Run の問題をご覧ください。
Cloud SQL のイベントタイプ
このセクションでは、ダッシュボードに表示される Cloud SQL のイベントタイプについて説明します。
Cloud SQL フェイルオーバー
このイベントタイプは、手動フェイルオーバーまたは自動フェイルオーバーが発生したタイミングを特定する際に役立ちます。フェイルオーバーは、インスタンスまたはゾーンの障害が発生し、スタンバイ インスタンスが新しいプライマリ インスタンスになったときに発生します。フェイルオーバーの際、Cloud SQL は自動的にスタンバイ インスタンスからデータを提供するように切り替えます。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
詳細については、高可用性についてをご覧ください。
Cloud SQL の開始または停止
このイベントタイプは、Cloud SQL インスタンスが手動で起動、停止、または再起動されたことを特定する際に役立ちます。インスタンスを停止すると、すべての接続、開いているファイル、実行中のオペレーションも停止します。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
詳細については、高可用性についてとインスタンスの開始、停止、再起動をご覧ください。
Cloud SQL ストレージ
このイベントタイプは、データベース ストレージがいっぱいになったときや、ストレージ容量に達してデータベースがシャットダウンされたときなど、Cloud SQL ストレージに関連するイベントを識別する際に役立ちます。ストレージ容量に達していて自動ストレージが有効になっていないデータベースは、データの破損を防ぐためにシャットダウンされる場合があります。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Compute Engine のイベントタイプ
このセクションでは、ダッシュボードに表示される Compute Engine のイベントタイプについて説明します。
仮想マシンの終了
このイベントタイプは、手動でトリガーされたリセットと停止、ゲスト OS の終了、メンテナンスの終了、ホストエラーなど、仮想マシン(VM)の終了を識別する際に役立ちます。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
詳細については、VM を停止して起動すると VM のシャットダウンおよび再起動のトラブルシューティングをご覧ください。
VM インスタンスの開始エラー
このイベントは、Compute Engine VM インスタンスの開始エラーを追跡します。このイベントには、容量不足、IP スペースの枯渇、割り当て超過、Shielded VM の整合性エラーによる開始エラーが表示されます。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
VM インスタンスのゲスト OS エラー
このイベントは、シリアル コンソールのログに記録された特定の Compute Engine VM インスタンスのゲスト OS エラーを追跡します。トラッキングされるエラーは、ディスクの空き容量不足、ファイル システムのマウント失敗、Linux 緊急モードがアクティブになる起動の失敗などです。
これらのイベントを表示するには、VM またはプロジェクトのメタデータで serial-port-logging-enable=true を設定して、Cloud Logging へのシリアルポート出力ロギングを有効にする必要があります。詳細については、シリアルポート出力のロギングの有効化と無効化をご覧ください。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
マネージド インスタンス グループの更新
このイベントタイプは、マネージド インスタンス グループ(MIG)が更新されたタイミングを特定する際に役立ちます。たとえば、VM が追加または削除された場合、サイズ上限が変更された場合などです。詳細については、MIG で VM 構成の更新を自動的に適用するをご覧ください。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
詳細については、マネージド インスタンスを操作するとマネージド インスタンス グループのトラブルシューティングをご覧ください。
マネージド インスタンス グループ オートスケーラー
このイベントは、MIG オートスケーラーによって行われたスケーリングの決定を追跡します。これには、MIG の推奨されるサイズの変更、またはオートスケーラー自体のステータスの変更が含まれる場合があります。詳細については、インスタンスのグループの自動スケーリングをご覧ください。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Personalized Service Health のイベントタイプ
このセクションでは、ダッシュボードに表示できる Personalized Service Health の種類について説明します。
Google Cloud インシデント
トラブルシューティングを行う場合は、所有するサービスによって発生した障害と、使用しているGoogle Cloud サービスによって発生した障害を区別する必要があります。ダッシュボードで Personalized Service Health アノテーションを有効にすると、 Google Cloud サービスの中断またはサービス ヘルス イベントを確認できます。Service Health と統合されているサービスの一覧については、サポートされている Google プロダクトをご覧ください。
他のイベントタイプとは異なり、 Google Cloud インシデントはログエントリの分析によって特定されません。これらのイベントが発生したときに通知を受け取るには、アラート ポリシーを作成します。事前構成されたアラート ポリシーを選択するには、[Service Health ダッシュボード] ページのオプションを使用します。詳細については、クイックスタート: アラートを設定するをご覧ください。
Monitoring は、Service Health API にリクエストを発行し、表示しているデータに関連するインシデントに対するレスポンスをフィルタリングすることで、 Google Cloud インシデントを特定します。リクエストの構成は次のとおりです。
Relevance列挙型は、RELATED、IMPACTED、またはPARTIALLY_RELATEDに設定されます。この制限により、ダッシュボードには、Google Cloud プロジェクトが使用している Google Cloud サービスのイベントのみが表示されます。DetailedState列挙型がFALSE_POSITIVEに設定されていません。
Service Health アノテーションには、開始時間と所要時間が表示されます。グラフの背景色を変更することで、所要時間が表示されます。 Google Cloud インシデントのツールチップには、次の情報が表示されます。
- Google Cloud サービス。
- インシデントが対応待ちか解決済みか。
- イベントの日時と開始時間。
- 影響を受けるプロダクトと場所の数を示すチップ。影響を受けるプロダクトまたはロケーションを一覧表示するには、対応するチップの上にポインタを置きます。
- [表示] ボタン。選択すると、インシデントの詳細ページが開きます。
Service Health API にリクエストを送信する方法については、Service Health でサービス停止を確認するをご覧ください。
トラブルシューティングについては、Service Health の一般的な問題のトラブルシューティングをご覧ください。
稼働時間チェックのイベントタイプ
このセクションでは、ダッシュボードに表示できる稼働時間チェックのイベントタイプについて説明します。
稼働時間チェックの失敗
このイベントタイプは、構成されたリージョンの稼働時間チェックの失敗を特定する際に役立ちます。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
トラブルシューティング情報については、合成モニターと稼働時間チェックのトラブルシューティングをご覧ください。
SAP 用エージェントのイベントタイプ
このセクションでは、ダッシュボードに表示できる SAP 用エージェントのイベントタイプについて説明します。
SAP の可用性
このイベントタイプは、SAP 用エージェントの可用性に関連するイベントを特定する際に役立ちます。これらのイベントは、SAP HANA、SAP NetWeaver、または Pacemaker クラスタの可用性が変更されたときにトリガーされます。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=(workload.googleapis.com/sap/hana/service OR workload.googleapis.com/sap/hana/availability OR workload.googleapis.com/sap/nw/service OR workload.googleapis.com/sap/nw/availability OR workload.googleapis.com/sap/cluster/nodes OR workload.googleapis.com/sap/cluster/resources)
SAP Backint
このイベントタイプは、SAP Backint 用エージェントに関連するイベントを特定する際に役立ちます。Backint のバックアップまたは復元では常に、成功または失敗の詳細を示すイベントが、転送の統計情報とともに書き込まれます。ログのバックアップと復元は失敗の場合にのみ表示され、データのバックアップと復元は成功と失敗の両方の場合に表示されます。
log_id(google-cloud-sap-agent-backint) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) (jsonPayload.fileType=data OR (jsonPayload.fileType=log AND jsonPayload.success=false)) jsonPayload.message=SAP_BACKINT_FILE_TRANSFER
SAP オペレーション
このイベントタイプは、SAP 用エージェントのオペレーションに関連するイベントを特定する際に役立ちます。これらのイベントは、SAP HANA のレプリケーション ステータスが変更されたときにトリガーされます。
このイベントタイプにログベースのアラート ポリシーを作成するには、次のクエリを使用します。
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=workload.googleapis.com/sap/hana/ha/replication
次のステップ
ダッシュボードにイベントを表示する方法については、ダッシュボードにイベントを表示するをご覧ください。