デフォルトでは、Ops エージェントと以前の Monitoring エージェントは、Compute Engine 仮想マシン(VM)で実行されているプロセスに関する情報を取得するように構成されています。これらの指標は、Amazon Elastic Compute Cloud(EC2)VM で Monitoring エージェントを使用して収集することもできます。この指標セットは、プロセス指標と呼ばれ、agent.googleapis.com/processes という接頭辞によって識別できます。これらの指標は、Google Kubernetes Engine(GKE)では収集されません。
2021 年 8 月 6 日より、課金対象の指標に記載されているように、これらの指標に対する料金が導入されます。プロセス指標のセットは課金対象に分類されますが、料金は実装されていません。
このドキュメントでは、プロセス指標を可視化するツール、これらの指標から取り込むデータの量を決定する方法、関連する料金を最小限に抑える方法について説明します。
プロセス指標の操作
Metrics Explorer またはカスタム ダッシュボードを使用すると、作成されたグラフでプロセス指標データを可視化できます。詳細については、ダッシュボードとグラフの使用をご覧ください。また、Cloud Monitoring では、事前定義された 2 つのダッシュボードにプロセス指標のデータが含まれています。
- Monitoring の [VM インスタンス] ダッシュボード
- Compute Engine の VM インスタンスの [詳細] ダッシュボード
次のセクションでは、これらのダッシュボードについて説明します。
Monitoring: 集計されたプロセス指標を表示する
指標スコープ内の集計されたプロセス指標を表示するには、[VM インスタンス] ダッシュボードの [プロセス] タブに移動します。
-
Google Cloud コンソールで [
 ダッシュボード] ページに移動します。
ダッシュボード] ページに移動します。検索バーを使用してこのページを検索する場合は、小見出しが [Monitoring] の結果を選択します。
リストから [VM インスタンス] ダッシュボードを選択します。
[プロセス] をクリックします。
次のスクリーンショットは、Monitoring の [プロセス] ページの例を示しています。
![Monitoring の **[プロセス]** ページには、集計されたプロセス指標が表示されます。](https://cloud.google.com/static/monitoring/images/monitoring-processes-tab.png?authuser=3&hl=ja)
[プロセス] タブのグラフを使用して、指標スコープ内で CPU とメモリの消費量が最も多いプロセスや、ディスク使用率が最も高いプロセスを特定できます。
Compute Engine: リソース消費量の多い VM のパフォーマンス指標を表示する
Google Cloud プロジェクトのリソースを消費している上位 5 つの VM を示すパフォーマンス グラフを表示するには、VM インスタンスの [オブザーバビリティ] タブに移動します。
-
Google Cloud コンソールで [VM インスタンス] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Compute Engine] の結果を選択します。
- [オブザーバビリティ] をクリックします。
次のスクリーンショットは、Compute Engine の [オブザーバビリティ] ページの例を示したものです。
![Compute Engine の **[オブザーバビリティ]** ページには、特定のリソースを消費している上位 5 つの VM が表示されます。](https://cloud.google.com/static/monitoring/images/vm_instances_observability.png?authuser=3&hl=ja)
これらの指標を使用して VM の問題を診断する方法については、VM のパフォーマンスに関する問題のトラブルシューティングをご覧ください。
Compute Engine: VM ごとのプロセス指標を表示する
単一の Compute Engine 仮想マシン(VM)で実行されているプロセスのリストと、リソース消費量が最も多いプロセスのグラフを表示するには、VM の [オブザーバビリティ] タブに移動します。
-
Google Cloud コンソールで [VM インスタンス] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Compute Engine] の結果を選択します。
[インスタンス] タブで、検査する VM の名前をクリックします。
[オブザーバビリティ] をクリックして、この VM の指標を表示します。
[オブザーバビリティ] タブのナビゲーション パネルで、[プロセス] を選択します。
次のスクリーンショットは、Compute Engine の [プロセス] ページの例を示したものです。
![Compute Engine の **[プロセス]** ページには、VM ごとのプロセス指標が表示されます。](https://cloud.google.com/static/monitoring/images/gce-processes-page.png?authuser=3&hl=ja)
プロセス指標は最大 24 時間保持されるため、過去のプロセス指標を確認し、リソース消費量の異常を引き起こしたプロセスや、最もリソース消費量の多いプロセスを特定できます。たとえば、次のグラフは CPU リソース消費量が最も多いプロセスを示しています。期間セレクタを使用すると、グラフの期間を変更できます。期間セレクタには、直近 1 時間などのプリセット値が用意されています。また、カスタムの期間を入力することもできます。
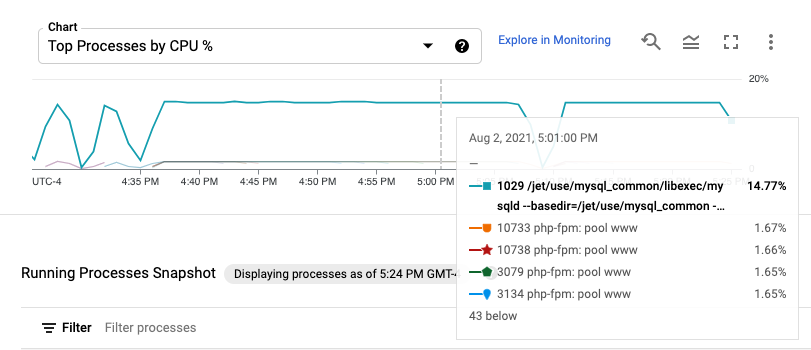
[実行中のプロセス] の表には、Linux top コマンドの出力に類似したリソース消費のリストが表示されます。デフォルトでは、最新のデータのスナップショットが表に表示されます。ただし、グラフ上で過去の終了時刻の時間範囲を選択すると、その範囲の最後に実行中のプロセスが表に表示されます。
これらの指標を使用して VM の問題を診断する方法については、VM のパフォーマンスに関する問題のトラブルシューティングをご覧ください。
エージェントによって収集されるプロセス指標
Linux エージェントは、次の表に示すすべての指標を Compute Engine VM で実行されているプロセスから、また Monitoring エージェントを使用して、Amazon Elastic Compute Cloud(EC2)VM で実行されているプロセスから収集します。Ops エージェント(バージョン 2.0.0 以降)と以前の Monitoring エージェントによる収集は無効にできます。
また、Windows VM で実行されている Ops エージェント(バージョン 2.0.0 以降)のプロセス指標の収集も無効にできます。
詳細については、プロセス指標の無効化をご覧ください。
Windows でこれらの指標の収集を無効にするには、Ops エージェントのバージョン 2.0.0 以降にアップグレードすることをおすすめします。詳細については、Ops エージェントのインストールをご覧ください。
プロセス指標の表
次の表の指標タイプの文字列には、agent.googleapis.com/processes/ という接頭辞を付ける必要があります。この接頭辞は表内で省略されています。
ラベルをクエリする場合は、metric.labels. 接頭辞を使用します(例: metric.labels.LABEL="VALUE")。
| 指標タイプリリース ステージ (リソース階層レベル) 表示名 |
|
|---|---|
| 種類、タイプ、単位 モニタリング対象リソース |
説明 ラベル |
count_by_state
GA
(プロジェクト)
プロセス |
|
GAUGE、DOUBLE、1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
特定の状態にあるプロセスの数。Linux のみ。60 秒ごとにサンプリングされます。state:
running、sleeping、zombie など
|
cpu_time
GA
(プロジェクト)
プロセス CPU |
|
CUMULATIVE、INT64、us{CPU}
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
特定のプロセスの CPU 時間。60 秒ごとにサンプリングされます。process:
プロセス名。
user_or_syst:
ユーザーまたはシステム プロセスのどちらか。
command:
プロセス コマンド。
command_line:
プロセス コマンドライン。最大文字数は 1,024 文字です。
owner:
プロセス オーナー。
pid:
プロセス ID。
|
disk/read_bytes_count
GA
(プロジェクト)
プロセスのディスク読み取り I/O |
|
CUMULATIVE、INT64、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
プロセスのディスク読み取り I/O。Linux のみ。60 秒ごとにサンプリングされます。process:
プロセス名。
command:
プロセス コマンド。
command_line:
プロセス コマンドライン。最大文字数は 1,024 文字です。
owner:
プロセス オーナー。
pid:
プロセス ID。
|
disk/write_bytes_count
GA
(プロジェクト)
プロセスのディスク書き込み I/O |
|
CUMULATIVE、INT64、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
プロセスのディスク書き込み I/O。Linux のみ。60 秒ごとにサンプリングされます。process:
プロセス名。
command:
プロセス コマンド。
command_line:
プロセス コマンドライン。最大文字数は 1,024 文字です。
owner:
プロセス オーナー。
pid:
プロセス ID。
|
fork_count
GA
(プロジェクト)
フォーク数 |
|
CUMULATIVE、INT64、1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
フォークされたプロセスの合計数。Linux のみ。60 秒ごとにサンプリングされます。 |
rss_usage
GA
(プロジェクト)
プロセスの常駐メモリ |
|
GAUGE、DOUBLE、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
特定のプロセスの常駐メモリ使用量。Linux のみ。60 秒ごとにサンプリングされます。process:
プロセス名。
command:
プロセス コマンド。
command_line:
プロセス コマンドライン。最大文字数は 1,024 文字です。
owner:
プロセス オーナー。
pid:
プロセス ID。
|
vm_usage
GA
(プロジェクト)
プロセスの仮想メモリ |
|
GAUGE、DOUBLE、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
特定のプロセスの VM 使用量。60 秒ごとにサンプリングされます。process:
プロセス名。
command:
プロセス コマンド。
command_line:
プロセス コマンドライン。最大文字数は 1,024 文字です。
owner:
プロセス オーナー。
pid:
プロセス ID。
|
表の生成日時: 2025-07-11 00:37:47 UTC
現在の取り込みの判別
Metrics Explorer を使用して、プロセス指標に対して現在取り込んでいるデータの量を確認できます。次の手順を行います。
-
Google Cloud コンソールで、[leaderboard Metrics Explorer] のページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Monitoring] の結果を選択します。
クエリビルダー ペインのツールバーで、[codeMQL] または [codePROMQL] という名前のボタンを選択します。
[言語] で [MQL] が選択されていることを確認します。言語切り替えボタンは、クエリの書式設定と同じツールバーにあります。
gce_instanceリソースとaws_ec2_instanceリソースのプロセス指標ポイントの合計数を表示する手順は次のとおりです。次のクエリを入力します。
def tagged_process_metric name = metric 'agent.googleapis.com/processes/'$name | add [metric_suffix: $name]; def process_metrics resource_type = fetch $resource_type | { @tagged_process_metric 'cpu_time' ; @tagged_process_metric 'disk/read_bytes_count' ; @tagged_process_metric 'disk/write_bytes_count' ; @tagged_process_metric 'rss_usage' ; @tagged_process_metric 'vm_usage' ; @tagged_process_metric 'count_by_state' ; @tagged_process_metric 'fork_count' } | within 1d | group_by [metric_suffix], 1m, [row_count: row_count()] | union; { @process_metrics 'gce_instance' ; @process_metrics 'aws_ec2_instance' } | outer_join 0, 0 | { rename [], [out: val(0)] | add [resource_type: 'gce_instance'] ; rename [], [out: val(1)] | add [resource_type: 'aws_ec2_instance'] } | union | group_by drop[metric_suffix], 1d, .sum[クエリを実行] をクリックします。結果のグラフには、各リソースタイプの値が表示されます。
指標の費用の見積もり
Monitoring の料金の例は、指標の取り込み費用を見積もる方法を示しています。これらの例は、プロセス指標に適用できます。
すべてのプロセス指標は 60 秒ごとにサンプリングされ、料金計算のために、すべてのプロセス指標は 8 バイトとしてカウントされるデータポイントを書き込みます。
プロセス指標の料金は、料金の例で使用されている、スタンダード ボリュームの費用の 5% に設定されます。したがって、それぞれの例で説明されているシナリオのすべての指標がプロセス指標であると仮定すると、各シナリオの総費用の 5% をプロセス指標の費用の見積もりとして使用できます。
プロセス指標の収集の無効化
Ops エージェント(バージョン 2.0.0 以降)と以前の Linux 用 Monitoring エージェントによるこれらの指標の収集を無効にする方法は複数あります。
エージェントは Compute Engine VM のみで実行され、Monitoring エージェントの場合は、Amazon Elastic Compute Cloud(EC2)VM のみで実行されます。以下の手順はこれらのプラットフォームにのみ適用されます。
2.0.0 より前のバージョンまたは以前の Windows 用 Monitoring エージェントを実行している場合は、Ops エージェントによる収集を無効にできません。Windows でこれらの指標の収集を無効にするには、Ops エージェントのバージョン 2.0.0 以降にアップグレードすることをおすすめします。詳細については、Ops エージェントのインストールをご覧ください。
一般的な手順を以下に示します。
VM に接続します。
既存の構成ファイルのコピーをバックアップとして作成します。バックアップ用のコピーはエージェントの構成ディレクトリの外部に保存して、エージェントが両方のファイルを読み込まないようにします。たとえば、次のコマンドは、Linux 用 Monitoring エージェントの構成ファイルのコピーを作成します。
cp /etc/stackdriver/collectd.conf BACKUP_DIR/collectd.conf.bak
以下で説明するオプションのいずれかを使用して構成を変更します。
エージェントを再起動して、新しい構成を読み込みます。
- Monitoring エージェント:
sudo service stackdriver-agent restart - Ops エージェント:
sudo service google-cloud-ops-agent restart
- Monitoring エージェント:
この VM のプロセス指標が収集されていないことを確認します。
[Metrics Explorer] を選択します。
[MQL] をクリックします。
gce_instanceリソースの場合は、次のクエリを入力します。VM_NAME は、この VM の名前に置き換えます。fetch gce_instance | metric 'agent.googleapis.com/processes/cpu_time' | filter (metadata.system_labels.name == 'VM_NAME') | align rate(1m) | every 1m
aws_ec2_instanceリソースの場合は、クエリ内のgce_instanceを置き換えます。[クエリを実行] をクリックします。
Linux または Windows 用 Ops エージェント
Ops エージェント用の構成ファイルの場所は、オペレーティング システムによって異なります。
- Linux の場合:
/etc/google-cloud-ops-agent/config.yaml - Windows の場合:
C:\Program Files\Google\Cloud Operations\Ops Agent\config\config.yaml
Ops エージェントによるすべてのプロセス指標の収集を無効にするには、以下を config.yaml ファイルに追加します。
metrics:
processors:
metrics_filter:
type: exclude_metrics
metrics_pattern:
- agent.googleapis.com/processes/*
これにより、metrics サービスのデフォルト パイプラインに適用される metrics_filter プロセッサでの収集からプロセス指標が除外されます。
Ops エージェントの構成オプションの詳細については、Ops エージェントの構成をご覧ください。
Linux 用 Monitoring エージェント
以前の Monitoring エージェントでのプロセス指標の収集を無効にするには、次のオプションがあります。
以降のセクションでは、各オプションと、そのオプションに関連するメリットとリスクを説明します。
エージェントの構成ファイルを変更する
このオプションでは、エージェントのメイン構成ファイル /etc/stackdriver/collectd.conf を直接編集して、プロセス指標の収集を有効にするセクションを削除します。
手順
collectd.conf ファイルに対して、3 つのグループを削除する必要があります。
次の
LoadPluginディレクティブとプラグイン構成を削除します。LoadPlugin processes <Plugin "processes"> ProcessMatch "all" ".*" Detail "ps_cputime" Detail "ps_disk_octets" Detail "ps_rss" Detail "ps_vm" </Plugin>次の
PostCacheChainディレクティブとPostCacheチェーンの構成を削除します。PostCacheChain "PostCache" <Chain "PostCache"> <Rule "processes"> <Match "regex"> Plugin "^processes$" Type "^(ps_cputime|disk_octets|ps_rss|ps_vm)$" </Match> <Target "jump"> Chain "MaybeThrottleProcesses" </Target> Target "stop" </Rule> <Rule "otherwise"> <Match "throttle_metadata_keys"> OKToThrottle false HighWaterMark 5700000000 # 950M * 6 LowWaterMark 4800000000 # 800M * 6 </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>PostCacheチェーンで使用されているMaybeThrottleProcessesチェーンを削除します。<Chain "MaybeThrottleProcesses"> <Rule "default"> <Match "throttle_metadata_keys"> OKToThrottle true TrackedMetadata "processes:pid" TrackedMetadata "processes:command" TrackedMetadata "processes:command_line" TrackedMetadata "processes:owner" </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>
メリットとリスク
- メリット
- 指標は一度も収集されないため、エージェントが使用するリソースを削減できます。
collectd.confファイルに他の変更を加えた場合、これらの変更を簡単に保存できます。
- リスク
- この構成ファイルを編集するには、
rootアカウントを使用する必要があります。 - ファイルに入力ミスが生じるリスクがあります。
- この構成ファイルを編集するには、
エージェントの構成ファイルを置き換える
このオプションでは、エージェントのメイン構成ファイルを、関連するセクションが削除された編集済みのバージョンに置き換えます。
手順
編集済みのファイル
collectd-no-process-metrics.confを GitHub リポジトリから/tmpディレクトリにダウンロードし、次の手順を行います。cd /tmp && curl -sSO https://raw.githubusercontent.com/Stackdriver/agent-packaging/master/collectd-no-process-metrics.conf既存の
collectd.confファイルを編集済みのファイルに置き換えます。cp /tmp/collectd-no-process-metrics.conf /etc/stackdriver/collectd.conf
メリットとリスク
- メリット
- 指標は一度も収集されないため、エージェントが使用するリソースを削減できます。
- ファイルを
rootとして手動で編集する必要はありません。 - 構成管理ツールを使用してファイルを簡単に置き換えることができます。
- リスク
collectd.confファイルにその他の変更を加えた場合は、これらの変更を置換後のファイルに統合する必要があります。
トラブルシューティング
このドキュメントで説明する手順では、エージェントの構成を変更するため、次のような問題が発生する可能性があります。
- 構成ファイルを編集するための十分な権限がない。構成ファイルを
rootアカウントから編集する必要がある。 - 構成ファイルを直接編集した場合、入力ミスが生じる。
他の問題の解決方法については、Monitoring エージェントのトラブルシューティングをご覧ください。
Windows 用 Monitoring エージェント
Windows VM 上で実行される以前の Monitoring エージェントによるプロセス指標の収集を無効にすることはできません。このエージェントは構成できません。Windows でこれらの指標の収集を無効にするには、Ops エージェントのバージョン 2.0.0 以降にアップグレードすることをおすすめします。詳細については、Ops エージェントのインストールをご覧ください。
Ops エージェントを実行している場合は、Linux または Windows 用 Ops エージェントをご覧ください。