根據預設,作業套件代理程式和舊版 Monitoring 代理程式會收集指標,擷取在 Compute Engine 虛擬機器 (VM) 上執行的程序相關資訊。您也可以使用 Monitoring 代理程式,在 Amazon Elastic Compute Cloud (EC2) VM 上收集這些指標。這組指標稱為「程序指標」,可透過 agent.googleapis.com/processes 前置字元識別。Google Kubernetes Engine (GKE) 不會收集這些指標。
自 2021 年 8 月 6 日起,系統將開始針對這些指標收費,詳情請參閱 Google Cloud Observability 價格頁面的「計費指標」一節。這組程序指標歸類為計費指標,但從未實施收費。
本文說明如何運用工具將程序指標視覺化、如何根據這些指標判斷擷取的資料量,以及如何盡量減少相關費用。
使用程序指標
您可以使用 Metrics Explorer 或自訂資訊主頁建立圖表,以視覺化方式呈現程序指標資料。詳情請參閱使用資訊主頁和圖表。此外,Cloud Monitoring 也會在兩個預先定義的資訊主頁中,納入程序指標的資料:
- Monitoring 中的「VM Instances」(VM 執行個體) 資訊主頁
- Compute Engine 中的 VM 執行個體「詳細資料」資訊主頁
以下各節將說明這些資訊主頁。
監控:查看匯總程序指標
如要查看指標範圍內的匯總程序指標,請前往「VM Instances」(VM 執行個體) 資訊主頁的「Processes」(程序) 分頁:
-
在 Google Cloud 控制台中,前往「Dashboards」(資訊主頁)
 頁面:
頁面:
如果您是使用搜尋列尋找這個頁面,請選取子標題為「Monitoring」的結果。
從清單中選取「VM Instances」(VM 執行個體) 資訊主頁。
按一下「程序」。
下方的螢幕截圖顯示「監控程序」頁面範例:
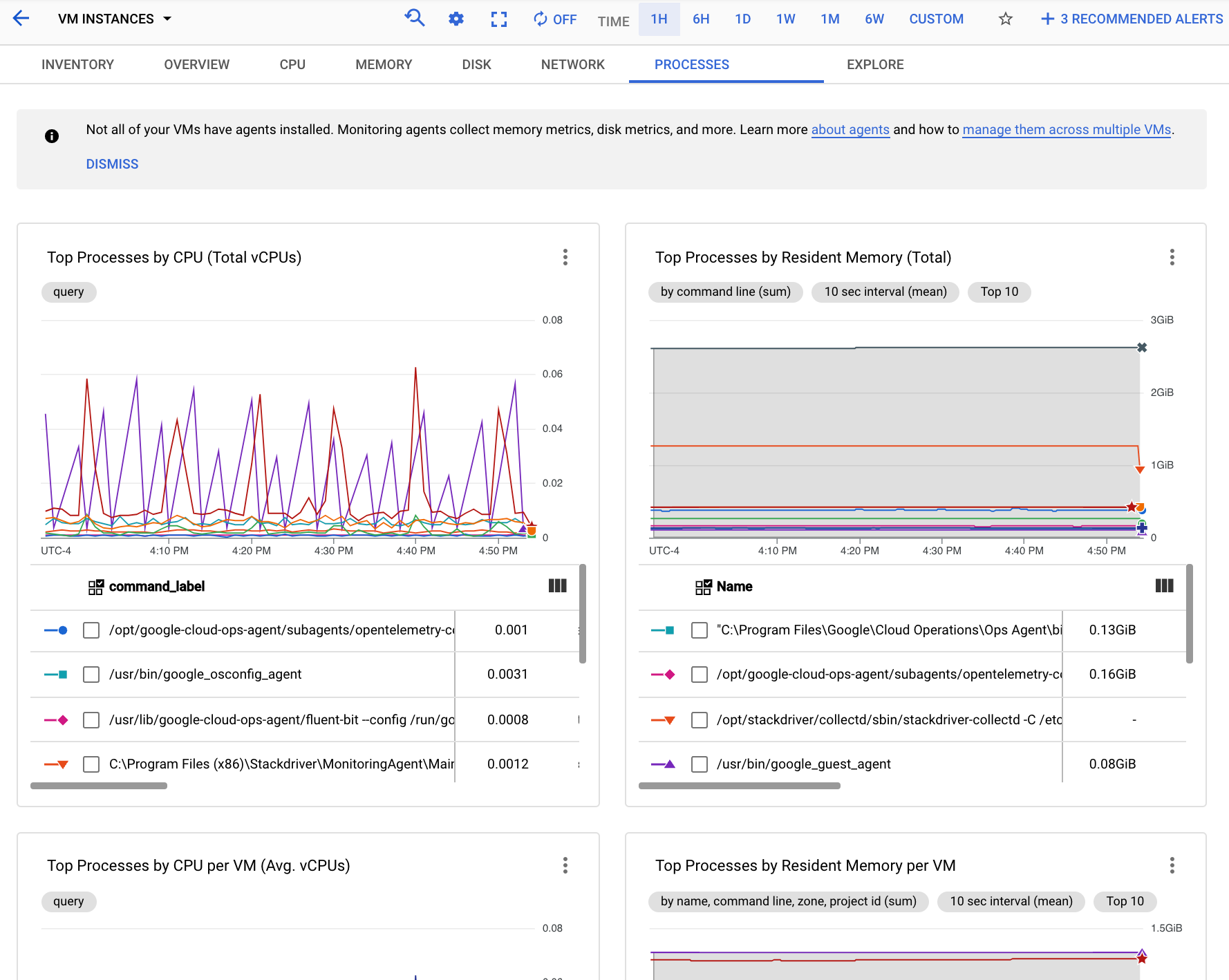
您可以透過「程序」分頁中的圖表,找出指標範圍內消耗最多 CPU 和記憶體,以及磁碟使用率最高的程序。
Compute Engine:查看耗用最多資源的 VM 的效能指標
如要查看效能圖表,瞭解專案中消耗最多資源的五部 VM,請前往 VM 執行個體的「可觀測性」 Google Cloud 分頁:
-
前往 Google Cloud 控制台的「VM instances」(VM 執行個體) 頁面:
如果您是使用搜尋列尋找這個頁面,請選取子標題為「Compute Engine」的結果。
- 按一下「可觀測性」。
以下螢幕截圖顯示 Compute Engine 可觀測性頁面的範例。
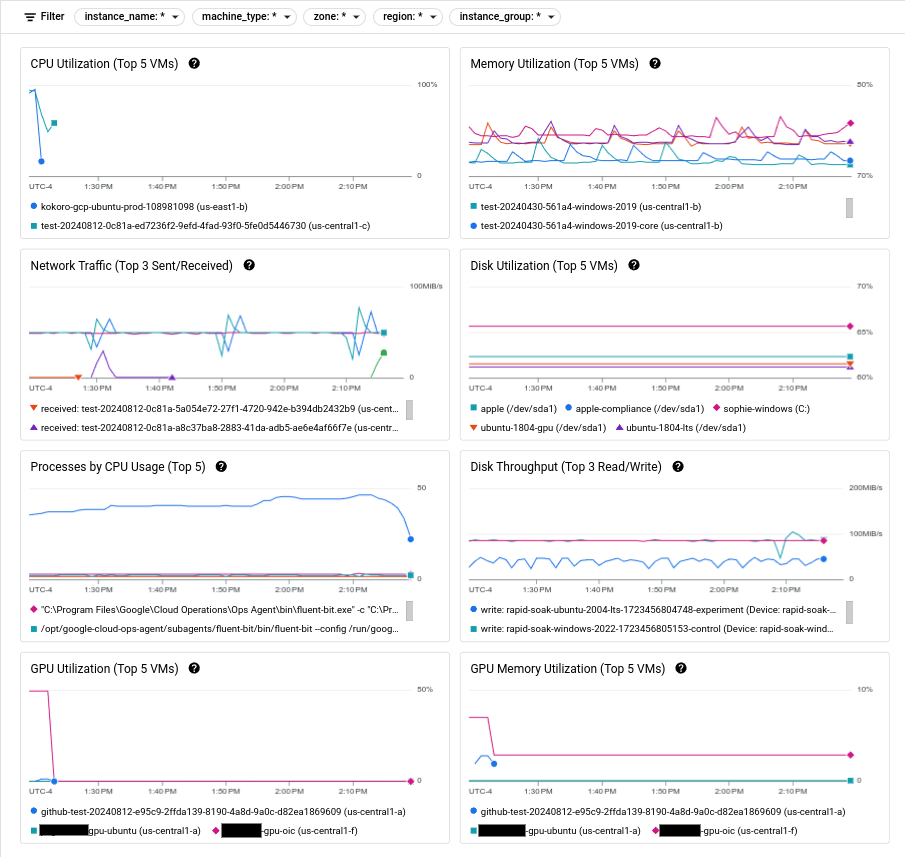
如要瞭解如何使用這些指標診斷 VM 問題,請參閱排解 VM 效能問題。
Compute Engine:查看每個 VM 的程序指標
如要查看在單一 Compute Engine 虛擬機器 (VM) 上執行的程序清單,以及資源耗用量最高的程序圖表,請前往 VM 的「可觀測性」分頁:
-
前往 Google Cloud 控制台的「VM instances」(VM 執行個體) 頁面:
如果您是使用搜尋列尋找這個頁面,請選取子標題為「Compute Engine」的結果。
在「Instances」(執行個體) 分頁中,按一下要檢查的 VM 名稱。
按一下「可觀測性」,即可查看這部 VM 的指標。
在「Observability」(可觀測性) 分頁的導覽窗格中,選取「Processes」(程序)。
以下螢幕截圖舉例說明 Compute Engine 的「Processes」(程序) 頁面:
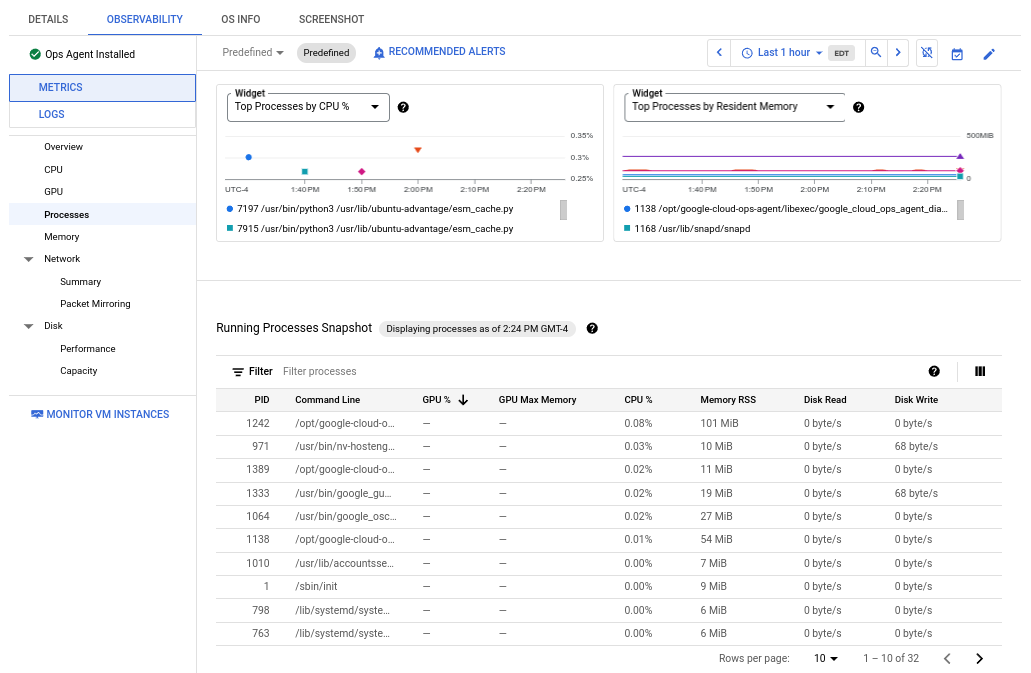
程序指標最多會保留 24 小時,因此您可以回溯時間,將資源消耗異常歸因於特定程序,或找出最耗費資源的程序。舉例來說,下圖顯示 CPU 資源使用率最高的程序。您可以使用時間範圍選取器變更圖表的時間範圍。時間範圍選取器提供預設值,例如最近一小時,您也可以輸入自訂時間範圍。
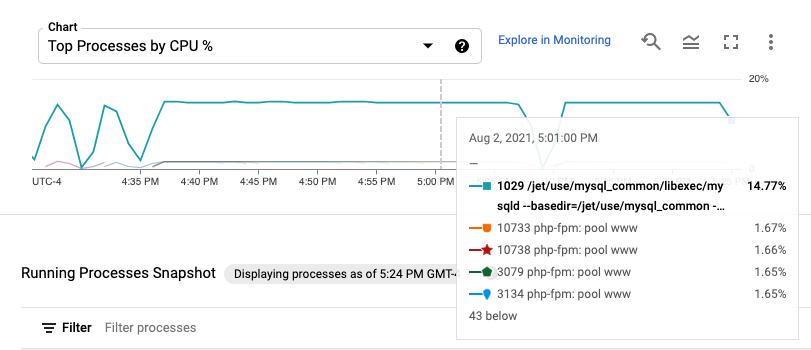
「Running Processes」(執行中的程序) 表格會列出資源耗用量,類似於 Linux top 指令的輸出內容。根據預設,表格會顯示最新資料的快照。
不過,如果您在圖表上選取的時間範圍結束於過去,表格就會顯示該範圍結束時執行的程序。
如要瞭解如何使用這些指標診斷 VM 問題,請參閱排解 VM 效能問題。
代理程式收集的程序指標
Linux 代理程式會從 Compute Engine VM 上執行的程序收集下表列出的所有指標,並使用 Monitoring 代理程式收集 Amazon Elastic Compute Cloud (EC2) VM 的指標。您可以透過作業套件代理程式 (2.0.0 以上版本) 和舊版 Monitoring 代理程式,停用這類資料的收集作業。
您也可以為在 Windows VM 上執行的作業套件代理程式 (2.0.0 以上版本) 停用程序指標收集功能。
詳情請參閱「停用程序指標」。
如要在 Windows 上停用這些指標的收集作業,建議您升級至作業套件代理程式 2.0.0 以上版本。詳情請參閱「安裝 Ops Agent」。
程序指標表
這個表格中的「指標類型」字串開頭必須為 agent.googleapis.com/processes/。該前置字串已從表格中的項目省略。
查詢標籤時,請使用 metric.labels. 前置字串,例如 metric.labels.LABEL="VALUE"。
| 指標類型 推出階段 (資源階層層級) 顯示名稱 |
|
|---|---|
| 種類、類型、單位 受監控資源 |
說明 標籤 |
count_by_state
GA
(專案)
程序 |
|
GAUGE、DOUBLE、1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
處於指定狀態的程序數量。僅適用於 Linux。取樣頻率為每 60 秒一次。
state:
跑步、睡覺、殭屍等。
|
cpu_time
GA
(專案)
程序 CPU |
|
CUMULATIVE、INT64、us{CPU}
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
指定程序的 CPU 時間。取樣頻率為每 60 秒一次。
process:
程序名稱。
user_or_syst:
使用者或系統程序。
command:
處理指令。
command_line:
處理指令列,最多 1024 個字元。
owner:
程序擁有者。
pid:
程序 ID。
|
disk/read_bytes_count
GA
(project)
處理磁碟讀取 I/O |
|
CUMULATIVE、INT64、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
處理磁碟讀取 I/O。僅適用於 Linux。取樣頻率為每 60 秒一次。
process:
程序名稱。
command:
處理指令。
command_line:
處理指令列,最多 1024 個字元。
owner:
程序擁有者。
pid:
程序 ID。
|
disk/write_bytes_count
GA
(project)
處理磁碟寫入 I/O |
|
CUMULATIVE、INT64、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
處理磁碟寫入 I/O。僅適用於 Linux。取樣頻率為每 60 秒一次。
process:
程序名稱。
command:
處理指令。
command_line:
處理指令列,最多 1024 個字元。
owner:
程序擁有者。
pid:
程序 ID。
|
fork_count
GA
(專案)
分支數量 |
|
CUMULATIVE、INT64、1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
分叉的程序總數。僅適用於 Linux。取樣頻率為每 60 秒一次。 |
rss_usage
GA
(專案)
程序常駐記憶體 |
|
GAUGE、DOUBLE、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
指定程序的常駐記憶體用量。僅適用於 Linux。取樣頻率為每 60 秒一次。
process:
程序名稱。
command:
處理指令。
command_line:
處理指令列,最多 1024 個字元。
owner:
程序擁有者。
pid:
程序 ID。
|
vm_usage
GA
(專案)
程序虛擬記憶體 |
|
GAUGE、DOUBLE、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
指定程序的 VM 用量。取樣頻率為每 60 秒一次。
process:
程序名稱。
command:
處理指令。
command_line:
處理指令列,最多 1024 個字元。
owner:
程序擁有者。
pid:
程序 ID。
|
這份表格的產生時間是 2025 年 8 月 8 日 23:40:45 (世界標準時間)。
判斷目前的擷取作業
您可以使用 Metrics Explorer 查看程序指標的擷取資料量。請按照下列程序操作:
-
前往 Google Cloud 控制台的 leaderboard「Metrics Explorer」頁面:
如果您是使用搜尋列尋找這個頁面,請選取子標題為「Monitoring」的結果。
在查詢建構工具窗格的工具列中,選取名稱為 code MQL 或 code PromQL 的按鈕。
確認已在「Language」(語言) 切換按鈕中選取「PromQL」。語言切換按鈕位於同一工具列,可供你設定查詢格式。
如要查看
gce_instance和aws_ec2_instance資源的程序指標點總數,請按照下列步驟操作:輸入下列查詢:
sum_over_time( sum by (resource_type) ( label_replace( label_replace( sum(count_over_time({"agent.googleapis.com/processes/cpu_time", monitored_resource="gce_instance"}[1m])), "metric_suffix", "cpu_time", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/read_bytes_count", monitored_resource="gce_instance"}[1m])), "metric_suffix", "disk_read_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/write_bytes_count", monitored_resource="gce_instance"}[1m])), "metric_suffix", "disk_write_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/rss_usage", monitored_resource="gce_instance"}[1m])), "metric_suffix", "rss_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/vm_usage", monitored_resource="gce_instance"}[1m])), "metric_suffix", "vm_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/count_by_state", monitored_resource="gce_instance"}[1m])), "metric_suffix", "count_by_state", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/fork_count", monitored_resource="gce_instance"}[1m])), "metric_suffix", "fork_count", "", "" ), "resource_type", "gce_instance", "", "" ) or label_replace( label_replace( sum(count_over_time({"agent.googleapis.com/processes/cpu_time", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "cpu_time", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/read_bytes_count", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "disk_read_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/write_bytes_count", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "disk_write_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/rss_usage", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "rss_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/vm_usage", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "vm_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/count_by_state", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "count_by_state", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/fork_count", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "fork_count", "", "" ), "resource_type", "aws_ec2_instance", "", "" ) )[1d:] )按一下 [Run query] (執行查詢),產生的圖表會顯示各資源類型的值。
預估指標費用
Monitoring 計費示例說明如何估算擷取指標的費用。這些範例可套用至程序指標。
系統每 60 秒會對所有程序指標取樣一次,且所有程序指標都會寫入資料點,這些資料點在計算費用時會計為 8 個位元組。
在定價範例中,程序指標的價格是標準用量費用的 5%。因此,如果您假設這些範例情境中的所有指標都是程序指標,則可將每個情境的總成本的 5% 做為程序指標成本的預估值。
停用程序指標收集功能
您可以透過多種方式,停用作業套件代理程式 (2.0.0 以上版本) 和 Linux 舊版 Monitoring 代理程式的指標收集功能。
代理程式僅適用於 Compute Engine VM,Monitoring 代理程式則適用於 Amazon Elastic Compute Cloud (EC2) VM;這些程序僅適用於這些平台。
如果您在 Windows 上執行 2.0.0 以下版本或舊版 Monitoring 代理程式,就無法透過作業套件代理程式停用收集作業。如要在 Windows 上停用這些指標的收集作業,建議您升級至作業套件代理程式 2.0.0 以上版本。詳情請參閱「安裝 Ops Agent」。
一般程序如下:
連線至 VM。
複製現有設定檔做為備份。請將備份副本儲存在代理程式設定目錄以外的位置,以免代理程式嘗試載入這兩個檔案。舉例來說,下列指令會複製 Linux 上的監控代理程式設定檔:
cp /etc/stackdriver/collectd.conf BACKUP_DIR/collectd.conf.bak
使用下列其中一個選項變更設定:
重新啟動代理程式,以納入新設定:
- 監控代理程式:
sudo service stackdriver-agent restart - 作業套件代理程式:
sudo service google-cloud-ops-agent restart
- 監控代理程式:
確認系統不再收集這個 VM 的程序指標:
-
前往 Google Cloud 控制台的 leaderboard「Metrics Explorer」頁面:
如果您是使用搜尋列尋找這個頁面,請選取子標題為「Monitoring」的結果。
在查詢建構工具窗格的工具列中,選取名稱為 code MQL 或 code PromQL 的按鈕。
確認已在「Language」(語言) 切換按鈕中選取「PromQL」。語言切換按鈕位於同一工具列,可供你設定查詢格式。
如果是
gce_instance資源,請輸入下列查詢,並將 VM_NAME 替換為這個 VM 的名稱:rate({"agent.googleapis.com/processes/cpu_time", monitored_resource="gce_instance", metadata_system_name="VM_NAME"}[1m])如果是
aws_ec2_instance資源,請在查詢中取代gce_instance。按一下 [Run Query] (執行查詢)。
-
Linux 或 Windows 上的作業套件代理程式
作業套件代理程式設定檔的位置會因作業系統而異:
- Linux:
/etc/google-cloud-ops-agent/config.yaml - Windows:
C:\Program Files\Google\Cloud Operations\Ops Agent\config\config.yaml
如要停用作業套件代理程式收集所有程序指標,請在 config.yaml 檔案中新增下列內容:
metrics:
processors:
metrics_filter:
type: exclude_metrics
metrics_pattern:
- agent.googleapis.com/processes/*
這會排除 metrics 服務中預設管道適用的處理器,避免收集程序指標。metrics_filter
如要進一步瞭解 Ops Agent 的設定選項,請參閱「設定 Ops Agent」。
Linux 的 Monitoring 代理程式
您可以透過下列選項,使用舊版 Monitoring 代理程式停用程序指標的收集作業:
以下各節將說明每個選項,並列出相關優點和風險。
修改代理程式的設定檔
使用這個選項時,您可以直接編輯代理程式的主要設定檔 /etc/stackdriver/collectd.conf,移除啟用程序指標收集作業的區段。
程序
您必須從 collectd.conf 檔案中刪除三組項目:
刪除下列
LoadPlugin指令和外掛程式設定:LoadPlugin processes <Plugin "processes"> ProcessMatch "all" ".*" Detail "ps_cputime" Detail "ps_disk_octets" Detail "ps_rss" Detail "ps_vm" </Plugin>刪除下列
PostCacheChain指令,以及PostCache鏈的設定:PostCacheChain "PostCache" <Chain "PostCache"> <Rule "processes"> <Match "regex"> Plugin "^processes$" Type "^(ps_cputime|disk_octets|ps_rss|ps_vm)$" </Match> <Target "jump"> Chain "MaybeThrottleProcesses" </Target> Target "stop" </Rule> <Rule "otherwise"> <Match "throttle_metadata_keys"> OKToThrottle false HighWaterMark 5700000000 # 950M * 6 LowWaterMark 4800000000 # 800M * 6 </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>刪除
PostCache鏈結使用的MaybeThrottleProcesses鏈結:<Chain "MaybeThrottleProcesses"> <Rule "default"> <Match "throttle_metadata_keys"> OKToThrottle true TrackedMetadata "processes:pid" TrackedMetadata "processes:command" TrackedMetadata "processes:command_line" TrackedMetadata "processes:owner" </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>
優點和風險
- 優點
- 由於系統不會收集指標,因此可減少代理程式消耗的資源。
- 如果您對
collectd.conf檔案進行了其他變更,或許可以輕鬆保留這些變更。
- 風險
- 您必須使用
root帳戶編輯這個設定檔。 - 這樣做可能會在檔案中加入錯字。
- 您必須使用
取代代理程式的設定檔
選用這個選項後,系統會以預先編輯的版本取代代理程式的主要設定檔,並為您移除相關區段。
程序
從 GitHub 存放區將預先編輯的
collectd-no-process-metrics.conf檔案下載至/tmp目錄,然後執行下列操作:cd /tmp && curl -sSO https://raw.githubusercontent.com/Stackdriver/agent-packaging/master/collectd-no-process-metrics.conf將現有的
collectd.conf檔案換成預先編輯的檔案:cp /tmp/collectd-no-process-metrics.conf /etc/stackdriver/collectd.conf
優點和風險
- 優點
- 由於系統不會收集指標,因此可減少代理程式消耗的資源。
- 您不必手動編輯
root檔案。 - 設定管理工具可以輕鬆取代檔案。
- 風險
- 如果您對
collectd.conf檔案進行其他變更,請將這些變更合併至替代檔案。
- 如果您對
疑難排解
本文件所述程序會變更代理程式的設定,因此最有可能發生下列問題:
- 權限不足,無法編輯設定檔。設定檔必須從
root帳戶編輯。 - 直接編輯設定檔時,可能會在設定檔中輸入錯字。
如要瞭解如何解決其他問題,請參閱「排解監控代理程式問題」。
Windows 上的 Monitoring 代理程式
在 Windows VM 上執行的舊版 Monitoring 代理程式無法停用程序指標收集功能。這個代理程式無法設定。 如要在 Windows 上停用這些指標的收集作業,建議您升級至作業套件代理程式 2.0.0 以上版本。詳情請參閱「安裝 Ops Agent」。
如果您執行的是作業套件代理程式,請參閱「Linux 或 Windows 上的作業套件代理程式」。