Memorystore for Redis のスタンダード ティアでは、リードレプリカを使用してアプリケーションの読み取りクエリをスケーリングできます。このページは、Memorystore のさまざまな Redis 階層の機能を理解していることを前提としています。
リードレプリカを使用すると、レプリカにクエリを実行して読み取りワークロードをスケーリングできます。読み取りエンドポイントは、アプリケーションがレプリカ間でクエリを簡単に分散できるようにするためのものです。詳細については、読み取りエンドポイントで読み取りをスケーリングするをご覧ください。
リードレプリカを使用して Redis インスタンスを管理する手順については、リードレプリカの管理をご覧ください。
リードレプリカのユースケース
セッション ストア、リーダーボード、レコメンデーション エンジンなどのユースケースでは、インスタンスの高可用性が必要です。これらのユースケースでは、書き込みよりも多くの読み取りが発生します。また通常であれば、ある程度のステイル読み取りは許容できます。このような場合は、リードレプリカを利用してインスタンスの可用性とスケーラビリティを改善することをおすすめします。
リードレプリカの動作
- リードレプリカは、デフォルトではスタンダード ティア インスタンスで有効になっていません。
- インスタンスでリードレプリカを有効にすると、そのインスタンスのリードレプリカは無効にできなくなります。
- スタンダード ティア インスタンスには 1~5 個のリードレプリカを含めることができます。
- 読み取りエンドポイントは、レプリカノード間でクエリを分散するための単一のエンドポイントを提供します。
- リードレプリカは、Redis 非同期レプリケーションを使用して維持されます。
注意点と制限事項
- リードレプリカは、ノードが 5 GB 以上のインスタンス サイズでのみサポートされます。
- リードレプリカは、Redis バージョン 5.0 以降を使用するインスタンスでのみ有効にできます。
- ノードのプロビジョニングにゾーンと代替ゾーンを指定した場合、Memorystore はインスタンスの 1 番目のノードと 2 番目のノードにこれらのゾーンを使用します。その後、Memorystore はインスタンスにプロビジョニングされた残りのノードのゾーンを選択します。
- CIDR IP アドレス範囲が
/28以上のインスタンスをプロビジョニングする必要があります。/27や/26など、より大きな範囲サイズも有効です。/29などの狭い範囲では、この機能はサポートされていません。
アーキテクチャ
リードレプリカを有効にするときに、インスタンスに必要なレプリカの数を指定します。Memorystore が、プライマリ ノードとリードレプリカ ノードをリージョン内の使用可能なゾーンに自動的に分散します。
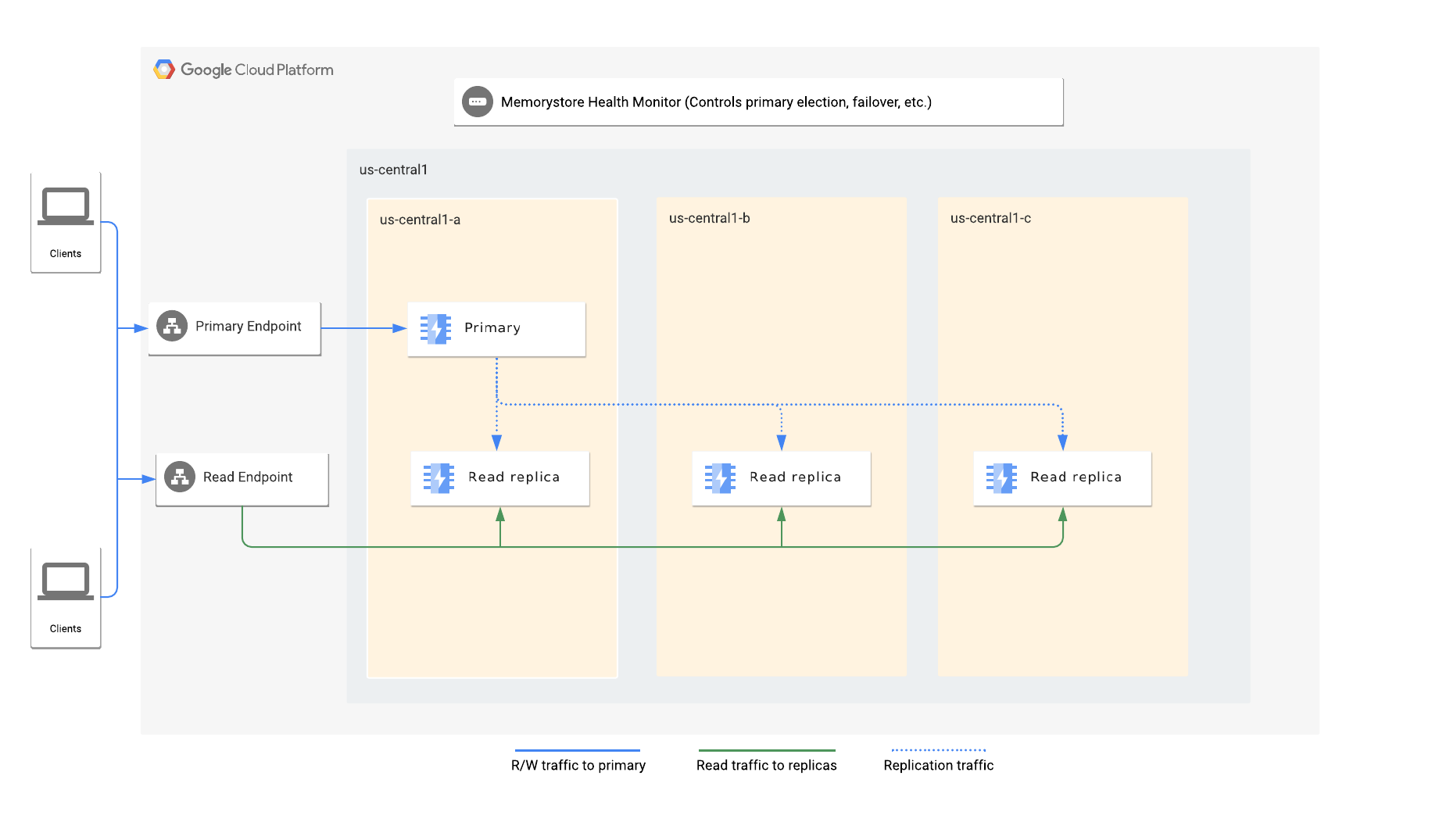
各インスタンスには、プライマリ エンドポイントと読み取りエンドポイントがあります。プライマリ エンドポイントは常にトラフィックをプライマリ ノードに転送し、読み取りエンドポイントは使用可能なレプリカ間で読み取りクエリを自動的に負荷分散します。
Memorystore for Redis のヘルスチェック サービスはインスタンスをモニタリングし、プライマリ ノードの障害を検出して、レプリカを新しいプライマリとして選択し、新しいプライマリへの自動フェイルオーバーを開始します。
リードレプリカを使用するインスタンスのフェイルオーバー
プライマリに障害が発生すると、Memorystore ヘルスモニタリング サービスがフェイルオーバーを開始し、新しいプライマリが読み取りと書き込みの両方で使用されます。通常、フェイルオーバーは 30 秒以内に完了します。
フェイルオーバーが発生すると、プライマリ エンドポイントは自動的にトラフィックを新しいプライマリにリダイレクトします。フェイルオーバー中は、プライマリ エンドポイントへのすべてのクライアント接続が切断されます。接続再試行ロジックを備えたアプリケーションは、新しいプライマリがオンラインになると自動的に再接続されます。読み取りエンドポイントへのクライアント接続の一部は、フェイルオーバー時にプライマリに昇格されたリードレプリカから切断されます。残りのレプリカへの接続は、フェイルオーバー中も処理されます。再試行すると、接続は新しいレプリカにリダイレクトされます。
レプリケーションは非同期のため、フェイルオーバー時に異なるレプリケーション ラグが発生する場合があります。ただし、フェイルオーバー プロセスは、ベスト エフォートで最小限の遅延でレプリカにフェイルオーバーします。これにより、フェイルオーバー時のデータ損失の量と読み取りスループットの低下を最小限に抑えることができます。新しく昇格したプライマリは、以前のプライマリと同じゾーンにも別のゾーンにも配置できます。レプリカが以前のプライマリと同じゾーンにあり、そのレプリカのラグが最も少ない場合、そのレプリカが新しいプライマリに選択されます。そうでない場合は、別のゾーンのレプリカを新しいプライマリにできます。
レプリケーションは非同期であるため、フェイルオーバー中に最新でないデータが読み取られる可能性があります。また、新しいプライマリが昇格されている間、インスタンスへの書き込みの一部が失われる可能性があります。アプリケーションはこの動作に対処できる必要があります。
Redis は、フェイルオーバー中に完全同期を必要とする他のレプリカを回避するよう最善を尽くしますが、まれに発生することがあります。完全同期には、書き込みレートとレプリケートされているデータセットのサイズに応じて、数分から 1 時間かかることがあります。この間、完全同期を行っているレプリカは読み取りができなくなります。同期が完了すると、レプリカにアクセスして読み取れるようになります。
リードレプリカの障害モード
リードレプリカを使用するインスタンスでは、アプリケーションに影響を与えるさまざまな障害、異常状態が発生する可能性があります。この動作は、インスタンスに 1 つのレプリカが存在するか、2 つ以上のレプリカが存在するかによって異なります。このセクションでは、一般的な障害モードの概要と、これらの状況下でのインスタンスの動作の概要について説明します。
レプリカを利用できない
レプリカがなんらかの理由で失敗した場合、レプリカは使用不可としてマークされ、そのレプリカへのすべての接続は一定のタイムアウト後に終了します。レプリカが復元されると、復元されたレプリカに新しい接続がルーティングされます。レプリカの復旧時間は、障害モードによって異なります。
ゾーン障害が発生した場合、Memorystore for Redis はゾーンが使用可能になるまでレプリカを復元しません。
ゾーンの障害
プライマリが配置されているゾーンに障害が発生した場合、そのプライマリは自動的に別のゾーンのレプリカにフェイルオーバーします。インスタンスにレプリカが 1 つしかない場合、読み取りエンドポイントはゾーンが停止している間は使用できません。インスタンスに複数のレプリカがある場合、影響を受けているゾーン外のレプリカを読み取ることができます
1 つ以上のレプリカが配置されているゾーンに障害が発生した場合、ゾーン障害が発生している間、これらのレプリカは使用できません。2 つのゾーンで障害が発生し、レプリカが 2 つ以上ある場合、残りのゾーンでラグが最も少ないレプリカがプライマリに昇格されます。影響を受けていないゾーンの残りのレプリカは、読み取りに使用できます。
ネットワーク パーティション
ネットワーク パーティションは、ノードが動作し続けているものの、すべてのクライアント、ゾーン、ピアノードに到達できないシナリオです。Memorystore では、クォーラム ベースのシステムを使用して、孤立したノードで書き込みが行われないようにします。ネットワーク パーティションの場合、少数パーティションのプライマリは自己降格します。多数パーティション(存在する場合)は、新しいプライマリをまだ選択していない場合は選択します。孤立したレプリカは引き続き読み取りを処理します。ただし、プライマリから同期できない場合、情報が最新でなくなる可能性があります。
リンクが壊れているかどうかを確認するには、master_link_down_since_seconds と offset_diff の指標をモニタリングして、孤立したノードを特定します。
完全同期
レプリカがプライマリから大幅に遅延すると、完全同期がトリガーされ、スナップショット全体がプライマリからレプリカにコピーされます。このオペレーションには、1 分から 1 時間かかります。完全同期によってインスタンスの失敗は発生しませんが、この間、完全同期を実行しているレプリカは読み取りができず、プライマリの CPU とメモリ使用率が高くなります。
プライマリ エンドポイントから READONLY が返される
リードレプリカがある Memorystore for Redis インスタンスのプライマリ エンドポイントへの書き込みによって、-READONLY You can't write against a read
only replica. エラーが発生することがあります。インスタンスへの接続を閉じて再作成することをおすすめします。ほとんどの場合、クライアント アプリケーションを再起動すると、問題を軽減できます。これらのオプションが利用できない場合や、問題が解決しない場合は、 Google Cloud サポートチームにお問い合わせください。
読み取りエンドポイントを使用した読み取りのスケーリング
リードレプリカでは、レプリカから読み取ることで読み取りをスケーリングできます。アプリケーションは、読み取りエンドポイントを介してリードレプリカに接続できます。
読み取りエンドポイント
読み取りエンドポイントは、アプリケーションが接続する IP アドレスです。これにより、インスタンス内のレプリカ間で接続が均等に負荷分散されます。リードレプリカへの接続は、読み取りクエリを送信できますが、書き込みクエリは送信できません。リードレプリカが有効になっているすべてのスタンダード ティア インスタンスには、読み取りエンドポイントがあります。インスタンスの読み取りエンドポイントを表示する手順については、インスタンスのリードレプリカ情報を表示するをご覧ください。
読み取りエンドポイントの動作
- 読み取りエンドポイントは、使用可能なすべてのレプリカに自動的に接続を分散します。接続はプライマリに転送されません。
- レプリカは、クライアント トラフィックを処理できる限り、使用可能とみなされます。これには、レプリカがプライマリと完全同期を実行している時間は含まれません。
- レプリケーション ラグが高いレプリカでは引き続きトラフィックが処理されます。書き込み量が多いアプリケーションは、大量の書き込みを行うレプリカから最新でないデータを読み取ることができます。
- レプリカノードがプライマリになると、そのノードへの接続が終了し、新しい接続は新しいレプリカノードにリダイレクトされます。
- 読み取りエンドポイントへの個々の接続は、接続の存続期間中に同じレプリカをターゲットにします。同じクライアント ホストからの異なる接続が、同じレプリカノードをターゲットにするとは限りません。
読み取りの整合性
リードレプリカは、ネイティブ OSS Redis 非同期レプリケーションを使用して維持されます。非同期レプリケーションの性質上、レプリカがプライマリより遅れる場合があります。レプリカからの読み取りも行っている一定の書き込みを伴うアプリケーションは、整合性のない読み取りを許容できる必要があります。
アプリケーションで「read your write」の整合性が必要な場合は、書き込みと読み取りの両方にプライマリ エンドポイントを使用することをおすすめします。プライマリ エンドポイントを使用すると、読み取りは常にプライマリに転送されます。この場合でも、フェイルオーバー後にステイル読み取りが発生する可能性があります。
プライマリのキーに TTL を設定すると、期限切れのキーがプライマリやレプリカから読み取られなくなります。これは、期限切れの鍵をレプリカから読み取れないためです。
既存のインスタンスでリードレプリカを有効にする動作
リードレプリカを有効にするのは排他的オペレーションです。つまり、リードレプリカを有効にするのと同じオペレーションの一部として、他のアップデート オペレーションのインスタンス変更を行うことはできません。
既存の Redis インスタンスでリードレプリカを有効にするには、ノードの配置に有効なセカンダリ IP アドレス範囲を割り当てる必要があります。これは、Memorystore for Redis に割り当てられている既存の IP アドレス範囲のサイズに関係なく、サイズ
/28のクラスレス ドメイン間ルーティング(CIDR)範囲である必要があります。- Redis インスタンスのリードレプリカを有効にする場合は、追加の IP 範囲を指定する必要があります。特定の範囲を選択することも、Memorystore で自動的に選択させることもできます。
リードレプリカを有効にしても、インスタンスの読み取り / 書き込み IP アドレスは変更されません。読み取りエンドポイントの IP アドレスは、Memorystore インスタンスに割り振られた元の範囲にあり、リードレプリカを有効にするときに指定した追加の範囲ではありません。
新しいリードエンドポイントを見つけるには、リードレプリカを有効にしてからインスタンスのリードレプリカ情報を表示します。
インスタンスのスケーリング
インスタンスのリードレプリカの数をスケーリングでき、また、ノードサイズを変更することもできます。
ノードの追加と削除の手順については、Redis インスタンスのレプリカノードを追加または削除するをご覧ください。
Redis ノードのサイズをスケーリングする手順については、Redis ノードのサイズをスケーリングするをご覧ください。
アプリケーションへの影響を最小限に抑えるために、読み取りトラフィックと書き込みトラフィックが少ない期間にインスタンスをスケーリングすることをおすすめします。
新しいレプリカを追加すると、レプリカが完全同期を実行している間、プライマリの負荷が増大します。ノードを追加しても、既存の接続は影響を受けたり転送されたりしません。新しいレプリカが使用可能になると、エンドポイントからの接続の受信が開始され、読み取りが行われます。レプリカを削除すると、そのレプリカにルーティングされているアクティブな接続が閉じられます。クライアント アプリケーションは、残りのレプリカへの接続を再確立するために、読み取りエンドポイントに自動的に再接続するように構成する必要があります。
おすすめの方法
メモリ管理
クライアントの書き込みがインスタンスの maxmemory の上限を超えることはありません。ただし、フラグメンテーション、レプリケーション バッファ、EVAL などのコストのかかるコマンドなどのオーバーヘッドにより、この制限を超えてメモリ使用率が増加する可能性があります。この場合、Memorystore はメモリ圧迫が軽減されるまで書き込みに失敗します。詳細については、メモリ管理のベスト プラクティスをご覧ください。
エクスポートまたは完全同期レプリケーションが原因で Memorystore で BGSAVE 操作が実行されていて、OOM 状態が発生した場合、子プロセスは強制終了されます。この場合、BGSAVE オペレーションは失敗し、Redis ノードサーバーは引き続き使用できます。
あらゆる状況でレプリケーションとスナップショットの作成を保証するには、エクスポート、スケーリングなどの重要なオペレーション中に、メモリ使用率を 50% 未満に保つことをおすすめします。手動でエクスポートやフェイルオーバーをトリガーすることで、これらのオペレーションのパフォーマンスへの影響を確認できます。
CPU 管理
Memorystore は、各ノードの CPU 使用率と接続数に関する指標を提供します。1 つのアベイラビリティ ゾーンの損失が許容されるように、十分なオーバーヘッドを割り当てることをおすすめします。理想的なターゲットはレプリカの数と使用パターンによって異なりますが、レプリカの CPU 使用率を 50% 未満に維持することから始めるのがおすすめです。
クライアントの使用パターンが不均衡な場合、またはフェイルオーバー操作によって接続の分散が不均衡になる場合、個々のノードで高い使用率が発生する可能性があります。このような場合は、Memorystore が自動的に接続を再調整できるように、接続を定期的に閉じることをおすすめします。Memorystore は、開いている接続を再調整しません。
接続バランス管理
ノードの接続を閉じるたびに、クライアントは再接続する必要があります。通常は、選択したクライアント ライブラリで自動再接続を有効にします。ノードが再作成されると、既存の接続は再ルーティングされませんが、新しい接続は新しいノードにルーティングされます。クライアントは定期的に接続を切断して、使用可能なノード間で調整することができます。
レプリケーション ラグの管理
特に書き込みレートが高い場合は、レプリカが遅延する可能性があります。このようなシナリオでは、引き続きレプリカを読み取りに使用できます。このような状況では、レプリカからの読み取りが古くなる可能性があるため、アプリケーションでこれを処理できる必要があるか、高い書き込み速度に対処する必要があります。
次のステップ
- リードレプリカを管理する方法について学習する。
- Redis インスタンスからのデータのエクスポートについて学習する。
- Memorystore for Redis の高可用性について学習する。