このチュートリアルでは、スケジュールされたオートスケーラーを Google Kubernetes Engine(GKE)にデプロイして、コストを削減する方法について説明します。このタイプのオートスケーラーは、時間帯や曜日に基づいてクラスタを増減します。スケジュールされたオートスケーラーは、トラフィックに予測可能な増減がある場合に役立ちます。たとえば、地域の小売業者の場合や、勤務時間が 1 日の特定の時間に制限されている従業員向けのソフトウェアを使用している場合などが該当します。
このチュートリアルは、トラフィックが急増する前にクラスタを確実にスケールアップし、夜間や週末など、オンライン ユーザーが少ない時間にクラスタを再度スケールダウンしてコストを節約しようとしているデベロッパーとオペレーターを対象としています。この記事は、Docker、Kubernetes、Kubernetes CronJob、GKE、Linux を理解していることを前提としています。
はじめに
多くのアプリケーションにおいてトラフィックは均一にはなりません。たとえば、組織の従業員によるアプリケーションの操作は日中に限られます。そのため、そのアプリケーションのデータセンター サーバーは夜間にアイドル状態になります。
Google Cloud には、他のメリットに加え、トラフィックの負荷に応じてインフラストラクチャを動的に割り当ててコストを節約する機能があります。単純な自動スケーリングを構成するだけで、不均一なトラフィックに対する割り当てという難問を管理できる場合があります。それに該当する場合は、その方針を継続してください。その他の場合、つまり、トラフィック パターンが急激に変化する場合、スケールアップ時のシステムの不安定性とクラスタのオーバープロビジョニングを回避するため、自動スケーリングの構成をより精密に調整する必要があります。
このチュートリアルは、トラフィック パターンの急激な変化が十分に理解され、オートスケーラーがインフラストラクチャでトラフィックの急激な変化が発生する兆しを捕捉するヒントを与えるというシナリオにもとづいています。このドキュメントでは、GKE クラスタを朝にスケールアップし、夜にスケールダウンする方法を説明します。同様の方法を使用して、ピークスケール イベント、広告キャンペーン、週末トラフィックなどの、既知のイベントの処理能力を増減できます。
確約利用割引利用時にクラスタをスケールダウンする
このチュートリアルでは、オフピーク時に GKE クラスタを最小限までスケールダウンしてコストを削減する方法について説明します。ただし、確約利用割引を購入している場合は、割引が自動スケーリングと連動して機能する仕組みを理解しておくことが重要です。
確約利用割引では、一定量のリソース(vCPU、メモリなど)の支払いを確約すると、大幅な割引価格が適用されます。ただし、確約するリソース量を決定するには、ワークロードが時間の経過とともに使用するリソースの量を事前に把握する必要があります。コスト削減に役立つよう、次の図に計画に含めるべきリソースと含めるべきではないリソースを示します。

図に示すように、確約利用契約の下ではリソース割り当てがフラットになっています。確約を価値あるものとするには、確約割引の対象となるリソースがほぼ常時使用されている必要があります。したがって、確約するリソースの計算にはトラフィックが急激に変化したときに使用されるリソースを含めないようにします。不安定なリソースの場合は、GKE オートスケーラー オプションを使用することをおすすめします。これらのオプションには、このドキュメントで説明しているスケジュールされたオートスケーラーや他のマネージド オプション(GKE でコスト最適化 Kubernetes アプリケーションを実行するためのベスト プラクティスで説明)が含まれます。
指定した量のリソースに対してすでに使用契約を結んでいる場合は、クラスタを契約の最小値未満にスケールダウンしてもコストは削減できません。こうしたシナリオでは、一部のジョブをスケジュールしてコンピューティング需要が低い時期のギャップを埋めることをおすすめします。
アーキテクチャ
このチュートリアルでデプロイするインフラストラクチャとスケジュールされたオートスケーラーのアーキテクチャを、次の図に示します。スケジュールされたオートスケーラーは、相互に連携してスケジュールに基づいてスケーリングを管理する一連のコンポーネントで構成されています。

このアーキテクチャでは、一連の Kubernetes CronJob によってトラフィック パターンに関する既知の情報が Cloud Monitoring カスタム指標にエクスポートされます。このデータは、HPA がワークロードをスケーリングするタイミングを知らせる入力として、Kubernetes HorizontalPodAutoscaler(HPA)によって読み取られます。HPA は、ターゲット CPU 使用率などの他の負荷指標とともに、特定のデプロイでレプリカをスケーリングする方法を決定します。
環境を準備する
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Cloud Shell で、 Google Cloud プロジェクト ID、メールアドレス、コンピューティング ゾーンとリージョンを構成します。
PROJECT_ID=YOUR_PROJECT_ID ALERT_EMAIL=YOUR_EMAIL_ADDRESS gcloud config set project $PROJECT_ID gcloud config set compute/region us-central1 gcloud config set compute/zone us-central1-f次のように置き換えます。
YOUR_PROJECT_ID: 使用しているプロジェクトの Google Cloud プロジェクト名。YOUR_EMAIL_ADDRESS: スケジュールされたオートスケーラーが正常に機能していない場合に通知を受け取るメールアドレス。
必要に応じて、このチュートリアルに別のリージョンとゾーンを選択できます。
kubernetes-engine-samplesGitHub リポジトリのクローンを作成します。git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples/ cd kubernetes-engine-samples/cost-optimization/gke-scheduled-autoscalerこの例のコードは、次のフォルダに構成されています。
- ルート: CronJob がカスタム指標を Cloud Monitoring にエクスポートするときに使用するコードが含まれます。
k8s/: Kubernetes HPA のデプロイメント サンプルが含まれます。k8s/scheduled-autoscaler/: カスタム指標から読み込むカスタム指標と HPA の更新版をエクスポートする CronJob が含まれます。k8s/load-generator/: 1 時間ごとの使用量をシミュレートするアプリケーションを持つ Kubernetes Deployment が含まれます。Deployment は、クラスタ内のノードに分散された Pod の複数のレプリカを実行できる Kubernetes API オブジェクトです。monitoring/: このチュートリアルで構成する Cloud Monitoring コンポーネントが含まれます。
Cloud Shell で、スケジュールされたオートスケーラーを実行する GKE クラスタを作成します。
gcloud container clusters create scheduled-autoscaler \ --enable-ip-alias \ --release-channel=stable \ --machine-type=e2-standard-2 \ --enable-autoscaling --min-nodes=1 --max-nodes=10 \ --num-nodes=1 \ --autoscaling-profile=optimize-utilization出力は次のようになります。
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS scheduled-autoscaler us-central1-f 1.22.15-gke.100 34.69.187.253 e2-standard-2 1.22.15-gke.100 1 RUNNINGこれは本番環境用の構成ではありませんが、このチュートリアルには適した構成です。この設定では、最小 1 ノード、最大 10 ノードでクラスタ オートスケーラーを構成します。また、
optimize-utilizationプロファイルを有効にすると、スケールダウン プロセスを高速化できます。スケジュールされたオートスケーラーを使用せずにサンプル アプリケーションをデプロイします。
kubectl apply -f ./k8sk8s/hpa-example.yamlファイルを開きます。次に、ファイルの内容を示します。
レプリカの最小数(
minReplicas)が 10 に設定されていることに注目してください。この構成では、CPU 使用率(name: cpuとtype: Utilizationの設定)に基づいてスケーリングするクラスタも設定されます。アプリケーションが利用可能になるまで待ちます。
kubectl wait --for=condition=available --timeout=600s deployment/php-apache EXTERNAL_IP='' while [ -z $EXTERNAL_IP ] do EXTERNAL_IP=$(kubectl get svc php-apache -o jsonpath={.status.loadBalancer.ingress[0].ip}) [ -z $EXTERNAL_IP ] && sleep 10 done curl -w '\n' http://$EXTERNAL_IPアプリケーションが利用可能になると、出力は次のようになります。
OK!設定を確認します。
kubectl get hpa php-apache出力は次のようになります。
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 9%/60% 10 20 10 6d19hREPLICAS列には、hpa-example.yamlファイルのminReplicasフィールドの値と一致する10が表示されます。ノード数が 4 に増加したかどうかを確認します。
kubectl get nodes出力は次のようになります。
NAME STATUS ROLES AGE VERSION gke-scheduled-autoscaler-default-pool-64c02c0b-9kbt Ready <none> 21S v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-ghfr Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-gvl9 Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-t9sr Ready <none> 21s v1.17.9-gke.1504クラスタを作成する際に、
min-nodes=1フラグを使用して最小構成を設定します。ただし、この手順の前半でデプロイしたアプリケーションは、インフラストラクチャの追加を要求しています。これは、hpa-example.yamlファイルのminReplicasが 10 に設定されているためです。minReplicasを 10 のような値に設定することは、営業日の最初の数時間にトラフィックの急増が予想される小売業者などの企業で行われるよくある手法です。ただし、HPAminReplicasの値を高く設定すると、アプリケーション トラフィックが少ない夜間でもクラスタ トラフィックが縮小せずコストが増加することがあります。Cloud Shell で、GKE クラスタにカスタム指標 - Cloud Monitoring アダプタをインストールします。
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml kubectl wait --for=condition=available --timeout=600s deployment/custom-metrics-stackdriver-adapter -n custom-metricsこのアダプタは、Cloud Monitoring カスタム指標に基づいて Pod の自動スケーリングを有効にします。
Artifact Registry にリポジトリを作成し、読み取り権限を付与します。
gcloud artifacts repositories create gke-scheduled-autoscaler \ --repository-format=docker --location=us-central1 gcloud auth configure-docker us-central1-docker.pkg.dev gcloud artifacts repositories add-iam-policy-binding gke-scheduled-autoscaler \ --location=us-central1 --member=allUsers --role=roles/artifactregistry.readerカスタム指標エクスポータのコードをビルドして push します。
docker build -t us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporter . docker push us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporterカスタム指標をエクスポートする CronJob をデプロイし、次のカスタム指標から読み取れる HPA の更新バージョンをデプロイします。
sed -i.bak s/PROJECT_ID/$PROJECT_ID/g ./k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml kubectl apply -f ./k8s/scheduled-autoscalerk8s/scheduled-autoscaler/scheduled-autoscale-example.yamlファイルを開いて確認します。次に、ファイルの内容を示します。
この構成では、CronJob は、その時間帯の推奨 Pod レプリカ数を
custom.googleapis.com/scheduled_autoscaler_exampleというカスタム指標にエクスポートします。このチュートリアルのモニタリング セクションを簡略化するため、スケジュール フィールドの構成では、1 時間ごとにスケールアップとスケールダウンを繰り返すように定義します。本番環境では、ビジネスニーズに合わせてこのスケジュールをカスタマイズできます。k8s/scheduled-autoscaler/hpa-example.yamlファイルを開いて確認します。ファイルの内容は次のとおりです。
この構成では、以前にデプロイした HPA を HPA オブジェクトで置き換えるよう指定します。この構成によって、
minReplicasの値が 1 に減ります。つまり、ワークロードは最小にスケールダウンできます。この構成では、外部指標(type: External)も追加されます。また、自動スケーリングは 2 つの要素によってトリガーされます。この複数指標のシナリオでは、HPA は各指標に対して提案されたレプリカ数を計算し、最も大きな値を返す指標を選択します。ここで、スケジュール済みオートスケーラーは特定の時点で Pod 数が 1 になるように提案できることを理解することが重要です。ただし、1 つの Pod の実際の CPU 使用率が予想より高くなる場合、HPA は複数のレプリカを作成します。
次のコマンドを再び実行して、ノード数と HPA レプリカをもう一度確認してください。
kubectl get nodes kubectl get hpa php-apache表示される出力は、スケジュールされたオートスケーラーの直近の動作に左右されます。特に、
minReplicasとnodesの値はスケーリング サイクル内の各ポイントで異なります。たとえば、各 1 時間の 51 分から 60 分の間(トラフィックがピークの期間)は、
minReplicasの HPA 値は 10、nodesの値は 4 になります。これに対し、1 分から 50 分の間(トラフィックが少ない期間)は、HPA
minReplicas値が 1 になり、nodes値は 1 または 2 になります(どちらになるかは割り当てられ削除された Pod の数に依存します)。低い値(1 分から 50 分まで)の場合、クラスタのスケールダウンが完了するまでに 10 分ほどかかる場合があります。Cloud Shell で、通知チャネルを作成します。
gcloud beta monitoring channels create \ --display-name="Scheduled Autoscaler team (Primary)" \ --description="Primary contact method for the Scheduled Autoscaler team lead" \ --type=email \ --channel-labels=email_address=${ALERT_EMAIL}出力は次のようになります。
Created notification channel NOTIFICATION_CHANNEL_ID.チュートリアルのステップを簡略化するため、このコマンドはタイプ
emailの通知チャネルを作成します。本番環境では、通知チャネルをsmsまたはpagerdutyに設定することにより、非同期の程度がより低い方法を使用することをおすすめします。NOTIFICATION_CHANNEL_IDプレースホルダに表示された値を含む変数を設定します。NOTIFICATION_CHANNEL_ID=NOTIFICATION_CHANNEL_IDアラート ポリシーをデプロイします。
gcloud alpha monitoring policies create \ --policy-from-file=./monitoring/alert-policy.yaml \ --notification-channels=$NOTIFICATION_CHANNEL_IDalert-policy.yamlファイルには、5 分経過しても指標が存在しない場合にアラートを送信する仕様が含まれています。Cloud Monitoring の [アラート] ページに移動して、アラート ポリシーを表示します。
スケジュールされたオートスケーラー ポリシーをクリックして、アラート ポリシーの詳細を確認します。
Cloud Shell で、負荷生成ツールをデプロイします。
kubectl apply -f ./k8s/load-generator次のリスティングは
load-generatorスクリプトを示しています。command: ["/bin/sh", "-c"] args: - while true; do RESP=$(wget -q -O- http://php-apache.default.svc.cluster.local); echo "$(date +%H)=$RESP"; sleep $(date +%H | awk '{ print "s("$0"/3*a(1))*0.5+0.5" }' | bc -l); done;このスクリプトは、
load-generatorデプロイを削除するまでクラスタで実行されます。これは、数ミリ秒ごとにphp-apacheサービスへのリクエストを行います。sleepコマンドは、1 日の中での負荷分散の変化をシミュレートします。このようにトラフィックを生成するスクリプトを使用することで、HPA 構成で CPU 使用率とカスタム指標を組み合わせるとどうなるかがわかります。Cloud Shell で新しいダッシュボードを作成します。
gcloud monitoring dashboards create \ --config-from-file=./monitoring/dashboard.yamlCloud Monitoring の [ダッシュボード] ページに移動します。
スケジュールされたオートスケーラー ダッシュボードをクリックします。
ダッシュボードには 3 つのグラフが表示されます。スケールアップとスケールダウンの動きを確認し、また 1 日の負荷の分散の違いが自動スケーリングに与える影響を確認するには、少なくとも 2 時間(理想的には 24 時間以上)待機する必要があります。
グラフに表示される内容を理解するには、終日ビューを表示する以下のグラフを検討してください。
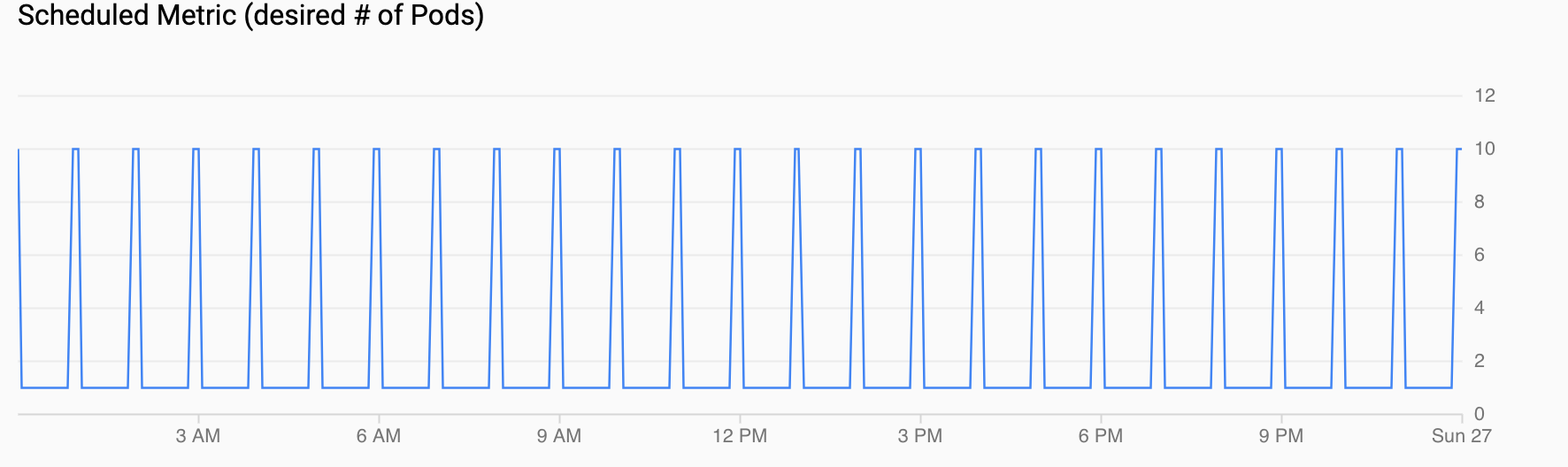
スケジュールされた指標(必要な Pod 数): スケジュールされたオートスケーラーの設定で構成した CronJob によって Cloud Monitoring にエクスポートされる時系列のカスタム指標を示します。
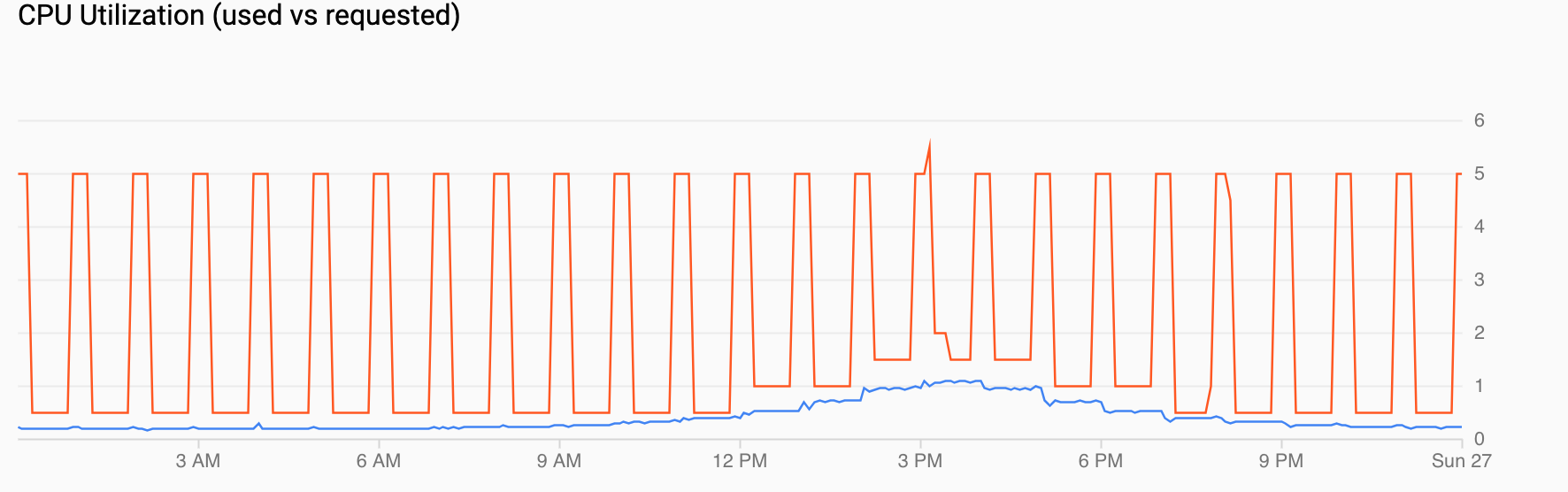
CPU 使用率(要求と実使用): リクエストされた CPU(赤)と実際の CPU 使用率(青色)を示します。負荷が低い場合、HPA はスケジュールされたオートスケーラーによる使用率の決定に従います。ただし、トラフィックが増加すると、午後 12 時から午後 6 時までのデータポイントが示すように、HPA は必要に応じて Pod の数を増やします。
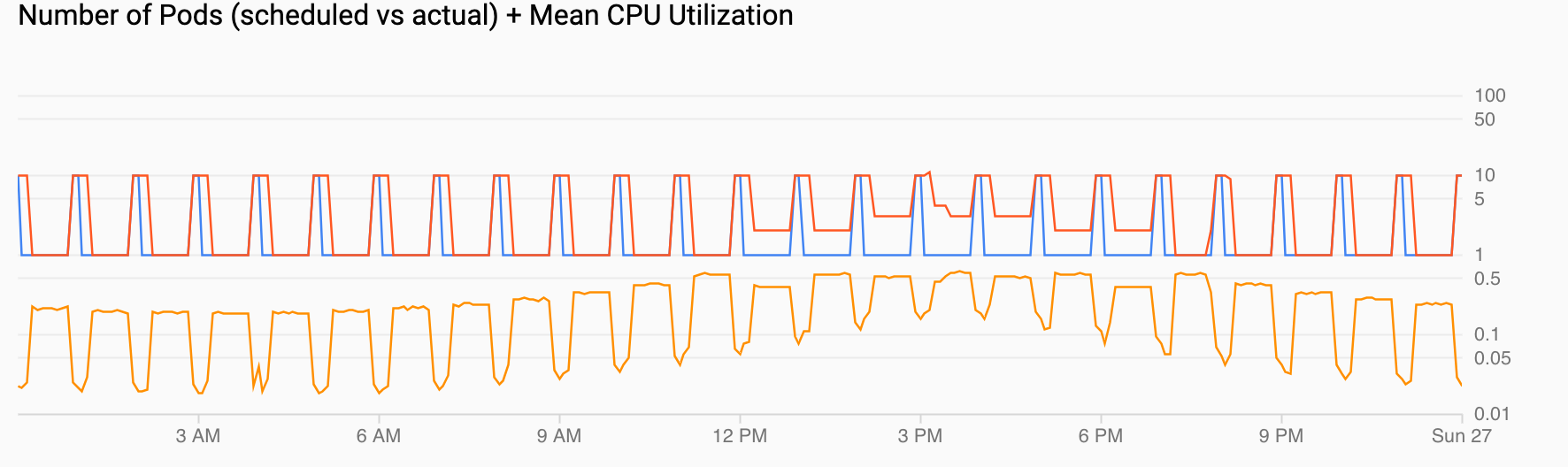
Pod 数(予定と実際)+ 平均 CPU 使用率: 前の Pod と同様のビューが表示されます。Pod 数(赤)は、スケジュール(青)に従い 1 時間ごとに 10 に増加します。Pod 数は、負荷に応じて時間の経過(午後 12 時と午後 6 時)とともに増加し、低下します。平均 CPU 使用率(オレンジ)は、設定した目標(60%)を下回る状態で推移します。
GKE クラスタを作成する
サンプル アプリケーションをデプロイする
スケジュールされたオートスケーラーを設定する
スケジュールされたオートスケーラーが正常に動作しない場合にアラートを構成する
本番環境では、CronJob がカスタム指標にデータを入力していない場合、それを把握する必要が生じることがよくあります。この目的のために、custom.googleapis.com/scheduled_autoscaler_example ストリームが 5 分間なければトリガーされるアラートを作成できます。
サンプル アプリケーションへの負荷を生成する
トラフィックまたはスケジュールされた指標に応じてスケーリングを可視化する
このセクションでは、スケールアップとスケールダウンの影響を示す可視化をレビューします。