Solo puedes usar la caché de datos con clústeres estándar de GKE. En esta guía se explica cómo habilitar GKE Data Cache al crear un clúster GKE Standard o un grupo de nodos, y cómo aprovisionar discos adjuntos de GKE con aceleración de Data Cache.
Acerca de GKE Data Cache
Con GKE Data Cache, puedes usar SSDs locales en tus nodos de GKE como capa de caché para tu almacenamiento persistente, como discos persistentes o hiperdiscos. El uso de SSDs locales reduce la latencia de lectura del disco y aumenta las consultas por segundo (QPS) de tus cargas de trabajo con estado, al tiempo que minimiza los requisitos de memoria. GKE Data Cache admite todos los tipos de Persistent Disk o Hyperdisk como discos de almacenamiento.
Para usar GKE Data Cache en tu aplicación, configura tu grupo de nodos de GKE con SSDs locales conectados. Puedes configurar GKE Data Cache para que use todo o parte del SSD local conectado. Los SSDs locales que usa la solución de caché de datos de GKE están cifrados en reposo mediante el cifrado estándar Google Cloud .
Ventajas
GKE Data Cache ofrece las siguientes ventajas:
- Aumento de la tasa de consultas gestionadas por segundo para bases de datos convencionales, como MySQL o Postgres, y bases de datos vectoriales.
- Mejora el rendimiento de lectura de las aplicaciones con estado minimizando la latencia del disco.
- La hidratación y la rehidratación de datos son más rápidas porque las unidades SSD son locales del nodo. La hidratación de datos es el proceso inicial de carga de los datos necesarios desde el almacenamiento persistente en el SSD local. La rehidratación de datos es el proceso de restaurar los datos de las unidades SSD locales después de que se haya reciclado un nodo.
Arquitectura de despliegue
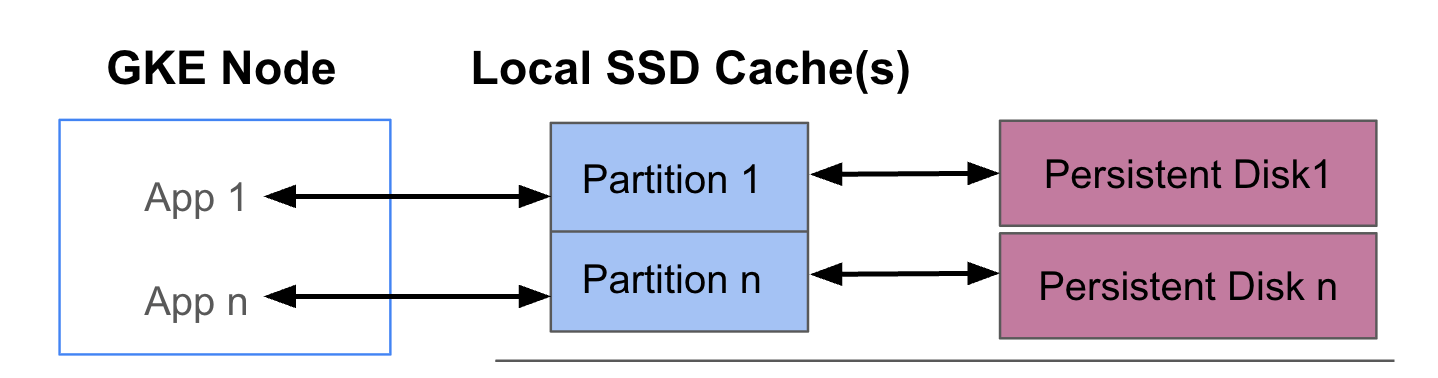
En el siguiente diagrama se muestra un ejemplo de una configuración de GKE Data Cache con dos pods que ejecutan una aplicación cada uno. Los pods se ejecutan en el mismo nodo de GKE. Cada pod usa un SSD local y un disco persistente de respaldo independientes.
Modos de implementación
Puedes configurar GKE Data Cache de dos formas:
- Escritura simultánea (opción recomendada): cuando tu aplicación escribe datos, estos se escriben de forma síncrona tanto en la caché como en el disco persistente subyacente. El modo
writethroughevita la pérdida de datos y es adecuado para la mayoría de las cargas de trabajo de producción. - Escritura diferida: cuando tu aplicación escribe datos, estos se escriben solo en la caché. A continuación, los datos se escriben en el disco persistente de forma asíncrona (en segundo plano). El modo
writebackmejora el rendimiento de escritura y es adecuado para cargas de trabajo que dependen de la velocidad. Sin embargo, este modo afecta a la fiabilidad. Si el nodo se cierra de forma inesperada, se perderán los datos de la caché que no se hayan vaciado.
Objetivos
En esta guía, aprenderás a hacer lo siguiente:
- Crea una infraestructura de GKE subyacente para usar GKE Data Cache.
- Crea un grupo de nodos dedicado con SSDs locales adjuntos.
- Crea una StorageClass para aprovisionar de forma dinámica un PersistentVolume (PV) cuando un pod lo solicite a través de un PersistentVolumeClaim (PVC).
- Crea un PVC para solicitar un PV.
- Crea un Deployment que use un PVC para asegurarte de que tu aplicación tenga acceso al almacenamiento persistente incluso después de que se reinicie un pod y durante la reprogramación.
Requisitos y planificación
Asegúrate de que cumples los siguientes requisitos para usar GKE Data Cache:
- Tu clúster de GKE debe tener la versión 1.32.3-gke.1440000 o una posterior.
- Tus grupos de nodos deben usar tipos de máquinas que admitan SSDs locales. Para obtener más información, consulta Asistencia para la serie de máquinas.
Planificación
Ten en cuenta estos aspectos al planificar la capacidad de almacenamiento de GKE Data Cache:
- Número máximo de pods por nodo que usarán GKE Data Cache simultáneamente.
- Los requisitos de tamaño de caché previstos de los pods que usarán GKE Data Cache.
- La capacidad total de los SSD locales disponibles en los nodos de GKE. Para obtener información sobre los tipos de máquinas que tienen SSDs locales conectadas de forma predeterminada y los tipos de máquinas que requieren que conectes SSDs locales, consulta Elegir un número válido de discos SSD locales.
- En el caso de los tipos de máquinas de tercera generación o posteriores (que tienen un número predeterminado de unidades SSD locales conectadas), ten en cuenta que las unidades SSD locales de la caché de datos se reservan del total de unidades SSD locales disponibles en esa máquina.
- La sobrecarga del sistema de archivos que puede reducir el espacio disponible en los SSD locales. Por ejemplo, aunque tengas un nodo con dos SSDs locales con una capacidad bruta total de 750 GiB, el espacio disponible para todos los volúmenes de caché de datos puede ser inferior debido a la sobrecarga del sistema de archivos. Parte de la capacidad de los SSD locales se reserva para el uso del sistema.
Limitaciones
Incompatibilidad con Copia de seguridad de GKE
Para mantener la integridad de los datos en situaciones como la recuperación tras un desastre o la migración de aplicaciones, es posible que tengas que crear copias de seguridad de tus datos y restaurarlos. Si usas Copia de seguridad de GKE para restaurar un PVC configurado para usar Data Cache, el proceso de restauración fallará. Este error se produce porque el proceso de restauración no propaga correctamente los parámetros de caché de datos necesarios de la StorageClass original.
Precios
Se te facturará la capacidad total aprovisionada de tus unidades SSD locales y los discos persistentes conectados. Se te cobra por cada GiB al mes.
Para obtener más información, consulta la sección Precios de los discos de la documentación de Compute Engine.
Antes de empezar
Antes de empezar, asegúrate de que has realizado las siguientes tareas:
- Habilita la API de Google Kubernetes Engine. Habilitar la API de Google Kubernetes Engine
- Si quieres usar Google Cloud CLI para esta tarea, instálala y, a continuación, inicialízala. Si ya has instalado la CLI de gcloud, obtén la versión más reciente ejecutando el comando
gcloud components update. Es posible que las versiones anteriores de la interfaz de línea de comandos de gcloud no admitan la ejecución de los comandos de este documento.
- Consulta los tipos de máquina que admiten SSDs locales para tu grupo de nodos.
Configurar nodos de GKE para usar la caché de datos
Para empezar a usar GKE Data Cache para acelerar el almacenamiento, tus nodos deben tener los recursos de SSD local necesarios. En esta sección se muestran los comandos para aprovisionar SSDs locales y habilitar GKE Data Cache cuando creas un clúster de GKE o añades un grupo de nodos a un clúster. No puedes actualizar un grupo de nodos para que use Data Cache. Si quieres usar la caché de datos en un clúster, añade un nuevo grupo de nodos al clúster.
En un clúster nuevo
Para crear un clúster de GKE con la caché de datos configurada, usa el siguiente comando:
gcloud container clusters create CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Haz los cambios siguientes:
CLUSTER_NAME: el nombre del clúster. Proporciona un nombre único para el clúster de GKE que vas a crear.LOCATION: la Google Cloud región o zona del nuevo clúster.MACHINE_TYPE: el tipo de máquina que se va a usar de una serie de máquinas de segunda, tercera o generaciones posteriores para tu clúster, comon2-standard-2oc3-standard-4-lssd. Este campo es obligatorio porque el SSD local no se puede usar con el tipoe2-mediumpredeterminado. Para obtener más información, consulta las series de máquinas disponibles.DATA_CACHE_COUNT: número de volúmenes SSD locales que se van a dedicar exclusivamente a la caché de datos en cada nodo del grupo de nodos predeterminado. Cada uno de estos SSD locales tiene una capacidad de 375 GiB. El número máximo de volúmenes varía según el tipo de máquina y la región. Ten en cuenta que parte de la capacidad de los SSD locales se reserva para el uso del sistema.(Opcional)
LOCAL_SSD_COUNT: número de volúmenes de SSD local que se van a aprovisionar para otras necesidades de almacenamiento efímero. Usa la marca--ephemeral-storage-local-ssd countsi quieres aprovisionar SSDs locales adicionales que no se usen para la caché de datos.Tenga en cuenta lo siguiente para los tipos de máquinas de tercera generación o posteriores:
- Los tipos de máquinas de tercera generación o posteriores tienen un número específico de SSDs locales conectados de forma predeterminada. El número de SSDs locales que se adjuntan a cada nodo depende del tipo de máquina que especifiques.
- Si tienes previsto usar la marca
--ephemeral-storage-local-ssd countpara obtener almacenamiento efímero adicional, asegúrate de asignar aDATA_CACHE_COUNTun valor inferior al total de discos SSD locales disponibles en la máquina. El número total de SSDs locales disponibles incluye los discos adjuntos predeterminados y los discos nuevos que añadas con la marca--ephemeral-storage-local-ssd count.
Este comando crea un clúster de GKE que se ejecuta en un tipo de máquina de segunda, tercera o posterior generación para su grupo de nodos predeterminado, aprovisiona SSDs locales para la caché de datos y, opcionalmente, aprovisiona SSDs locales adicionales para otras necesidades de almacenamiento efímero, si se especifica.
Estos ajustes solo se aplican al grupo de nodos predeterminado.
En un clúster
Para usar la caché de datos en un clúster, debes crear un grupo de nodos con la caché de datos configurada.
Para crear un grupo de nodos de GKE con la caché de datos configurada, usa el siguiente comando:
gcloud container node-pool create NODE_POOL_NAME \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Haz los cambios siguientes:
NODE_POOL_NAME: el nombre del grupo de nodos. Asigna un nombre único al grupo de nodos que vas a crear.CLUSTER_NAME: el nombre de un clúster de GKE donde quieras crear el grupo de nodos.LOCATION: la misma región o zona que tu clúster. Google CloudMACHINE_TYPE: el tipo de máquina que se va a usar de una serie de máquinas de segunda, tercera o generaciones posteriores para tu clúster, comon2-standard-2oc3-standard-4-lssd. Este campo es obligatorio, ya que no se puede usar un SSD local con el tipoe2-mediumpredeterminado. Para obtener más información, consulta las series de máquinas disponibles.DATA_CACHE_COUNT: número de volúmenes SSD locales que se van a dedicar exclusivamente a la caché de datos en cada nodo del pool de nodos. Cada uno de estos SSD locales tiene una capacidad de 375 GiB. El número máximo de volúmenes varía según el tipo de máquina y la región. Ten en cuenta que parte de la capacidad de los SSD locales se reserva para el uso del sistema.(Opcional)
LOCAL_SSD_COUNT: número de volúmenes de SSD local que se van a aprovisionar para otras necesidades de almacenamiento efímero. Usa la marca--ephemeral-storage-local-ssd countsi quieres aprovisionar SSDs locales adicionales que no se usen para la caché de datos.Tenga en cuenta lo siguiente para los tipos de máquinas de tercera generación o posteriores:
- Los tipos de máquinas de tercera generación o posteriores tienen un número específico de SSDs locales conectados de forma predeterminada. El número de SSDs locales que se adjuntan a cada nodo depende del tipo de máquina que especifiques.
- Si tienes previsto usar el indicador
--ephemeral-storage-local-ssd countpara obtener almacenamiento efímero adicional, asegúrate de que el valor deDATA_CACHE_COUNTsea inferior al número total de discos SSD locales disponibles en la máquina. El número total de SSDs locales disponibles incluye los discos adjuntos predeterminados y los discos nuevos que añadas con la marca--ephemeral-storage-local-ssd count.
Este comando crea un grupo de nodos de GKE que se ejecuta en un tipo de máquina de segunda, tercera o posterior generación, aprovisiona SSDs locales para la caché de datos y, opcionalmente, aprovisiona SSDs locales adicionales para otras necesidades de almacenamiento efímero, si se especifica.
Aprovisionar Data Cache para el almacenamiento persistente en GKE
En esta sección se proporciona un ejemplo de cómo habilitar las ventajas de rendimiento de GKE Data Cache en tus aplicaciones con estado.
Crear un grupo de nodos con SSDs locales para la caché de datos
Empieza creando un grupo de nodos con SSDs locales conectados en tu clúster de GKE. GKE Data Cache usa los SSDs locales para acelerar el rendimiento de los discos persistentes conectados.
El siguiente comando crea un grupo de nodos que usa una máquina de segunda generación:
n2-standard-2
gcloud container node-pools create datacache-node-pool \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--num-nodes=2 \
--data-cache-count=1 \
--machine-type=n2-standard-2
Haz los cambios siguientes:
CLUSTER_NAME: el nombre del clúster. Especifica el clúster de GKE en el que vas a crear el nuevo grupo de nodos.LOCATION: la misma región o zona que tu clúster. Google Cloud
Este comando crea un grupo de nodos con las siguientes especificaciones:
--num-nodes=2: define el número inicial de nodos de este grupo en dos.--data-cache-count=1: especifica una SSD local por nodo dedicada a la caché de datos de GKE.
El número total de unidades SSD locales aprovisionadas para este grupo de nodos es dos, ya que cada nodo se aprovisiona con una unidad SSD local.
Crear un DataCache StorageClass
Crea un StorageClass de Kubernetes
que indique a GKE cómo aprovisionar dinámicamente un volumen persistente
que use Data Cache.
Usa el siguiente manifiesto para crear y aplicar un StorageClass llamado pd-balanced-data-cache-sc:
kubectl apply -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: pd-balanced-data-cache-sc
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-balanced
data-cache-mode: writethrough
data-cache-size: "100Gi"
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
EOF
Los parámetros de StorageClassData Cache incluyen los siguientes:
type: especifica el tipo de disco subyacente del volumen persistente. Para ver más opciones, consulta los tipos de disco persistente o los tipos de Hyperdisk admitidos.data-cache-mode: usa el modowritethroughrecomendado. Para obtener más información, consulta Modos de despliegue.data-cache-size: define la capacidad de la SSD local en 100 GiB, que se usa como caché de lectura para cada PVC.
Solicitar almacenamiento con una reclamación de volumen persistente
Crea un PVC que haga referencia a la pd-balanced-data-cache-sc StorageClass que
has creado. La PVC solicita un volumen persistente con la caché de datos habilitada.
Usa el siguiente manifiesto para crear una PVC llamada pvc-data-cache que solicite un volumen persistente de al menos 300 GiB con acceso ReadWriteOnce.
kubectl apply -f - <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-data-cache
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: pd-balanced-data-cache-sc
EOF
Crear un Deployment que use el PVC
Crea un Deployment llamado postgres-data-cache que ejecute un Pod que use el PVC pvc-data-cache que has creado anteriormente. El selector de nodos cloud.google.com/gke-data-cache-count
asegura que el pod se programe en un nodo que tenga los recursos de SSD local
necesarios para usar GKE Data Cache.
Crea y aplica el siguiente manifiesto para configurar un pod que implemente un servidor web de Postgres mediante el PVC:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-data-cache
labels:
name: database
app: data-cache
spec:
replicas: 1
selector:
matchLabels:
service: postgres
app: data-cache
template:
metadata:
labels:
service: postgres
app: data-cache
spec:
nodeSelector:
cloud.google.com/gke-data-cache-disk: "1"
containers:
- name: postgres
image: postgres:14-alpine
volumeMounts:
- name: pvc-data-cache-vol
mountPath: /var/lib/postgresql/data2
subPath: postgres
env:
- name: POSTGRES_USER
value: admin
- name: POSTGRES_PASSWORD
value: password
restartPolicy: Always
volumes:
- name: pvc-data-cache-vol
persistentVolumeClaim:
claimName: pvc-data-cache
EOF
Confirma que el despliegue se ha creado correctamente:
kubectl get deployment
El contenedor de Postgres puede tardar unos minutos en completar el aprovisionamiento y mostrar el estado READY.
Verificar el aprovisionamiento de la caché de datos
Después de crear la implementación, confirma que el almacenamiento persistente con caché de datos se ha aprovisionado correctamente.
Para verificar que tu
pvc-data-cachese ha enlazado correctamente a un volumen persistente, ejecuta el siguiente comando:kubectl get pvc pvc-data-cacheEl resultado debería ser similar al siguiente:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE pvc-data-cache Bound pvc-e9238a16-437e-45d7-ad41-410c400ae018 300Gi RWO pd-balanced-data-cache-sc <unset> 10mPara confirmar que se ha creado el grupo de Logical Volume Manager (LVM) para la caché de datos en el nodo, sigue estos pasos:
Obtén el nombre del pod del controlador PDCSI en ese nodo:
NODE_NAME=$(kubectl get pod --output json | jq '.items[0].spec.nodeName' | sed 's/\"//g') kubectl get po -n kube-system -o wide | grep ^pdcsi-node | grep $NODE_NAMEEn el resultado, copia el nombre del
pdcsi-nodePod.Ver los registros del controlador PDCSI para la creación de grupos LVM:
PDCSI_POD_NAME="PDCSI-NODE_POD_NAME" kubectl logs -n kube-system $PDCSI_POD_NAME gce-pd-driver | grep "Volume group creation"Sustituye
PDCSI-NODE_POD_NAMEpor el nombre del pod que has copiado en el paso anterior.El resultado debería ser similar al siguiente:
Volume group creation succeeded for LVM_GROUP_NAME
Este mensaje confirma que la configuración de LVM para la caché de datos se ha configurado correctamente en el nodo.
Limpieza
Para evitar que se apliquen cargos en tu cuenta de Google Cloud , elimina los recursos de almacenamiento que has creado en esta guía.
Elimina el despliegue.
kubectl delete deployment postgres-data-cacheElimina el PersistentVolumeClaim.
kubectl delete pvc pvc-data-cacheElimina el grupo de nodos.
gcloud container node-pools delete datacache-node-pool \ --cluster CLUSTER_NAMESustituye
CLUSTER_NAMEpor el nombre del clúster en el que has creado el grupo de nodos que usa la caché de datos.
Siguientes pasos
- Consulta Solucionar problemas de almacenamiento en GKE.
- Consulta más información sobre el controlador de CSI para Persistent Disk en GitHub.