Datastream for BigQuery
直接从关系型数据库无缝复制到 BigQuery,可实现近乎实时的运营数据分析。

优势
以尽可能短的延迟时间复制运营数据
将数据从 MySQL、PostgreSQL、AlloyDB、SQL Server 和 Oracle 数据库直接无缝复制到 BigQuery,延迟时间短,并且不影响源性能。
通过无服务器架构扩容和缩容
通过可自动扩缩的无服务器方法消除运维开销,您无需管理基础架构。
在几分钟内快速启动并运行
简化的设置体验使您只需几个步骤即可开始将数据从您的运营数据库复制到 BigQuery。
主要特性
主要特性
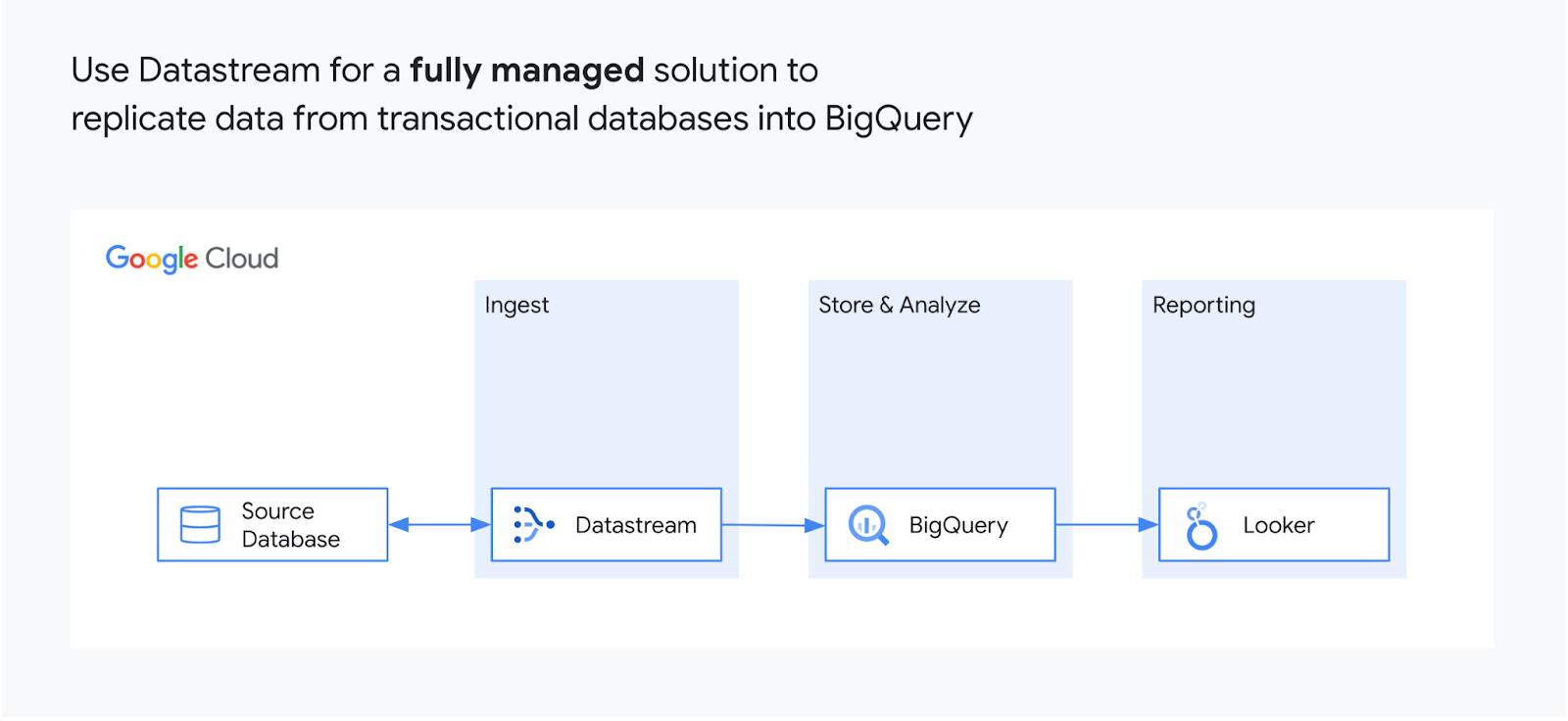
将运营数据复制到 BigQuery
Datastream 使用 BigQuery 的变更数据捕获 (CDC) 功能和 Storage Write API 近乎实时地直接从源系统中高效复制更新。您不再需要将宝贵资源浪费在复杂的数据流水线、自行管理的暂存表、复杂的合并逻辑或手动数据类型转换上的复制解决方案。
设置简单
使用 Datastream,您只需几个步骤即可开始将数据复制到 BigQuery 中。只需在 BigQuery 中配置源数据库、连接类型和目标位置,就大功告成了。Datastream for BigQuery 将回填历史数据,并在出现新更改时持续复制。
从关系型数据库流式传输数据
DataStream 从 MySQL、PostgreSQL、AlloyDB、SQL Server 和 Oracle 数据库读取每个更改(插入、更新和删除)并传送到 BigQuery 中,延迟时间极短。源数据库可以托管在本地、Google Cloud 服务(如 Cloud SQL 或 Oracle 裸金属解决方案)中或任何云环境中的任何其他位置。它是一种无代理的 Google 原生服务,专为 BigQuery 构建,能够可靠地流式传输每个发生的事件。
架构偏移解析
当源架构发生变化时,Datastream 会无缝处理架构偏移,并自动将源中添加的新列和表复制到 BigQuery。
从设计上保证安全
Datastream 支持多种安全的专用连接方法,以保护传输中的数据。静态数据也会加密。

客户
客户使用 Datastream 和 BigQuery 实现实时数据分析


借助 Datastream,我们只需通过这一款工具就能将运营数据无缝、近乎实时地复制到 BigQuery 中。Datastream 帮助我们以更快的速度对运营数据进行分析,提供更稳定的数据产品,并更好地满足我们的业务需求。
René Delgado,Falabella 数据解决方案主管

比较将数据从运营数据库流式插入 BigQuery 的不同方案
Datastream for BigQuery
Datastream 和 Dataflow
Datastream 和 Data Fusion
主要优势
主要优势
将运营数据复制到 BigQuery 的较简单方法
可自动伸缩的无服务器架构
可实现端到端可见性和复制流水线监控的单一界面
可自定义的解决方案,更加灵活
Google 支持的适用于一系列目标的预构建模板
集成数据质量和数据遮盖等其他功能
面向 ETL 开发者和数据分析师的简单界面
提前发现复制中的潜在的问题和缺陷
可近乎实时地了解复制性能
Datastream for BigQuery
主要优势
将运营数据复制到 BigQuery 的较简单方法
可自动伸缩的无服务器架构
可实现端到端可见性和复制流水线监控的单一界面
Datastream 和 Dataflow
主要优势
可自定义的解决方案,更加灵活
Google 支持的适用于一系列目标的预构建模板
集成数据质量和数据遮盖等其他功能
Datastream 和 Data Fusion
主要优势
面向 ETL 开发者和数据分析师的简单界面
提前发现复制中的潜在的问题和缺陷
可近乎实时地了解复制性能


















