在 Datastore 中实现快速可靠的排名
排名:一个简单而又异常棘手的问题
Applibot 的 App Engine 首席工程师 Tomoaki Suzuki(图 1)正在想方设法地解决每个大型游戏服务公司都会面临的一个极为常见而又异常棘手的问题:排名。

Applibot 是日本主要的社交应用提供商之一。该公司的独特之处,是其积累了丰富的知识和经验,在 Google 的平台即服务 (PaaS) 产品 Google App Engine 上构建具有卓越扩缩能力的社交游戏服务。借助该平台的强大功能,Applibot 成功抓住了社交游戏市场(不仅包括日本市场,而且包括美国市场)中的商机。Applibot 无疑取得了成功。Legend of the Cryptids(图 2)是该公司最出名的游戏之一,该款游戏于 2012 年 10 月在 Apple AppStore 北美游戏类别中排名第一。Legend 系列下载量达 470 万次。Gang Road 是该公司另一款著名游戏,在 2012 年 12 月 AppStore 日本总销量排名中名列第一。

这些游戏能够顺畅地进行扩缩,并且能够处理大规模增长的流量。Applibot 不必费力地构建复杂的虚拟服务器集群或分片数据库。他们利用 App Engine 的强大功能,高效地实现了可扩缩性和可用性。
然而,更新玩家排名并不是一个容易解决的问题,对于 Tomoaki 如此,对于任何开发者可能也是如此,尤其是在规模如此之大的情况下。要求很简单:
- 您的游戏拥有数十万(或更多)玩家。
- 每当玩家与敌人战斗(或进行其他活动)时,他们的得分会发生变化。
- 您想要在网站门户页面上显示玩家的最新排名。
如何计算排名?
如果对可扩缩性和速度没有要求的话,那么获取排名很容易。例如,您可以执行以下查询:
SELECT count(key) FROM Players WHERE Score > YourScore
此查询统计所有得分比您高的玩家(图 4)。但是您要对门户页面上的每个请求执行该查询吗?当您有一百万玩家时,这需要多长时间?
Tomoaki 最初实施了这种方法,但获取每个响应均需要几秒钟时间。这种方法速度太慢,成本太高,而且随着规模增加,性能也逐渐变差。
接下来,Tomoaki 尝试在 Memcache 中维护排名数据。虽然速度很快,但不可靠。Memcache 条目可能随时被逐出,并且有时 Memcache 服务本身并不可用。使用仅依赖于内存中键值对的排名服务难以保持一致性和可用性。
Tomoaki 决定降低服务等级,以作为权宜之计。他并没有针对每个请求计算排名,而是建立了一个计划任务,该任务每小时扫描和更新一次每个玩家的排名。通过这种方式,来自门户页的请求可以立即获取玩家排名,但是排名结果可能是一小时之前的排名。
Tomoaki 的最终目标是寻找一种持久、事务性、快速且可扩展的排名实现,它可以每秒接受 300 个得分更新请求,并在数百毫秒内获得每个玩家的排名。为了找到一种解决方案,Tomoaki 向 Kaz Sato 寻求帮助,后者担任 Google Cloud Platform 团队的解决方案架构师 (SA) 兼技术支持客户经理 (TAM),依照高级支持合同被指派给 Applibot。
解决问题的快捷途径
Google Cloud Platform 的许多大客户或合作伙伴(如 Applibot)都签订了一份高级支持合同。该支持合同规定,除云客户服务团队提供全天候支持和云销售团队提供业务支持外,Google 还向每个客户指派一名技术支持客户经理 (TAM)。
TAM 在 Google 工程团队代表客户。Google 工程团队负责构建实际的云端基础架构。TAM 对客户的系统和体系结构有详尽的了解,一旦用户报告重大问题,他们将以 Google 工程团队驻公司代表的身份,运用自己的知识和关系网络来解决问题。TAM 可将问题上报给该团队中的解决方案架构师或 Cloud Platform 团队中的软件工程师。高级支持是借助 Google Cloud Platform 寻找解决方案的快捷通道。
作为向 Applibot 提供支持的 TAM,Kaz 明白排名对于任何可扩展分布式服务都是一个既经典又难以解决的问题。他开始梳理 Google Cloud Datastore 和其他 NoSQL 数据存储区上的已知排名实现,希望能找到满足 Applibot 需求的解决方案。
寻找 O(log n) 算法
简单的查询解决方案需要扫描得分更高的所有玩家来计算某个玩家的排名。此算法的时间复杂度为 O(n);也就是说,执行查询所需的时间与玩家人数成正比。实际上,这意味着该算法无法扩缩。相反,我们需要 O(log n) 或更快的算法;使用此类算法,所需时间只会随着玩家人数的增长而成对数增长。
如果您参加过计算机科学课程,您可能会记得,二叉树、红黑树或 B 树等树算法能够以 O(log n) 时间复杂度执行查找元素。树算法也可用于通过在每个分支节点上保留聚合值来计算计数、最大值/最小值和平均值等一系列元素的聚合值。使用这种方法,可以实现具备 O(log n) 效果的排名算法。
Kaz 找到了一个基于树的排名算法的开放源代码实现:Google Code Jam 排名库,它由 Google 工程师编写,适用于 Datastore。
这个基于 Python 的库公开了两个方法:
SetScore用于设置玩家得分。FindRank用于获取给定得分的排名。
由于玩家/得分对通过 SetScore 方法创建和更新,因此 Code Jam 排名库会构建一个 N 叉树1。例如,我们构建一个可计算得分在 0 - 80 范围内的玩家人数的三叉树(图 5)。该库将包含三个数字的根节点存储为一个实体。每个数字分别对应得分在 0 - 26、27 - 53 和 54 - 80 范围内的玩家人数。根节点针对每个范围都具有一个子节点,依次包含子范围的下一级范围内的玩家对应的三个值。该层次结构需要 4 个级别来存储 81 个不同得分值对应的玩家人数。
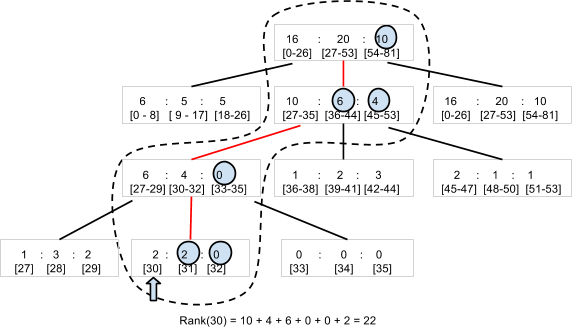
为了确定得分为 30 的玩家的排名,该库只需要读取 4 个实体(图中虚线圈出的节点)来计算得分高于 30 的玩家总数。由于在 4 个实体“右侧”总共有 22 名玩家,因此该玩家排名第 23 位。
同样,调用 SetScore 只需要更新 4 个实体。即使您具有大量不同得分,Datastore 访问也只会按 O(log n) 增加,不受玩家人数的影响。实际上,Code Jam 排名库使用 100(而不是 3)作为每个节点的值的默认数,因此仅需访问 2 个(得分范围大于 10 万时,则为 3 个)实体。
Kaz 使用常用的负载测试工具 Apache JMeter 对 Code Jam 排名库进行负载测试,并证实了该库响应速度很快。通过使用时间复杂度为 O(log n) 的 N 叉树算法,SetScore 和 FindRank 均可在数百毫秒内完成作业。
并发更新限制可扩展性
然而,在负载测试期间,Kaz 发现了 Code Jam 排名库存在一个严重限制。它在更新吞吐量方面的可扩展性非常低。当他将负载增加到每秒三次更新时,该库开始返回事务重试错误。显然,该库无法满足 Applibot 每秒 300 次更新的要求。它大约只能处理该吞吐量的 1%。
为什么?其原因在于保持树的一致性。在 Datastore 中,更新一个事务中的多个实体时,必须使用实体组来确保高度一致性(请参阅利用 Google Cloud Datastore 在高度一致性和最终一致性之间取得平衡)。Code Jam 排名库使用一个实体组保存整个树,以确保树元素中计数的一致性。
但 Datastore 中的实体组具有性能限制。在一个实体组上,Datastore 仅支持每秒大约一个事务。此外,如果在并发事务中修改同一实体组,则可能会失败,因此必须重试。Code Jam 排名库具有高度一致性、事务性并且相当快速,但不支持大量的并发更新。
Datastore 团队的解决方案:作业聚合
Kaz 记得 Datastore 团队的一名软件工程师曾提到一种技术,该技术可在一个实体组上获得比每秒更新一次高得多的吞吐量。这可通过将一批更新集中到一个事务中来实现,而不是将每个更新作为单独的事务来执行。但由于事务包含大量更新,每个事务需要更长的时间,从而增加了并发事务冲突的可能性。
为回应 Kaz 的请求,Datastore 团队开始讨论这个问题,并建议我们考虑使用作业聚合(这是 Megastore 使用的一种设计模式)。
Megastore 是 Datastore 的底层存储层,它管理实体组的一致性和事务性。每秒一次更新的限制源于该层。由于 Megastore 广泛用于各种 Google 服务,工程师一直在收集和共享公司内部的最佳做法和设计模式,以通过该 NoSQL 数据存储区构建可扩展的一致系统。
作业聚合的基本构想是使用单个线程处理批量更新。由于实体组中仅有一个线程并且仅有一个打开的事务,因此并发更新不会导致事务失败。您可以在其他存储产品(例如 VoltDb 和 Redis)中发现类似构想。
但是,作业聚合模式有一个缺点:它只使用一个线程聚合所有更新,这会限制将更新发送到 Datastore 的速度。因此,必须确定作业聚合是否能够满足 Applibot 每秒 300 次更新的吞吐量要求。
通过拉取队列进行作业聚合
根据 Datastore 团队的建议,Kaz 编写了概念验证 (PoC) 代码,用于将作业聚合模式与 Code Jam 排名库相结合。该 PoC 具有以下组件:
- 前端:接受来自用户的
SetScore请求并将它们作为任务添加到拉取队列中。 - 拉取队列:接收并保存来自前端的
SetScore更新请求。 - 后端:使用单线程运行无限循环;该线程从队列中拉取更新请求,并使用 Code Jam 排名库执行请求。
该 PoC 会创建一个拉取队列,这是 App Engine 中的一种任务队列,允许开发者实现一个或多个工作器来处理添加到队列中的任务。后端实例中具有一个处于无限循环的单线程,该线程持续从队列中尽可能多地拉取任务(最高可达 1000 个)。该线程将每个更新请求传递到 Code Jam 排名库,该库在单个事务中批量执行这些请求。事务可能打开一秒钟或更长时间,但由于该库和 Datastore 受单线程驱动,因此不存在争用和并发修改问题。
后端实例被定义为模块,这是 App Engine 的一项功能,使开发者能够定义具有各种特征的应用实例。在此 PoC 中,后端实例被定义为手动缩放实例。在任何特定时间只可运行一个此类实例。
Kaz 使用 JMeter 对该 PoC 进行了负载测试。他证实了此 PoC 每秒能够处理 200 个 SetScore 请求,每个事务的批次可包含 500 到 600 个更新。作业聚合的确有用!
实行队列分片以获得稳定性能
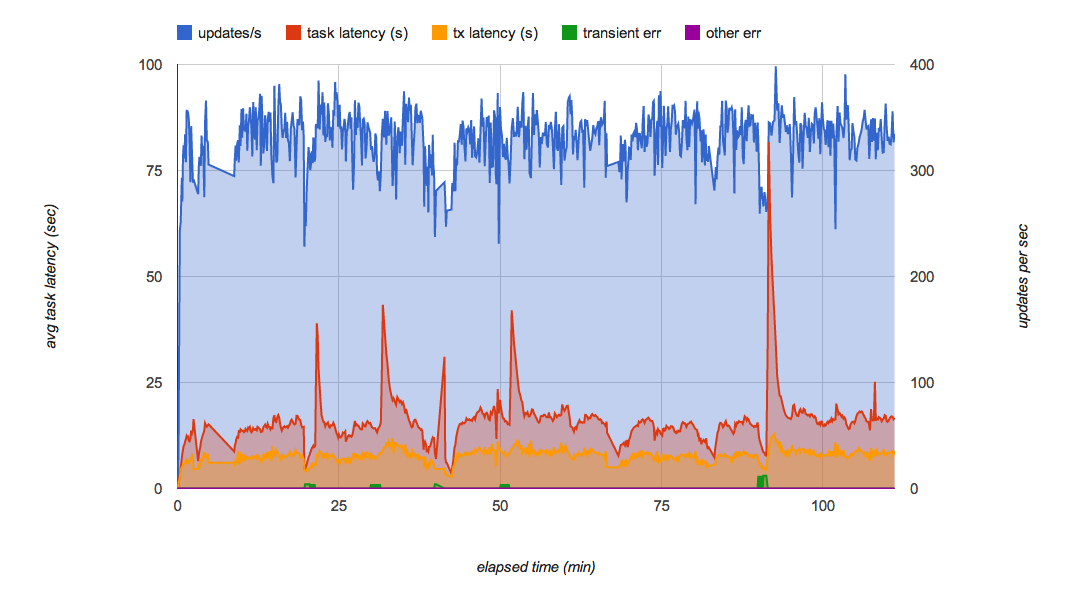
但 Kaz 很快就发现了另一个问题。当他继续运行测试几分钟后,发现拉取队列的吞吐量不时会发生波动(图 6)。尤其是他在几分钟内以每秒 200 个任务不断向队列添加请求时,队列突然停止向后端传递任务,每个任务的延迟都急剧增加。
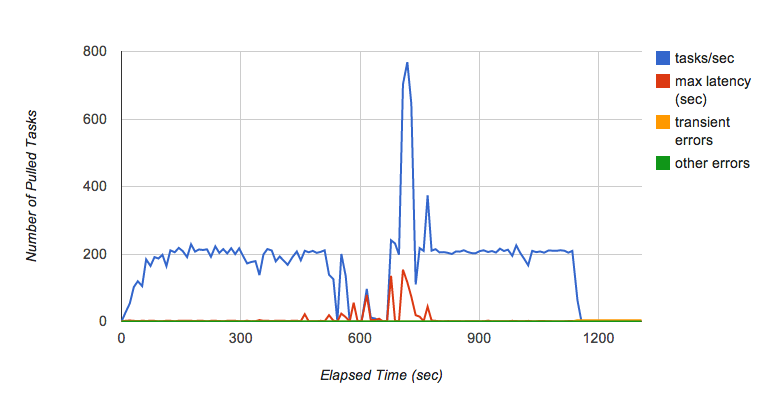
Kaz 向任务队列团队咨询出现这种情况的原因。根据任务队列团队的说法,这是当前拉取队列实现的一个已知行为,该实现依赖于 Bigtable 作为其永久层。当一个 Bigtable 片增加到一定程度时,就会分成多个片。该片在拆分时会停止传递任务,这导致了队列在高速接收任务时的性能波动。任务队列团队正在努力改进这些性能特征。
解决方案架构师 Michael Tang 推荐使用队列分片的变通方法。他建议不要仅使用一个队列,而是将负载分配到多个队列中。每个队列都可以存储在不同的 Bigtable 片服务器上,以最大程度地减少片拆分的影响和保持较高的任务处理速度。当一个队列处理拆分时,其他队列将继续工作,而且分片会减少每个队列的负载,因此可降低拆分片发生的频率。
增强的后端实例循环执行以下算法:
- 从 10 个队列获取
SetScore任务。 - 对任务调用
SetScores方法。 - 从队列中删除获取的任务。
在步骤 1 中,每个队列最多提供 1000 个任务,每个任务保存一个玩家名称和一个得分。将所有玩家/得分对聚合到字典中后,步骤 2 将批量更新传递给 Code Jam 排名库的 SetScores 方法,该方法打开一个事务,将更新存储在 Datastore 中。如果执行该方法时没有出现错误,则步骤 3 会从队列中删除获取的任务。
如果循环或后端实例出现错误或意外关停,更新任务会保留在任务队列中,以便在实例重启时得到处理。在生产系统中,您可能会让另一个后端充当处于备用模式的监视者,在第一个实例出现故障时准备进行接替。
建议解决方案:保持每秒运行 300 次更新2
图 7 显示了使用队列分区的最终 PoC 实现的负载测试结果。它尽可能有效地减少了队列中的性能波动,并且可在数小时内保持每秒 300 次更新。在通常的负载下,每次更新在接收请求后几秒钟内会应用到 Datastore。
此解决方案符合 Applibot 的所有原始要求:
- 具备可扩展性,以处理数以万计的玩家。
- 具备持续性和一致性(因为所有更新均在 Datastore 事务中执行)。
- 足够快速,每秒可处理 300 次更新。
Kaz 将该解决方案与负载测试结果和 PoC 代码一并提交给了 Tomoaki 和其他 Applibot 工程师。Tomoaki 计划将该解决方案整合到他们的生产系统中,期望将排名信息更新的延迟从一小时缩短到数秒钟,并希望能够显著改善用户体验。
使用作业聚合的排名树总结
上述建议的解决方案具有若干优点和一个缺点:
优点:
- 快速:
FindRank调用仅需数百毫秒或更少时间。 - 快速:
SetScore只调度一个任务,后端在几秒钟内处理该任务。 - 在 Datastore 中具备高度一致性和持久性。
- 排名准确。
- 可扩展至任意数量的玩家。
缺点:
- 吞吐量存在限制(目前的实现约为 300 次更新/秒)。
由于此解决方案使用作业聚合模式,因此它依赖单线程来聚合所有更新。若要借助当前 App Engine 实例的 CPU 能力和 Datastore 性能实现高于 300 次更新/秒的吞吐量,则需要额外工作或复杂度。
通过分片树实现可扩展性更高的解决方案
如果需要更高的更新速率,您可能需要对排名树进行分片。您可以创建上述系统的多个实现,即创建一组队列,每个队列均驱动一个后端模块以更新自己的排名树。
一般来说,无需对树进行协调。在最简单的情况下,每个 SetScore 更新被随机调度到一个队列中。借助三个此类型的树(每个树具有自己的 Datastore 实体组和后端服务区),预期更新吞吐量将提高三倍。但不足之处在于,FindRank 必须查询每个排名树以获得某个得分的排名,然后对每个树的排名求和以找到实际排名,这将需要稍微多一点的时间。将实体保留在 Memcache 中可以大幅减少 FindRank 的查询时间。
这与使用分片计数器这种常见方法类似:每个计数器均独立递增,并且只有在客户端需要时才会计算总和。
例如,如果使用三个树,FindRank(865) 会发现 3 个排名:124、183 和 156。这三个数字分别表示每个树中得分高于 865 的个数。得分高于 865 的总个数计算出来为 124 + 183 + 156 = 463。
虽然这种方法不适用于所有类型的分布式算法,但是由于排名从根本上而言是交换性计数问题,所以它应适用于大量排名的问题。
通过近似方法实现可扩展性更高的解决方案
如果应用对可扩展性的要求高于准确性,且可接受一定程度的不准确性或近似值,您可选择使用随机方法,例如:
- 具有全局查询的区段
- 有损计数法
- 节俭型流式传输
这些近似方法均衍生自同一种理念:如何通过在一定程度上降低排名准确性来压缩排名信息的存储空间?
具有全局查询的区段是由 Datastore 团队和 TAM Alex Amies 提出的一种替代解决方案。Alex 基于 Datastore 团队的想法实施了一个 PoC,并进行了广泛的性能分析。他证实了,具有全局查询的区段是一种可扩缩的排名解决方案,其排名准确性降低程度最小,可适用于吞吐量要求高于 Code Jam 排名库的应用。如需了解详细说明和测试结果,请参阅附录。
有损计数法和节俭型流式传输即所谓的在线算法和流式传输算法。通过这些算法,您可以利用内存中极少的存储空间,根据大量玩家/得分对来计算排名靠前者的随机估计值。这些算法适用于需要极低延迟和超高带宽(例如,每秒数千次更新)的应用,排名结果的准确性和覆盖率更为有限。例如,如果您希望有一个实时信息中心可以显示输入到社交网络流中的前 100 个关键字,这些算法很有用处。
总结
如果您要求算法可扩缩、一致并且快速,则排名是一个既经典又难以解决的问题。在本文中,我们介绍了 Google TAM 如何与客户和 Google 工程团队紧密合作,克服困难,提供一种可将排名更新延迟从一小时减少到几秒的解决方案。在需要每秒数百次更新和高度一致性的其他基于 Datastore 的系统设计中,此过程中发现的设计模式(作业聚合与队列分片)也可以应用于一些常见问题。
注意
- Code Jam 排名库使用一个名为“分支因子”的参数来指定每个实体拥有的得分个数。默认情况下,该库使用 100 作为参数。在这种情况下,从 0 到 9999 的得分将作为根节点的子节点存储在 100 个实体上。如果需要处理更宽范围的得分,则可以将分支因子更改为一个更大的值,从而优化实体访问的数量。
- 本文描述的任何性能数据均为仅供参考的采样值,并不保证 App Engine、Datastore 或其他服务的绝对性能。
附录:具有全局查询的区段解决方案
正如如何获取排名部分所述,为每个排名请求查询数据库的成本很高。此替代方法会定期获取所有得分的计数,计算选定得分的排名,并提供这些数据点以用于计算特定玩家的排名。得分的总范围划分为若干个“区段”。每个区段包含得分的子范围以及得分在该子范围的玩家人数。通过该数据,可找到任意得分的排名的近似值。这些存储分区与排名树中的顶级节点相似,但这种算法仅在一个存储分区内插值,而不是细化到更为详细的节点。
用户从前端检索排名与在后端存储分区上计算排名相分离,从而最大程度减少查找排名所需的时间。在请求某位玩家的排名时,将基于该玩家的得分找到对应的存储分区。该存储分区包含排名上限和该存储分区内的玩家计数。在存储分区内使用线性插值法估算存储分区内玩家的排名。在测试中,我们能够稳定地在 400 毫秒内实现一次完整的 HTTP 往返,获取玩家的排名。FindRank 方法的费用与玩家人数无关。
计算给定得分的排名
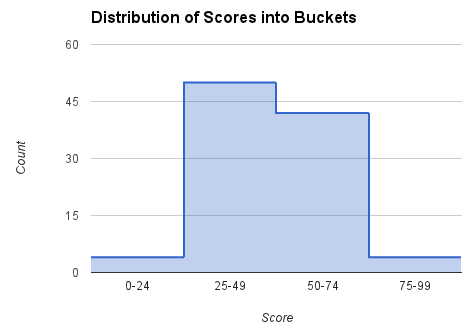
系统会记录每个区段的计数和最高排名(即此区段中可能的最高排名)。对于区段中介于最低得分和最高得分之间的得分,我们使用线性插值法估算排名。例如,如果玩家得分为 60,那么我们就来查看 [50, 74] 这个范围,通过以下公式,使用计数(该范围内玩家/得分个数)(42) 和最高排名 (5) 来计算该玩家的排名:
rank = 5 + (74 - 60)*42/(74 - 50) = 30
计算每个存储分区的计数和范围
在后台,使用 Cron 作业或任务队列,通过循环访问所有存储分区,计算并保存每个存储分区的计数。我们将此称为“全局查询”,因为它通过检查所有玩家的得分来计算估算排名所需的参数。利用 [low_score, high_score] 范围内的得分为每个区段执行此操作的示例 Python 代码如下所示。
next_upper_rank = 1 for b in buckets: count = GetCountInRange(b.low_score, b.high_score) b.count = count b.upper_rank = next_upper_rank b.put() next_upper_rank += count
GetCountInRange() 方法计算区段中得分在此范围内的所有玩家的人数。由于 Datastore 维持玩家得分的排序索引,因此可以高效地计算出该计数。
如果需要查找特定玩家的排名,我们可以使用如下所示的代码。
b = GetBucketByScore(score) rank = RankInBucket(b, score) return rank + b.upper_rank - 1
GetBucketByScore(score) 方法检索包含给定得分的区段。RankInBucket() 方法估算区段内的排名。玩家的排名为该区段内最高排名与包含该玩家得分的特定区段内的排名之和。我们需要从结果中减去 1,因为最大存储分区的排名上限为 1,特定存储分区内排名最高的玩家的排名也为 1。
存储分区会同时存储到 Datastore 和 Memcache。计算排名时,从 Memcache(如果 Memcache 缺失数据则从 Datastore )读取存储分区。在我们自己实现此算法的过程中,我们使用了 Python NDB 客户端库。该客户端库使用 Memcache 缓存 Datastore 中存储的数据。
由于使用了存储分区(或其他方法)来紧凑地表示数据,因此产生的排名并非准确值。存储分区内的排名通过线性插值法近似计算得出。可使用其他更为准确的插值法(例如回归公式)来获取存储分区内更接近的近似值。
成本
查找排名和更新玩家得分的成本均为 O(1);也就是说,成本与玩家人数无关。
全局查询作业的成本为 O(玩家数)× 缓存更新的频率。
后端作业中计算存储分区数据的成本也与存储分区数有关,因为会对每个存储分区执行计数查询。虽然计数查询经优化后使用仅限于键的查询,但即使如此,仍然必须检索完整键列表。
优点
此方法可非常快速地更新玩家得分和找到得分对应的排名。虽然结果基于后台作业,但如果玩家得分发生变化,排名也会立即反映相应趋势的变化。这是由于在存储分区内使用了插值法。
由于计算存储分区的最高排名是通过计划作业在后台完成的,因此无需保持存储分区数据同步即可更新玩家得分。所以此方法不会对更新玩家得分的吞吐量造成限制。
缺点
需要考虑计算所有玩家得分个数、计算全局排名和更新区段所需的时间。在我们的测试中,如果有一千万名玩家,则 App Engine 上的测试系统耗时 8 分 34 秒。虽然这比计算每个玩家的排名需要的几个小时要少,但它只能在每个区段内对得分进行近似计算。相反,树算法每隔几秒以递增方式计算“区段范围”(树的顶端节点),但实现复杂度更大、吞吐量受限程度更高。
在所有情况下,FindRank 所需的时间还取决于从 Memcache 中检索数据(区段或树节点)的速度。如果数据已从 Memcache 中逐出,则必须从 Datastore 中重新获取并重新缓存,以用于后续的 FindRank 请求。
准确性
存储分区方法的准确性取决于存储分区数、玩家排名和得分分布。图 9 显示了排名估算的准确性与不同区段数之间的关系的研究结果。
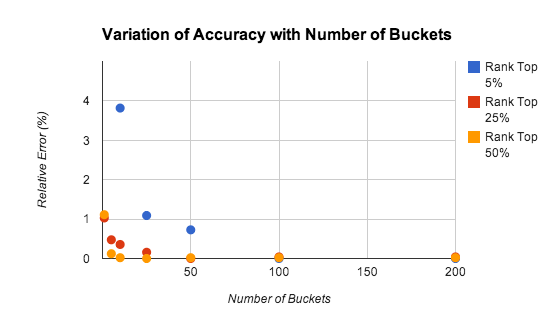
测试对象为 1 万名玩家,其得分在 [0-9999] 范围内均匀分布。即使只有 5 个存储分区,相对误差也在 1% 左右。
排名较高的玩家,准确性反而较低,主要是因为在只考虑高得分时,大数法则并不适用。在很多情况下,建议使用更为精确的算法来计算前一千或两千名玩家的排名。由于需要追踪的玩家人数更少,更新的聚合速率也相应更低,因此显著降低了问题的复杂性。
上述测试使用均匀分布的随机数字,其中累积分布函数呈线性,因而有助于在区段内使用线性插值法,但是区段内的该插值法也非常适合用于任何密集分布的得分。图 10 显示了得分的估算排名和实际排名近似于正态分布。
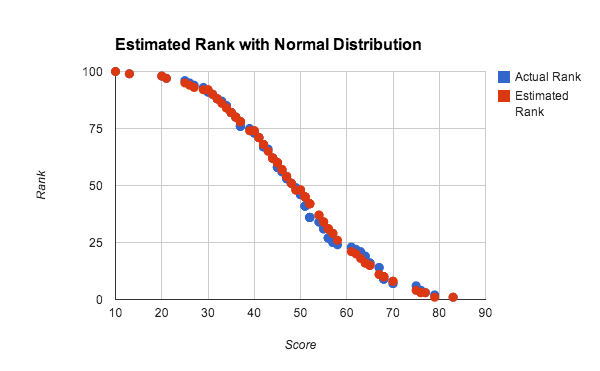
本实验中,使用了 100 位玩家人数来测试小规模数据集的准确性。通过计算 0 到 100 之间的 4 个随机数字的平均值生成每个得分,其近似为得分的正态分布。通过在 10 个存储分区上结合使用全局查询方法和线性插值法计算出估算排名。可以看出,即使对于非常小的数据集和非均匀分布,结果也非常理想。