Schnelles und zuverlässiges Ranking in Datastore
Bewertung: Ein einfaches und doch kompliziertes Problem
Tomoaki Suzuki (Abbildung 1) ist App Engine Lead Engineer bei Applibot. Er versucht, das sehr häufige und schwierige Problem zu lösen, dem jeder große Spieledienst gegenübersteht: Ranking.

Applibot ist einer der wichtigen Anbieter von sozialen Netzwerken in Japan. Das Unternehmen zeichnet sich durch umfassendes Wissen und umfassende Erfahrung beim Erstellen von hoch skalierbaren Spielediensten in Google App Engine aus, dem PaaS-Angebot (Platform as a Service) von Google. Durch Nutzung der Leistung der Plattform konnte Applibot erfolgreich Geschäftschancen im Markt für Spieledienste für soziale Netzwerke erschließen, nicht nur in Japan, sondern auch in den USA. Applibot kann seinen Erfolg wahrlich belegen. Einer der größten Titel, "Legend of the Cryptids" (Abbildung 2), stand in der Apple AppStore North America-Spielekategorie im Oktober 2012 auf Platz 1. Die Legend-Serie verzeichnete 4,7 Millionen Downloads. Ein weiterer Titel, Gang Road, stand im Gesamtumsatz-Ranking vom AppStore Japan im Dezember 2012 ebenfalls auf Platz 1.

Diese Titel konnten reibungslos skaliert werden und den stark anwachsenden Datenverkehr bewältigen. Applibot musste sich nicht mit dem Erstellen komplexer Cluster mit virtuellen Servern oder fragmentierten Datenbanken abmühen. Mit der Leistung von App Engine konnte das Unternehmen mühelos Skalierbarkeit und Verfügbarkeit erreichen.
Das heutige Spielerranking ist jedoch kein einfach zu lösendes Problem, nicht für Tomoaki, und wahrscheinlich auch für keinen anderen Entwickler, insbesondere in dieser Größenordnung. Die Anforderungen sind einfach:
- Ihr Spiel hat Hunderttausende (oder mehr!) Spieler.
- Immer wenn ein Spieler Feinde bekämpft (oder andere Aktivitäten ausführt), ändert sich sein Score.
- Sie möchten das neueste Ranking für den Spieler auf der Seite eines Webportals anzeigen.
Wie berechne ich einen Rang?

Das Ermitteln eines Rangs ist einfach, wenn dies nicht skalierbar und schnell sein muss. Sie könnten beispielsweise folgende Abfrage ausführen:
SELECT count(key) FROM Players WHERE Score > YourScore
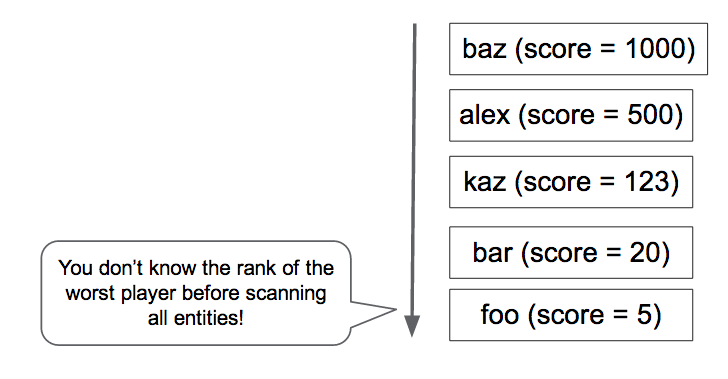
Diese Abfrage zählt alle Spieler, die einen höheren Score als Sie haben (Abbildung 4). Aber möchten Sie diese Abfrage für jede Anfrage von der Portalseite ausführen? Wie lange würde dies bei einer Million Spieler dauern?
Tomoaki hat diese Lösung ursprünglich implementiert, jede Antwort hat jedoch einige Sekunden gedauert. Dies war zu langsam, zu teuer und die Leistung wurde mit wachsenden Spielerzahlen immer schlechter.
Als Nächstes hat Tomoaki versucht, Rankingdaten in Memcache zu verwalten. Das war schnell, jedoch nicht verlässlich. Memcache-Einträge konnten jederzeit entfernt werden, und gelegentlich war der Memcache-Dienst selbst nicht verfügbar. Mit einem Rankingdienst, der ausschließlich von Schlüsselwerten im Speicher abhing, konnten Konsistenz und Verfügbarkeit nur schwer aufrechterhalten werden.
Als temporäre Lösung hat Tomoaki beschlossen, das Service-Level herunterzusetzen. Anstatt den Rang bei jeder Anfrage zu berechnen, hat er eine geplante Aufgabe eingerichtet, die den Rang jedes Spielers einmal pro Stunde scannt und aktualisiert. Auf diese Weise konnten Anfragen von der Portalseite den Rang des Spielers sofort abrufen, wobei dieser jedoch bis zu einer Stunde alt sein konnte.
Letztlich hat Tomoaki nach einer persistenten, transaktionalen, schnellen und skalierbaren Ranking-Implementierung gesucht, die 300 Anforderungen zur Score-Aktualisierung pro Sekunde akzeptieren und einen Rang für jeden Spieler in hundertstel Millisekunden ermitteln konnte. Um eine Lösung zu finden, hat sich Tomoaki an Kaz Sato, einen Solutions Architect (SA) und gleichzeitig Technical Account Manager (TAM) im Google Cloud Platform-Team gewandt, der für Applibot unter einem Premium-Supportvertrag zuständig war.
Probleme besonders schnell lösen
Viele große Kunden oder Partner der Google Cloud Platform, wie Applibot, abonnieren einen Premium-Supportvertrag. Bei diesem Supportvertrag weist Google neben Rund-um-die-Uhr-Support durch das Cloud Customer Support-Team und Business-Support durch das Cloud Sales-Team jedem Kunden einen Technical Account Manager (TAM) zu.
Ein TAM vertritt den Kunden bei Google Engineering, das die eigentliche Cloud-Infrastruktur erstellt. TAMs kennen das System und die Architektur des Kunden im Detail. Sobald bei diesem ein kritischer Fall auftritt, nutzen sie ihr Wissen und Netzwerk als Google Engineering-Vertreter im Unternehmen, um das Problem zu lösen. TAMs können Probleme zu Solutions Architects im Team oder zu Software Engineers im Cloud Platform-Team eskalieren. Der Premium-Support ist der schnellste Weg zu einer Lösung bei der Google Cloud Platform.
Kaz, der TAM für Applibot, wusste, dass Ranking ein klassisches und dennoch schwer zu lösendes Problem für jeden skalierbaren verteilten Dienst war. Er hat zuerst die bekannten Implementierungen für das Ranking in Google Cloud Datastore und anderen NoSQL-Datenspeichern untersucht, um eine Lösung für die Anforderungen von Applibot zu finden.
Suche nach einem O(log n)-Algorithmus
Die einfache Abfragelösung erfordert das Scannen aller Spieler mit einem höheren Score, um den Rang von einem Spieler zu ermitteln. Die Zeitkomplexität dieses Algorithmus ist O(n); d. h. die Zeit zur Ausführung der Abfrage wächst proportional mit der Anzahl von Spielern. In der Praxis bedeutet dies, dass der Algorithmus nicht skalierbar ist. Stattdessen wird ein O(log n)- oder schnellerer Algorithmus benötigt, bei dem die Zeit nur logarithmisch mit der Anzahl von Spielern wächst.
Wenn Sie je einen Informatikkurs besucht haben, erinnern Sie sich vielleicht daran, dass Baumalgorithmen, wie Binärbäume, Rot-Schwarz-Bäume oder B-Bäume ein Element mit O(log n)-Zeitkomplexität finden können. Baumalgorithmen können auch zur Berechnung eines Aggregatwerts für einen Elementbereich verwendet werden, wie Anzahl, Max/Min und Durchschnitt, indem die aggregierten Werte in jedem Zweigknoten gespeichert werden. Mit dieser Technik kann ein Rankingalgorithmus mit O(log n)-Leistung implementiert werden.
Kaz hat eine Open Source-Implementierung eines baumbasierten Rankingalgorithmus für Datastore gefunden, die von einem Google-Techniker geschrieben wurde: die Google Code Jam-Rankingbibliothek.
Diese Python-basierte Bibliothek enthält zwei Methoden:
SetScore, um den Score eines Spielers festzulegen.FindRank, um den Rang für einen bestimmten Score zu berechnen.
Während Spieler/Score-Paare mit der Methode SetScore erstellt und aktualisiert werden, erstellt die Code Jam-Rankingbibliothek einen n-ären Baum1. Beispiel: Lassen Sie uns einen tertiären Baum betrachten, der die Anzahl von Spielern mit Scores im Bereich von 0 bis 80 zählen kann (Abbildung 5). Die Bibliothek speichert den Stammknoten, der drei Zahlen enthält, als eine Entität. Jede Zahl entspricht der Anzahl von Spielern mit Scores in den Unterbereichen 0 – 26, 27 – 53 bzw. 54 – 80. Der Stammknoten verfügt über einen untergeordneten Knoten für jeden Bereich, der wiederum drei Werte für Spieler in den Unterbereichen des Unterbereichs enthält. Die Hierarchie muss vier Ebenen umfassen, um die Anzahl von Spielern für 81 unterschiedliche Scorewerte zu speichern.

Damit die Bibliothek den Rang für einen Spieler mit dem Score 30 feststellen kann, muss sie nur vier Entitäten lesen: die mit der gestrichelten Linie in dem Diagramm eingekreisten Knoten, damit sie die Anzahl von Spielern mit einem höheren Score als 30 addieren kann. Mit 22 Spielern "rechts" in vier Entitäten hat der Spieler den 23. Rang.
Ebenso ist es erforderlich, dass ein Aufruf von SetScore nur vier Entitäten aktualisiert. Selbst bei einer großen Anzahl von unterschiedlichen Scores wird der Datastore-Zugriff nur um O(log n) erhöht und ist von der Anzahl von Spielern nicht betroffen. In der Praxis nutzt die Code Jam-Rankingbibliothek 100 (anstelle von 3) als Standardanzahl von Werten pro Knoten, sodass nur auf zwei (oder drei bei einem Scorebereich von mehr als 100.000) Entitäten zugegriffen werden muss.
Kaz hat das bekannte Belastungstest-Tool Apache JMeter für einen Belastungstest mit der Code Jam-Rankingbibliothek verwendet und bestätigt, dass die Bibliothek schnell reagiert. Sowohl SetScore als auch FindRank können ihre Aufgaben in hundertstel Millisekunden mit dem n-ären Baumalgorithmus ausführen, der mit O(log n)-Zeitkomplexität arbeitet.
Gleichzeitige Updates begrenzen die Skalierbarkeit
Bei Belastungstests hat Kaz eine kritische Begrenzung bei der Code Jam-Rankingbibliothek ermittelt. Ihre Skalierbarkeit bezogen auf den Updatedurchsatz war recht niedrig. Als er die Belastung auf drei Updates pro Sekunde erhöhte, hat die Bibliothek erste Transaktionswiederholungsfehler zurückgegeben. Es war offensichtlich, dass die Bibliothek die Anforderungen von Applibots von 300 Updates pro Sekunde nicht erfüllen konnte. Sie konnte nur etwa 1 % dieses Durchsatzes verarbeiten.
Warum ist das so? Der Grund ist die erforderliche Aufrechterhaltung der Konsistenz des Baums. In Datastore ist eine Entitätengruppe erforderlich, damit beim Aktualisieren mehrerer Entitäten in einer Transaktion strikte Konsistenz erreicht wird. Weitere Informationen dazu finden Sie unter Ausgleich zwischen strikter Konsistenz und Eventual Consistency herstellen. Die Code Jam-Rankingbibliothek verwendet eine einzelne Entitätsgruppe zur Speicherung des ganzen Baums, um die Konsistenz der Werte in den Baumelementen zu gewährleisten.
Eine Entitätengruppe in Datastore hat jedoch eine Leistungsbegrenzung. Datastore unterstützt nur circa eine Transaktion pro Sekunde bei einer Entitätengruppe. Wenn außerdem dieselbe Entitätengruppe in gleichzeitigen Transaktionen geändert wird, schlägt dieser Vorgang wahrscheinlich fehl und muss wiederholt werden. Die Code Jam-Rankingbibliothek ist stark konsistent, transaktional und relativ schnell, unterstützt jedoch kein hohes Volumen an gleichzeitigen Updates.
Lösung des Datastore-Teams: Jobaggregation
Kaz hat sich daran erinnert, dass ein Software Engineer im Datastore-Team eine Technik erwähnt hatte, mit der ein wesentlich höherer Durchsatz als ein Update pro Sekunde bei einer Entitätengruppe erzielt werden kann. Dies konnte durch Zusammenfassung eines Stapels von Updates in einer Transaktion erreicht werden, anstatt jedes Update als separate Transaktion auszuführen. Weil die Transaktion jedoch eine große Anzahl von Updates umfasst, dauert jede Transaktion länger. Dadurch wird ein Konflikt durch gleichzeitige Transaktionen wahrscheinlicher.
Als Reaktion auf die Anfrage von Kaz hat das Datastore-Team sich mit diesem Problem befasst und eine Jobaggregation vorgeschlagen – eines der Designmuster bei Megastore.
Megastore ist die zugrundeliegende Speicherschicht von Datastore. Sie verwaltet Konsistenz und Transaktionalität von Entitätsgruppen. Der Grenzwert von einem Update pro Sekunde stammt aus dieser Schicht. Da Megastore von verschiedenen Google-Diensten intensiv genutzt wird, haben die Engineers Best Practices und Designmuster innerhalb des Unternehmens gesammelt und geteilt, um ein skalierbares und konsistentes System mit diesem NoSQL-Datenspeicher zu erstellen.
Die Grundidee der Jobaggregation ist die Verwendung eines einzelnen Threads zur Verarbeitung eines Stapels von Updates. Weil nur ein Thread vorhanden ist und nur eine Transaktion für die Entitätengruppe geöffnet ist, kommt es wegen gleichzeitiger Updates zu keinen Transaktionsfehlern. Sie können ähnliche Ansätze in anderen Speicherprodukten finden, beispielsweise in VoltDb und Redis.
Es gibt jedoch einen Nachteil bei dem Muster der Jobaggregation: es verwendet nur einen Thread zur Aggregation aller Updates und dies führt zu einer Einschränkung bei der Geschwindigkeit, mit der die Updates an Datastore gesendet werden können. Deshalb musste unbedingt bestimmt werden, ob die Jobaggregation die Anforderung von Applibot für einen Durchsatz von 300 Updates pro Sekunde erfüllen konnte.
Jobaggregation durch Pull-Warteschlange
Aufbauend auf dem Vorschlag des Datastore-Teams hat Kaz einen Machbarkeitsnachweiscode (Proof of Concept, PoC) geschrieben, der das Jobaggregationsmuster mit der Code Jam-Rankingbibliothek kombiniert. Der PoC hat die folgenden Komponenten:
- Front-End: Akzeptiert die
SetScore-Anfragen von Nutzern und fügt sie als Aufgaben in eine Pull-Warteschlange ein. - Pull-Warteschlange: Empfängt und speichert die
SetScore-Aktualisierungsanfragen vom Front-End. - Backend: Führt eine Endlosschleife mit einem einzigen Thread durch, der die Updateanforderungen per Pull-Befehl aus der Warteschlange abruft und sie mit der Code Jam-Rankingbibliothek ausführt.
Der PoC erstellt eine Pull-Warteschlange. Dies ist eine Art Aufgabenwarteschlange in App Engine, mit der Entwickler Worker implementieren können. Worker verarbeiten die Aufgaben, die der Warteschlange hinzugefügt wurden. Die Back-End-Instanz enthält einen einzelnen Thread in einer Endlosschleife, der so viele Aufgaben wie möglich (bis zu 1.000) per Pull-Befehl aus der Warteschlange abruft. Der Thread sendet jede Updateanforderung an die Code Jam-Rankingbibliothek, die sie als Stapel in einer einzigen Transaktion verarbeitet. Die Transaktion kann während einer Sekunde oder länger geöffnet sein, weil jedoch ein einzelner Thread die Bibliothek und Datastore steuert, kommt es zu keinem Konflikt oder Problem wegen gleichzeitiger Änderung.
Die Back-End-Instanz ist als Modul definiert, eine Funktion von App Engine, mit der Entwickler eine Anwendungsinstanz mit verschiedenen Eigenschaften definieren können. In diesem PoC ist die Back-End-Instanz als manuelle Skalierungsinstanz definiert. Es wird immer nur eine derartige Instanz gleichzeitig ausgeführt.
Kaz hat die PoC mit JMeter einem Belastungstest unterzogen. Er hat bestätigt, dass die PoC 200 SetScore-Anforderungen pro Sekunde mit Stapeln von 500 bis 600 Updates pro Transaktion verarbeiten konnte. Die Jobaggregation funktioniert.
Warteschlangenfragmentierung für stabile Leistung
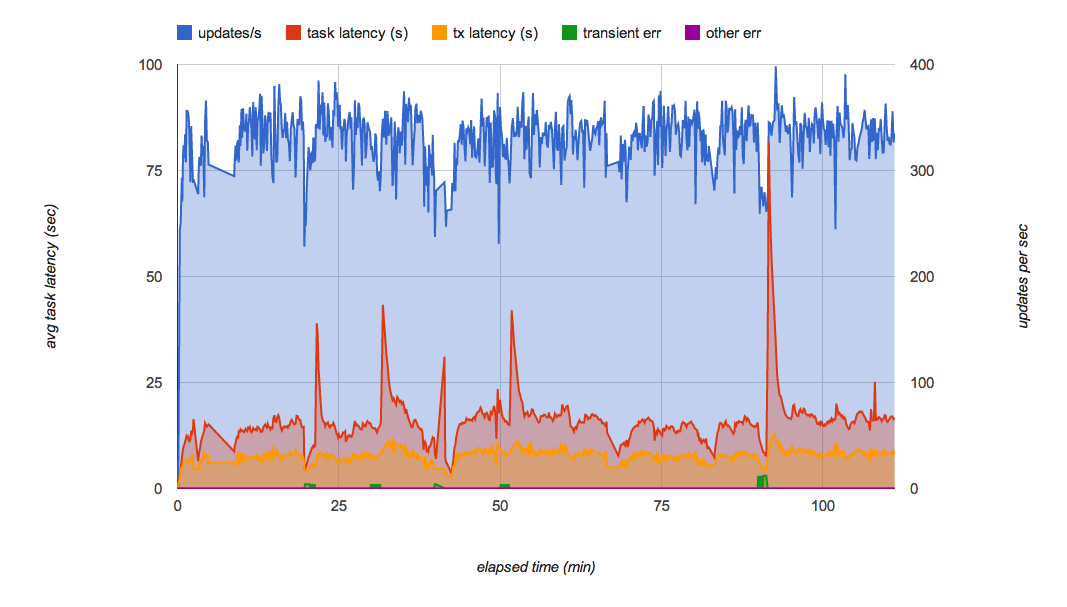
Kaz hat jedoch bald ein anderes Problem gefunden. Während er den Test einige Minuten lang ausgeführt hat, stellte er fest, dass der Durchsatz der Pull-Warteschlange von Zeit zu Zeit schwankte (Abbildung 6). Insbesondere, wenn er über mehrere Minuten hinweg immer wieder weitere Anforderungen mit 200 Aufgaben pro Sekunde der Warteschlange hinzugefügte, sendete die Warteschlange plötzlich keine Aufgaben mehr an das Back-End und die Latenz für jede Aufgabe hat sich deutlich erhöht.

Kaz hat sich mit dem Team der Aufgabenwarteschlange besprochen, um den Grund dafür zu erfahren. Gemäß den Aussagen dieses Teams ist dies ein bekanntes Verhalten bei der aktuellen Pull-Warteschlangenimplementierung, die von Bigtable als deren Persistenzschicht abhängt. Wenn eine Bigtable-Tabellenreihe zu groß wird, wird sie in mehrere Tabellenreihen aufgeteilt. Während die Tabellenreihe aufgeteilt wird, werden keine Aufgaben zugestellt. Dies führt zu der Leistungsschwankung, wenn die Warteschlange eine hohe Anzahl von Aufgaben empfängt. Das Team der Aufgabenwarteschlange arbeitet an der Verbesserung dieser Leistungseigenschaften.
Michael Tang, ein Softwarearchitekt, hat empfohlen, das Problem mit Warteschlangenfragmentierung zu umgehen. Anstatt nur eine Warteschlange zu verwenden, schlug er vor, die Belastung über mehrere Warteschlangen zu verteilen. Jede Warteschlange kann in einem anderen Bigtable-Tabellenreihenserver gespeichert werden, um die Auswirkung der Aufteilung einer Tabellenreihe zu minimieren und eine hohe Aufgabenverarbeitungsrate aufrechtzuerhalten. Während eine Warteschlange eine Aufteilung verarbeitet, arbeiten andere Warteschlangen weiter. Die Aufteilung verringert die Belastung jeder Warteschlange, sodass eine Tabellenreihenaufteilung weniger häufig erforderlich ist.
Die Schleife der erweiterten Back-End-Instanz führt den folgenden Algorithmus aus:
SetScore-Aufgaben aus zehn Warteschlangen freigeben- Die Methode
SetScoresmit den Aufgaben aufrufen - Löschen der freigegebenen Aufgaben aus den Warteschlangen.
In Schritt 1 stellt jede Warteschlange maximal 1.000 Aufgaben bereit, wobei jede Aufgabe einen Spielernamen und einen Score enthält. Nachdem alle Spieler/Score-Paare in einem Wörterbuch aggregiert wurden, wird in Schritt 2 der Stapel Updates an die Methode SetScores der Code Jam-Rankingbibliothek gesendet. Diese öffnet dann eine Transaktion, um sie in Datastore zu speichern. Wenn bei der Ausführung der Methode kein Fehler aufgetreten ist, löscht Schritt 3 die freigegebenen Aufgaben aus den Warteschlangen.
Wenn ein Fehler aufgetreten ist oder die Schleife bzw. die Back-End-Instanz unerwartet heruntergefahren wurde, bleiben die Updateaufgaben in den Aufgabewarteschlangen, sodass sie beim Neustart der Instanz verarbeitet werden können. In einem Produktionssystem könnte ein weiteres Back-End als Watchdog im Standbymodus fungieren, das übernehmen kann, falls die erste Instanz einen Fehler aufweist.
Lösungsvorschlag: Führt kontinuierlich 300 Updates pro Sekunde aus2
In Abbildung 7 wird das Ergebnis des Belastungstests der endgültigen PoC-Implementierung mit Warteschlangenfragmentierung dargestellt. Sie minimiert die Leistungsschwankungen in den Warteschlangen und kann 300 Updates pro Sekunde über mehrere Stunden hinweg kontinuierlich ausführen. Unter normaler Belastung wird jedes Update innerhalb weniger Sekunden nach Empfang der Anforderung auf Datastore angewendet.
Diese Lösung erfüllt alle ursprünglichen Anforderungen von Applibot:
- Skalierbar zur Verarbeitung von Zehntausenden von Spielern.
- Persistent und konsistent, weil alle Updates in Datastore-Transaktionen ausgeführt werden.
- Schnell genug zur Verarbeitung von 300 Updates pro Sekunde.
Mit den Ergebnissen des Belastungstests und dem PoC-Code hat Kaz Tomoaki und anderen Applibot-Technikern die Lösung vorgestellt. Tomoaki plant, die Lösung in das Produktionssystem zu integrieren. Er erwartet, die Latenz bei der Aktualisierung der Rankinginformationen von einer Stunde auf wenige Sekunden zu reduzieren. Damit hofft er, die Nutzererfahrung wesentlich verbessern zu können.
Zusammenfassung von Rankingbaum mit Jobaggregation
Die vorgeschlagene Lösung hat mehrere Vorteile und einen Nachteil:
Vorteile:
- Schnell:
FindRank-Aufruf dauert einige Hundert Millisekunden oder weniger. - Schnell:
SetScoreleitet nur eine Aufgabe weiter, die in wenigen Sekunden vom Back-End verarbeitet wird. - Stark konsistent und in Datastore vorgehalten.
- Die Rankings sind korrekt.
- Skalierbar auf eine beliebige Anzahl von Spielern.
Nachteil:
- Der Durchsatz ist begrenzt (ca. 300 Updates/Sek. bei der aktuellen Implementierung).
Da diese Lösung das Jobaggregationsmuster verwendet, benötigt sie einen einzelnen Thread zur Zusammenfassung aller Updates. Ein höherer Durchsatz als 300 Updates/Sek. mit der aktuellen CPU-Leistung von App Engine-Instanzen und der aktuellen Datastore-Leistung ist nur mit mehr Aufwand und mehr Komplexität zu erreichen.
Skalierbarere Lösung mit fragmentiertem Baum
Wenn Sie eine noch höhere Updaterate benötigen, müssen Sie den Rankingbaum möglicherweise fragmentieren. Dazu würden Sie mehrere Implementierungen des obigen Systems erstellen – eine Reihe von Warteschlangen, die jeweils ein Back-End-Modul steuern, das seinen eigenen Rankingbaum aktualisiert.
Im Allgemeinen ist die Koordination dieser Bäume nicht erforderlich bzw. wird nicht erwartet. Im einfachsten Fall wird jedes SetScore-Update mit dem Zufallsverfahren in eine Warteschlange weitergeleitet. Mit drei solcher Bäume, jeder mit einer eigenen Datastore-Entitätsgruppe und einem eigenen Back-End-Server, wäre der erwartete Updatedurchsatz drei Mal größer. Der Nachteil ist, dass FindRank jeden Rankingbaum abfragen muss, um den Rang eines Scores zu ermitteln. Dann muss der Rang aus jedem Baum summiert werden, um den tatsächlichen Rang zu ermitteln – dies dauert etwas länger. Die Abfragezeit für FindRank kann erheblich verkürzt werden, wenn Entitäten in Memcache verbleiben.
Dies ist der bekannten Lösung von fragmentierten Zählern ähnlich: Jeder Zähler wird unabhängig inkrementiert und die Gesamtsumme wird nur berechnet, wenn sie vom Kunden benötigt wird.
Beispiel: Bei drei Bäumen könnte FindRank(865) die drei Ränge 124, 183 und 156 ermitteln, die angeben, dass jeder Baum die entsprechende Anzahl von Scores über 865 enthält. Die berechnete Gesamtanzahl von Scores, die höher sind als 865, beträgt dann 124 + 183 + 156 = 463.
Diese Lösung funktioniert nicht für alle Arten von verteilten Algorithmen. Weil das Ranking jedoch im Wesentlichen ein kommutatives Zählungsproblem ist, sollte es für ein umfangreiches Ranking geeignet sein.
Skalierbarere Lösungen mit näherungsweisen Ansätzen
Wenn bei Ihrer Anwendung Skalierbarkeit wichtiger ist als Genauigkeit des Rangs und wenn ein gewisser Ungenauigkeitsgrad oder Näherungsgrad toleriert wird, könnten Sie stochastische Lösungen wählen wie:
- Buckets mit globaler Abfrage
- Verlustbehaftete Zählungsmethode
- Einfaches Streaming
Diese näherungsweisen Ansätze sind alles Varianten einer Idee: Wie komprimiere ich den Speicher für Rankinginformationen, indem eine bestimmte Beeinträchtigung der Rankinggenauigkeit toleriert wird?
Buckets mit globaler Abfrage ist eine alternative Lösung, die vom Datastore-Team und dem TAM Alex Amies vorgeschlagen wurde. Alex Amies hat eine PoC basierend auf der Idee des Datastore-Teams implementiert und eine umfassende Leistungsanalyse durchgeführt. Er hat bewiesen, dass "Buckets mit globaler Abfrage" eine skalierbare Rankinglösung mit minimalen Auswirkungen auf die Rankinggenauigkeit ist, und für Anwendungen geeignet sein könnte, die einen höheren Durchsatz als bei der Code Jam-Rankingbibliothek erfordern. Im Anhang finden Sie eine detaillierte Beschreibung und Testergebnisse.
Die verlustbehaftete Zählungsmethode und das einfache Streaming sind sogenannte Online-Algorithmen und Streaming-Algorithmen. Damit können Sie mit sehr wenig internem Speicher eine stochastische Schätzung der Top-Ranker aus einem Stream von Spieler/Score-Paaren berechnen. Diese Algorithmen eignen sich für Anwendungen, die eine sehr geringe Latenz und eine besonders hohe Bandbreite benötigen, wie Tausende von Updates pro Sekunde, mit einer begrenzteren Genauigkeit und Abdeckung von Rankingergebnissen. Beispiel: Wenn Sie ein Echtzeit-Dashboard haben möchten, in dem die 100 wichtigsten Keywords angezeigt werden, die in den Stream eines sozialen Netzwerks eingegeben werden, wären diese Algorithmen geeignet.
Fazit
Ranking ist ein klassisches und dennoch schwer zu lösendes Problem, wenn der Algorithmus skalierbar, konsistent und schnell sein muss. In diesem Artikel haben wir beschrieben, wie die Google TAMs eng mit dem Kunden und den Google Engineering-Teams zusammengearbeitet haben, um sich der Herausforderung zu stellen und eine Lösung zu erarbeiten, mit der die Latenz des Rankingupdates von einer Stunde auf wenige Sekunden reduziert werden kann. Die in dem Prozess ermittelten Designmuster – Jobaggregation und Warteschlangenfragmentierung – könnten auch auf allgemeine Probleme in anderen Datastore-basierten Systementwürfen angewendet werden, die Hunderte von Updates pro Sekunde mit starker Konsistenz erfordern.
Hinweise
- Die Code Jam-Rankingbibliothek verwendet einen Parameter mit der Bezeichnung "Verzweigungsfaktor", mit dem angegeben wird, wie viele Scores jede Entität enthalten wird. Standardmäßig verwendet die Bibliothek 100 als Parameter. In diesem Fall werden Scores im Bereich von 0 bis 9999 in 100 Entitäten als untergeordnete Elemente des Stammknotens gespeichert. Wenn Sie einen breiteren Bereich von Scores verarbeiten müssen, können Sie den Verzweigungsfaktor erhöhen, um die Anzahl von Entitätszugriffen zu optimieren.
- Alle in diesem Artikel beschriebenen Leistungszahlen sind für Referenzzwecke erfasste Werte und stellen keine Gewähr für eine absolute Leistung von App Engine, Datastore oder andere Diensten dar.
Anhang: Lösung – Buckets mit globaler Abfrage
Wie im Abschnitt Rang ermitteln erwähnt, ist die Abfrage der Datenbank für jede Rankinganfrage teuer. Diese Alternativlösung ruft die Anzahl aller Scores in regelmäßigen Abständen ab, berechnet den Rang der ausgewählten Scores und stellt diese Datenpunkte zur Verwendung bei der Berechnung des Rankings bestimmter Spieler bereit. Der Gesamtbereich der Scores wird in "Buckets" unterteilt. Jeder Bucket zeichnet sich durch einen Unterbereich von Scores und der Anzahl von Spielern in diesem Bereich aus. Anhand dieser Daten kann der Rang jedes Scores mit einem guten Näherungswert ermittelt werden. Diese Buckets sind dem Knoten der obersten Ebene in dem Rankingbaum ähnlich. Anstatt jedoch eine Aufgliederung zu detaillierteren Knoten vorzunehmen, interpoliert dieser Algorithmus nur innerhalb eines Buckets.
Das Abrufen des Rangs durch Nutzer von dem Frontend ist von der Berechnung des Rangs in Buckets im Backend entkoppelt, um die Zeit zur Ermittlung eines Rangs zu minimieren. Wenn der Rang eines Spielers angefordert wird, wird das entsprechende Bucket basierend auf dem Score des Spielers ermittelt. Das Bucket umfasst eine obere Ranggrenze und eine Anzahl von Spielern innerhalb des Buckets. Der Rang von Spielern innerhalb von Buckets wird mit linearer Interpolation geschätzt. In unseren Tests konnten wir den Rang eines Spielers konsistent in weniger als 400 Millisekunden für eine vollständige HTTP-Umlaufzeit ermitteln. Die Kosten der Methode FindRank hängen nicht von der Anzahl der Spieler in der Gesamtheit ab.
Rang für einen bestimmten Score berechnen

Die Anzahl und der höchste Rang (d. h. der höchste Rang, der in diesem Bucket möglich ist) werden für jedes Bucket aufgezeichnet. Für Scores zwischen den niedrigen und hohen Scoregrenzen in einem Bucket, verwenden wir die lineare Interpolation zur Schätzung des Rangs. Beispiel: Wenn der Spieler einen Score von 60 hat, prüfen wir den Bucket [50, 74] mit der Zahl (Anzahl von Spielern/Scores im Bucket) (42) und dem höchsten Rang (5), um den Rang des Spielers mit dieser Formel zu berechnen:
rank = 5 + (74 - 60)*42/(74 - 50) = 30
Zahl und Bereich für jedes Bucket berechnen
Im Hintergrund werden die Zahlen für jedes Bucket mit einem Cron-Job oder einer Aufgabenwarteschlange berechnet und gespeichert, indem alle Buckets durchlaufen werden. Dies nennen wir globale Abfrage, weil sie die Parameter berechnet, die zur Schätzung des Rankings erforderlich sind, indem die Scores aller Spieler geprüft werden. Ein Python-Beispielcode für diesen Vorgang mit den Scores im Bereich [low_score, high_score] für jeden Bucket wird unten dargestellt.
next_upper_rank = 1 for b in buckets: count = GetCountInRange(b.low_score, b.high_score) b.count = count b.upper_rank = next_upper_rank b.put() next_upper_rank += count
Die Methode GetCountInRange() zählt jeden Spieler mit Scores in dem Bereich, der vom Bucket abgedeckt wird. Weil Datastore einen sortierten Index für die Spielerscores verwaltet, kann diese Zahl effizient berechnet werden.
Wenn der Rang eines bestimmten Spielers ermittelt werden muss, können wir Code wie unten dargestellt verwenden.
b = GetBucketByScore(score) rank = RankInBucket(b, score) return rank + b.upper_rank - 1
Die Methode GetBucketByScore(score) ruft den Bucket ab, der den angegebenen Score enthält. Die Methode RankInBucket() führt eine Schätzung des Rangs innerhalb des Buckets aus. Der Rang des Spielers besteht aus der Summe des höchsten Rangs des Buckets und dem Rang innerhalb des angegebenen Buckets, das den Score des Spielers einschließt. Wir müssen 1 von dem Ergebnis abziehen, weil der höchste Rang des obersten Buckets 1 ist und der Rang des besten Spielers innerhalb eines bestimmten Buckets ebenfalls 1 ist.
Die Buckets werden sowohl in Datastore als auch in Memcache gespeichert. Zur Berechnung des Rangs lesen Sie Buckets aus Memcache (oder Datastore, wenn Memcache die Daten nicht enthält). In unserer eigenen Implementierung dieses Algorithmus haben wir die Python NDB-Clientbibliothek verwendet, die Memcache verwendet, um Daten im Cache zu speichern, die in Datastore gespeichert sind.
Weil Buckets (oder andere Methoden) zur kompakten Darstellung der Daten verwendet werden, sind die erzeugten Rankings nicht genau. Ränge innerhalb eines Buckets werden mit der linearen Interpolation näherungsweise bestimmt. Andere, genauere Interpolationsmethoden könnten für einen besseren Näherungswert innerhalb des Buckets verwendet werden, wie beispielsweise eine Regressionsformel.
Kosten
Die Kosten zur Ermittlung und Aktualisierung des Scores eines Spielers sind beide O(1), d. h. unabhängig von der Anzahl von Spielern.
Die Kosten des globalen Abfragejobs sind O(Spieler) * Häufigkeit des Cacheupdates.
Die Kosten zur Berechnung der Bucket-Daten in dem Back-End-Job stehen ebenfalls im Zusammenhang mit der Anzahl von Buckets, weil die Abfrage der Zahl für jedes Bucket ausgeführt wird. Die Abfrage der Zahl ist so optimiert, dass eine ausschließlich schlüsselbasierte Abfrage verwendet wird, dennoch muss die vollständige Schlüsselliste abgerufen werden.
Vorteile
Diese Methode ist sehr schnell sowohl bei der Aktualisierung des Scores eines Spielers als auch bei der Ermittlung des Rangs eines Scores. Auch wenn die Ergebnisse auf einem Hintergrundjob basieren, wenn sich der Score eines Spielers ändert, zeigt der Rang eine Änderung in der entsprechenden Richtung sofort an. Dies ist auf die Interpolation innerhalb des Buckets zurückzuführen.
Weil die Berechnung des höchsten Rangs eines Buckets im Hintergrund mit einem geplanten Job ausgeführt wird, können die Scores des Spielers aktualisiert werden, ohne dass die Daten des Buckets synchronisiert werden müssen. Deshalb wird der Durchsatz der Aktualisierung der Scores der Spieler bei dieser Lösung nicht eingeschränkt.
Nachteile
Die Zeit zur Zählung der Scores aller Spieler, zur Berechnung des globalen Rankings und zur Aktualisierung der Buckets muss berücksichtigt werden. In unseren Tests betrug die Zeit bei einer Population von 10 Millionen Spielern bei unserem Testsystem in App Engine 8 Minuten und 34 Sekunden. Dies ist schneller als die Stunden, die es dauern würde, um den Rang jedes Spielers zu berechnen. Der Kompromiss besteht jedoch in den Näherungswerten der Scores innerhalb jedes Buckets. Dagegen berechnet der Baumalgorithmus die "Bucket-Bereiche" (den obersten Knoten des Baums) inkrementell in Abständen von wenigen Sekunden, die Implementierung ist jedoch komplexer und der Durchsatz begrenzt.
In allen Fällen hängt die Zeit für FindRank auch vom schnellen Abruf von Daten (Bucket oder Baumknoten) aus Memcache ab. Wenn die Daten aus Memcache entfernt werden, müssen sie noch einmal aus Datastore abgerufen und für nachfolgende FindRank-Anfragen noch einmal im Cache gespeichert werden.
Genauigkeit
Die Genauigkeit der Bucket-Methode hängt von der Anzahl vorhandener Buckets, vom Rang des Spielers und der Verteilung der Scores ab. In Abbildung 9 werden Ergebnisse unserer Studie zur Genauigkeit der Rangschätzungen mit einer unterschiedlichen Anzahl von Buckets dargestellt.

Es wurden Tests für eine Population von 10.000 Spielern mit gleichmäßig verteilten Scores im Bereich [0–9.999] vorgenommen. Der relative Fehler beträgt ca. 1 %, sogar bei nur 5 Buckets.
Die Genauigkeit fällt bei Spielern mit hohem Ranking ab, im Wesentlichen weil das Gesetz der großen Zahlen nicht greift, wenn nur die höchsten Scores betrachtet werden. In vielen Fällen wird empfohlen, einen genaueren Algorithmus zu verwenden, um das Ranking der ein- oder zweitausend Spieler mit dem höchsten Score zu verwalten. Das Problem wird wesentlich geringer, da nur wenige Spieler verfolgt werden müssen und die zusammengefasste Rate von Updates entsprechend niedriger ist.
In dem obigen Test wird bei Verwendung von gleichmäßig verteilten Zufallszahlen, bei denen die kumulative Verteilungsfunktion linear ist, die lineare Interpolation innerhalb des Buckets bevorzugt. Die Interpolation innerhalb von Buckets funktioniert jedoch bei jeder dichten Verteilung der Scores gut. In Abbildung 10 wird der geschätzte und tatsächliche Rang für eine ungefähr normale Verteilung von Scores dargestellt.
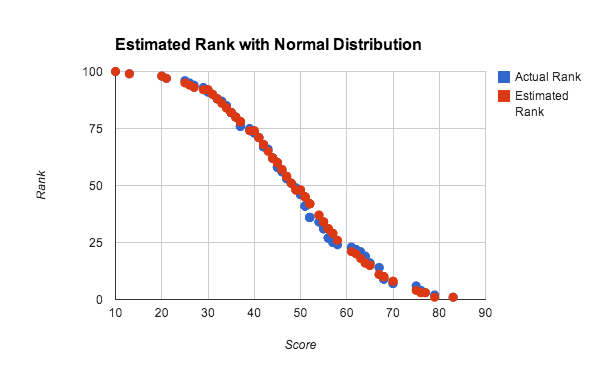
In diesem Experiment wurde eine Population von 100 Spielern verwendet, um die Genauigkeit mit einem kleinen Dataset zu testen. Jeder Score wurde anhand des Durchschnittswertes von vier Zufallszahlen zwischen null und 100 generiert, der etwa eine normale Verteilung von Scores näherungsweise darstellt. Der geschätzte Rang wurde mit der globalen Abfragemethode mit linearer Interpolation mit 10 Buckets berechnet. Dabei kann festgestellt werden, dass die Ergebnisse selbst bei sehr kleinen Datasets und nicht gleichförmigen Verteilungen sehr gut sind.