Antes de comenzar
Si aún no lo hiciste, configura un proyecto Google Cloud y dos (2) buckets de Cloud Storage.
Configura tu proyecto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init - In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
- Crea la plantilla de flujo de trabajo.
gcloud dataproc workflow-templates create wordcount-template \ --region=us-central1
- Agrega el trabajo de conteo de palabras a la plantilla de flujo de trabajo.
-
Especifica tu output-bucket-name antes de ejecutar el comando (tu función proporcionará el bucket de entrada).
Después de insertar el nombre de bucket de salida, este debe leerse de la siguiente manera:
gs://your-output-bucket/wordcount-output". -
El ID del paso "conteo" es obligatorio y, además, identifica el trabajo hadoop agregado.
gcloud dataproc workflow-templates add-job hadoop \ --workflow-template=wordcount-template \ --step-id=count \ --jar=file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ --region=us-central1 \ -- wordcount gs://input-bucket gs://output-bucket-name/wordcount-output
-
Especifica tu output-bucket-name antes de ejecutar el comando (tu función proporcionará el bucket de entrada).
Después de insertar el nombre de bucket de salida, este debe leerse de la siguiente manera:
- Usa un clúster administrado y de un solo nodo para ejecutar el flujo de trabajo. Dataproc creará el clúster, ejecutará el flujo de trabajo en él y, luego, borrará el clúster cuando este se complete.
gcloud dataproc workflow-templates set-managed-cluster wordcount-template \ --cluster-name=wordcount \ --single-node \ --region=us-central1 - Haz clic en el nombre de
wordcount-templateen la página Flujos de trabajo de Dataproc en la consola de Google Cloud para abrir la página Detalles de la plantilla de flujo de trabajo. Confirme los atributos de la plantilla de conteo de palabras.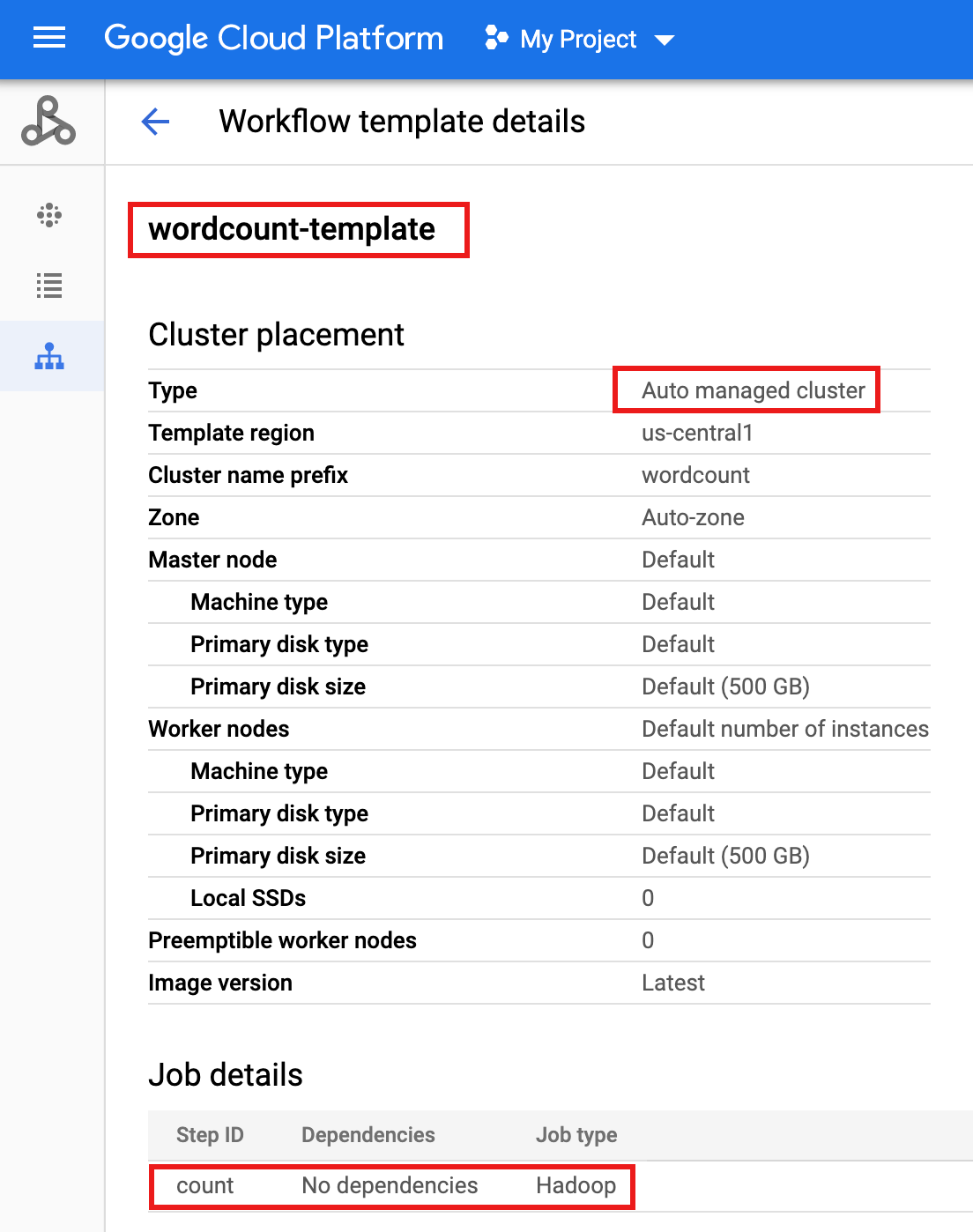
- Exporta la plantilla de flujo de trabajo a un archivo de texto
wordcount.yamlpara la parametrización.gcloud dataproc workflow-templates export wordcount-template \ --destination=wordcount.yaml \ --region=us-central1
- Con un editor de texto, abre
wordcount.yamly, luego, agrega un bloque deparametersal final del archivo YAML para que el INPUT_BUCKET_URI de Cloud Storage se pueda pasar comoargs[1]al conteo de palabras.A continuación, se muestra un ejemplo de un archivo YAML exportado. Puedes implementar uno de estos dos enfoques para actualizar tu plantilla:
- Copia y pega todo el archivo para reemplazar tu
wordcount.yamlexportado después de reemplazar your-output_bucket por el nombre de tu depósito de salida. - Copia y pega solo la sección
parametersal final del archivowordcount.yamlexportado.
jobs: - hadoopJob: args: - wordcount - gs://input-bucket - gs://your-output-bucket/wordcount-output mainJarFileUri: file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar stepId: count placement: managedCluster: clusterName: wordcount config: softwareConfig: properties: dataproc:dataproc.allow.zero.workers: 'true' parameters: - name: INPUT_BUCKET_URI description: wordcount input bucket URI fields: - jobs['count'].hadoopJob.args[1] - Copia y pega todo el archivo para reemplazar tu
- Importa el archivo de texto
wordcount.yamlcon parámetros. Escribe “Y” cuando se te solicite reemplazar la plantilla.gcloud dataproc workflow-templates import wordcount-template \ --source=wordcount.yaml \ --region=us-central1
Abre la página Cloud Run functions en la consola deGoogle Cloud y, luego, haz clic en CREATE FUNCTION.
En la página Crear función, ingresa o selecciona la siguiente información:
- Nombre: Recuento de palabras.
- Memoria asignada: Mantén la selección predeterminada.
- Trigger:
- Cloud Storage
- Tipo de evento: Finalizar/Crear.
- Bucket: Selecciona tu bucket de entrada (consulta Crea un bucket de Cloud Storage en tu proyecto). Cuando se agrega un archivo a este bucket, la función activará el flujo de trabajo. El flujo de trabajo ejecutará la aplicación de recuento de palabras, que procesará todos los archivos de texto en el bucket.
Código de origen:
- Editor directo
- Entorno de ejecución: Node.js 8
- Pestaña
INDEX.JS: Reemplaza el fragmento de código predeterminado por el siguiente código y, luego, edita la líneaconst projectIdpara proporcionar -your-project-id- (sin un "-" al principio ni al final).
const dataproc = require('@google-cloud/dataproc').v1; exports.startWorkflow = (data) => { const projectId = '-your-project-id-' const region = 'us-central1' const workflowTemplate = 'wordcount-template' const client = new dataproc.WorkflowTemplateServiceClient({ apiEndpoint: `${region}-dataproc.googleapis.com`, }); const file = data; console.log("Event: ", file); const inputBucketUri = `gs://${file.bucket}/${file.name}`; const request = { name: client.projectRegionWorkflowTemplatePath(projectId, region, workflowTemplate), parameters: {"INPUT_BUCKET_URI": inputBucketUri} }; client.instantiateWorkflowTemplate(request) .then(responses => { console.log("Launched Dataproc Workflow:", responses[1]); }) .catch(err => { console.error(err); }); };- Pestaña
PACKAGE.JSON: Reemplaza el fragmento de código predeterminado por el siguiente código.
{ "name": "dataproc-workflow", "version": "1.0.0", "dependencies":{ "@google-cloud/dataproc": ">=1.0.0"} }- Función que se ejecutará: Insert: "startWorkflow".
Haga clic en CREAR.
Copia el archivo público
rose.txten tu bucket para activar la función. Inserta your-input-bucket-name (el bucket que se usa para activar la función) en el comando.gcloud storage cp gs://pub/shakespeare/rose.txt gs://your-input-bucket-name
Espera 30 segundos y, luego, ejecuta el siguiente comando para verificar que la función se haya completado correctamente.
gcloud functions logs read wordcount
... Function execution took 1348 ms, finished with status: 'ok'
Para ver los registros de la función desde la página de lista Funciones en la consola de Google Cloud , haz clic en el nombre de la función
wordcounty, luego, en VER REGISTROS en la página Detalles de la función.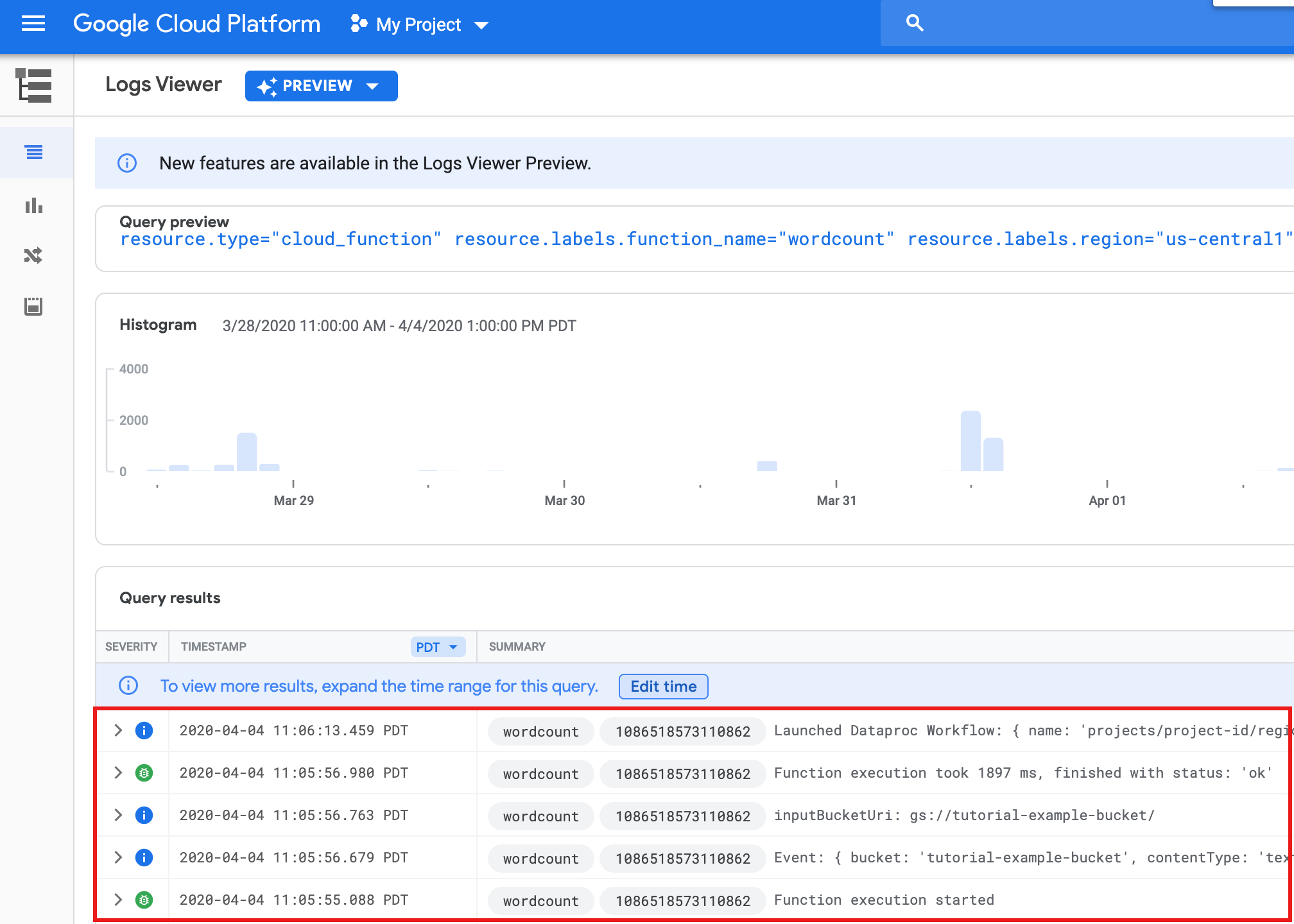
Puedes ver la carpeta
wordcount-outputen tu bucket de salida desde la página Navegador de Storage en la consola deGoogle Cloud .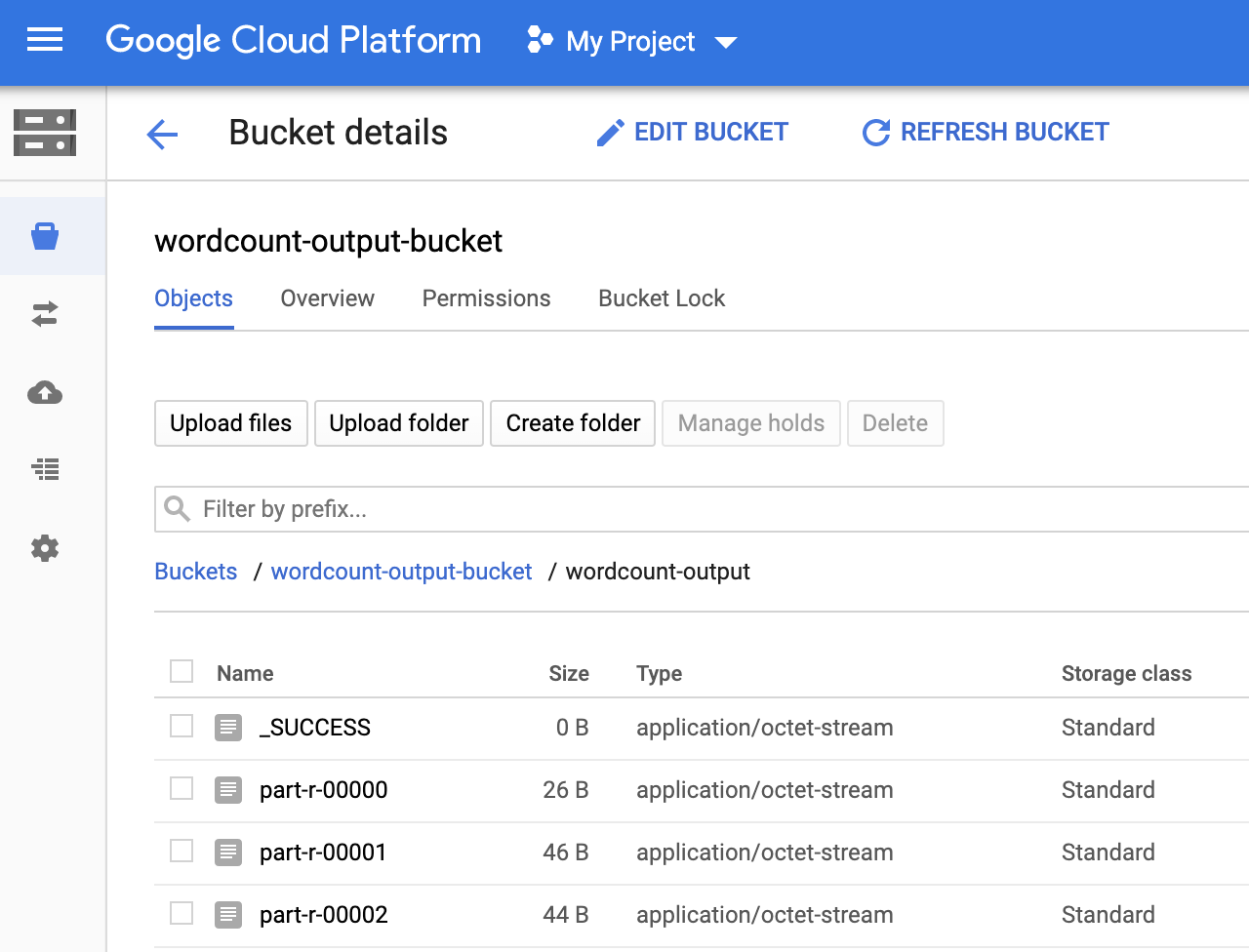
Una vez que se completa el flujo de trabajo, los detalles del trabajo persisten en la consola deGoogle Cloud . Haz clic en el trabajo
count...que aparece en la página Trabajos de Dataproc para ver los detalles del trabajo de flujo de trabajo.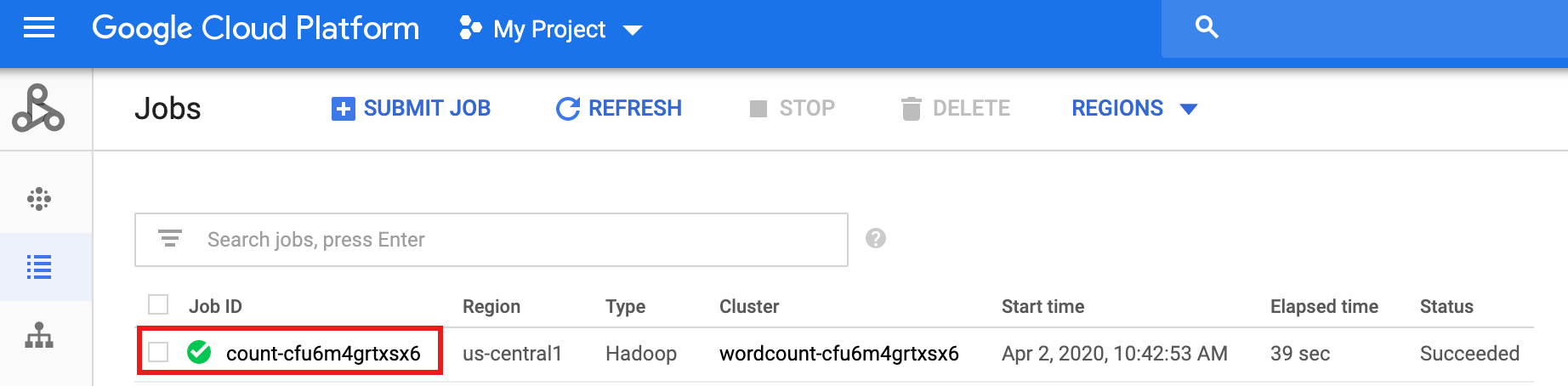
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click the checkbox for the bucket that you want to delete.
- To delete the bucket, click Delete, and then follow the instructions.
- Consulta la Descripción general de las plantillas de flujos de trabajo de Dataproc.
- Consulta Soluciones de programación del flujo de trabajo.
Crea o usa dos buckets de Cloud Storage en tu proyecto.
Necesitarás dos buckets de Cloud Storage en tu proyecto: uno para los archivos de entrada y otro para los de salida.
Crear una plantilla de flujo de trabajo
Para crear y definir una plantilla de flujo de trabajo, copia y ejecuta los siguientes comandos en una ventana de la terminal local o en Cloud Shell.
Parametriza la plantilla de flujo de trabajo
Parametriza la variable del bucket de entrada que se pasará a la plantilla de flujo de trabajo.
Crea una Cloud Function
Prueba la función
Limpia
El flujo de trabajo de este instructivo borra su clúster administrado cuando se completa. Para evitar costos recurrentes, puedes borrar otros recursos asociados con este instructivo.
Borra un proyecto
Borra depósitos de Cloud Storage
Borra tu plantilla de flujo de trabajo
gcloud dataproc workflow-templates delete wordcount-template \ --region=us-central1
Borra tu función de Cloud Functions
Abre la página Cloud Run functions en la consola de Google Cloud , selecciona la casilla a la izquierda de la función wordcount y, luego, haz clic en Borrar.