Crea un cluster Dataproc utilizzando le librerie client
Il codice campione elencato di seguito mostra come utilizzare le librerie client di Cloud per creare un cluster Dataproc, eseguire un job sul cluster, quindi eliminare il cluster.
Puoi anche eseguire queste attività utilizzando:
- Richieste API REST in Guide rapide che utilizzano Explorer API
- la console Google Cloud in Creare un cluster Dataproc utilizzando la console Google Cloud
- Google Cloud CLI in Crea un cluster Dataproc utilizzando Google Cloud CLI
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
- Installa la libreria client Per saperne di più, vedi Configurazione dell'ambiente di sviluppo.
- Configurare l'autenticazione
- Clona ed esegui il codice GitHub di esempio.
- Visualizza l'output. Il codice restituisce il log del driver del job al bucket di staging Dataproc predefinito in Cloud Storage. Puoi visualizzare l'output del driver del job dalla console Google Cloud nella sezione Job di Dataproc del tuo progetto. Fai clic sull'ID job per visualizzare l'output del job nella pagina Dettagli job.
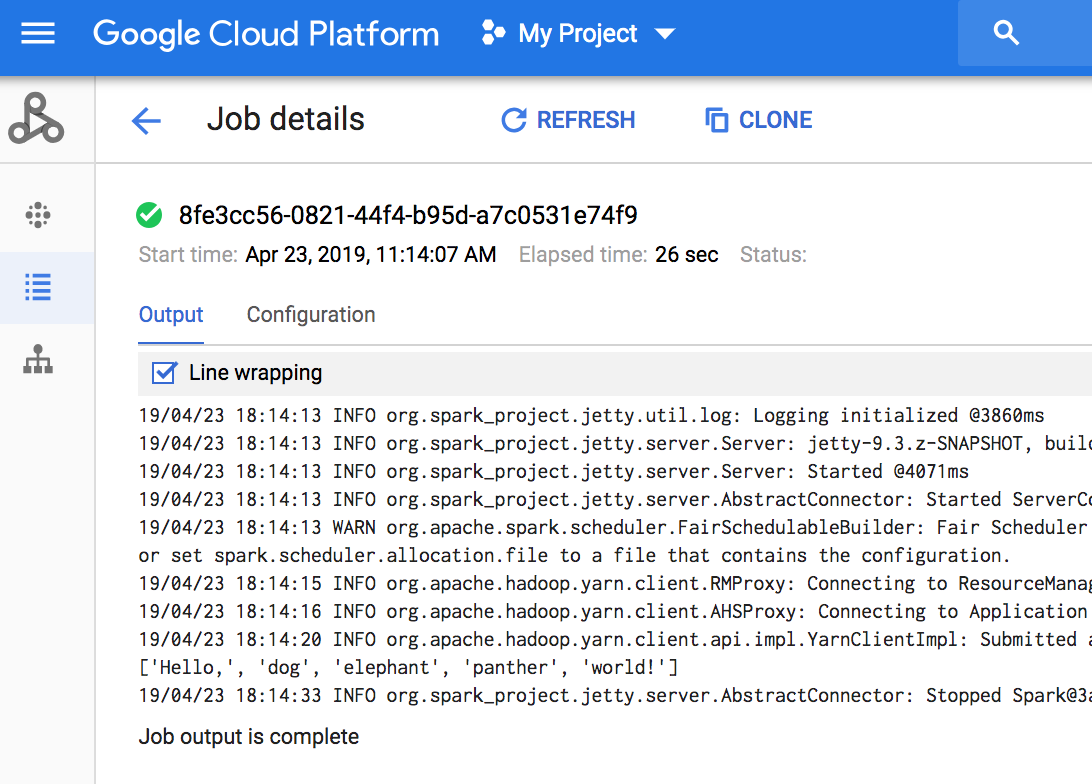
- Installa la libreria client Per ulteriori informazioni, vedi Configurazione di un ambiente di sviluppo Java.
- Configurare l'autenticazione
- Clona ed esegui il codice GitHub di esempio.
- Visualizza l'output. Il codice restituisce il log del driver del job al bucket di staging Dataproc predefinito in Cloud Storage. Puoi visualizzare l'output del driver del job dalla console Google Cloud nella sezione Job di Dataproc del tuo progetto. Fai clic sull'ID job per visualizzare l'output del job nella pagina Dettagli job.
- Installa la libreria client Per saperne di più, consulta Configurazione di un ambiente di sviluppo Node.js.
- Configurare l'autenticazione
- Clona ed esegui il codice GitHub di esempio.
- Visualizza l'output. Il codice restituisce il log del driver del job al bucket di staging Dataproc predefinito in Cloud Storage. Puoi visualizzare l'output del driver del job dalla console Google Cloud nella sezione Job di Dataproc del tuo progetto. Fai clic sull'ID job per visualizzare l'output del job nella pagina Dettagli job.
- Installa la libreria client Per ulteriori informazioni, consulta Configurazione di un ambiente di sviluppo Python.
- Configurare l'autenticazione
- Clona ed esegui il codice GitHub di esempio.
- Visualizza l'output. Il codice restituisce il log del driver del job al bucket di staging Dataproc predefinito in Cloud Storage. Puoi visualizzare l'output del driver del job dalla console Google Cloud nella sezione Job di Dataproc del tuo progetto. Fai clic sull'ID job per visualizzare l'output del job nella pagina Dettagli job.
- Consulta la libreria client Cloud di Dataproc Risorse aggiuntive.
Esegui il codice
Prova la procedura dettagliata:fai clic su Apri in Cloud Shell per eseguire una procedura dettagliata delle librerie client di Cloud per Python che crea un cluster, esegue un job PySpark e poi elimina il cluster.