Créer un cluster Dataproc à l'aide de bibliothèques clientes
L'exemple de code ci-dessous montre comment utiliser les bibliothèques clientes Cloud pour créer un cluster Dataproc, exécuter une tâche sur le cluster, puis supprimer le cluster.
Pour effectuer ces tâches, vous pouvez également utiliser :
- des requêtes d'API REST dans les guides de démarrage rapide avec l'explorateur d'API ;
- la console Google Cloud dans Créer un cluster Dataproc à l'aide de la console Google Cloud .
- Google Cloud CLI dans Créer un cluster Dataproc à l'aide de Google Cloud CLI
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
- Installez la bibliothèque cliente. Pour plus d'informations, consultez la page Configurer votre environnement de développement.
- Configurez l'authentification.
- Clonez et exécutez l'exemple de code GitHub.
- Consultez le résultat. Le code génère le journal du pilote de tâches dans le bucket de préproduction Dataproc par défaut dans Cloud Storage. Vous pouvez afficher le résultat du pilote de tâches depuis la console Google Cloud dans la section Tâches Dataproc de votre projet. Cliquez sur l'ID de tâche pour afficher le résultat de la tâche sur la page "Job details" (Informations sur la tâche).
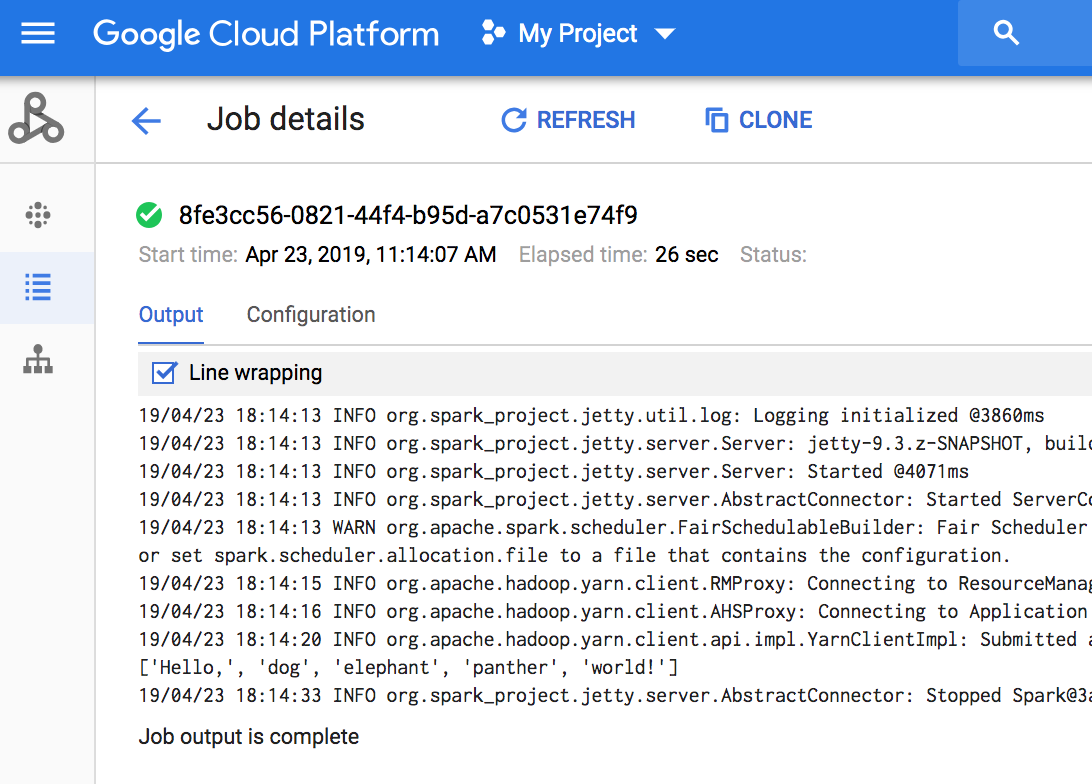
- Installez la bibliothèque cliente. Pour plus d'informations, consultez la page Configurer un environnement de développement Java.
- Configurez l'authentification.
- Clonez et exécutez l'exemple de code GitHub.
- Consultez le résultat. Le code génère le journal du pilote de tâches dans le bucket de préproduction Dataproc par défaut dans Cloud Storage. Vous pouvez afficher le résultat du pilote de tâches depuis la console Google Cloud dans la section Tâches Dataproc de votre projet. Cliquez sur l'ID de tâche pour afficher le résultat de la tâche sur la page "Job details" (Informations sur la tâche).
- Installez la bibliothèque cliente. Pour plus d'informations, consultez la page Configurer un environnement de développement Node.js.
- Configurez l'authentification.
- Clonez et exécutez l'exemple de code GitHub.
- Consultez le résultat. Le code génère le journal du pilote de tâches dans le bucket de préproduction Dataproc par défaut dans Cloud Storage. Vous pouvez afficher le résultat du pilote de tâches depuis la console Google Cloud dans la section Tâches Dataproc de votre projet. Cliquez sur l'ID de tâche pour afficher le résultat de la tâche sur la page "Job details" (Informations sur la tâche).
- Installez la bibliothèque cliente. Pour plus d'informations, consultez la page Configurer un environnement de développement Python.
- Configurez l'authentification.
- Clonez et exécutez l'exemple de code GitHub.
- Consultez le résultat. Le code génère le journal du pilote de tâches dans le bucket de préproduction Dataproc par défaut dans Cloud Storage. Vous pouvez afficher le résultat du pilote de tâches depuis la console Google Cloud dans la section Tâches Dataproc de votre projet. Cliquez sur l'ID de tâche pour afficher le résultat de la tâche sur la page "Job details" (Informations sur la tâche).
- Consultez les ressources supplémentaires concernant les bibliothèques clientes Cloud pour Dataproc.
Exécuter le Code
Essayez le tutoriel : cliquez sur Ouvrir dans Cloud Shell pour exécuter un tutoriel sur les bibliothèques clientes Cloud Python qui crée un cluster, exécute un job PySpark, puis supprime le cluster.