Dataproc NodeGroup 资源是一组执行分配的角色的 Dataproc 集群节点。本页介绍了驱动程序节点组,这是一组分配有 Driver 角色的 Compute Engine VMS,用于在 Dataproc 集群上运行作业驱动程序。
何时使用驱动程序节点组
- 仅当您需要在共享集群上运行多个并发作业时,才使用驱动程序节点组。
- 在使用驱动程序节点组之前,请增加主节点资源,以避免出现驱动程序节点组限制。
驱动程序节点如何帮助您运行并发作业
Dataproc 在 Dataproc 集群主节点上为每个作业启动作业驱动程序进程。该驱动程序进程又将应用驱动程序(例如 spark-submit)作为其子进程运行。不过,在主节点上运行的并发作业数量受主节点上可用资源限制,而且由于 Dataproc 主节点无法扩缩,因此当主节点资源不足以运行作业时,作业可能会失败或被限制。
驱动程序节点组是由 YARN 管理的特殊节点组,因此作业并发不会受到主节点资源限制。在包含驱动程序节点组的集群中,应用驱动程序会在驱动程序节点上运行。如果驱动程序节点有足够的资源,则每个驱动程序节点都可以运行多个应用驱动程序。
优势
使用包含驱动程序节点组的 Dataproc 集群,您可以执行以下操作:
- 横向扩展作业驱动程序资源以运行更多并发作业
- 将驱动程序资源与工作器资源分开进行扩缩
- 在 Dataproc 2.0+ 及更高版本的映像集群上实现更快的缩容速度。在这些集群上,应用主控器会在驱动程序节点组中的 Spark 驱动程序内运行(默认情况下,
spark.yarn.unmanagedAM.enabled设置为true)。 - 对驱动程序节点启动进行自定义。您可以在初始化脚本中添加
{ROLE} == 'Driver',让脚本为节点选择中的驱动程序节点组执行操作。
限制
- 在 Dataproc 工作流模板中,节点组不受支持。
- 您无法停止、重启或自动扩缩节点组集群。
- MapReduce 应用主控器在工作器节点上运行。如果您启用了安全停用,则工作器节点的缩容速度可能会很慢。
- 作业并发受
dataproc:agent.process.threads.job.max集群属性影响。例如,在具有三个主节点且此属性设置为默认值100的情况下,集群级作业并发数量上限为300。
驱动程序节点组与 Spark 集群模式相比较
| 功能 | Spark 集群模式 | 驱动程序节点组 |
|---|---|---|
| 工作器节点缩容 | 长期运行的驱动程序与短期运行的容器在同一工作器节点上运行,使得采用安全停用功能的工作器节点的缩容速度很慢。 | 当驱动程序在节点组上运行时,工作器节点会更快地缩容。 |
| 流式驱动程序输出 | 需要在 YARN 日志中搜索,以查找驱动程序被调度到的节点。 | 驱动程序输出会流式传输到 Cloud Storage,并在作业完成后显示在 Google Cloud 控制台和 gcloud dataproc jobs wait 命令输出中。 |
驱动程序节点组 IAM 权限
以下 IAM 权限与 Dataproc 节点组相关操作关联。
| 权限 | 操作 |
|---|---|
dataproc.nodeGroups.create
|
创建 Dataproc 节点组。如果用户在项目中具有 dataproc.clusters.create,则会被授予此权限。 |
dataproc.nodeGroups.get |
获取 Dataproc 节点组的详细信息。 |
dataproc.nodeGroups.update |
调整 Dataproc 节点组的大小。 |
驱动程序节点组操作
您可以使用 gcloud CLI 和 Dataproc API 创建作业、获取作业、调整作业大小、删除作业以及将作业提交到 Dataproc 驱动程序节点组。
创建驱动程序节点组集群
一个驱动程序节点组与一个 Dataproc 集群相关联。您可以在创建 Dataproc 集群的过程中创建节点组。您可以使用 gcloud CLI 或 Dataproc REST API 创建包含驱动程序节点组的 Dataproc 集群。
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
必填标志:
- CLUSTER_NAME:集群名称(在项目中必须是唯一的)。该名称必须以小写字母开头,最多可包含 51 个小写字母、数字和连字符,不能以连字符结尾。已删除集群的名称可以再次使用。
- REGION:集群所在的区域。
- SIZE:节点组中的驱动程序节点数。所需节点数取决于作业负载和驱动程序池机器类型。最小驱动程序组节点数等于作业驱动程序所需的内存总量或 vCPU 总数除以每个驱动程序池的机器内存量或 vCPU 数。
- NODE_GROUP_ID:可选,但建议填写。ID 在集群中必须是唯一的。在日后的操作(例如调整节点组大小)中,使用此 ID 可识别驱动程序组。如果节点组 ID 尚未指定,则 Dataproc 会生成它。
推荐标志:
--enable-component-gateway:添加此标志可启用 Dataproc 组件网关,以便访问 YARN 网页界面。YARN 界面中的“应用”和“调度程序”页面会显示集群和作业状态、应用队列内存、核心容量以及其他指标。
其他标志:您可以将以下可选的 driver-pool 标志添加到 gcloud dataproc clusters create 命令,以自定义节点组。
| 标志 | 默认值 |
|---|---|
--driver-pool-id |
字符串标识符,如果未由标志设置,则由服务生成。将来执行节点池操作(例如调整节点组大小)时,您可以使用此 ID 来识别节点组。 |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
无默认值。指定加速器时,您必须指定 GPU 类型;GPU 数量是可选项。 |
--num-driver-pool-local-ssds |
无默认值 |
--driver-pool-local-ssd-interface |
无默认值 |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
在 Dataproc API cluster.create 请求中完成 AuxiliaryNodeGroup。
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:必填。Google Cloud 项目 ID。
- REGION:必填。Dataproc 集群区域。
- CLUSTER_NAME:必填。集群名称(在项目中必须是唯一的)。该名称必须以小写字母开头,最多可包含 51 个小写字母、数字和连字符。它不能以连字符结尾。已删除集群的名称可以再次使用。
- SIZE:必填。节点组中的节点数。
- NODE_GROUP_ID:可选,但建议填写。ID 在集群中必须是唯一的。在日后的操作(例如调整节点组大小)中,使用此 ID 可识别驱动程序组。如果节点组 ID 尚未指定,则 Dataproc 会生成它。
其他选项:请参阅 NodeGroup。
HTTP 方法和网址:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
请求 JSON 正文:
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
获取驱动程序节点组集群元数据
您可以使用 gcloud dataproc node-groups describe 命令或 Dataproc API 获取驱动程序节点组元数据。
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
必填标志:
- NODE_GROUP_ID:您可以运行
gcloud dataproc clusters describe CLUSTER_NAME来列出节点组 ID。 - CLUSTER_NAME:集群名称。
- REGION:集群区域。
REST
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:必填。Google Cloud 项目 ID。
- REGION:必填。集群区域。
- CLUSTER_NAME:必填。集群名称。
- NODE_GROUP_ID:必填。您可以运行
gcloud dataproc clusters describe CLUSTER_NAME来列出节点组 ID。
HTTP 方法和网址:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
调整驱动程序节点组大小
您可以使用 gcloud dataproc node-groups resize 命令或 Dataproc API,向集群驱动程序节点组添加驱动程序节点或从中移除驱动程序节点。
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
必填标志:
- NODE_GROUP_ID:您可以运行
gcloud dataproc clusters describe CLUSTER_NAME来列出节点组 ID。 - CLUSTER_NAME:集群名称。
- REGION:集群区域。
- SIZE:指定节点组中的新驱动程序节点数。
可选标志:
--graceful-decommission-timeout=TIMEOUT_DURATION:当节点组缩容时,您可以添加此标志以指定安全停用 TIMEOUT_DURATION,从而避免作业驱动程序立即终止。建议:设置的超时时长至少应等于在节点组上运行时间最长的作业的时长(不支持恢复失败的驱动程序)。
示例:gcloud CLI NodeGroup 扩容命令:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
示例:gcloud CLI NodeGroup 缩容命令:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:必填。Google Cloud 项目 ID。
- REGION:必填。集群区域。
- NODE_GROUP_ID:必填。您可以运行
gcloud dataproc clusters describe CLUSTER_NAME来列出节点组 ID。 - SIZE:必填。节点组中的新节点数。
- TIMEOUT_DURATION:可选。当节点组缩容时,您可以向请求正文添加
gracefulDecommissionTimeout,以避免作业驱动程序立即终止。建议:设置的超时时长至少应等于在节点组上运行时间最长的作业的时长(不支持恢复失败的驱动程序)。示例:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
HTTP 方法和网址:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
请求 JSON 正文:
{
"size": SIZE,
}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
删除驱动程序节点组集群
当您删除 Dataproc 集群时,与该集群关联的节点组也会被删除。
提交作业
您可以使用 gcloud dataproc jobs submit 命令或 Dataproc API,将作业提交到包含驱动程序节点组的集群。
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
必填标志:
- JOB_COMMAND:指定作业命令。
- CLUSTER_NAME:集群名称。
- DRIVER_MEMORY:运行作业所需的作业驱动程序内存量(以 MB 为单位)(请参阅 Yarn 内存控制)。
- DRIVER_VCORES:运行作业所需的 vCPU 数量。
其他标志:
- DATAPROC_FLAGS:添加与作业类型相关的任何其他 gcloud dataproc jobs submit 标志。
- JOB_ARGS:添加任何参数(在
--后面),以传递给作业。
示例:您可以在 Dataproc 驱动程序节点组集群上通过 SSH 终端会话运行以下示例。
用于估算
pi值的 Spark 作业:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Spark wordcount 作业:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
用于估算
pi值的 PySpark 作业:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Hadoop TeraGen MapReduce 作业:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:必填。Google Cloud 项目 ID。
- REGION:必填。Dataproc 集群区域
- CLUSTER_NAME:必填。集群名称(在项目中必须是唯一的)。该名称必须以小写字母开头,最多可包含 51 个小写字母、数字和连字符。它不能以连字符结尾。已删除集群的名称可以再次使用。
- DRIVER_MEMORY:必填。运行作业所需的作业驱动程序内存量(以 MB 为单位)(请参阅 Yarn 内存控制)。
- DRIVER_VCORES:必填。运行作业所需的 vCPU 数量。
pi 值的 Spark 作业所需的字段)。
HTTP 方法和网址:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
请求 JSON 正文:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
查看作业日志
如需查看作业状态并帮助调试作业问题,您可以使用 gcloud CLI 或 Google Cloud 控制台查看驱动程序日志。
gcloud
作业驱动程序日志会在作业执行期间流式传输到 gcloud CLI 输出或Google Cloud 控制台。驱动程序日志会保留在 Cloud Storage 中的 Dataproc 集群暂存存储桶中。
运行以下 gcloud CLI 命令,列出 Cloud Storage 中驱动程序日志的位置:
gcloud dataproc jobs describe JOB_ID \ --region=REGION
Cloud Storage 中驱动程序日志的位置在命令输出中列为 driverOutputResourceUri,格式如下:
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
控制台
如需查看节点组集群日志,请执行以下操作:
您可以使用以下 Logs Explorer 查询格式来查找日志:
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID:项目 ID。 Google Cloud
- CLUSTER_NAME:集群名称。
- LOG_TYPE:
- Yarn 用户日志:
yarn-userlogs - Yarn 资源管理器日志:
hadoop-yarn-resourcemanager - Yarn 节点管理器日志:
hadoop-yarn-nodemanager
- Yarn 用户日志:
监控指标
Dataproc 节点组作业驱动程序在 dataproc-driverpool 分区下的 dataproc-driverpool-driver-queue 子队列中运行。
驱动程序节点组指标
下表列出了关联的节点组驱动程序指标,系统在默认情况下会为驱动程序节点组收集这些指标。
| 驱动程序节点组指标 | 说明 |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
dataproc-driverpool 分区下 dataproc-driverpool-driver-queue 中的可用内存量(以兆比字节为单位)。
|
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
dataproc-driverpool 分区下 dataproc-driverpool-driver-queue 中的待处理(排队)的容器数量。 |
子队列指标
下表列出了子队列指标。默认情况下,系统会为驱动程序节点组收集这些指标,并且可以针对任何 Dataproc 集群启用这些指标的收集。
| 子队列指标 | 说明 |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
默认分区下此队列中的可用内存量(以兆比字节为单位)。 |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
默认分区下此队列中的待处理(排队)的容器数量。 |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
所有分区下此队列中运行时间介于 0 到 60 分钟之间的作业的数量。 |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
所有分区下此队列中运行时间介于 60 到 300 分钟之间的作业的数量。 |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
所有分区下此队列中运行时间介于 300 到 1440 分钟之间的作业的数量。 |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
所有分区下此队列中运行时间超过 1440 分钟的作业的数量。 |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
所有分区下提交到此队列的应用的数量。 |
如需在Google Cloud 控制台中查看 YARN ChildQueueMetrics 和 DriverPoolsQueueMetrics,请执行以下操作:
在 Metrics Explorer 中,选择 VM Instance → Custom 资源。
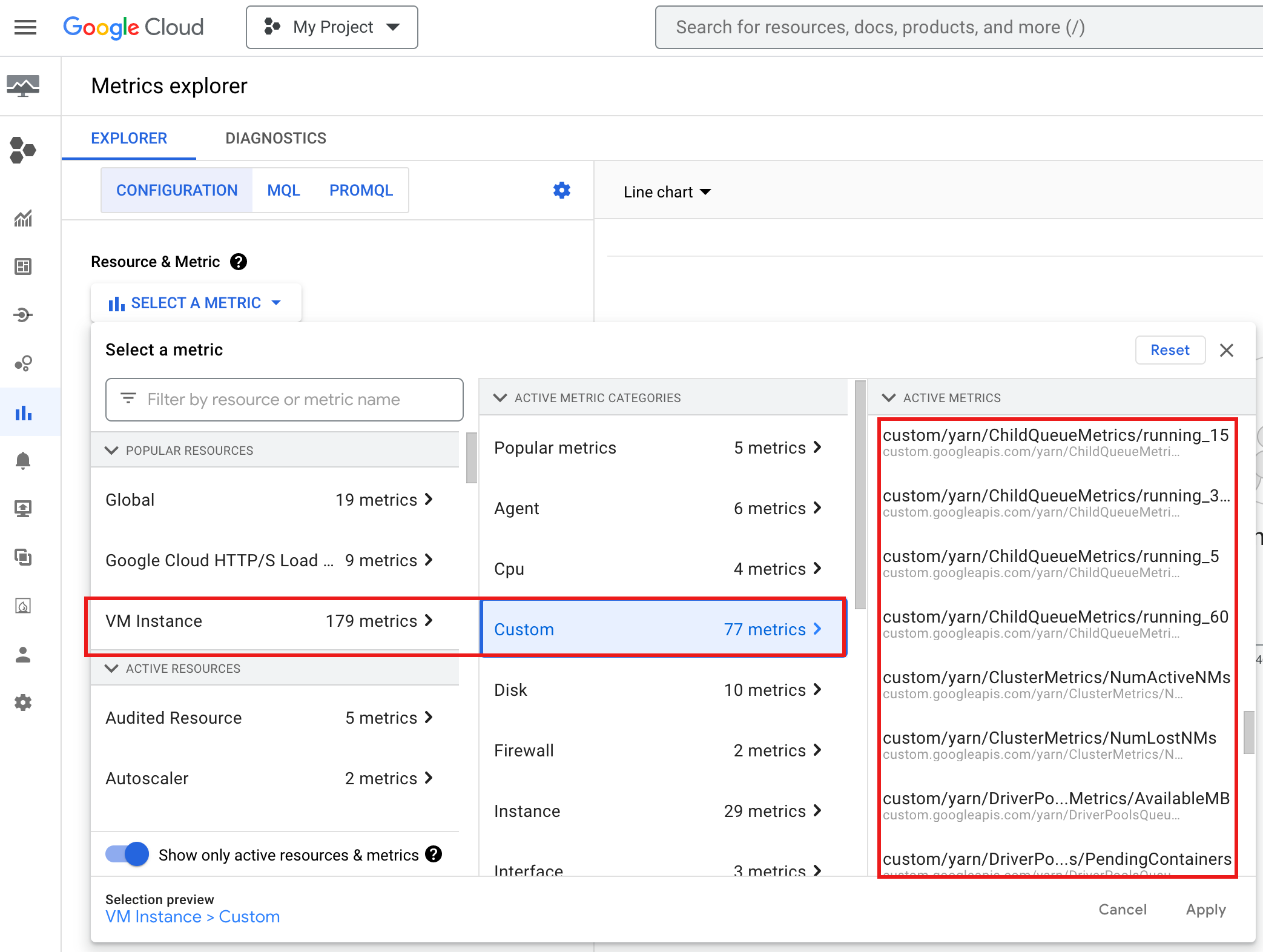
调试节点组作业驱动程序
此部分介绍了驱动程序节点组情况和错误,并提供了相应建议来解决这些情况或错误。
条件
情况:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB接近0。这表示集群驱动程序池队列即将耗尽内存。建议:扩大驱动程序池的规模。
情况:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers大于 0。这可能表示集群驱动程序池队列即将耗尽内存,并且 YARN 正在将作业加入队列。建议:扩大驱动程序池的规模。
错误
错误:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.建议:使用正数设置
driver-required-memory-mb和driver-required-vcores。错误:
Container exited with a non-zero exit code 137。建议:将
driver-required-memory-mb增加到作业内存用量。