Dataproc NodeGroup リソースは、割り当てられたロールを実行する Dataproc クラスタノードのグループです。このページでは、ドライバ ノードグループについて説明します。これは、Dataproc クラスタでジョブドライバを実行するために Driver ロールが割り当てられた Compute Engine VM のグループです。
ドライバ ノードグループを使用するタイミング
- ドライバ ノードグループは、共有クラスタで多くのジョブを同時に実行する必要がある場合にのみ使用します。
- ドライバノード グループの制限を避けるため、ドライバノード グループを使用する前にマスターノード リソースを増やします。
ドライバのノードが同時実行ジョブの実行にどのように役立つか
Dataproc は、ジョブごとに Dataproc クラスタ マスターノードでジョブドライバ プロセスを開始します。ドライバ プロセスは、spark-submit などのアプリケーション ドライバを子プロセスとして実行します。ただし、マスターで実行される同時実行ジョブの数は、マスターノードで利用可能なリソースによって制限されます。また、Dataproc マスターノードはスケーリングできないため、マスターノード リソースがジョブの実行に不十分だと、ジョブは失敗するか、スロットルされます。
ドライバノード グループは、YARN によって管理される特別なノードグループであるため、ジョブの同時実行がマスターノード リソースによって制限されることはありません。ドライバ ノードグループがあるクラスタでは、アプリケーション ドライバがドライバノードで実行されます。各ドライバノードには十分なリソースがある場合、複数のアプリケーション ドライバを実行できます。
利点
ドライバ ノードグループを使用する Dataproc クラスタを使用すると、次のことが可能になります。
- ジョブドライバ リソースを水平方向にスケーリングして、より多くのジョブを同時に実行する
- ドライバ リソースをワーカー リソースとは別にスケーリングする
- Dataproc 2.0 以降のイメージ クラスタでスケールダウンを高速化する。これらのクラスタでは、アプリマスターはドライバ ノードグループの Spark ドライバ内で実行されます(
spark.yarn.unmanagedAM.enabledはデフォルトでtrueに設定されています)。 - ドライバノードの起動をカスタマイズします。初期化スクリプトに
{ROLE} == 'Driver'を追加すると、ノードの選択でドライバ ノードグループに対するアクションをスクリプトで実行できるようになります。
制限事項
- ノードグループは Dataproc ワークフロー テンプレートではサポートされていません。
- ノードグループ クラスタは、停止、再起動、自動スケーリングを行えません。
- MapReduce アプリマスターは、ワーカーノード上で動作します。正常なデコミッションを有効にすると、ワーカーノードのスケールダウンが遅くなる可能性があります。
- ジョブの同時実行は
dataproc:agent.process.threads.job.maxクラスタ プロパティの影響を受けます。たとえば、3 つのマスターがあり、このプロパティがデフォルト値の100に設定されている場合、クラスタレベルでのジョブの最大同時実行数は300になります。
ドライバ ノードグループと Spark クラスタモードの比較
| 機能 | Spark クラスタモード | ドライバ ノードグループ |
|---|---|---|
| ワーカーノードのスケールダウン | 有効期間が長いドライバは有効期間が短いコンテナと同じワーカーノードで実行されるため、正常なデコミッションによるワーカーのスケールダウンが遅くなります。 | ドライバをノードグループで実行すると、ワーカーノードはより迅速にスケールダウンされます。 |
| ストリーミングされたドライバ出力 | YARN ログで検索して、ドライバがスケジュールされたノードを探す必要があります。 | ドライバ出力は Cloud Storage にストリーミングされ、 Google Cloud コンソールや、ジョブの完了後の gcloud dataproc jobs wait コマンド出力で確認できます。 |
ドライバ ノードグループの IAM 権限
次の IAM 権限は、Dataproc ノードグループに関連するアクションに関連付けられています。
| 権限 | アクション |
|---|---|
dataproc.nodeGroups.create
|
Dataproc ノードグループを作成します。プロジェクトに dataproc.clusters.create があるユーザーには、この権限が付与されます。 |
dataproc.nodeGroups.get |
Dataproc ノードグループの詳細を取得します。 |
dataproc.nodeGroups.update |
Dataproc ノードグループのサイズを変更します。 |
ドライバ ノードグループのオペレーション
gcloud CLI と Dataproc API を使用して、Dataproc ドライバ ノードグループを作成、取得、サイズ変更、削除、ジョブ送信できます。
ドライバ ノードグループ クラスタを作成する
ドライバ ノードグループは 1 つの Dataproc クラスタに関連付けられます。ノードグループは、Dataproc クラスタの作成の一環として作成します。gcloud CLI または Dataproc REST API を使用して、ドライバ ノードグループを持つ Dataproc クラスタを作成できます。
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
必須フラグ:
- CLUSTER_NAME: クラスタ名。プロジェクト内で一意にする必要があります。名前は先頭を小文字にする必要があり、51 文字以下の小文字、数字、ハイフンを使用できます。末尾をハイフンにすることはできません。削除されたクラスタの名前は再利用できます。
- REGION: クラスタが配置されるリージョン。
- SIZE: ノードプール内のノード数。必要なノード数は、ジョブ負荷とドライバプールのマシンタイプによって異なります。ドライバ グループ ノードの最小数は、ジョブドライバが必要とするメモリまたは vCPU の合計数を各ドライバプールのマシンのメモリまたは vCPU で割った値です。
- NODE_GROUP_ID: 省略可、推奨。ID はクラスタ内で一意である必要があります。ノードグループのサイズ変更など、今後のオペレーションでドライバ ID を識別するために使用します。指定しない場合、Dataproc はノードグループ ID を生成します。
推奨フラグ:
--enable-component-gateway: このフラグを追加して、YARN ウェブ インターフェースへのアクセスを提供する Dataproc コンポーネント ゲートウェイを有効にします。YARN UI の [アプリケーション] と [スケジューラ] ページには、クラスタとジョブのステータス、アプリケーション キューのメモリ、コア容量、その他の指標が表示されます。
追加のフラグ: 次のオプションの driver-pool フラグを gcloud dataproc clusters create コマンドに追加して、ノードグループをカスタマイズできます。
| フラグ | デフォルト値 |
|---|---|
--driver-pool-id |
フラグで設定されていない場合はサービスによって生成される文字列識別子。ノードグループのサイズ変更など、今後ノードプール オペレーションを実行するときに、この ID を使用してノードグループを識別できます。 |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
デフォルトはありません。アクセラレータを指定する場合は、GPU のタイプが必要です。GPU の数は省略可能です。 |
--num-driver-pool-local-ssds |
デフォルトなし |
--driver-pool-local-ssd-interface |
デフォルトなし |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
Dataproc API の cluster.create リクエストの一環として AuxiliaryNodeGroup を作成します。
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: 必須。Google Cloud プロジェクト ID。
- REGION: 必須。Dataproc クラスタのリージョン。
- CLUSTER_NAME: 必須。クラスタ名。プロジェクト内で一意にする必要があります。 名前は先頭を小文字にする必要があり、51 文字以下の小文字、数字、ハイフンを使用できます。末尾をハイフンにすることはできません。削除されたクラスタの名前は再利用できます。
- SIZE: 必須。ノードプール内のノード数。
- NODE_GROUP_ID: 省略可、推奨。ID はクラスタ内で一意である必要があります。ノードグループのサイズ変更など、今後のオペレーションでドライバ ID を識別するために使用します。指定しない場合、Dataproc はノードグループ ID を生成します。
その他のオプション: NodeGroup をご覧ください。
HTTP メソッドと URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
リクエストの本文(JSON):
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
ドライバ ノードグループ クラスタのメタデータを取得する
gcloud dataproc node-groups describe コマンドまたは Dataproc API を使用して、ドライバ ノードグループのメタデータを取得できます。
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
必須フラグ:
- NODE_GROUP_ID:
gcloud dataproc clusters describe CLUSTER_NAMEを実行して、ノードグループ ID を一覧表示できます。 - CLUSTER_NAME: クラスタ名。
- REGION: クラスタ リージョン。
REST
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: 必須。Google Cloud プロジェクト ID。
- REGION: 必須。クラスタ リージョン。
- CLUSTER_NAME: 必須。クラスタ名。
- NODE_GROUP_ID: 必須。
gcloud dataproc clusters describe CLUSTER_NAMEを実行して、ノードグループ ID を一覧表示できます。
HTTP メソッドと URL:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
ドライバ ノードグループのサイズを変更する
gcloud dataproc node-groups resize コマンドまたは Dataproc API を使用して、クラスタ ドライバ ノードグループからドライバノードを追加または削除できます。
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
必須フラグ:
- NODE_GROUP_ID:
gcloud dataproc clusters describe CLUSTER_NAMEを実行して、ノードグループ ID を一覧表示できます。 - CLUSTER_NAME: クラスタ名。
- REGION: クラスタ リージョン。
- SIZE: ノードグループ内の新しいドライバノード数を指定します。
オプション フラグ:
--graceful-decommission-timeout=TIMEOUT_DURATION: ノードグループをスケールダウンする際に、このフラグを追加することで、正常なデコミッション TIMEOUT_DURATION を指定して、ジョブドライバの即時終了を回避できます。推奨: ノードグループで実行されている最長ジョブと同等以上のタイムアウト時間を設定します(失敗したドライバの復元はサポートされていません)。
例: gcloud CLI NodeGroup スケールアップ コマンド:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
例: gcloud CLI NodeGroup スケールダウン コマンド:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: 必須。Google Cloud プロジェクト ID。
- REGION: 必須。クラスタ リージョン。
- NODE_GROUP_ID: 必須。
gcloud dataproc clusters describe CLUSTER_NAMEを実行して、ノードグループ ID を一覧表示できます。 - SIZE: 必須。ノードプール内の新しいノード数。
- TIMEOUT_DURATION: 省略可。ノードグループをスケールダウンする際に、
gracefulDecommissionTimeoutをリクエストの本文に追加することで、ジョブドライバの即時終了を回避できます。推奨: ノードグループで実行されている最長ジョブと同等以上のタイムアウト時間を設定します(失敗したドライバの復元はサポートされていません)。例:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
HTTP メソッドと URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
リクエストの本文(JSON):
{
"size": SIZE,
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
ドライバ ノードグループ クラスタを削除する
Dataproc クラスタを削除すると、クラスタに関連付けられているノードグループも削除されます。
ジョブの送信
gcloud dataproc jobs submit コマンドまたは Dataproc API を使用して、ドライバ ノードグループを持つクラスタにジョブを送信できます。
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
必須フラグ:
- JOB_COMMAND: ジョブコマンドを指定します。
- CLUSTER_NAME: クラスタ名。
- DRIVER_MEMORY: ジョブの実行に必要なジョブドライバのメモリ容量(MB)。Yarn メモリ制御をご覧ください。
- DRIVER_VCORES: ジョブの実行に必要な vCPU の数。
追加フラグ:
- DATAPROC_FLAGS: ジョブタイプに関連する gcloud dataproc jobs submit フラグを追加します。
- JOB_ARGS: ジョブに渡す
--の後に引数 ( を追加します。
例: Dataproc ドライバ ノードグループ クラスタの SSH ターミナル セッションから次の例を実行できます。
piの値を見積もる Spark ジョブ:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Spark ワードカウント ジョブ:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
piの値を見積もる PySpark ジョブ:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Hadoop TeraGen MapReduce ジョブ:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: 必須。Google Cloud プロジェクト ID。
- REGION: 必須。Dataproc クラスタのリージョン
- CLUSTER_NAME: 必須。クラスタ名。プロジェクト内で一意にする必要があります。 名前は先頭を小文字にする必要があり、51 文字以下の小文字、数字、ハイフンを使用できます。末尾をハイフンにすることはできません。削除されたクラスタの名前は再利用できます。
- DRIVER_MEMORY: 必須。ジョブの実行に必要なジョブドライバのメモリ量(MB 単位)(Yarn メモリ制御をご覧ください)。
- DRIVER_VCORES: 必須。ジョブの実行に必要な vCPU の数。
pi の値を見積もる Spark ジョブを送信するために必要なフィールドが含まれています)。HTTP メソッドと URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
リクエストの本文(JSON):
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
- クライアント ライブラリをインストールする
- アプリケーションのデフォルト認証情報を設定する
- コードを実行する
- pi の値を見積もる Spark ジョブ:
- 「hello world」を出力する PySpark ジョブ:
ジョブのログを表示する
ジョブのステータスを表示し、ジョブの問題のデバッグに役立てるには、gcloud CLI または Google Cloud コンソールを使用してドライバログを表示します。
gcloud
ジョブの実行中に、ジョブドライバのログが gcloud CLI の出力またはGoogle Cloud コンソールにストリーミングされます。ドライバログは、Cloud Storage の Dataproc クラスタのステージング バケットに保持されます。
次の gcloud CLI コマンドを実行して、Cloud Storage のドライバログの場所を一覧表示します。
gcloud dataproc jobs describe JOB_ID \ --region=REGION
ドライバログの Cloud Storage の場所は、次の形式でコマンド出力の driverOutputResourceUri として一覧表示されます。
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
コンソール
ノードグループのクラスタログを表示するには:
次のログ エクスプローラ クエリ形式を使用して、ログを検索できます。
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID: Google Cloud プロジェクト ID。
- CLUSTER_NAME: クラスタ名。
- LOG_TYPE:
- Yarn ユーザーログ:
yarn-userlogs - Yarn Resource Manager のログ:
hadoop-yarn-resourcemanager - YARN Node Manager のログ:
hadoop-yarn-nodemanager
- Yarn ユーザーログ:
指標をモニタリングする
Dataproc ノードグループのジョブドライバは、dataproc-driverpool パーティションの dataproc-driverpool-driver-queue 子キューで実行されます。
ドライバ ノードグループの指標
次の表に、ドライバノード グループに対してデフォルトで収集される、関連するノードグループ ドライバの指標の一覧を示します。
| ドライバ ノードグループの指標 | 説明 |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
dataproc-driverpool パーティション内の dataproc-driverpool-driver-queue で使用可能なメモリ量(MiB)。 |
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
dataproc-driverpool パーティション内の dataproc-driverpool-driver-queue で保留中の(キューに格納された)コンテナの数。 |
子キューの指標
次の表に、子キューの指標を示します。指標は、デフォルトでドライバ ノードグループに対して収集され、任意の Dataproc クラスタでの収集に対して有効にできます。
| 子キューの指標 | 説明 |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
デフォルト パーティションの下のこのキューで使用可能なメモリ量(MiB)。 |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
デフォルト パーティションにある、このキュー内の保留中の(キューに格納された)コンテナの数。 |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
すべてのパーティションのこのキュー内でランタイムが 0~60 分のジョブの数。 |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
すべてのパーティションのこのキュー内でランタイムが 60~300 分のジョブの数。 |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
すべてのパーティションのこのキュー内でランタイムが 300~1440 分のジョブの数。 |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
すべてのパーティションのこのキュー内でランタイムが 1440 分を超えるジョブの数。 |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
すべてのパーティションのこのキューに送信されたアプリケーションの数。 |
Google Cloud コンソールで YARN ChildQueueMetrics と DriverPoolsQueueMetrics を表示するには:
Metrics Explorer で、[VM インスタンス] → [カスタム] リソースを選択します。
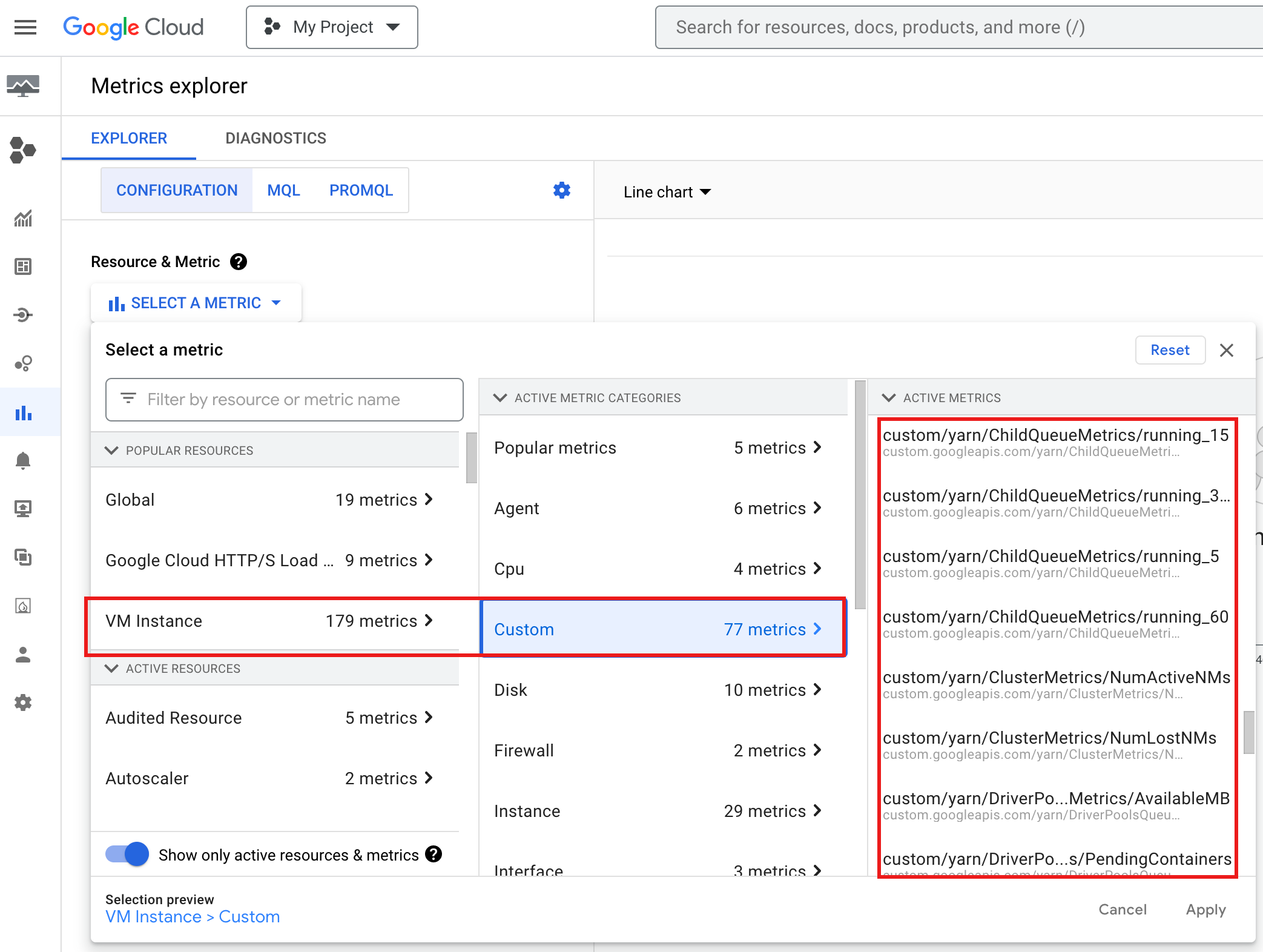
ノードグループ ジョブドライバをデバッグする
このセクションでは、ドライバ ノードグループの条件とエラー、さらには、条件やエラーを修正するための推奨事項を示します。
条件
条件:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBが0に近づいている。これは、クラスタ ドライバプールのキューがメモリ不足になっていることを示します。推奨: ドライバプールのサイズをスケールアップします。
条件:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainersが 0 より大きい。これは、クラスタ ドライバプールのキューがメモリ不足になり、YARN がジョブをキューイングしている可能性があることを示しています。推奨: ドライバプールのサイズをスケールアップします。
エラー
エラー:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.推奨事項:
driver-required-memory-mbとdriver-required-vcoresに正の数を設定します。エラー:
Container exited with a non-zero exit code 137。推奨: ジョブのメモリ使用量に合わせて
driver-required-memory-mbを増やします。