Une ressource NodeGroup Dataproc est un groupe de nœuds de cluster Dataproc qui exécutent un rôle attribué. Cette page décrit le groupe de nœuds pilotes, qui est un groupe de VM Compute Engine auxquelles le rôle Driver est attribué pour exécuter des pilotes de job sur le cluster Dataproc.
Quand utiliser des groupes de nœuds de pilote ?
- N'utilisez les groupes de nœuds de pilote que lorsque vous devez exécuter de nombreux jobs simultanés sur un cluster partagé.
- Augmentez les ressources du nœud maître avant d'utiliser des groupes de nœuds de pilote pour éviter les limites des groupes de nœuds de pilote.
Comment les nœuds de pilote vous aident à exécuter des jobs simultanés
Dataproc démarre un processus de pilote de job sur un nœud maître de cluster Dataproc pour chaque job. Le processus du pilote exécute à son tour un pilote d'application, tel que spark-submit, en tant que processus enfant.
Toutefois, le nombre de jobs simultanés exécutés sur le maître est limité par les ressources disponibles sur le nœud maître. Étant donné que les nœuds maîtres Dataproc ne peuvent pas être mis à l'échelle, un job peut échouer ou être limité lorsque les ressources du nœud maître sont insuffisantes pour l'exécuter.
Les groupes de nœuds de pilote sont des groupes de nœuds spéciaux gérés par YARN. La simultanéité des jobs n'est donc pas limitée par les ressources des nœuds maîtres. Dans les clusters avec un groupe de nœuds de pilote, les pilotes d'application s'exécutent sur les nœuds de pilote. Chaque nœud de pilote peut exécuter plusieurs pilotes d'application si le nœud dispose de ressources suffisantes.
Avantages
L'utilisation d'un cluster Dataproc avec un groupe de nœuds de pilote vous permet :
- Faire évoluer horizontalement les ressources du pilote de job pour exécuter plus de jobs simultanés
- Mettre à l'échelle les ressources du pilote séparément de celles du nœud de calcul
- Obtenez un scale-down plus rapide sur les clusters d'images Dataproc 2.0 et versions ultérieures. Sur ces clusters, le maître d'application s'exécute dans un pilote Spark au sein d'un groupe de nœuds de pilote (
spark.yarn.unmanagedAM.enabledest défini surtruepar défaut). - Personnalisez le démarrage du nœud du pilote. Vous pouvez ajouter
{ROLE} == 'Driver'dans un script d'initialisation pour que le script effectue des actions pour un groupe de nœuds de pilote dans la sélection de nœuds.
Limites
- Les groupes de nœuds ne sont pas compatibles avec les modèles de workflow Dataproc.
- Il est impossible d'arrêter, de redémarrer ou d'autoscaler les clusters de groupes de nœuds.
- Le maître d'application MapReduce s'exécute sur les nœuds de calcul. La réduction du nombre de nœuds de calcul peut être lente si vous activez la mise hors service progressive.
- La simultanéité des tâches est affectée par la propriété de cluster
dataproc:agent.process.threads.job.max. Par exemple, avec trois nœuds principaux et cette propriété définie sur la valeur par défaut de100, la simultanéité maximale des jobs au niveau du cluster est de300.
Groupe de nœuds du pilote par rapport au mode cluster Spark
| Fonctionnalité | Mode cluster Spark | Groupe de nœuds du pilote |
|---|---|---|
| Scaling à la baisse des nœuds de calcul | Les pilotes de longue durée s'exécutent sur les mêmes nœuds de calcul que les conteneurs de courte durée, ce qui ralentit la réduction du nombre de nœuds de calcul à l'aide de la mise hors service progressive. | Les nœuds de calcul sont mis à l'échelle à la baisse plus rapidement lorsque les pilotes s'exécutent sur des groupes de nœuds. |
| Résultats du pilote en streaming | Vous devez effectuer une recherche dans les journaux YARN pour trouver le nœud sur lequel le pilote a été planifié. | Les résultats du pilote sont diffusés en streaming vers Cloud Storage. Ils sont visibles dans la console Google Cloud et dans les résultats de la commande gcloud dataproc jobs wait une fois la tâche terminée. |
Autorisations IAM du groupe de nœuds du pilote
Les autorisations IAM suivantes sont associées aux actions liées aux groupes de nœuds Dataproc.
| Autorisation | Action |
|---|---|
dataproc.nodeGroups.create
|
Créez des groupes de nœuds Dataproc. Si un utilisateur dispose de dataproc.clusters.create dans le projet, cette autorisation lui est accordée. |
dataproc.nodeGroups.get |
Obtenez les détails d'un groupe de nœuds Dataproc. |
dataproc.nodeGroups.update |
Redimensionnez un groupe de nœuds Dataproc. |
Opérations sur les groupes de nœuds de pilote
Vous pouvez utiliser gcloud CLI et l'API Dataproc pour créer, obtenir, redimensionner, supprimer et envoyer un job à un groupe de nœuds de pilote Dataproc.
Créer un cluster de groupe de nœuds de pilote
Un groupe de nœuds de pilote est associé à un cluster Dataproc. Vous créez un groupe de nœuds lorsque vous créez un cluster Dataproc. Vous pouvez utiliser gcloud CLI ou l'API REST Dataproc pour créer un cluster Dataproc avec un groupe de nœuds de pilote.
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
Indicateurs requis :
- CLUSTER_NAME : nom du cluster, qui doit être unique dans un projet. Le nom doit commencer par une lettre minuscule et peut contenir jusqu'à 51 lettres minuscules, chiffres et traits d'union. Il ne peut pas se terminer par un trait d'union. Le nom d'un cluster supprimé peut être réutilisé.
- REGION : région dans laquelle se trouvera le cluster.
- SIZE : nombre de nœuds de pilote dans le groupe de nœuds. Le nombre de nœuds nécessaires dépend de la charge de travail et du type de machine du pool de pilotes. Le nombre minimal de nœuds de groupe de pilotes est égal à la mémoire totale ou aux processeurs virtuels requis par les pilotes de job, divisés par la mémoire ou les processeurs virtuels de chaque pool de pilotes.
- NODE_GROUP_ID : facultatif, mais recommandé. L'ID doit être unique dans le cluster. Utilisez cet ID pour identifier le groupe de pilotes lors de futures opérations, comme le redimensionnement du groupe de nœuds. Si aucun ID n'est spécifié, Dataproc en génère un.
Indicateur recommandé :
--enable-component-gateway: ajoutez cet indicateur pour activer la passerelle des composants Dataproc, qui permet d'accéder à l'interface Web YARN. Les pages "Application" et "Scheduler" de l'UI YARN affichent l'état du cluster et des jobs, la mémoire de la file d'attente des applications, la capacité de cœur et d'autres métriques.
Options supplémentaires : les options driver-pool facultatives suivantes peuvent être ajoutées à la commande gcloud dataproc clusters create pour personnaliser le groupe de nœuds.
| Option | Valeur par défaut |
|---|---|
--driver-pool-id |
Identifiant de chaîne généré par le service s'il n'est pas défini par l'indicateur. Cet ID peut être utilisé pour identifier le groupe de nœuds lors de futures opérations sur les pools de nœuds, comme le redimensionnement du groupe de nœuds. |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
Aucune valeur par défaut Lorsque vous spécifiez un accélérateur, le type de GPU est obligatoire, tandis que le nombre de GPU est facultatif. |
--num-driver-pool-local-ssds |
Aucune valeur par défaut |
--driver-pool-local-ssd-interface |
Aucune valeur par défaut |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
Renseignez un AuxiliaryNodeGroup dans le cadre d'une requête cluster.create de l'API Dataproc.
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- PROJECT_ID : valeur obligatoire. ID de projet Google Cloud
- REGION : valeur obligatoire. Région du cluster Dataproc.
- CLUSTER_NAME : valeur obligatoire. Nom du cluster, qui doit être unique dans un projet. Le nom doit commencer par une lettre minuscule et peut contenir jusqu'à 51 lettres minuscules, chiffres et traits d'union. Il ne peut pas se terminer par un trait d'union. Le nom d'un cluster supprimé peut être réutilisé.
- SIZE : valeur obligatoire. Nombre de nœuds dans le groupe de nœuds.
- NODE_GROUP_ID : facultatif et recommandé. L'ID doit être unique dans le cluster. Utilisez cet ID pour identifier le groupe de pilotes lors de futures opérations, comme le redimensionnement du groupe de nœuds. Si aucun ID n'est spécifié, Dataproc génère l'ID du groupe de nœuds.
Options supplémentaires : consultez NodeGroup.
Méthode HTTP et URL :
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
Corps JSON de la requête :
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
Obtenir les métadonnées du cluster du groupe de nœuds pilotes
Vous pouvez utiliser la commande gcloud dataproc node-groups describe ou l'API Dataproc pour obtenir les métadonnées du groupe de nœuds pilotes.
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
Indicateurs requis :
- NODE_GROUP_ID : vous pouvez exécuter
gcloud dataproc clusters describe CLUSTER_NAMEpour lister l'ID du groupe de nœuds. - CLUSTER_NAME : nom du cluster.
- REGION : région du cluster.
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- PROJECT_ID : valeur obligatoire. ID de projet Google Cloud
- REGION : valeur obligatoire. Région du cluster.
- CLUSTER_NAME : valeur obligatoire. Nom du cluster.
- NODE_GROUP_ID : valeur obligatoire. Vous pouvez exécuter
gcloud dataproc clusters describe CLUSTER_NAMEpour lister l'ID du groupe de nœuds.
Méthode HTTP et URL :
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
Redimensionner un groupe de nœuds de pilote
Vous pouvez utiliser la commande gcloud dataproc node-groups resize ou l'API Dataproc pour ajouter ou supprimer des nœuds pilotes d'un groupe de nœuds pilotes de cluster.
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
Indicateurs requis :
- NODE_GROUP_ID : vous pouvez exécuter
gcloud dataproc clusters describe CLUSTER_NAMEpour lister l'ID du groupe de nœuds. - CLUSTER_NAME : nom du cluster.
- REGION : région du cluster.
- SIZE : spécifiez le nouveau nombre de nœuds de pilote dans le groupe de nœuds.
Indicateur facultatif :
--graceful-decommission-timeout=TIMEOUT_DURATION: lorsque vous réduisez un groupe de nœuds, vous pouvez ajouter cet indicateur pour spécifier une mise hors service concertée TIMEOUT_DURATION afin d'éviter l'arrêt immédiat des pilotes de tâches. Recommandation : Définissez une durée de délai d'attente au moins égale à la durée du job le plus long en cours d'exécution sur le groupe de nœuds (la récupération des pilotes ayant échoué n'est pas prise en charge).
Exemple : commande gcloud CLI NodeGroup pour augmenter la capacité :
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
Exemple de commande gcloud CLI NodeGroup pour réduire l'échelle :
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- PROJECT_ID : valeur obligatoire. ID de projet Google Cloud
- REGION : valeur obligatoire. Région du cluster.
- NODE_GROUP_ID : valeur obligatoire. Vous pouvez exécuter
gcloud dataproc clusters describe CLUSTER_NAMEpour lister l'ID du groupe de nœuds. - SIZE : valeur obligatoire. Nouveau nombre de nœuds dans le groupe de nœuds.
- TIMEOUT_DURATION : facultatif. Lorsque vous réduisez un groupe de nœuds, vous pouvez ajouter un
gracefulDecommissionTimeoutau corps de la requête pour éviter l'arrêt immédiat des pilotes de tâches. Recommandation : Définissez une durée de délai avant expiration au moins égale à la durée du job le plus long exécuté sur le groupe de nœuds (la récupération des pilotes ayant échoué n'est pas prise en charge).Exemple :
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
Méthode HTTP et URL :
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
Corps JSON de la requête :
{
"size": SIZE,
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
Supprimer un cluster de groupe de nœuds de pilote
Lorsque vous supprimez un cluster Dataproc, les groupes de nœuds associés au cluster sont supprimés.
Envoyer une tâche
Vous pouvez utiliser la commande gcloud dataproc jobs submit ou l'API Dataproc pour envoyer un job à un cluster avec un groupe de nœuds de pilote.
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
Indicateurs requis :
- JOB_COMMAND : spécifiez la commande du job.
- CLUSTER_NAME : nom du cluster.
- DRIVER_MEMORY : quantité de mémoire des pilotes de job en Mo nécessaire pour exécuter un job (voir Contrôles de la mémoire Yarn).
- DRIVER_VCORES : nombre de processeurs virtuels nécessaires pour exécuter un job.
Options supplémentaires :
- DATAPROC_FLAGS : ajoutez d'autres indicateurs gcloud dataproc jobs submit liés au type de tâche.
- JOB_ARGS : ajoutez les arguments (après
--) à transmettre au job.
Exemples : vous pouvez exécuter les exemples suivants à partir d'une session de terminal SSH sur un cluster de groupe de nœuds de pilote Dataproc.
Tâche Spark pour estimer la valeur de
pi:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Job Spark de décompte de mots :
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
Tâche PySpark pour estimer la valeur de
pi:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Tâche Hadoop TeraGen MapReduce :
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- PROJECT_ID : valeur obligatoire. ID de projet Google Cloud
- REGION : valeur obligatoire. Région du cluster Dataproc
- CLUSTER_NAME : valeur obligatoire. Nom du cluster, qui doit être unique dans un projet. Le nom doit commencer par une lettre minuscule et peut contenir jusqu'à 51 lettres minuscules, chiffres et traits d'union. Il ne peut pas se terminer par un trait d'union. Le nom d'un cluster supprimé peut être réutilisé.
- DRIVER_MEMORY : valeur obligatoire. Quantité de mémoire (en Mo) des pilotes de tâches nécessaire pour exécuter une tâche (voir Contrôles de la mémoire Yarn).
- DRIVER_VCORES : valeur obligatoire. Nombre de vCPU nécessaires pour exécuter un job.
pi).
Méthode HTTP et URL :
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Corps JSON de la requête :
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
- Installer la bibliothèque cliente
- Configurer les identifiants par défaut de l'application
- Exécuter le code
- Tâche Spark pour estimer la valeur de pi :
- Tâche PySpark pour imprimer "hello world" :
Afficher les journaux de jobs
Pour afficher l'état des jobs et résoudre les problèmes liés aux jobs, vous pouvez afficher les journaux du pilote à l'aide de la gcloud CLI ou de la console Google Cloud .
gcloud
Les journaux du pilote de job sont diffusés en continu dans la sortie de la gcloud CLI ou dans la consoleGoogle Cloud pendant l'exécution du job. Les journaux de pilote sont conservés dans le bucket de préproduction du cluster Dataproc dans Cloud Storage.
Exécutez la commande gcloud CLI suivante pour lister l'emplacement des journaux de pilote dans Cloud Storage :
gcloud dataproc jobs describe JOB_ID \ --region=REGION
L'emplacement Cloud Storage des journaux de pilote est indiqué sous la forme driverOutputResourceUri dans le résultat de la commande, au format suivant :
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
Console
Pour afficher les journaux de cluster de groupe de nœuds :
Vous pouvez utiliser le format de requête Explorateur de journaux suivant pour trouver des journaux :
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID : Google Cloud ID du projet.
- CLUSTER_NAME : nom du cluster.
- LOG_TYPE :
- Journaux utilisateur Yarn :
yarn-userlogs - Journaux du gestionnaire de ressources Yarn :
hadoop-yarn-resourcemanager - Journaux du gestionnaire de nœuds Yarn :
hadoop-yarn-nodemanager
- Journaux utilisateur Yarn :
Surveiller les métriques
Les pilotes de tâches de groupe de nœuds Dataproc s'exécutent dans une file d'attente enfant dataproc-driverpool-driver-queue sous une partition dataproc-driverpool.
Métriques du groupe de nœuds du pilote
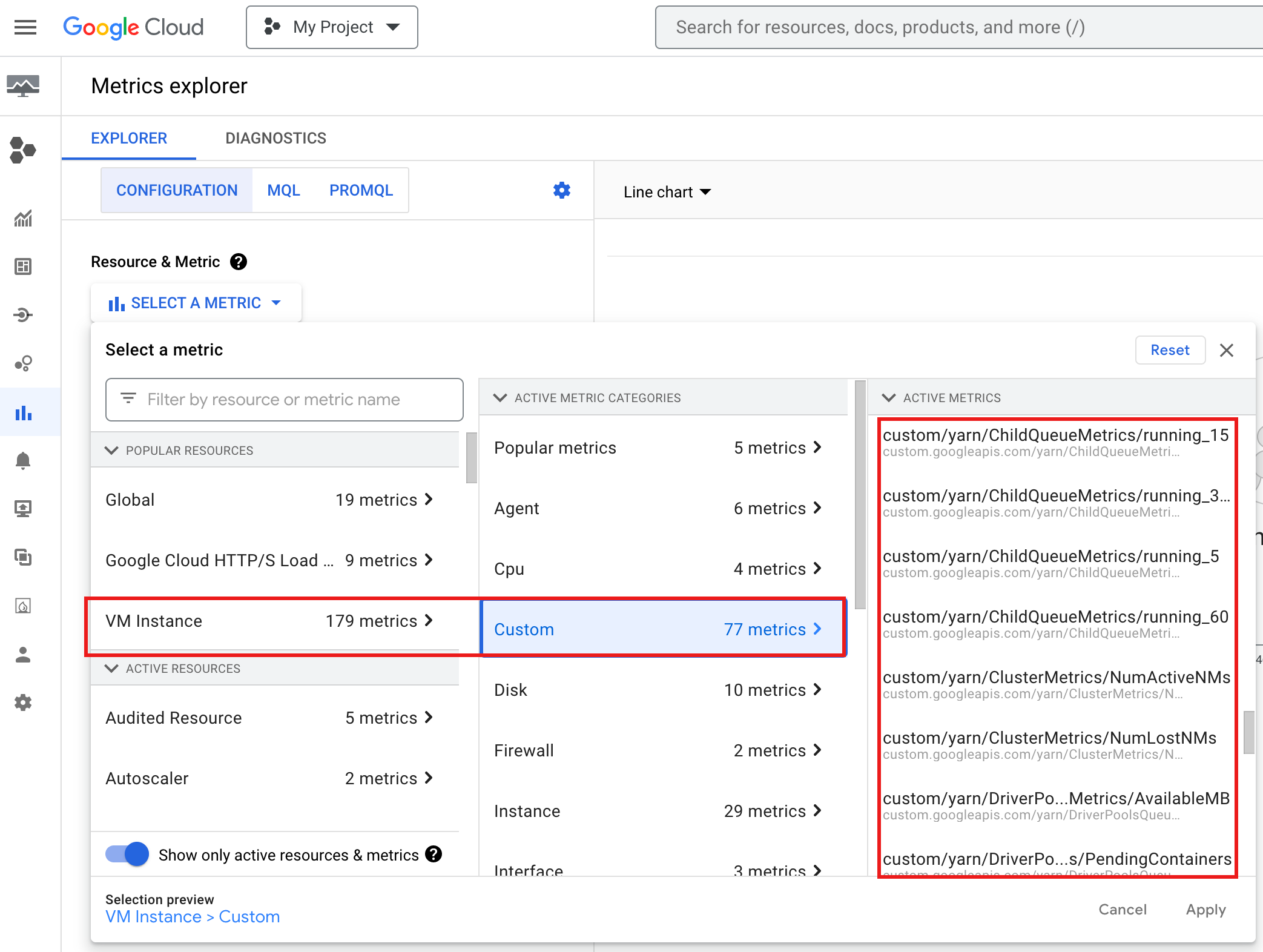
Le tableau suivant liste les métriques de pilote de groupe de nœuds associées, qui sont collectées par défaut pour les groupes de nœuds de pilote.
| Métrique du groupe de nœuds du pilote | Description |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
Quantité de mémoire disponible en mébioctets dans dataproc-driverpool-driver-queue sous la partition dataproc-driverpool.
|
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
Nombre de conteneurs en attente (en file d'attente) dans dataproc-driverpool-driver-queue sous la partition dataproc-driverpool. |
Métriques de la file d'attente enfant
Le tableau suivant liste les métriques des files d'attente enfants. Les métriques sont collectées par défaut pour les groupes de nœuds de pilote et peuvent être activées pour la collecte sur n'importe quel cluster Dataproc.
| Métrique de file d'attente enfant | Description |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
Quantité de mémoire disponible en mébioctets dans cette file d'attente sous la partition par défaut. |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
Nombre de conteneurs en attente (en file d'attente) dans cette file d'attente sous la partition par défaut. |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
Nombre de jobs dont la durée d'exécution est comprise entre 0 et 60 minutes dans cette file d'attente, pour toutes les partitions. |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
Nombre de jobs dont la durée d'exécution est comprise entre 60 et 300 minutes dans cette file d'attente, pour toutes les partitions. |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
Nombre de jobs dont la durée d'exécution est comprise entre 300 et 1440 minutes dans cette file d'attente, pour toutes les partitions. |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
Nombre de tâches dont la durée d'exécution est supérieure à 1440 minutes dans cette file d'attente, pour toutes les partitions. |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
Nombre de demandes envoyées à cette file d'attente dans toutes les partitions. |
Pour afficher YARN ChildQueueMetrics et DriverPoolsQueueMetrics dans la consoleGoogle Cloud :
Sélectionnez les ressources Instance de VM → Personnalisé dans l'explorateur de métriques.
Déboguer le pilote de tâches du groupe de nœuds
Cette section fournit des conditions et des erreurs de groupe de nœuds de pilote, ainsi que des recommandations pour résoudre la condition ou l'erreur.
Conditions
Condition :
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBapproche de0. Cela indique que les files d'attente des pools de pilotes de cluster manquent de mémoire.Recommandation : augmentez la taille du pool de pilotes.
Condition :
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainersest supérieur à 0. Cela peut indiquer que les pools de pilotes de cluster sont à court de mémoire et que YARN met les tâches en file d'attente.Recommandation : augmentez la taille du pool de pilotes.
Erreurs
Erreur :
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.Recommandation : Définissez
driver-required-memory-mbetdriver-required-vcoresavec des nombres positifs.Erreur :
Container exited with a non-zero exit code 137.Recommandation : augmentez
driver-required-memory-mbpour l'utilisation de la mémoire du job.