Mit Cloud Monitoring erhalten Sie Einblick in die Leistung, die Betriebszeit und die reibungslose Funktion cloudbasierter Anwendungen. Google Cloud Observability erfasst und speichert Messwerte, Ereignisse und Metadaten aus Dataproc-Clustern, einschließlich HDFS-, YARN-, Job- und Vorgangsmesswerten pro Cluster, um Informationen durch Dashboards und Diagramme zu generieren (siehe Cloud Monitoring-Dataproc-Messwerte).
Unter Cloud Monitoring-Preise finden Sie Informationen zu Ihren Kosten.
Informationen zur Aufbewahrung der Messwertdaten finden Sie unter Monitoring-Kontingente und -Limits.
Erfassung von Messwerten zu Dataproc-Ressourcen
Cloud Monitoring erfasst Messwerte für die folgenden Dataproc-Ressourcen:
- Cloud Dataproc-Cluster
- Cloud Dataproc-Job
- Cloud Dataproc-Batch
- Cloud Dataproc-Sitzung
Dataproc-Ressourcenmesswerte werden im folgenden Format erfasst:
dataproc.googleapis.com/RESOURCE/METRIC.
Dazu gehört auch die Erfassung mehrerer OSS-Messwerte.
Dataproc-Ressourcenmesswerte ansehen
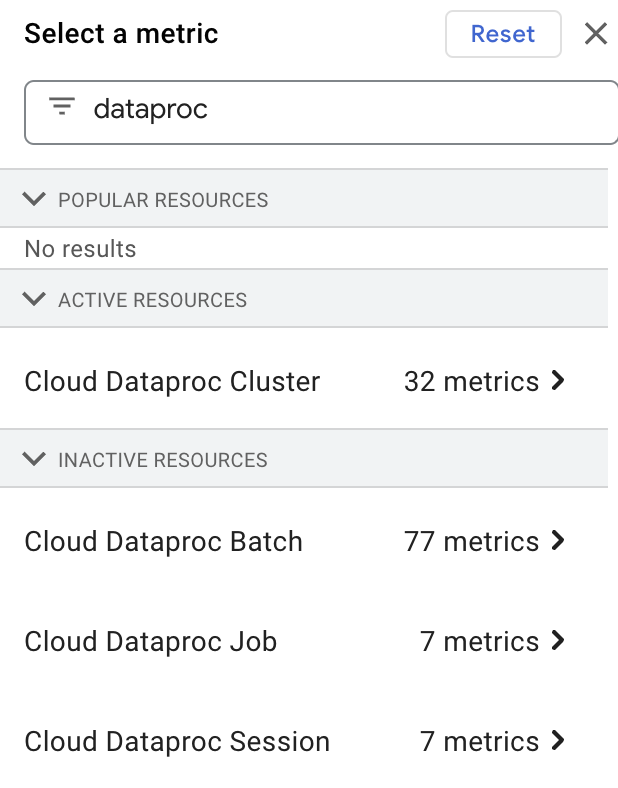
Sie können die Messwerte für Dataproc-Ressourcen im Metrics Explorer aufrufen, indem Sie „dataproc“ in das Feld Filter by resource or metric name eingeben und dann eine „Cloud Dataproc“-Ressource auswählen.
Erfassung benutzerdefinierter Messwerte
Wenn Sie einen Dataproc-Cluster erstellen, können Sie die Erfassung von Messwerten aus einer oder mehreren benutzerdefinierten Messwertquellen aktivieren. Aus jeder aktivierten Messwertquelle wird standardmäßig eine Reihe von Messwerten erfasst, sofern Sie nicht die Messwerte angeben, die aus einer Messwertquelle erfasst werden sollen. Nutzerdefinierte Messwerte werden als Messwertüberschreibungen bezeichnet.
Benutzerdefinierte OSS-Messwerte werden im folgenden Format erfasst:
custom.googleapis.com/OSS_COMPONENT/METRIC
Beispiele für benutzerdefinierte OSS-Messwerte:
custom.googleapis.com/spark/driver/DAGScheduler/job/allJobs custom.googleapis.com/hiveserver2/memory/MaxNonHeapMemory
Erfassung benutzerdefinierter Messwerte aktivieren
Sie können die gcloud CLI oder die Dataproc API verwenden, um die Erfassung von benutzerdefinierten Messwerten aus einer oder mehreren Messwertquellen zu aktivieren.
gcloud-CLI
Erhebung benutzerdefinierter Messwerte
Verwenden Sie das Flag
gcloud dataproc clusters create --metric-sources, um das Erfassen von benutzerdefinierten Messwerten aus einer oder mehreren Messwertquellen zu aktivieren.
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ ... other flags
Hinweise:
--metric-sources: Erforderlich, um die Erfassung benutzerdefinierter Messwerte zu aktivieren. Geben Sie eine oder mehrere der folgenden Messwertquellen an:spark,flink,hdfs,yarn,spark-history-server,hiveserver2,hivemetastoreundmonitoring-agent-defaults. Beim Namen der Messwertquelle wird nicht zwischen Groß- und Kleinschreibung unterschieden. Es ist also sowohl „yarn“ als auch „YARN“ zulässig.- monitoring-agent-defaults sind in Clustern mit Image-Version 2.2 nicht verfügbar. Sie können den Ops-Agent installieren, der Syslog-Logs und Hostmesswerte erfasst .
Messwerterfassung überschreiben
Optional können Sie das Flag --metric-overrides oder --metric-overrides-file hinzufügen, um das Erfassen von einem oder mehreren benutzerdefinierten Messwerten aus einer oder mehreren Messwertquellen zu aktivieren.
-
Alle benutzerdefinierten Messwerte und alle Spark-Messwerte können als Messwertüberschreibung für die Erfassung aufgeführt werden. Bei Messwertüberschreibungen wird die Groß-/Kleinschreibung beachtet. Sie müssen gegebenenfalls im CamelCase-Format angegeben werden.
Beispiele:
sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committedhiveserver2:JVM:Memory:NonHeapMemoryUsage.usedyarn:ResourceManager:JvmMetrics:MemHeapMaxM
-
Nur die angegebenen überschriebenen Messwerte werden aus einer bestimmten Messwertquelle erfasst. Wenn beispielsweise ein oder mehrere
spark:executive-Messwerte als Messwertüberschreibungen aufgeführt sind, werden keine anderenSPARK-Messwerte erhoben. Die Erfassung benutzerdefinierter Messwerte aus anderen Messwertquellen ist davon nicht betroffen. Wenn beispielsweise sowohlSPARK- als auchYARN-Messwertquellen aktiviert sind und nur für Spark-Messwerte Überschreibungen angegeben werden, wird der Standardsatz der aktivierten YARN-Messwerte erfasst. -
Die Quelle der angegebenen Messwertüberschreibung muss aktiviert sein. Wenn beispielsweise ein oder mehrere
spark:driver-Messwerte als Messwertüberschreibungen angegeben werden, muss diespark-Messwertquelle aktiviert sein (--metric-sources=spark).
Liste der überschriebenen Messwerte
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ --metric-overrides=LIST_OF_METRIC_OVERRIDES \ ... other flags
Hinweise:
--metric-sources: Erforderlich, um die Erfassung benutzerdefinierter Messwerte zu aktivieren. Geben Sie eine oder mehrere der folgenden Messwertquellen an:spark,flink,hdfs,yarn,spark-history-server,hiveserver2,hivemetastoreundmonitoring-agent-defaults. Beim Namen der Messwertquelle wird nicht zwischen Groß- und Kleinschreibung unterschieden. Es ist also sowohl „yarn“ als auch „YARN“ zulässig.--metric-overrides: Geben Sie eine Liste von Messwerten im folgenden Format an:METRIC_SOURCE:INSTANCE:GROUP:METRIC
Beispiel:
--metric-overrides=sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committedDieses Flag ist eine Alternative zum
--metric-overrides-file-Flag und kann nicht damit verwendet werden.
Datei mit überschriebenen Messwerten
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC-SOURCE(s) \ --metric-overrides-file=METRIC_OVERRIDES_FILENAME \ ... other flags
Hinweise:
-
--metric-sources: Erforderlich, um die Erfassung benutzerdefinierter Messwerte zu aktivieren. Geben Sie eine oder mehrere der folgenden Messwertquellen an:spark,flink,hdfs,yarn,spark-history-server,hiveserver2,hivemetastoreundmonitoring-agent-defaults. Beim Namen der Messwertquelle wird nicht zwischen Groß- und Kleinschreibung unterschieden. Es ist also sowohl „yarn“ als auch „YARN“ zulässig. -
--metric-overrides-file: Geben Sie eine lokale Datei oder eine Cloud Storage-Datei (gs://bucket/filename) an, die ein oder mehrere Messwerte im folgenden Format enthält:METRIC_SOURCE:INSTANCE:GROUP:METRIC
Verwenden Sie bei Bedarf das CamelCase-Format.Beispiele:
--metric-overrides-file=gs://my-bucket/my-filename.txt--metric-overrides-file=./local-directory/local-filename.txtDieses Flag ist eine Alternative zum
--metric-overrides-Flag und kann nicht damit verwendet werden.
REST API
Verwenden Sie DataprocMetricConfig als Teil einer clusters.create-Anfrage, um die Erfassung benutzerdefinierter Messwerte zu aktivieren. Hinweis: monitoring-agent-defaults sind in Clustern mit der Image-Version 2.2 nur verfügbar, wenn der Ops-Agent installiert ist.
Benutzerdefinierte Messwerte ansehen
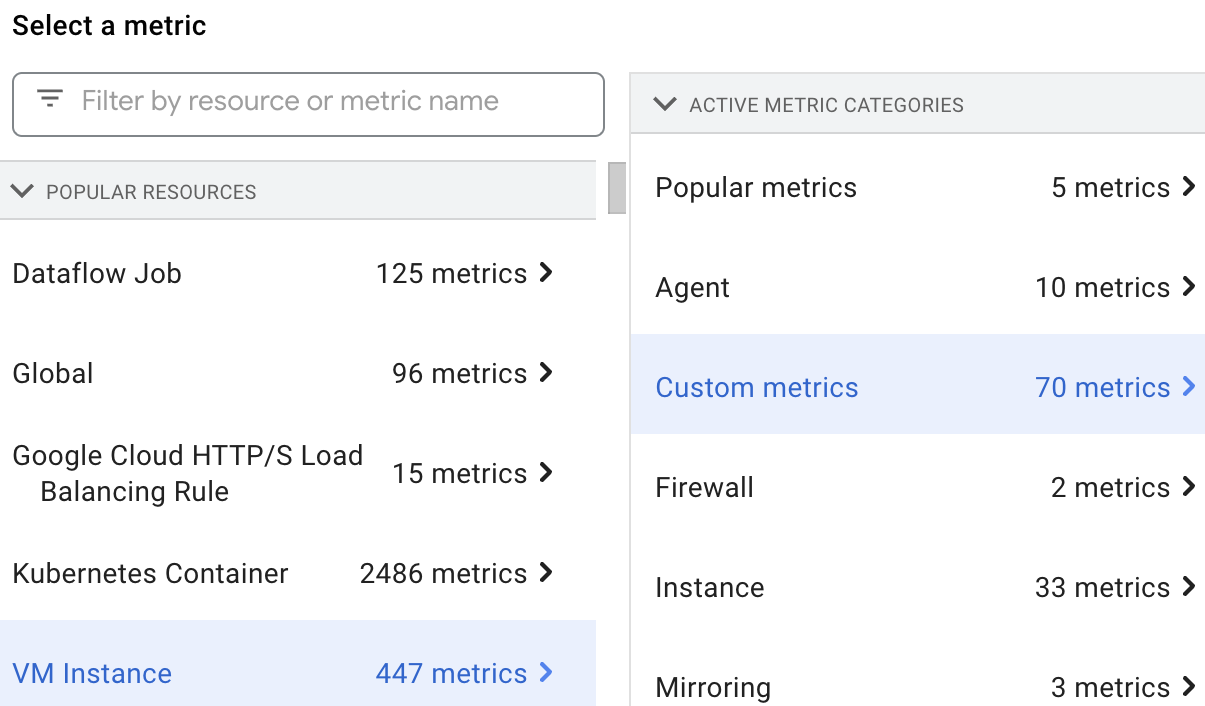
Sie können die Messwerte für Dataproc-Ressourcen im Metrics Explorer auswählen und ansehen, indem Sie die VM Instance-Ressource und dann Custom metrics auswählen.
Benutzerdefinierte Messwerte
Sie können Dataproc so konfigurieren, dass die in den folgenden Tabellen aufgeführten benutzerdefinierten Messwerte erfasst werden.
Die Spalte Aktivierte Messwerte ist mit „y“ gekennzeichnet, wenn Dataproc den Messwert erfasst, wenn Sie die zugehörige Messwertquelle aktivieren.
Alle für eine Messwertquelle aufgeführten Messwerte und alle Spark-Messwerte können für die Erfassung aktiviert werden, wenn Sie die Erfassung des Standardsatzes aktivierter Messwerte für die Messwertquelle überschreiben (siehe Erfassung benutzerdefinierter Messwerte aktivieren).
Dataproc verwendet den Monitoring-Agent, um Messwerte zu erfassen. Wenn Sie eine Messwertquelle aktivieren, wird die Erfassung von Agent-Messwerten aktiviert. Diese Messwerte werden Nutzern nicht in Rechnung gestellt. Dataproc verwendet sie, um Probleme bei der Erhebung von Messwerten zu diagnostizieren.
Hadoop-Messwerte
HDFS-Messwerte
| Messwert | Name des Metrics Explorer | Aktivierte Messwerte |
|---|---|---|
| hdfs:NameNode:FSNamesystem:CapacityTotalGB | dfs/FSNamesystem/CapacityTotalGB | y |
| hdfs:NameNode:FSNamesystem:CapacityUsedGB | dfs/FSNamesystem/CapacityUsedGB | y |
| hdfs:NameNode:FSNamesystem:CapacityRemainingGB | dfs/FSNamesystem/CapacityRemainingGB | y |
| hdfs:NameNode:FSNamesystem:FilesTotal | dfs/FSNamesystem/FilesTotal | y |
| hdfs:NameNode:FSNamesystem:MissingBlocks | dfs/FSNamesystem/MissingBlocks | n |
| hdfs:NameNode:FSNamesystem:ExpiredHeartbeats | dfs/FSNamesystem/ExpiredHeartbeats | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastCheckpoint | dfs/FSNamesystem/TransactionsSinceLastCheckpoint | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastLogRoll | dfs/FSNamesystem/TransactionsSinceLastLogRoll | n |
| hdfs:NameNode:FSNamesystem:LastWrittenTransactionId | dfs/FSNamesystem/LastWrittenTransactionId | n |
| hdfs:NameNode:FSNamesystem:CapacityTotal | dfs/FSNamesystem/CapacityTotal | n |
| hdfs:NameNode:FSNamesystem:CapacityUsed | dfs/FSNamesystem/CapacityUsed | n |
| hdfs:NameNode:FSNamesystem:CapacityRemaining | dfs/FSNamesystem/CapacityRemaining | n |
| hdfs:NameNode:FSNamesystem:CapacityUsedNonDFS | dfs/FSNamesystem/CapacityUsedNonDFS | n |
| hdfs:NameNode:FSNamesystem:TotalLoad | dfs/FSNamesystem/TotalLoad | n |
| hdfs:NameNode:FSNamesystem:SnapshottableDirectories | dfs/FSNamesystem/SnapshottableDirectories | n |
| hdfs:NameNode:FSNamesystem:Snapshots | dfs/FSNamesystem/Snapshots | n |
| hdfs:NameNode:FSNamesystem:BlocksTotal | dfs/FSNamesystem/BlocksTotal | n |
| hdfs:NameNode:FSNamesystem:PendingReplicationBlocks | dfs/FSNamesystem/PendingReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:UnderReplicatedBlocks | dfs/FSNamesystem/UnderReplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:CorruptBlocks | dfs/FSNamesystem/CorruptBlocks | n |
| hdfs:NameNode:FSNamesystem:ScheduledReplicationBlocks | dfs/FSNamesystem/ScheduledReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDeletionBlocks | dfs/FSNamesystem/PendingDeletionBlocks | n |
| hdfs:NameNode:FSNamesystem:ExcessBlocks | dfs/FSNamesystem/ExcessBlocks | n |
| hdfs:NameNode:FSNamesystem:PostponedMisreplicatedBlocks | dfs/FSNamesystem/PostponedMisreplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDataNodeMessageCourt | dfs/FSNamesystem/PendingDataNodeMessageCourt | n |
| hdfs:NameNode:FSNamesystem:MillisSinceLastLoadedEdits | dfs/FSNamesystem/MillisSinceLastLoadedEdits | n |
| hdfs:NameNode:FSNamesystem:BlockCapacity | dfs/FSNamesystem/BlockCapacity | n |
| hdfs:NameNode:FSNamesystem:StaleDataNodes | dfs/FSNamesystem/StaleDataNodes | n |
| hdfs:NameNode:FSNamesystem:TotalFiles | dfs/FSNamesystem/TotalFiles | n |
| hdfs:NameNode:JvmMetrics:MemHeapUsedM | dfs/jvm/MemHeapUsedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapCommittedM | dfs/jvm/MemHeapCommittedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapMaxM | dfs/jvm/MemHeapMaxM | n |
| hdfs:NameNode:JvmMetrics:MemMaxM | dfs/jvm/MemMaxM | n |
YARN-Messwerte
| Messwert | Name des Metrics Explorer | Aktivierte Messwerte |
|---|---|---|
| yarn:ResourceManager:ClusterMetrics:NumActiveNMs | yarn/ClusterMetrics/NumActiveNMs | y |
| yarn:ResourceManager:ClusterMetrics:NumDecommissionedNMs | yarn/ClusterMetrics/NumDecommissionedNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumLostNMs | yarn/ClusterMetrics/NumLostNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumUnhealthyNMs | yarn/ClusterMetrics/NumUnhealthyNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumRebootedNMs | yarn/ClusterMetrics/NumRebootedNMs | n |
| yarn:ResourceManager:QueueMetrics:running_0 | yarn/QueueMetrics/running_0 | y |
| yarn:ResourceManager:QueueMetrics:running_60 | yarn/QueueMetrics/running_60 | y |
| yarn:ResourceManager:QueueMetrics:running_300 | yarn/QueueMetrics/running_300 | y |
| yarn:ResourceManager:QueueMetrics:running_1440 | yarn/QueueMetrics/running_1440 | y |
| yarn:ResourceManager:QueueMetrics:AppsSubmitted | yarn/QueueMetrics/AppsSubmitted | y |
| yarn:ResourceManager:QueueMetrics:AvailableMB | yarn/QueueMetrics/AvailableMB | y |
| yarn:ResourceManager:QueueMetrics:PendingContainers | yarn/QueueMetrics/PendingContainers | y |
| yarn:ResourceManager:QueueMetrics:AppsRunning | yarn/QueueMetrics/AppsRunning | n |
| yarn:ResourceManager:QueueMetrics:AppsPending | yarn/QueueMetrics/AppsPending | n |
| yarn:ResourceManager:QueueMetrics:AppsCompleted | yarn/QueueMetrics/AppsCompleted | n |
| yarn:ResourceManager:QueueMetrics:AppsKilled | yarn/QueueMetrics/AppsKilled | n |
| yarn:ResourceManager:QueueMetrics:AppsFailed | yarn/QueueMetrics/AppsFailed | n |
| yarn:ResourceManager:QueueMetrics:AllocatedMB | yarn/QueueMetrics/AllocatedMB | n |
| yarn:ResourceManager:QueueMetrics:AllocatedVCores | yarn/QueueMetrics/AllocatedVCores | n |
| yarn:ResourceManager:QueueMetrics:AllocatedContainers | yarn/QueueMetrics/AllocatedContainers | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersAllocated | yarn/QueueMetrics/AggregateContainersAllocated | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersReleased | yarn/QueueMetrics/AggregateContainersReleased | n |
| yarn:ResourceManager:QueueMetrics:AvailableVCores | yarn/QueueMetrics/AvailableVCores | n |
| yarn:ResourceManager:QueueMetrics:PendingMB | yarn/QueueMetrics/PendingMB | n |
| yarn:ResourceManager:QueueMetrics:PendingVCores | yarn/QueueMetrics/PendingVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedMB | yarn/QueueMetrics/ReservedMB | n |
| yarn:ResourceManager:QueueMetrics:ReservedVCores | yarn/QueueMetrics/ReservedVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedContainers | yarn/QueueMetrics/ReservedContainers | n |
| yarn:ResourceManager:QueueMetrics:ActiveUsers | yarn/QueueMetrics/ActiveUsers | n |
| yarn:ResourceManager:QueueMetrics:ActiveApplications | yarn/QueueMetrics/ActiveApplications | n |
| yarn:ResourceManager:QueueMetrics:FairShareMB | yarn/QueueMetrics/FairShareMB | n |
| yarn:ResourceManager:QueueMetrics:FairShareVCores | yarn/QueueMetrics/FairShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MinShareMB | yarn/QueueMetrics/MinShareMB | n |
| yarn:ResourceManager:QueueMetrics:MinShareVCores | yarn/QueueMetrics/MinShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MaxShareMB | yarn/QueueMetrics/MaxShareMB | n |
| yarn:ResourceManager:QueueMetrics:MaxShareVCores | yarn/QueueMetrics/MaxShareVCores | n |
| yarn:ResourceManager:JvmMetrics:MemHeapUsedM | yarn/jvm/MemHeapUsedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapCommittedM | yarn/jvm/MemHeapCommittedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapMaxM | yarn/jvm/MemHeapMaxM | n |
| yarn:ResourceManager:JvmMetrics:MemMaxM | yarn/jvm/MemMaxM | n |
Spark-Messwerte
Spark-Treibermesswerte
| Messwert | Name des Metrics Explorer | Aktivierte Messwerte |
|---|---|---|
| spark:driver:BlockManager:disk.diskSpaceUsed_MB | spark/driver/BlockManager/disk/diskSpaceUsed_MB | y |
| spark:driver:BlockManager:memory.maxMem_MB | spark/driver/BlockManager/memory/maxMem_MB | y |
| spark:driver:BlockManager:memory.memUsed_MB | spark/driver/BlockManager/memory/memUsed_MB | y |
| spark:driver:DAGScheduler:job.allJobs | spark/driver/DAGScheduler/job/allJobs | y |
| spark:driver:DAGScheduler:stage.failedStages | spark/driver/DAGScheduler/stage/failedStages | y |
| spark:driver:DAGScheduler:stage.waitingStages | spark/driver/DAGScheduler/stage/waitingStages | y |
Messwerte für Spark-Ausführer
| Messwert | Name des Metrics Explorer | Aktivierte Messwerte |
|---|---|---|
| spark:executor:executor:bytesRead | spark/executor/bytesRead | y |
| spark:executor:executor:bytesWritten | spark/executor/bytesWritten | y |
| spark:executor:executor:cpuTime | spark/executor/cpuTime | y |
| spark:executor:executor:diskBytesSpilled | spark/executor/diskBytesSpilled | y |
| spark:executor:executor:recordsRead | spark/executor/recordsRead | y |
| spark:executor:executor:recordsWritten | spark/executor/recordsWritten | y |
| spark:executor:executor:runTime | spark/executor/runTime | y |
| spark:executor:executor:shuffleRecordsRead | spark/executor/shuffleRecordsRead | y |
| spark:executor:executor:shuffleRecordsWritten | spark/executor/shuffleRecordsWritten | y |
Flink-Messwerte
| Messwert | Name des Metrics Explorer | Aktivierte Messwerte |
|---|---|---|
| flink:jobmanager:numRegisteredTaskManagers | flink/jobmanager/numRegisteredTaskManagers | n |
| flink:jobmanager:numRunningJobs | flink/jobmanager/numRunningJobs | n |
| flink:jobmanager:Status.JVM.ClassLoader.ClassesLoaded | flink/jobmanager/Status.JVM.ClassLoader.ClassesLoaded | n |
| flink:jobmanager:Status.JVM.ClassLoader.ClassesUnloaded | flink/jobmanager/Status.JVM.ClassLoader.ClassesUnloaded | n |
| flink:jobmanager:Status.JVM.CPU.Load | flink/jobmanager/Status.JVM.CPU.Load | n |
| flink:jobmanager:Status.JVM.CPU.Time | flink/jobmanager/Status.JVM.CPU.Time | y |
| flink:jobmanager:Status.JVM.GarbageCollector.PSMarkSweep.Count | flink/jobmanager/Status.JVM.GarbageCollector.PSMarkSweep.Count | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSMarkSweep.Time | flink/jobmanager/Status.JVM.GarbageCollector.PSMarkSweep.Time | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSScavenge.Count | flink/jobmanager/Status.JVM.GarbageCollector.PSScavenge.Count | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSScavenge.Time | flink/jobmanager/Status.JVM.GarbageCollector.PSScavenge.Time | n |
| flink:jobmanager:Status.JVM.Memory.Direct.Count | flink/jobmanager/Status.JVM.Memory.Direct.Count | y |
| flink:jobmanager:Status.JVM.Memory.Direct.MemoryUsed | flink/jobmanager/Status.JVM.Memory.Direct.MemoryUsed | y |
| flink:jobmanager:Status.JVM.Memory.Direct.TotalCapacity | flink/jobmanager/Status.JVM.Memory.Direct.TotalCapacity | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Committed | flink/jobmanager/Status.JVM.Memory.Heap.Committed | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Max | flink/jobmanager/Status.JVM.Memory.Heap.Max | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Used | flink/jobmanager/Status.JVM.Memory.Heap.Used | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.Count | flink/jobmanager/Status.JVM.Memory.Mapped.Count | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.MemoryUsed | flink/jobmanager/Status.JVM.Memory.Mapped.MemoryUsed | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.TotalCapacity | flink/jobmanager/Status.JVM.Memory.Mapped.TotalCapacity | y |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Committed | flink/jobmanager/Status.JVM.Memory.Metaspace.Committed | n |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Max | flink/jobmanager/Status.JVM.Memory.Metaspace.Max | n |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Used | flink/jobmanager/Status.JVM.Memory.Metaspace.Used | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Committed | flink/jobmanager/Status.JVM.Memory.NonHeap.Committed | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Max | flink/jobmanager/Status.JVM.Memory.NonHeap.Max | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Used | flink/jobmanager/Status.JVM.Memory.NonHeap.Used | n |
| flink:jobmanager:Status.JVM.Threads.Count | flink/jobmanager/Status.JVM.Threads.Count | n |
| flink:jobmanager:taskSlotsAvailable | flink/jobmanager/taskSlotsAvailable | y |
| flink:jobmanager:taskSlotsTotal | flink/jobmanager/taskSlotsTotal | y |
| flink:operator:numRecordsIn | flink/operator/numRecordsIn | n |
| flink:operator:numRecordsInPerSecond.count | flink/operator/numRecordsInPerSecond.count | n |
| flink:operator:numRecordsInPerSecond.rate | flink/operator/numRecordsInPerSecond.rate | n |
| flink:operator:numRecordsOut | flink/operator/numRecordsOut | n |
| flink:operator:numRecordsOutPerSecond.count | flink/operator/numRecordsOutPerSecond.count | n |
| flink:operator:numRecordsOutPerSecond.rate | flink/operator/numRecordsOutPerSecond.rate | n |
| flink:operator:numSplitsProcessed | flink/operator/numSplitsProcessed | n |
| flink:task:buffers.inPoolUsage | flink/task/buffers.inPoolUsage | n |
| flink:task:buffers.inputExclusiveBuffersUsage | flink/task/buffers.inputExclusiveBuffersUsage | n |
| flink:task:buffers.inputFloatingBuffersUsage | flink/task/buffers.inputFloatingBuffersUsage | n |
| flink:task:buffers.inputQueueLength | flink/task/buffers.inputQueueLength | n |
| flink:task:buffers.outPoolUsage | flink/task/buffers.outPoolUsage | n |
| flink:task:buffers.outputQueueLength | flink/task/buffers.outputQueueLength | n |
| flink:task:idleTimeMsPerSecond.count | flink/task/idleTimeMsPerSecond.count | n |
| flink:task:idleTimeMsPerSecond.rate | flink/task/idleTimeMsPerSecond.rate | n |
| flink:task:numBuffersInLocal | flink/task/numBuffersInLocal | n |
| flink:task:numBuffersInLocalPerSecond.count | flink/task/numBuffersInLocalPerSecond.count | n |
| flink:task:numBuffersInLocalPerSecond.rate | flink/task/numBuffersInLocalPerSecond.rate | n |
| flink:task:numBuffersInRemote | flink/task/numBuffersInRemote | n |
| flink:task:numBuffersInRemotePerSecond.count | flink/task/numBuffersInRemotePerSecond.count | n |
| flink:task:numBuffersInRemotePerSecond.rate | flink/task/numBuffersInRemotePerSecond.rate | n |
| flink:task:numBuffersOut | flink/task/numBuffersOut | n |
| flink:task:numBuffersOutPerSecond.count | flink/task/numBuffersOutPerSecond.count | n |
| flink:task:numBuffersOutPerSecond.rate | flink/task/numBuffersOutPerSecond.rate | n |
| flink:task:numBytesIn | flink/task/numBytesIn | n |
| flink:task:numBytesInLocal | flink/task/numBytesInLocal | n |
| flink:task:numBytesInLocalPerSecond.count | flink/task/numBytesInLocalPerSecond.count | n |
| flink:task:numBytesInLocalPerSecond.rate | flink/task/numBytesInLocalPerSecond.rate | n |
| flink:task:numBytesInPerSecond.count | flink/task/numBytesInPerSecond.count | n |
| flink:task:numBytesInPerSecond.rate | flink/task/numBytesInPerSecond.rate | n |
| flink:task:numBytesInRemote | flink/task/numBytesInRemote | n |
| flink:task:numBytesInRemotePerSecond.count | flink/task/numBytesInRemotePerSecond.count | n |
| flink:task:numBytesInRemotePerSecond.rate | flink/task/numBytesInRemotePerSecond.rate | n |
| flink:task:numBytesOut | flink/task/numBytesOut | n |
| flink:task:numBytesOutPerSecond.count | flink/task/numBytesOutPerSecond.count | n |
| flink:task:numBytesOutPerSecond.rate | flink/task/numBytesOutPerSecond.rate | n |
| flink:task:numRecordsIn | flink/task/numRecordsIn | n |
| flink:task:numRecordsInPerSecond.count | flink/task/numRecordsInPerSecond.count | n |
| flink:task:numRecordsInPerSecond.rate | flink/task/numRecordsInPerSecond.rate | n |
| flink:task:numRecordsOut | flink/task/numRecordsOut | n |
| flink:task:numRecordsOutPerSecond.count | flink/task/numRecordsOutPerSecond.count | n |
| flink:task:numRecordsOutPerSecond.rate | flink/task/numRecordsOutPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.Buffers.inPoolUsage | flink/task/Shuffle.Netty.Input.Buffers.inPoolUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputExclusiveBuffersUsage | flink/task/Shuffle.Netty.Input.Buffers.inputExclusiveBuffersUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputFloatingBuffersUsage | flink/task/Shuffle.Netty.Input.Buffers.inputFloatingBuffersUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputQueueLength | flink/task/Shuffle.Netty.Input.Buffers.inputQueueLength | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocal | flink/task/Shuffle.Netty.Input.numBuffersInLocal | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocalPerSecond.count | flink/task/Shuffle.Netty.Input.numBuffersInLocalPerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocalPerSecond.rate | flink/task/Shuffle.Netty.Input.numBuffersInLocalPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemote | flink/task/Shuffle.Netty.Input.numBuffersInRemote | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemotePerSecond.count | flink/task/Shuffle.Netty.Input.numBuffersInRemotePerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemotePerSecond.rate | flink/task/Shuffle.Netty.Input.numBuffersInRemotePerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocal | flink/task/Shuffle.Netty.Input.numBytesInLocal | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocalPerSecond.count | flink/task/Shuffle.Netty.Input.numBytesInLocalPerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocalPerSecond.rate | flink/task/Shuffle.Netty.Input.numBytesInLocalPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemote | flink/task/Shuffle.Netty.Input.numBytesInRemote | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemotePerSecond.count | flink/task/Shuffle.Netty.Input.numBytesInRemotePerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemotePerSecond.rate | flink/task/Shuffle.Netty.Input.numBytesInRemotePerSecond.rate | n |
| flink:task:Shuffle.Netty.Output.Buffers.outPoolUsage | flink/task/Shuffle.Netty.Output.Buffers.outPoolUsage | n |
| flink:task:Shuffle.Netty.Output.Buffers.outputQueueLength | flink/task/Shuffle.Netty.Output.Buffers.outputQueueLength | n |
| flink:taskmanager:Status.flink.Memory.Managed.Total | flink/taskmanager/Status.flink.Memory.Managed.Total | n |
| flink:taskmanager:Status.flink.Memory.Managed.Used | flink/taskmanager/Status.flink.Memory.Managed.Used | n |
| flink:taskmanager:Status.JVM.ClassLoader.ClassesLoaded | flink/taskmanager/Status.JVM.ClassLoader.ClassesLoaded | n |
| flink:taskmanager:Status.JVM.ClassLoader.ClassesUnloaded | flink/taskmanager/Status.JVM.ClassLoader.ClassesUnloaded | n |
| flink:taskmanager:Status.JVM.CPU.Load | flink/taskmanager/Status.JVM.CPU.Load | n |
| flink:taskmanager:Status.JVM.CPU.Time | flink/taskmanager/Status.JVM.CPU.Time | y |
| flink:taskmanager:Status.JVM.GarbageCollector.PSMarkSweep.Count | flink/taskmanager/Status.JVM.GarbageCollector.PSMarkSweep.Count | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSMarkSweep.Time | flink/taskmanager/Status.JVM.GarbageCollector.PSMarkSweep.Time | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSScavenge.Count | flink/taskmanager/Status.JVM.GarbageCollector.PSScavenge.Count | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSScavenge.Time | flink/taskmanager/Status.JVM.GarbageCollector.PSScavenge.Time | n |
| flink:taskmanager:Status.JVM.Memory.Direct.Count | flink/taskmanager/Status.JVM.Memory.Direct.Count | y |
| flink:taskmanager:Status.JVM.Memory.Direct.MemoryUsed | flink/taskmanager/Status.JVM.Memory.Direct.MemoryUsed | y |
| flink:taskmanager:Status.JVM.Memory.Direct.TotalCapacity | flink/taskmanager/Status.JVM.Memory.Direct.TotalCapacity | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Committed | flink/taskmanager/Status.JVM.Memory.Heap.Committed | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Max | flink/taskmanager/Status.JVM.Memory.Heap.Max | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Used | flink/taskmanager/Status.JVM.Memory.Heap.Used | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.Count | flink/taskmanager/Status.JVM.Memory.Mapped.Count | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.MemoryUsed | flink/taskmanager/Status.JVM.Memory.Mapped.MemoryUsed | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.TotalCapacity | flink/taskmanager/Status.JVM.Memory.Mapped.TotalCapacity | y |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Committed | flink/taskmanager/Status.JVM.Memory.Metaspace.Committed | n |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Max | flink/taskmanager/Status.JVM.Memory.Metaspace.Max | n |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Used | flink/taskmanager/Status.JVM.Memory.Metaspace.Used | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Committed | flink/taskmanager/Status.JVM.Memory.NonHeap.Committed | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Max | flink/taskmanager/Status.JVM.Memory.NonHeap.Max | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Used | flink/taskmanager/Status.JVM.Memory.NonHeap.Used | n |
| flink:taskmanager:Status.JVM.Threads.Count | flink/taskmanager/Status.JVM.Threads.Count | n |
| flink:taskmanager:Status.Network.AvailableMemorySegments | flink/taskmanager/Status.Network.AvailableMemorySegments | n |
| flink:taskmanager:Status.Network.TotalMemorySegments | flink/taskmanager/Status.Network.TotalMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.AvailableMemory | flink/taskmanager/Status.Shuffle.Netty.AvailableMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.AvailableMemorySegments | flink/taskmanager/Status.Shuffle.Netty.AvailableMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.TotalMemory | flink/taskmanager/Status.Shuffle.Netty.TotalMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.TotalMemorySegments | flink/taskmanager/Status.Shuffle.Netty.TotalMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.UsedMemory | flink/taskmanager/Status.Shuffle.Netty.UsedMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.UsedMemorySegments | flink/taskmanager/Status.Shuffle.Netty.UsedMemorySegments | n |
Messwerte des Spark-Verlaufsservers
Dataproc erfasst die folgenden JVM-Speichermesswerte des Spark-Verlaufsservice:
| Messwert | Name des Metrics Explorer | Aktivierte Messwerte |
|---|---|---|
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.used | sparkHistoryServer/memory/UsedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.max | sparkHistoryServer/memory/MaxHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.used | sparkHistoryServer/memory/UsedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.max | sparkHistoryServer/memory/MaxNonHeapMemory | y |
HiveServer 2-Messwerte
| Messwert | Name des Metrics Explorer | Aktivierte Messwerte |
|---|---|---|
| hiveserver2:JVM:Memory:HeapMemoryUsage.committed | hiveserver2/memory/CommittedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.used | hiveserver2/memory/UsedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.max | hiveserver2/memory/MaxHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.committed | hiveserver2/memory/CommittedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.used | hiveserver2/memory/UsedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.max | hiveserver2/memory/MaxNonHeapMemory | y |
Hive-Metastore-Messwerte
| Messwert | Name des Metrics Explorer | Aktivierte Messwerte |
|---|---|---|
| hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean | y |
| hivemetastore:API:CreateDatabase:Mean | hivemetastore/create_database/mean | y |
| hivemetastore:API:DropDatabase:Mean | hivemetastore/drop_database/mean | y |
| hivemetastore:API:AlterDatabase:Mean | hivemetastore/alter_database/mean | y |
| hivemetastore:API:GetAllDatabases:Mean | hivemetastore/get_all_databases/mean | y |
| hivemetastore:API:CreateTable:Mean | hivemetastore/create_table/mean | y |
| hivemetastore:API:DropTable:Mean | hivemetastore/drop_table/mean | y |
| hivemetastore:API:AlterTable:Mean | hivemetastore/alter_table/mean | y |
| hivemetastore:API:GetTable:Mean | hivemetastore/get_table/mean | y |
| hivemetastore:API:GetAllTables:Mean | hivemetastore/get_all_tables/mean | y |
| hivemetastore:API:AddPartitionsReq:Mean | hivemetastore/add_partitions_req/mean | y |
| hivemetastore:API:DropPartition:Mean | hivemetastore/drop_partition/mean | y |
| hivemetastore:API:AlterPartition:Mean | hivemetastore/alter_partition/mean | y |
| hivemetastore:API:GetPartition:Mean | hivemetastore/get_partition/mean | y |
| hivemetastore:API:GetPartitionNames:Mean | hivemetastore/get_partition_names/mean | y |
| hivemetastore:API:GetPartitionsPs:Mean | hivemetastore/get_partitions_ps/mean | y |
| hivemetastore:API:GetPartitionsPsWithAuth:Mean | hivemetastore/get_partitions_ps_with_auth/mean | y |
Hive-Metastore-Messwerte
| Statistische Messung | Beispielmesswert | Beispiel für einen Messwertnamen |
|---|---|---|
| Max. | hivemetastore:API:GetDatabase:Max | hivemetastore/get_database/max |
| Min. | hivemetastore:API:GetDatabase:Min | hivemetastore/get_database/min |
| Durchschnitt | hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean |
| Anzahl | hivemetastore:API:GetDatabase:Count | hivemetastore/get_database/count |
| 50. Perzentil | hivemetastore:API:GetDatabase:50thPercentile | hivemetastore/get_database/median |
| 75. Perzentil | hivemetastore:API:GetDatabase:75thPercentile | hivemetastore/get_database/75th_percentile |
| 95. Perzentil | hivemetastore:API:GetDatabase:95thPercentile | hivemetastore/get_database/95th_percentile |
| 98. Perzentil | hivemetastore:API:GetDatabase:98thPercentile | hivemetastore/get_database/98th_percentile |
| 99. Perzentil | hivemetastore:API:GetDatabase:99thPercentile | hivemetastore/get_database/99th_percentile |
| 999thPercentile | hivemetastore:API:GetDatabase:999thPercentile | hivemetastore/get_database/999th_percentile |
| StdDev | hivemetastore:API:GetDatabase:StdDev | hivemetastore/get_database/stddev |
| FifteenMinuteRate | hivemetastore:API:GetDatabase:FifteenMinuteRate | hivemetastore/get_database/15min_rate |
| FiveMinuteRate | hivemetastore:API:GetDatabase:FiveMinuteRate | hivemetastore/get_database/5min_rate |
| OneMinuteRate | hivemetastore:API:GetDatabase:OneMinuteRate | hivemetastore/get_database/1min_rate |
| MeanRate | hivemetastore:API:GetDatabase:MeanRate | hivemetastore/get_database/mean_rate |
Messwerte des Dataproc-Monitoring-Agents
Dataproc erfasst die folgenden Messwerte des Dataproc-Monitoring-Agents, wenn Sie --metric-sources=monitoring-agent-defaults festlegen.
Diese Messwerte werden mit dem Präfix agent.googleapis.com veröffentlicht.
CPU
agent.googleapis.com/cpu/load_15m
agent.googleapis.com/cpu/load_1m
agent.googleapis.com/cpu/load_5m
agent.googleapis.com/cpu/usage_time*
agent.googleapis.com/cpu/utilization*
Festplatte
agent.googleapis.com/disk/bytes_used
agent.googleapis.com/disk/io_time
agent.googleapis.com/disk/merged_operations
agent.googleapis.com/disk/operation_count
agent.googleapis.com/disk/operation_time
agent.googleapis.com/disk/pending_operations
agent.googleapis.com/disk/percent_used
agent.googleapis.com/disk/read_bytes_count
Swap
agent.googleapis.com/swap/bytes_used
agent.googleapis.com/swap/io
agent.googleapis.com/swap/percent_used
Arbeitsspeicher
agent.googleapis.com/memory/bytes_used
agent.googleapis.com/memory/percent_used
Prozesse: Für einige Attribute gelten eigene Kontingentrichtlinien.
agent.googleapis.com/processes/count_by_state
agent.googleapis.com/processes/cpu_time
agent.googleapis.com/processes/disk/read_bytes_count
agent.googleapis.com/processes/disk/write_bytes_count
agent.googleapis.com/processes/fork_count
agent.googleapis.com/processes/rss_usage
agent.googleapis.com/processes/vm_usage
Schnittstelle
agent.googleapis.com/interface/errors
agent.googleapis.com/interface/packets
agent.googleapis.com/interface/traffic
Netzwerk
agent.googleapis.com/network/tcp_connections
Monitoring-Dashboard erstellen
Sie können ein Monitoring-Dashboard erstellen, in dem Diagramme ausgewählter Dataproc-Messwerte angezeigt werden.
Wählen Sie + DASHBOARD ERSTELLEN auf der Monitoring-Seite Dashboard-Übersicht aus. Geben Sie einen Namen für das Dashboard ein und klicken Sie dann im Menü oben rechts auf Diagramm hinzufügen, um das Fenster "Diagramm hinzufügen" zu öffnen. Wählen Sie "Cloud Dataproc-Cluster" als Ressourcentyp aus. Wählen Sie mindestens einen Messwert und Messwert- und Diagrammattribute aus. Speichern Sie dann das Diagramm.

Sie können Ihrem Dashboard zusätzliche Diagramme hinzufügen. Nach dem Speichern des Dashboards, wird dessen Name auf der Monitoring-Seite Dashboard-Übersicht angezeigt. Dashboard-Diagramme können auf der Anzeigeseite des Dashboards angesehen, aktualisiert und gelöscht werden.