Questo documento mostra come creare una tabella Apache Iceberg con metadati nel metastore BigLake utilizzando il servizio Dataproc Jobs, la CLI Spark SQL o l'interfaccia web Zeppelin in esecuzione su un cluster Dataproc.
Prima di iniziare
Se non l'hai ancora fatto, crea un progetto, un bucket Cloud Storage e un cluster Dataproc. Google Cloud
Configurare il progetto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init Crea un bucket Cloud Storage nel tuo progetto.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Crea un cluster Dataproc. Per risparmiare risorse e costi, puoi creare un cluster Dataproc a un solo nodo per eseguire gli esempi presentati in questo documento.
La subnet nella regione in cui viene creato il cluster deve avere l'accesso privato Google (PGA) abilitato.
.Se vuoi eseguire l'esempio di interfaccia web Zeppelin in questa guida, devi utilizzare o creare un cluster Dataproc con il componente facoltativo Zeppelin abilitato.
Concedi ruoli a un service account personalizzato (se necessario): per impostazione predefinita, le VM del cluster Dataproc utilizzano l'account di servizio predefinito di Compute Engine per interagire con Dataproc. Se vuoi specificare un service account personalizzato quando crei il cluster, questo deve disporre del ruolo Dataproc Worker (
roles/dataproc.worker) o di un ruolo personalizzato con le autorizzazioni del ruolo Worker necessarie.In una finestra del terminale locale o in Cloud Shell, utilizza un editor di testo, ad esempio
vionano, per copiare i seguenti comandi in un fileiceberg-table.sql, quindi salva il file nella directory corrente.USE CATALOG_NAME; CREATE NAMESPACE IF NOT EXISTS example_namespace; USE example_namespace; DROP TABLE IF EXISTS example_table; CREATE TABLE example_table (id int, data string) USING ICEBERG LOCATION 'gs://BUCKET/WAREHOUSE_FOLDER'; INSERT INTO example_table VALUES (1, 'first row'); ALTER TABLE example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE example_table;
Sostituisci quanto segue:
- CATALOG_NAME: il nome del catalogo Iceberg.
- BUCKET e WAREHOUSE_FOLDER: bucket e cartella Cloud Storage utilizzati per il warehouse Iceberg.
Utilizza gcloud CLI per copiare il file locale
iceberg-table.sqlnel bucket in Cloud Storage.gcloud storage cp iceberg-table.sql gs://BUCKET/
In una finestra del terminale locale o in Cloud Shell, esegui il seguente comando
curlper scaricare il file JARiceberg-spark-runtime-3.5_2.12-1.6.1nella directory corrente.curl -o iceberg-spark-runtime-3.5_2.12-1.6.1.jar https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar
Utilizza gcloud CLI per copiare il file JAR
iceberg-spark-runtime-3.5_2.12-1.6.1locale dalla directory corrente al tuo bucket in Cloud Storage.gcloud storage cp iceberg-spark-runtime-3.5_2.12-1.6.1.jar gs://BUCKET/
Esegui il seguente comando gcloud dataproc jobs submit spark-sql localmente in una finestra del terminale locale o in Cloud Shell per inviare il job Spark SQL per creare la tabella Iceberg.
gcloud dataproc jobs submit spark-sql \ --project=PROJECT_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars="gs://BUCKET/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar" \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER" \ -f="gs://BUCKETiceberg-table.sql"
Note:
- PROJECT_ID: il tuo ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della Google Cloud console Dashboard.
- CLUSTER_NAME: il nome del cluster Dataproc.
- REGION: la regione di Compute Engine in cui si trova il cluster.
- CATALOG_NAME: il nome del catalogo Iceberg.
- BUCKET e WAREHOUSE_FOLDER: bucket e cartella Cloud Storage utilizzati per il warehouse Iceberg.
- LOCATION: una posizione BigQuery supportata. La località predefinita è "US".
--jars: i file JAR elencati sono necessari per creare i metadati della tabella in BigLake Metastore.--properties: Proprietà del catalogo.-f: il file di jobiceberg-table.sqlche hai copiato nel bucket in Cloud Storage.
Visualizza la descrizione della tabella nell'output del terminale al termine del job.
Time taken: 2.194 seconds id int data string newDoubleCol double Time taken: 1.479 seconds, Fetched 3 row(s) Job JOB_ID finished successfully.
Per visualizzare i metadati della tabella in BigQuery
Nella console Google Cloud , vai alla pagina BigQuery.
Visualizza i metadati della tabella Iceberg.
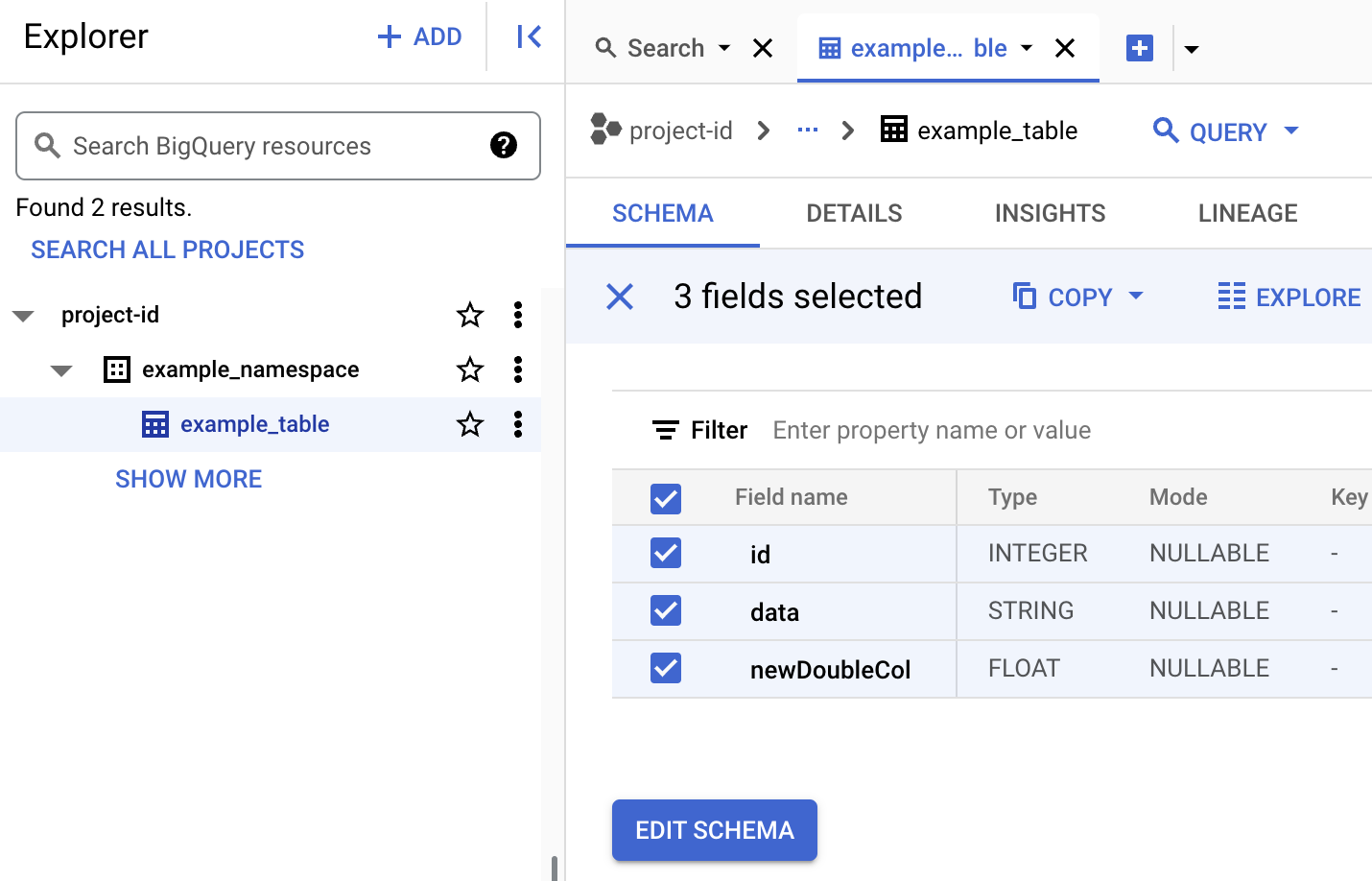
Nella console Google Cloud , vai a Dataproc Invia un job.
Vai alla pagina Invia un job, poi completa i seguenti campi:
- ID job: accetta l'ID suggerito o inserisci il tuo ID.
- Regione: seleziona la regione in cui si trova il cluster.
- Cluster: seleziona il cluster.
- Tipo di prestazione: seleziona
SparkSql. - Tipo di origine query: seleziona
Query file. - File di query: inserisci
gs://BUCKET/iceberg-table.sql - File jar: inserisci quanto segue:
gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar
- Proprietà: fai clic su Aggiungi proprietà
cinque volte per creare un elenco di cinque campi di input
keyvalue, poi copia le seguenti coppie Chiave e Valore per definire cinque proprietà.# Chiave Valore 1. spark.sql.catalog.CATALOG_NAMEorg.apache.iceberg.spark.SparkCatalog2. spark.sql.catalog.CATALOG_NAME.catalog-implorg.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog3. spark.sql.catalog.CATALOG_NAME.gcp_projectPROJECT_ID4. spark.sql.catalog.CATALOG_NAME.gcp_locationLOCATION5. spark.sql.catalog.CATALOG_NAME.warehousegs://BUCKET/WAREHOUSE_FOLDER
Note:
- CATALOG_NAME: il nome del catalogo Iceberg.
- PROJECT_ID: il tuo ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della Google Cloud console Dashboard. Regione in cui si trova il cluster.
- LOCATION: una posizione BigQuery supportata. La località predefinita è "US".
- BUCKET e WAREHOUSE_FOLDER: bucket e cartella Cloud Storage utilizzati per il warehouse Iceberg.
Fai clic su Invia.
Per monitorare l'avanzamento del job e visualizzare l'output, vai alla pagina Job di Dataproc nella console Google Cloud , poi fai clic su
Job IDper aprire la pagina Dettagli job.
Per visualizzare i metadati della tabella in BigQuery
Nella console Google Cloud , vai alla pagina BigQuery.
Visualizza i metadati della tabella Iceberg.
- PROJECT_ID: il tuo ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della Google Cloud console Dashboard.
- CLUSTER_NAME: il nome del cluster Dataproc.
- REGION: la regione Compute Engine in cui si trova il cluster.
- CATALOG_NAME: il nome del catalogo Iceberg.
- BUCKET e WAREHOUSE_FOLDER: bucket Cloud Storage e cartella utilizzati per il warehouse Iceberg. LOCATION: una posizione BigQuery supportata. La località predefinita è "US".
jarFileUris: i file JAR elencati sono necessari per creare i metadati della tabella in BigQuery Metastore.properties: Proprietà del catalogo.queryFileUri: il file di jobiceberg-table.sqlche hai copiato nel bucket in Cloud Storage.Nella console Google Cloud , vai alla pagina BigQuery.
Visualizza i metadati della tabella Iceberg.
Utilizza SSH per connetterti al nodo master del cluster Dataproc.
Nel terminale della sessione SSH, utilizza l'editor di testo
vionanoper copiare i seguenti comandi in un fileiceberg-table.sql.SET CATALOG_NAME = `CATALOG_NAME`; SET BUCKET = `BUCKET`; SET WAREHOUSE_FOLDER = `WAREHOUSE_FOLDER`; USE `${CATALOG_NAME}`; CREATE NAMESPACE IF NOT EXISTS `${CATALOG_NAME}`.example_namespace; DROP TABLE IF EXISTS `${CATALOG_NAME}`.example_namespace.example_table; CREATE TABLE `${CATALOG_NAME}`.example_namespace.example_table (id int, data string) USING ICEBERG LOCATION 'gs://${BUCKET}/${WAREHOUSE_FOLDER}'; INSERT INTO `${CATALOG_NAME}`.example_namespace.example_table VALUES (1, 'first row'); ALTER TABLE `${CATALOG_NAME}`.example_namespace.example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE `${CATALOG_NAME}`.example_namespace.example_table;Sostituisci quanto segue:
- CATALOG_NAME: il nome del catalogo Iceberg.
- BUCKET e WAREHOUSE_FOLDER: bucket e cartella Cloud Storage utilizzati per il warehouse Iceberg.
Nel terminale della sessione SSH, esegui il seguente comando
spark-sqlper creare la tabella Iceberg.spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1 \ --jars https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog \ --conf spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID \ --conf spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION \ --conf spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER \ -f iceberg-table.sql
Sostituisci quanto segue:
- PROJECT_ID: il tuo ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della Google Cloud console Dashboard.
- LOCATION: una posizione BigQuery supportata. La località predefinita è "US".
Visualizzare i metadati della tabella in BigQuery
Nella console Google Cloud , vai alla pagina BigQuery.
Visualizza i metadati della tabella Iceberg.
Nella console Google Cloud , vai alla pagina Cluster di Dataproc.
Seleziona il nome del cluster per aprire la pagina Dettagli cluster.
Fai clic sulla scheda Interfacce web per visualizzare un elenco di link del gateway dei componenti alle interfacce web dei componenti predefiniti e facoltativi installati sul cluster.
Fai clic sul link Zeppelin per aprire l'interfaccia web di Zeppelin.
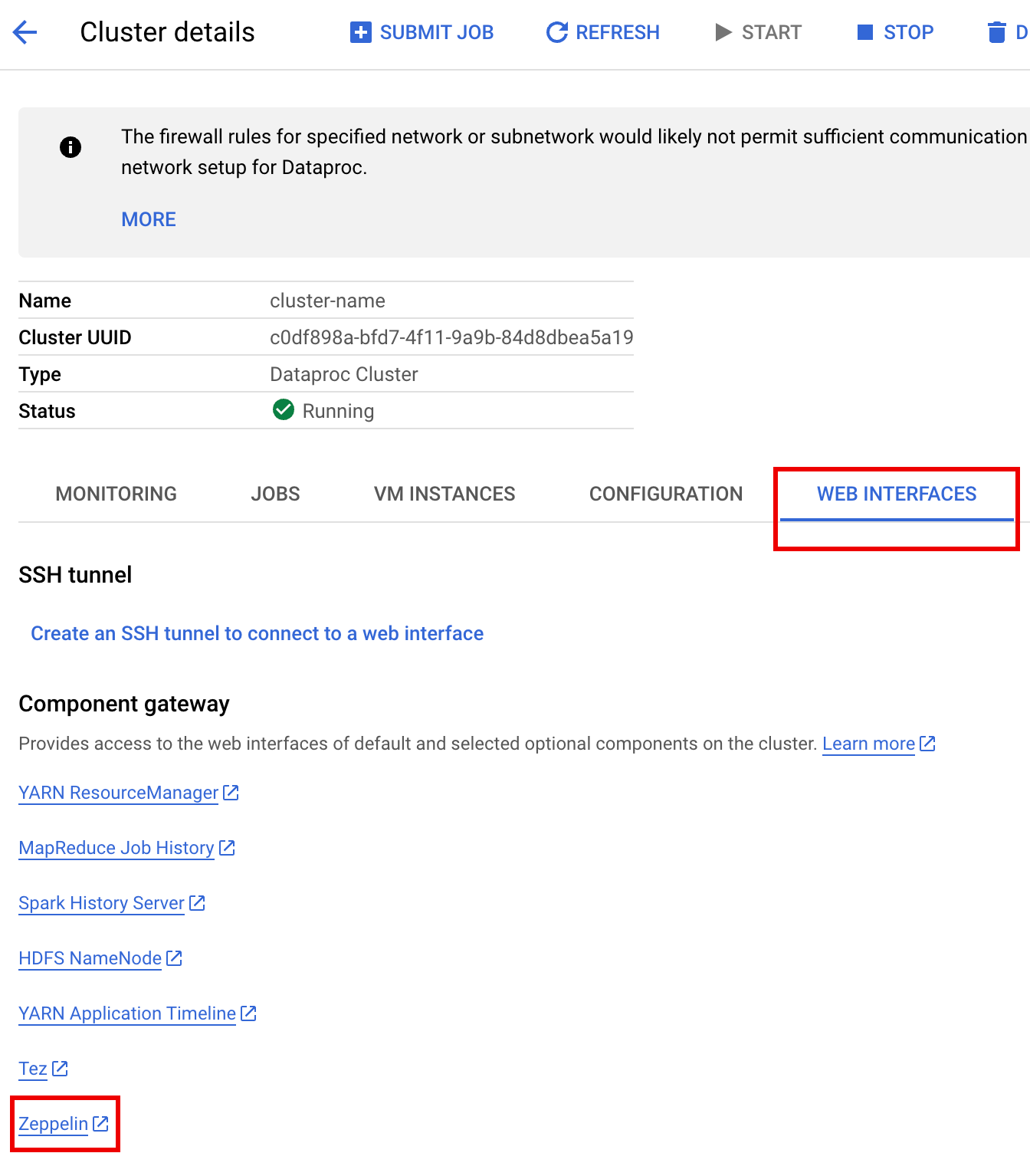
Nell'interfaccia web di Zeppelin, fai clic sul menu anonimo, poi su Interprete per aprire la pagina Interpreti.
Aggiungi due file JAR all'interprete Zeppelin Spark nel seguente modo:
- Digita "Spark" nella casella
Search interpretersper scorrere fino alla sezione dell'interprete Spark. - Fai clic su edit (modifica).
Incolla quanto segue nel campo spark.jars:
https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar

Fai clic su Salva nella parte inferiore della sezione dell'interprete Spark, quindi fai clic su Ok per aggiornare l'interprete e riavviarlo con le nuove impostazioni.
- Digita "Spark" nella casella
Dal menu del notebook Zeppelin, fai clic su Crea nuova nota.
Nella finestra di dialogo Crea nuovo blocco note, inserisci un nome per il blocco note e accetta l'interprete spark predefinito. Fai clic su Crea per aprire il notebook.
Copia il seguente codice PySpark nel notebook Zeppelin dopo aver compilato le variabili.
%pyspark
from pyspark.sql import SparkSession
project_id = "PROJECT_ID" catalog = "CATALOG_NAME" namespace = "NAMESPACE" location = "LOCATION" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY"
spark = SparkSession.builder \ .appName("BigQuery Metastore Iceberg") \ .config(f"spark.sql.catalog.{catalog}", "org.apache.iceberg.spark.SparkCatalog") \ .config(f"spark.sql.catalog.{catalog}.catalog-impl", "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog") \ .config(f"spark.sql.catalog.{catalog}.gcp_project", f"{project_id}") \ .config(f"spark.sql.catalog.{catalog}.gcp_location", f"{location}") \ .config(f"spark.sql.catalog.{catalog}.warehouse", f"{warehouse_dir}") \ .getOrCreate()
spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;")
\# Create table and display schema (without LOCATION) spark.sql("DROP TABLE IF EXISTS example_iceberg_table") spark.sql("CREATE TABLE example_iceberg_table (id int, data string) USING ICEBERG") spark.sql("DESCRIBE example_iceberg_table;")
\# Insert table data. spark.sql("INSERT INTO example_iceberg_table VALUES (1, 'first row');")
\# Alter table, then display schema. spark.sql("ALTER TABLE example_iceberg_table ADD COLUMNS (newDoubleCol double);")
\# Select and display the contents of the table. spark.sql("SELECT * FROM example_iceberg_table").show()Sostituisci quanto segue:
- PROJECT_ID: il tuo ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della Google Cloud console Dashboard.
- CATALOG_NAME e NAMESPACE: il nome e lo spazio dei nomi del catalogo Iceberg si combinano per identificare la tabella Iceberg (
catalog.namespace.table_name). - LOCATION: una posizione BigQuery supportata. La località predefinita è "US".
- BUCKET e WAREHOUSE_DIRECTORY: bucket Cloud Storage e cartella utilizzati come directory del warehouse Iceberg.
Fai clic sull'icona di esecuzione o premi
Shift-Enterper eseguire il codice. Al termine del job, il messaggio di stato indica "Spark Job Finished" e l'output mostra i contenuti della tabella:
Visualizzare i metadati della tabella in BigQuery
Nella console Google Cloud , vai alla pagina BigQuery.
Visualizza i metadati della tabella Iceberg.
Mappatura del database OSS al set di dati BigQuery
Tieni presente il seguente mapping tra i termini del database open source e del set di dati BigQuery:
Database OSS BigQuery dataset Spazio dei nomi, database Set di dati Tabella partizionata o non partizionata Tabella Visualizza Visualizza Creare una tabella Iceberg
Questa sezione mostra come creare una tabella Iceberg con metadati nel metastore BigLake inviando un codice Spark SQL al servizio Dataproc, all'interfaccia a riga di comando Spark SQL e all'interfaccia web del componente Zeppelin, che vengono eseguiti su un cluster Dataproc.
Job Dataproc
Puoi inviare un job al servizio Dataproc inviandolo a un cluster Dataproc utilizzando la Google Cloud console o Google Cloud CLI, oppure tramite una richiesta REST HTTP o una chiamata programmatica gRPC alle librerie client Cloud dell'API Dataproc Jobs.
Gli esempi in questa sezione mostrano come inviare un job Spark SQL Dataproc al servizio Dataproc per creare una tabella Iceberg con metadati in BigQuery utilizzando gcloud CLI, la console Google Cloud o l'API REST Dataproc.
Preparare i file di job
Per creare un file di job Spark SQL, segui questi passaggi. Il file contiene comandi Spark SQL per creare e aggiornare una tabella Iceberg.
Successivamente, scarica e copia il file JAR
iceberg-spark-runtime-3.5_2.12-1.6.1in Cloud Storage.Invia il job Spark SQL
Seleziona una scheda per seguire le istruzioni per inviare il job Spark SQL al servizio Dataproc utilizzando gcloud CLI, la consoleGoogle Cloud o l'API REST Dataproc.
gcloud
Console
Segui questi passaggi per utilizzare la console Google Cloud per inviare il job Spark SQL al servizio Dataproc per creare una tabella Iceberg con metadati nel metastore BigLake.
REST
Puoi utilizzare l'API Dataproc jobs.submit per inviare il job Spark SQL al servizio Dataproc per creare una tabella Iceberg con metadati in BigLake Metastore.
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
Metodo HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Corpo JSON della richiesta:
{ "projectId": "PROJECT_ID", "job": { "placement": { "clusterName": "CLUSTER_NAME" }, "statusHistory": [], "reference": { "jobId": "", "projectId": "PROJECT_ID" }, "sparkSqlJob": { "properties": { "spark.sql.catalog."CATALOG_NAME": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog."CATALOG_NAME".catalog-impl": "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog", "spark.sql.catalog."CATALOG_NAME".gcp_project": "PROJECT_ID", "spark.sql.catalog."CATALOG_NAME".gcp_location": "LOCATION", "spark.sql.catalog."CATALOG_NAME".warehouse": "gs://BUCKET/WAREHOUSE_FOLDER" }, "jarFileUris": [ "gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.5.2.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.5.2-1.0.1-beta.jar" ], "scriptVariables": {}, "queryFileUri": "gs://BUCKET/iceberg-table.sql" } } }Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{ "reference": { "projectId": "PROJECT_ID", "jobId": "..." }, "placement": { "clusterName": "CLUSTER_NAME", "clusterUuid": "..." }, "status": { "state": "PENDING", "stateStartTime": "..." }, "submittedBy": "USER", "sparkSqlJob": { "queryFileUri": "gs://BUCKET/iceberg-table.sql", "properties": { "spark.sql.catalog.USER_catalog": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.USER_catalog.catalog-impl": "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog", "spark.sql.catalog.USER_catalog.gcp_project": "PROJECT_ID", "spark.sql.catalog.USER_catalog.gcp_location": "LOCATION", "spark.sql.catalog.USER_catalog.warehouse": "gs://BUCKET/WAREHOUSE_FOLDER" }, "jarFileUris": [ "gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.5.2.jar", "gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.5.2-1.0.1-beta.jar" ] }, "driverControlFilesUri": "gs://dataproc-...", "driverOutputResourceUri": "gs://dataproc-.../driveroutput", "jobUuid": "...", "region": "REGION" }Per monitorare l'avanzamento del job e visualizzare l'output, vai alla pagina Job di Dataproc nella console Google Cloud , poi fai clic su
Job IDper aprire la pagina Dettagli job.
Per visualizzare i metadati della tabella in BigQuery
CLI Spark SQL
I seguenti passaggi mostrano come creare una tabella Iceberg con i metadati della tabella memorizzati in BigLake Metastore utilizzando Spark SQL CLI in esecuzione sul nodo master di un cluster Dataproc.
Interfaccia web di Zeppelin
I seguenti passaggi mostrano come creare una tabella Iceberg con metadati della tabella archiviati in BigLake Metastore utilizzando l'interfaccia web Zeppelin in esecuzione sul nodo master di un cluster Dataproc .