Vous pouvez créer une alerte Monitoring qui vous avertit lorsqu'une métrique de cluster ou de tâche Dataproc dépasse un seuil spécifié.
Créer une alerte
Ouvrez la page Alertes dans la console Google Cloud .
Cliquez sur + Créer une règle pour ouvrir la page Créer une règle d'alerte.
- Cliquez sur Sélectionner une métrique.
- Dans la zone de saisie "Filtrer par nom de ressource ou de métrique", saisissez "dataproc" pour lister les métriques Dataproc. Parcourez la hiérarchie des métriques Cloud Dataproc pour sélectionner une métrique de cluster, de job, de lot ou de session.
- Cliquez sur Appliquer.
- Cliquez sur Suivant pour ouvrir le volet Configurer le déclencheur d'alerte.
- Définissez une valeur de seuil pour déclencher l'alerte.
- Cliquez sur Suivant pour ouvrir le volet Configurer les notifications et finaliser l'alerte.
- Définissez les canaux de notification, la documentation et le nom de la règle d'alerte.
- Cliquez sur Suivant pour examiner la règle d'alerte.
- Cliquez sur Créer une règle pour créer l'alerte.
Exemples d'alertes
Cette section décrit un exemple d'alerte pour une tâche envoyée au service Dataproc et une alerte pour une tâche exécutée en tant qu'application YARN.
Alerte de tâche Dataproc de longue durée
Dataproc émet la métrique dataproc.googleapis.com/job/state, qui suit la durée pendant laquelle une tâche est restée dans différents états. Cette métrique se trouve dans l'explorateur de métriques de la console Google Cloud , sous la ressource Job Cloud Dataproc (cloud_dataproc_job).
Vous pouvez utiliser cette métrique pour configurer une alerte qui vous avertit lorsque l'état RUNNING du job dépasse un seuil de durée.
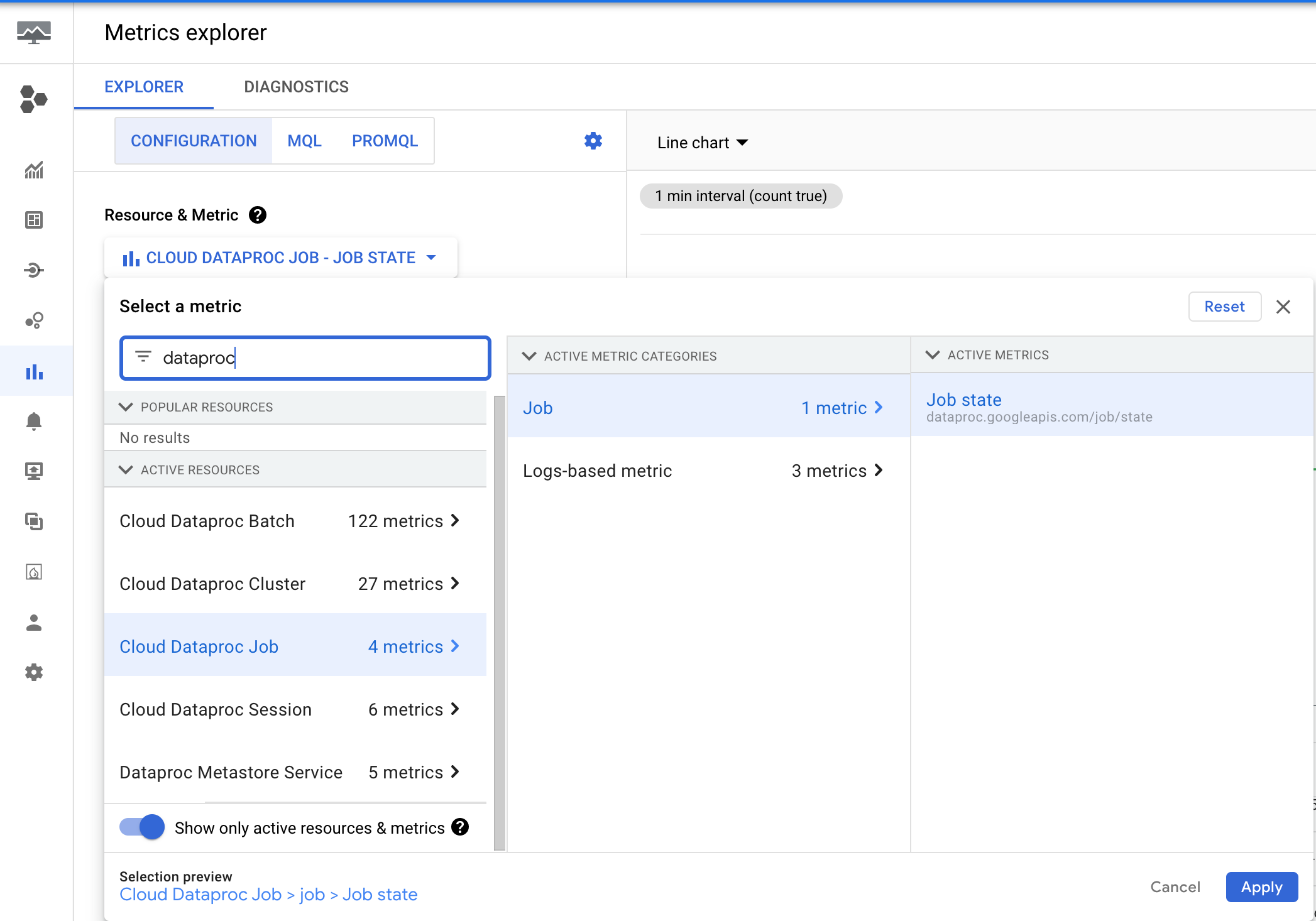
Configurer une alerte de durée de tâche
Cet exemple utilise le Monitoring Query Language (MQL) pour créer une règle d'alerte (voir Créer des règles d'alerte MQL (console)).
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'RUNNING'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Dans l'exemple suivant, l'alerte se déclenche lorsqu'un job est en cours d'exécution depuis plus de 30 minutes.
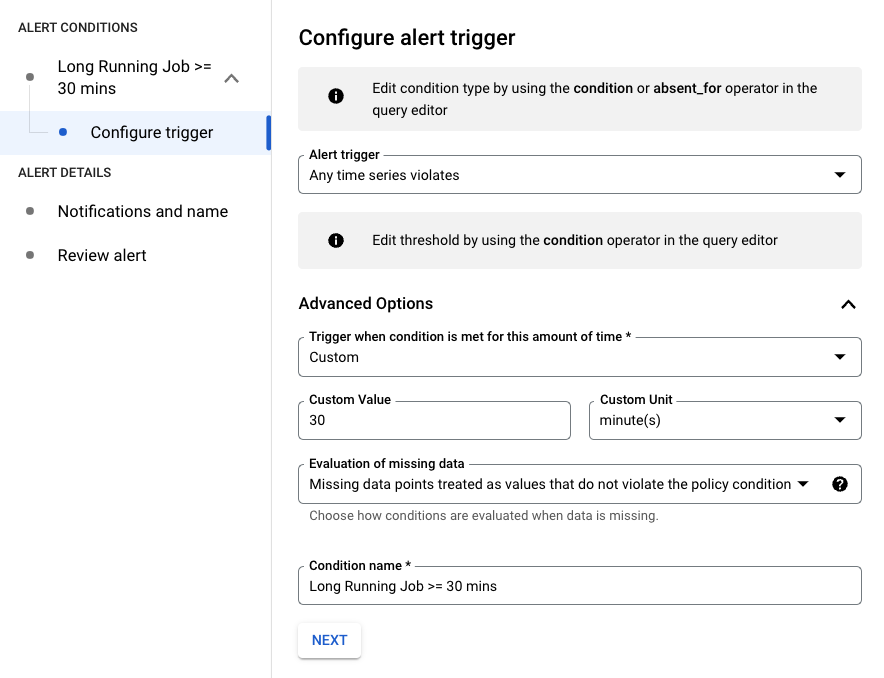
Vous pouvez modifier la requête en filtrant sur resource.job_id pour l'appliquer à une tâche spécifique :
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'RUNNING')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Alerte d'application YARN de longue durée
L'exemple précédent montre une alerte déclenchée lorsqu'un job Dataproc s'exécute plus longtemps qu'une durée spécifiée, mais il ne s'applique qu'aux jobs envoyés au service Dataproc à l'aide de la console Google Cloud , de la Google Cloud CLI ou par des appels directs à l'API jobs Dataproc. Vous pouvez également utiliser des métriques OSS pour configurer des alertes similaires qui surveillent la durée d'exécution des applications YARN.
Commençons par quelques informations de contexte. YARN émet des métriques de durée d'exécution dans plusieurs buckets.
Par défaut, YARN conserve 60, 300 et 1 440 minutes comme seuils de bucket et émet quatre métriques : running_0, running_60, running_300 et running_1440.
running_0enregistre le nombre de jobs dont la durée d'exécution est comprise entre 0 et 60 minutes.running_60enregistre le nombre de jobs dont la durée d'exécution est comprise entre 60 et 300 minutes.running_300enregistre le nombre de jobs dont la durée d'exécution est comprise entre 300 et 1 440 minutes.running_1440enregistre le nombre de jobs dont la durée d'exécution est supérieure à 1 440 minutes.
Par exemple, un job exécuté pendant 72 minutes sera enregistré dans running_60, mais pas dans running_0.
Ces seuils de bucket par défaut peuvent être modifiés en transmettant de nouvelles valeurs à la propriété de cluster yarn:yarn.resourcemanager.metrics.runtime.buckets lors de la création du cluster Dataproc. Lorsque vous définissez des seuils de buckets personnalisés, vous devez également définir des remplacements de métriques. Par exemple, pour spécifier des seuils de bucket de 30, 60 et 90 minutes, la commande gcloud dataproc clusters create doit inclure les indicateurs suivants :
Seuils de bucket :
‑‑properties=yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90Remplacements de métriques :
‑‑metric-overrides=yarn:ResourceManager:QueueMetrics:running_0, yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60, yarn:ResourceManager:QueueMetrics:running_90
Exemple de commande de création de cluster
gcloud dataproc clusters create test-cluster \ --properties ^#^yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90 \ --metric-sources=yarn \ --metric-overrides=yarn:ResourceManager:QueueMetrics:running_0,yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60,yarn:ResourceManager:QueueMetrics:running_90
Ces métriques sont listées dans l'explorateur de métriques de la console Google Cloud sous la ressource Instance de VM (gce_instance).
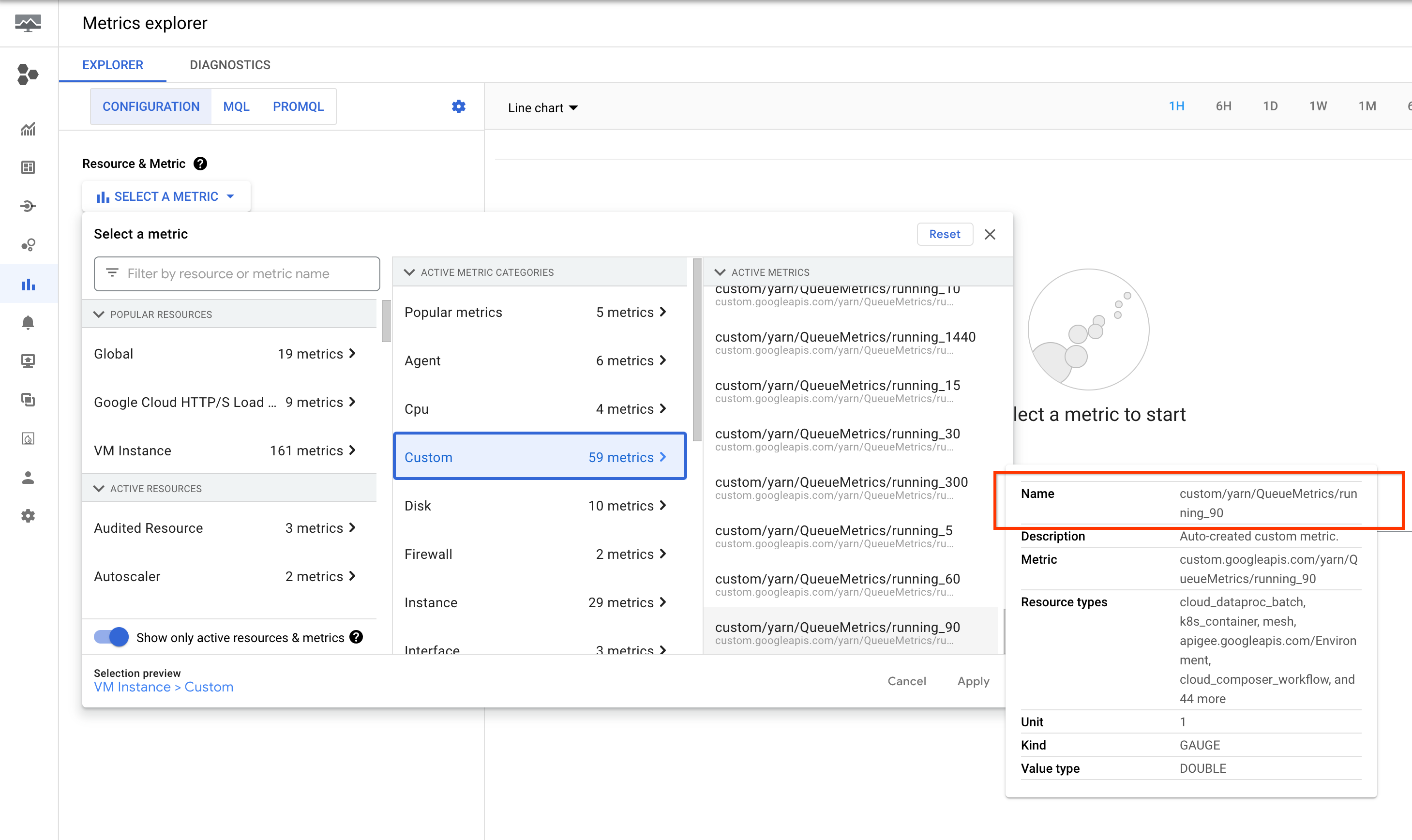
Configurer des alertes pour les applications YARN
Créez un cluster avec les buckets et les métriques requis activés.
Créez une règle d'alerte qui se déclenche lorsque le nombre d'applications dans un bucket de métriques YARN dépasse un seuil spécifié.
Vous pouvez également ajouter un filtre pour recevoir des alertes sur les clusters qui correspondent à un modèle.
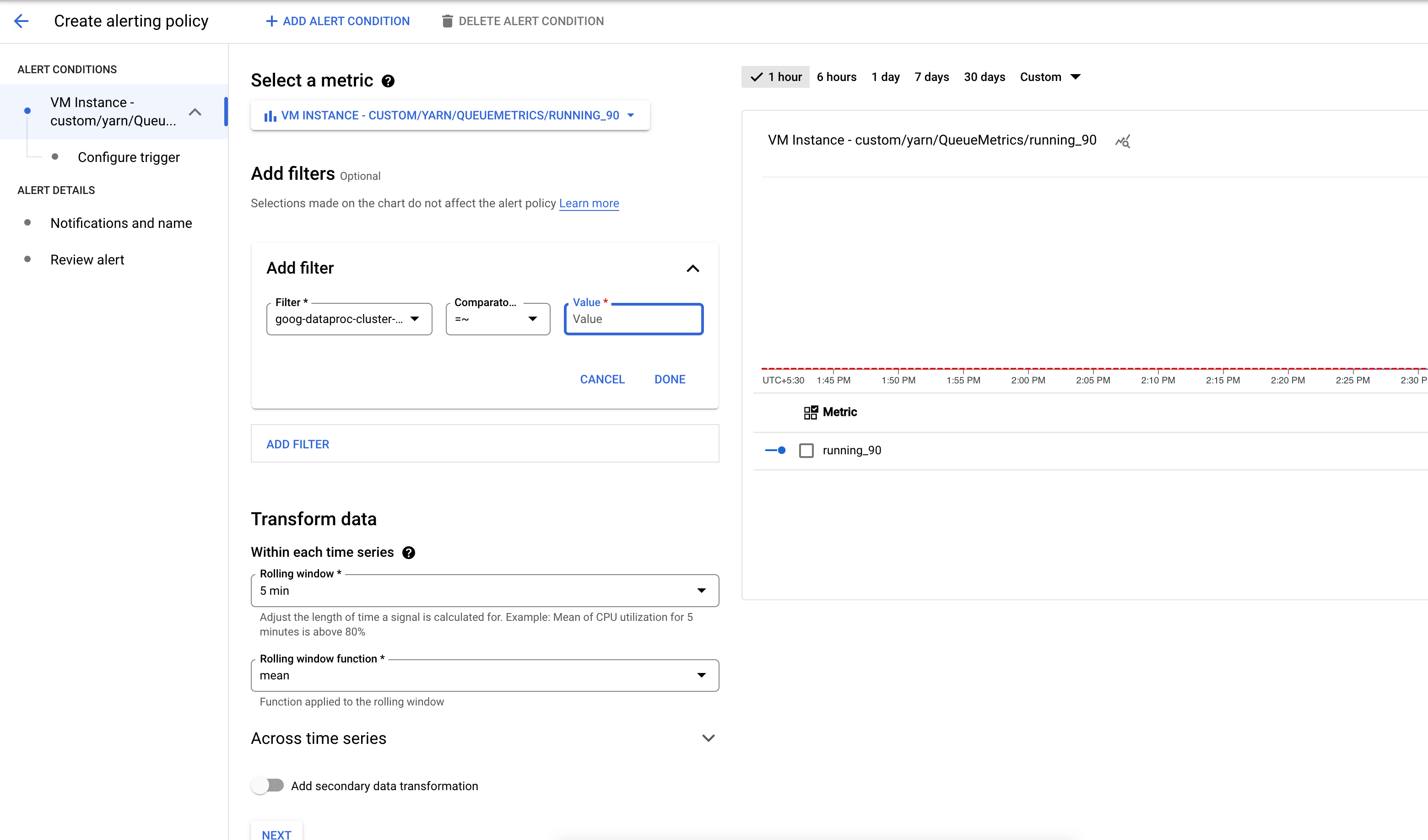
Configurez le seuil de déclenchement de l'alerte.
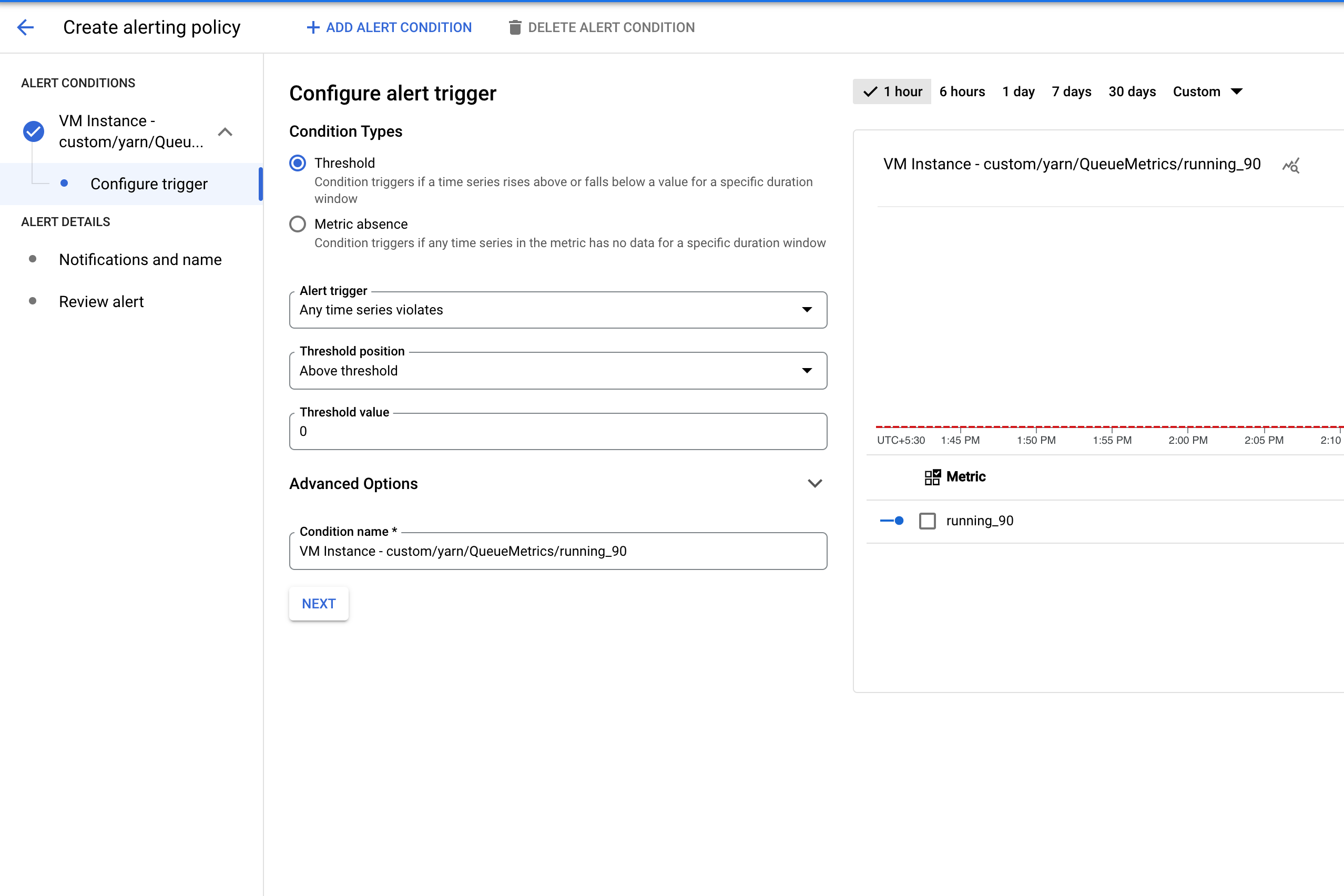
Alerte d'échec de tâche Dataproc
Vous pouvez également utiliser la métrique dataproc.googleapis.com/job/state (voir Alerte de job Dataproc de longue durée) pour recevoir une alerte en cas d'échec d'un job Dataproc.
Échec de la configuration des alertes d'emploi
Cet exemple utilise le Monitoring Query Language (MQL) pour créer une règle d'alerte (voir Créer des règles d'alerte MQL (console)).
Langage MQL des alertes
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'ERROR'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Configuration du déclencheur d'alerte
Dans l'exemple suivant, l'alerte se déclenche en cas d'échec d'un job Dataproc dans votre projet.
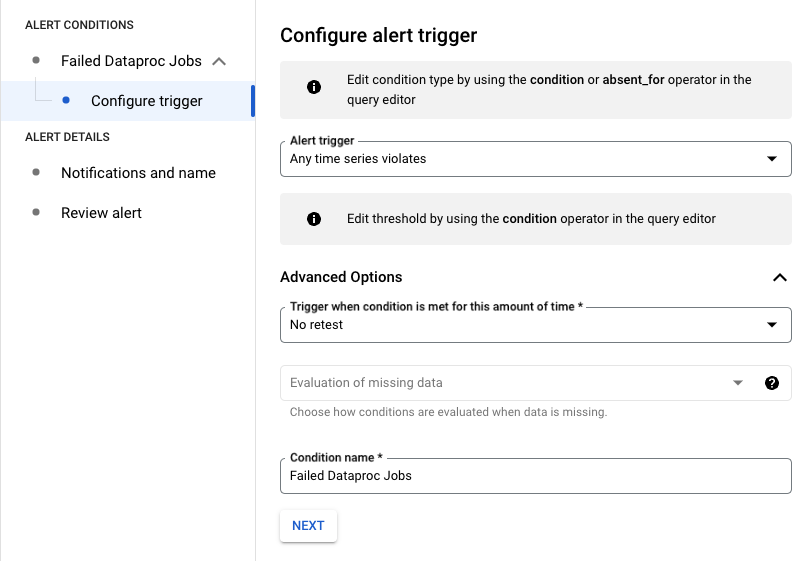
Vous pouvez modifier la requête en filtrant sur resource.job_id pour l'appliquer à une tâche spécifique :
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'ERROR')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Alerte de déviation de la capacité du cluster
Dataproc émet la métrique dataproc.googleapis.com/cluster/capacity_deviation, qui indique la différence entre le nombre de nœuds attendu dans le cluster et le nombre de nœuds YARN actifs. Vous trouverez cette métrique dans l'explorateur de métriques de la consoleGoogle Cloud , sous la ressource Cluster Cloud Dataproc. Vous pouvez utiliser cette métrique pour créer une alerte qui vous avertit lorsque la capacité du cluster s'écarte de la capacité attendue pendant une durée supérieure à un seuil spécifié.
Les opérations suivantes peuvent entraîner une sous-déclaration temporaire des nœuds de cluster dans la métrique capacity_deviation. Pour éviter les alertes de faux positifs, définissez le seuil d'alerte de métrique en tenant compte de ces opérations :
Création et mise à jour de clusters : la métrique
capacity_deviationn'est pas émise lors des opérations de création ou de mise à jour de clusters.Actions d'initialisation de cluster : les actions d'initialisation sont effectuées après le provisionnement d'un nœud.
Mises à jour des nœuds de calcul secondaires : les nœuds de calcul secondaires sont ajoutés de manière asynchrone, une fois l'opération de mise à jour terminée.
Configurer des alertes de variation de capacité
Cet exemple utilise le Monitoring Query Language (MQL) pour créer une règle d'alerte.
fetch cloud_dataproc_cluster
| metric 'dataproc.googleapis.com/cluster/capacity_deviation'
| every 1m
| condition val() <> 0 '1'
Dans l'exemple suivant, l'alerte se déclenche lorsque la variation de capacité du cluster est non nulle pendant plus de 30 minutes.
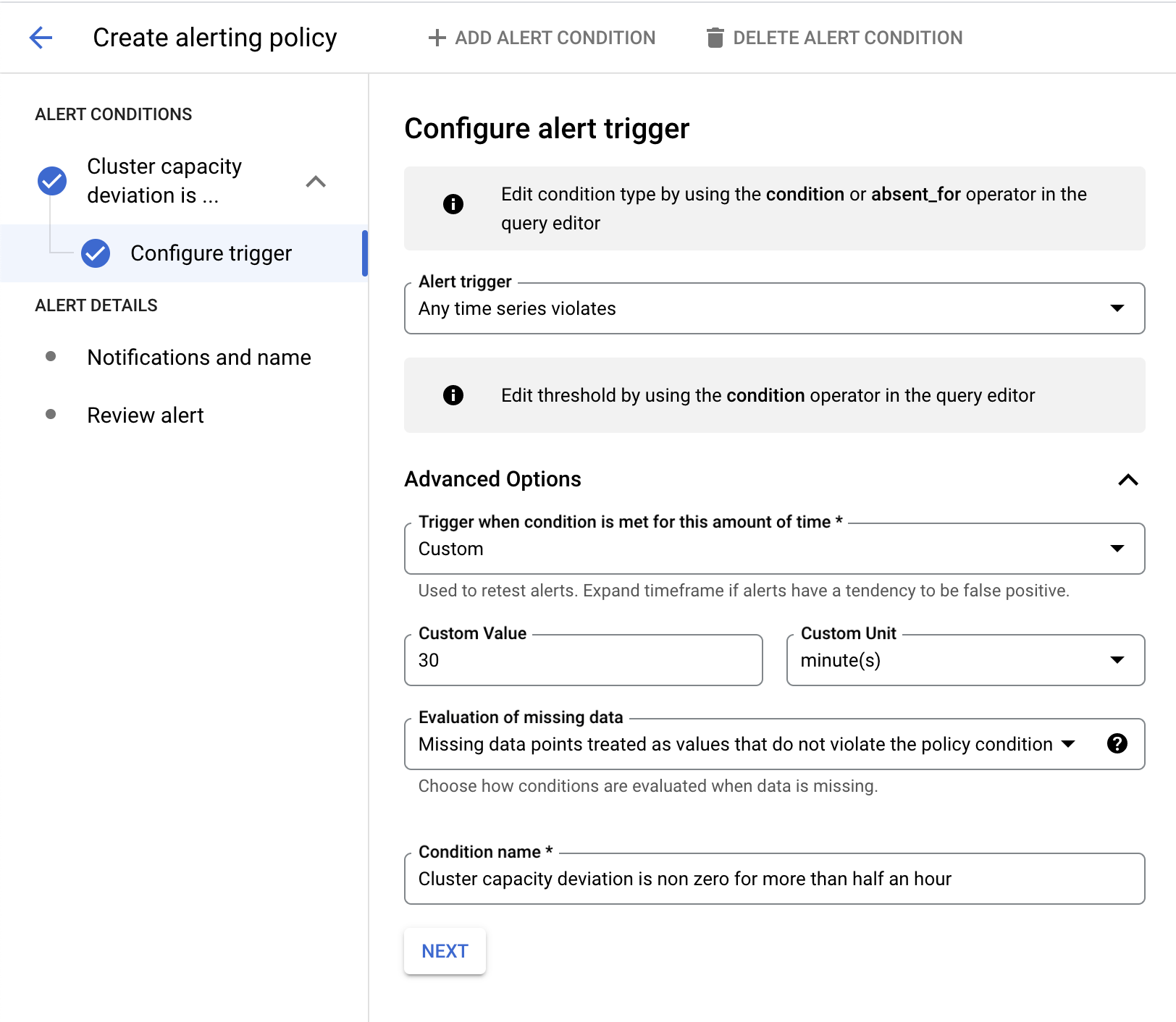
Afficher les alertes
Lorsqu'une condition de seuil de métrique déclenche une alerte, Monitoring crée un incident (et un événement correspondant). Vous pouvez afficher les incidents à partir de la page Alertes Monitoring dans la console Google Cloud .
Si vous avez spécifié un mécanisme de notification dans la règle d'alerte, telle qu'une notification par e-mail ou SMS, Monitoring envoie une notification de l'incident.
Étapes suivantes
- Consultez la présentation des alertes.