Dataproc クラスタを作成すると、クラスタ内のプライマリ ワーカーノードまたはセカンダリ ワーカーノードの数を増減して(水平スケーリング)、クラスタを調整(スケール)できます。Dataproc クラスタは、クラスタでジョブを実行している場合も含めいつでもスケールできます。既存のクラスタのマシンタイプは変更できません(垂直スケーリング)。垂直方向にスケーリングするには、サポートされているマシンタイプを使用してクラスタを作成してから、ジョブを新しいクラスタに移行します。
Dataproc クラスタは、次の目的でスケーリングできます。
- ワーカーの数を増やしてジョブの実行時間を短縮するため。
- ワーカーの数を減らして費用を節減するため(進行中の作業が失われないようにクラスタを小さくする場合に使用するオプションとしては、正常なデコミッションをご覧ください)。
- ノードの数を増やして使用可能な Hadoop Distributed File System(HDFS)ストレージを拡大するため。
クラスタは何度でもスケールできるため、一度にまとめてクラスタサイズを増減し、その後様子を見ながら増減して調整することをおすすめします。
スケーリングを使用する
Dataproc クラスタをスケールするには、次の 3 つの方法があります。
- gcloud CLI で
gcloudコマンドライン ツールを使用します。 - Google Cloud コンソールでクラスタ構成を編集します。
- REST API を使用します。
新しくクラスタに追加したワーカーでは、既存のワーカーと同じマシンタイプが使用されます。たとえば、n1-standard-8 マシンタイプを使用するワーカーを含めてクラスタを作成した場合、新しいワーカーも n1-standard-8 マシンタイプを使用します。
プライマリ ワーカーの数またはセカンダリ(プリエンプティブル)ワーカーの数、あるいはその両方をスケールできます。たとえば、プリエンプティブル ワーカーの数だけをスケールした場合、プライマリ ワーカーの数は同じままです。
gcloud
gcloud dataproc clusters update を使用してクラスタを作成するには、次のコマンドを実行します。gcloud dataproc clusters update cluster-name \ --region=region \ [--num-workers and/or --num-secondary-workers]=new-number-of-workers
gcloud dataproc clusters update dataproc-1 \
--region=region \
--num-workers=5
...
Waiting on operation [operations/projects/project-id/operations/...].
Waiting for cluster update operation...done.
Updated [https://dataproc.googleapis.com/...].
clusterName: my-test-cluster
...
masterDiskConfiguration:
bootDiskSizeGb: 500
masterName: dataproc-1-m
numWorkers: 5
...
workers:
- my-test-cluster-w-0
- my-test-cluster-w-1
- my-test-cluster-w-2
- my-test-cluster-w-3
- my-test-cluster-w-4
...
REST API
clusters.patch をご覧ください。
例
PATCH /v1/projects/project-id/regions/us-central1/clusters/example-cluster?updateMask=config.worker_config.num_instances,config.secondary_worker_config.num_instances
{
"config": {
"workerConfig": {
"numInstances": 4
},
"secondaryWorkerConfig": {
"numInstances": 2
}
},
"labels": null
}
コンソール
クラスタの作成後にクラスタをスケーリングするには、Google Cloud コンソールの [クラスタ] ページから [クラスタ] ページを開き、[構成] タブの [編集] ボタンをクリックします。 [ワーカーノード] や [プリエンプティブル ワーカーノード] の数の新しい値を入力します(次のスクリーンショットでは、それぞれ「5」と「2」に更新しています)。
[ワーカーノード] や [プリエンプティブル ワーカーノード] の数の新しい値を入力します(次のスクリーンショットでは、それぞれ「5」と「2」に更新しています)。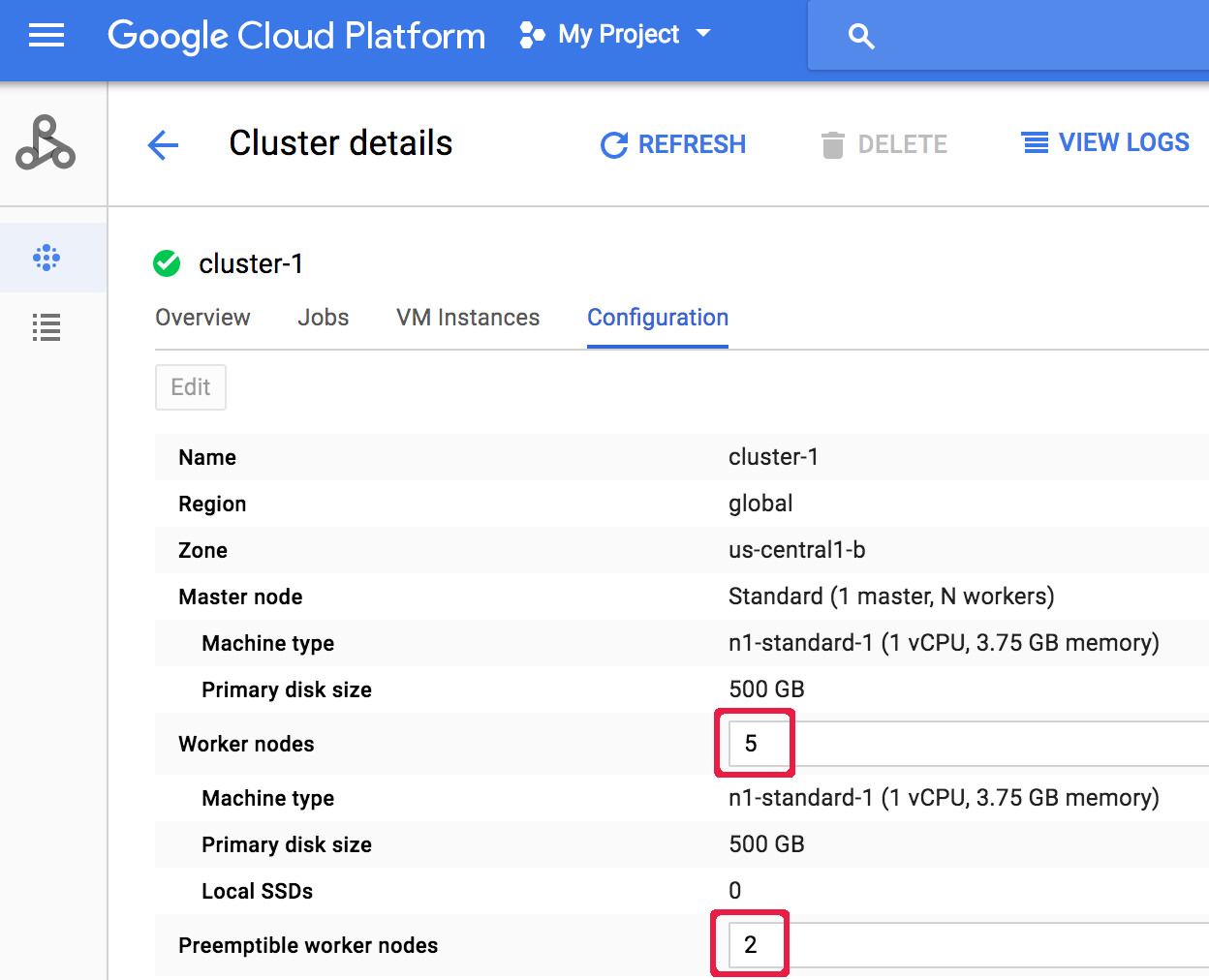 [保存] をクリックしてクラスタを更新します
[保存] をクリックしてクラスタを更新しますDataproc が削除するクラスタノードを選択する方法
クラスタのスケールダウン時に、イメージ バージョン 1.5.83+、2.0.57+、2.1.5+ で作成されたクラスタで、Dataproc は非アクティブで異常なアイドル状態のノードを削除してから、実行中の YARN アプリケーション マスターと実行中のコンテナが最も少ないノードを削除して、実行中の YARN アプリケーションでのノードの削除の影響を最小限に抑えようとします。
正常なデコミッション
クラスタをダウンスケールすると、進行中の作業が完了前に終了することがあります。Dataproc v 1.2 以降を使用している場合は、正常なデコミッションを使用できます。これには YARN ノードの正常なデコミッションが組み込まれていて、ワーカーを Cloud Dataproc クラスタから削除する前に、そのワーカーで進行中の作業を終了します。
正常なデコミッションとセカンダリ ワーカー
プリエンプティブル(セカンダリ)ワーカー グループは、クラスタ スケーリングのオペレーションに完了のマークが付いた後も、想定サイズに達するまでワーカーのプロビジョニングまたは削除を続行します。セカンダリ ワーカーを正常にデコミッションしようとすると、次のようなエラー メッセージが表示される場合があります。
「セカンダリ ワーカー グループを Dataproc の外部で変更することはできません。最近このクラスタを作成または更新した場合は、正常なデコミッションによりすべてのセカンダリ インスタンスがこのクラスタに参加または離脱できるようになるまでしばらくお待ちください。想定されているセカンダリ ワーカー グループ サイズは x で、実際のサイズは y です」
この場合、数分間待ってから正常なデコミッションのリクエストを繰り返してください。
正常なデコミッションの使用
Dataproc の正常なデコミッションには YARN ノードの正常なデコミッションが組み込まれていて、ワーカーを Cloud Dataproc クラスタから削除する前に、そのワーカーで進行中の作業を終了します。デフォルトでは、正常なデコミッションは無効になっています。この機能を有効にするには、クラスタから 1 つ以上のワーカーを削除するようにクラスタを更新する際に、タイムアウト値を設定します。
gcloud
クラスタを更新して 1 つ以上のワーカーを削除する場合は、--graceful-decommission-timeout フラグを指定して gcloud dataproc clusters update コマンドを使用します。タイムアウト(文字列)値は、「0」(デフォルト、正常ではなく強制的なデコミッション)または現在の時刻を基準とする正の期間(たとえば「3s」)にすることができます。期間の最大値は 1 日です。
gcloud dataproc clusters update cluster-name \ --region=region \ --graceful-decommission-timeout="timeout-value" \ [--num-workers and/or --num-secondary-workers]=decreased-number-of-workers \ ... other args ...
REST API
clusters.patch.gracefulDecommissionTimeout をご覧ください。タイムアウト(文字列)値は、「0」(デフォルト、正常ではなく強制的なデコミッション)または秒単位の期間(たとえば「3s」)にすることができます。期間の最大値は 1 日です。コンソール
クラスタの作成後にクラスタの正常なデコミッションを選択するには、Google Cloud コンソールの [クラスタ] ページからクラスタの [クラスタの詳細] ページを開き、[構成] タブの [編集] ボタンをクリックします。
[正常なデコミッション] セクションで、[正常なデコミッションの使用] を選択し、タイムアウト値を選択します。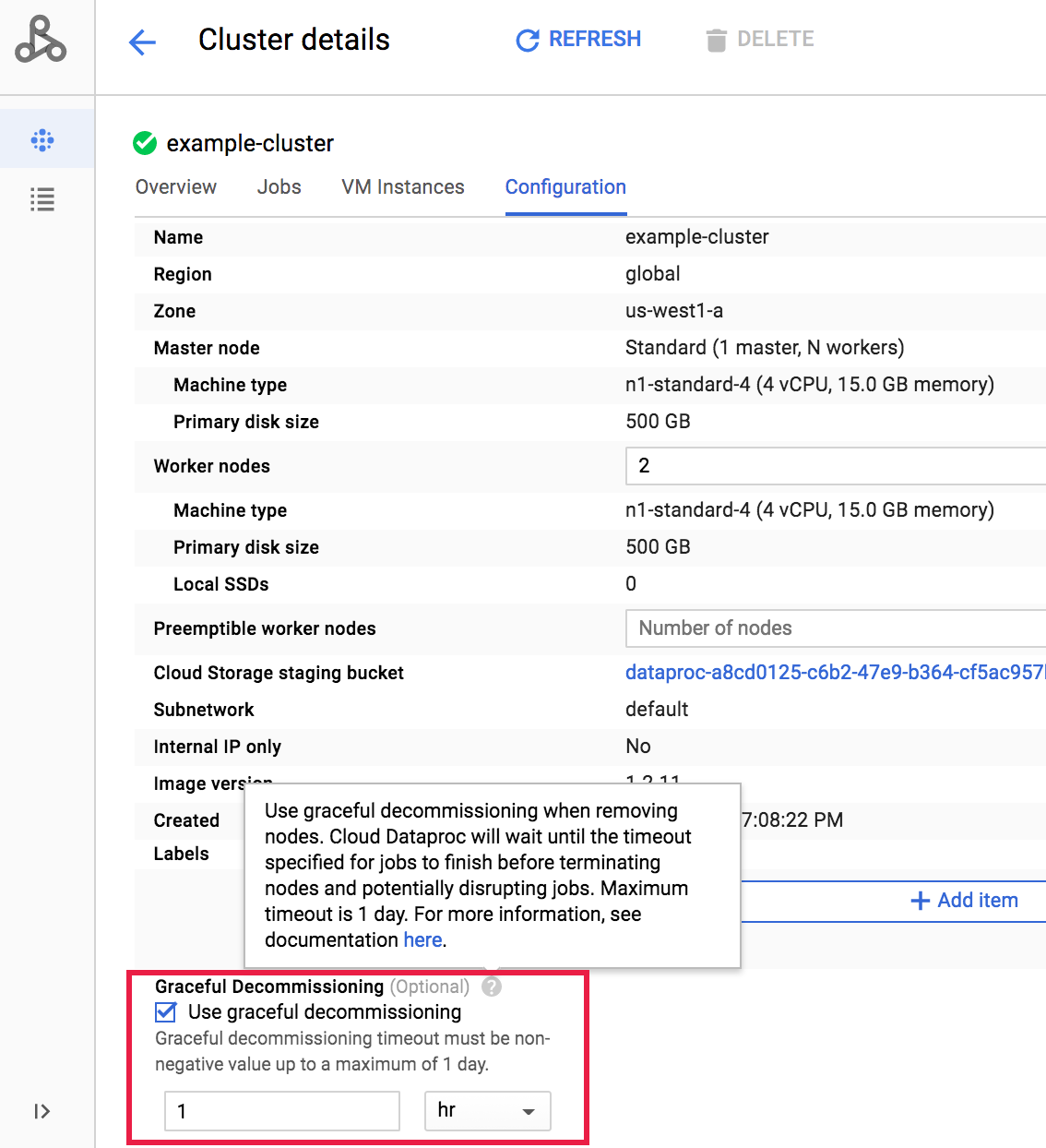 [保存] をクリックしてクラスタを更新します
[保存] をクリックしてクラスタを更新します正常なデコミッションのスケールダウン オペレーションをキャンセルする
イメージ バージョン 2.0.57 以降または 2.1.5 以降で作成された Dataproc クラスタの場合、gcloud dataproc operations cancel コマンドを実行するか、Dataproc API operations.cancel リクエストを発行して、正常なデコミッションのスケールダウン オペレーションをキャンセルすることができます。
正常なデコミッションのスケールダウン オペレーションをキャンセルすると、次のようになります。
DECOMMISSIONING状態のワーカーが再コミッションされ、オペレーションのキャンセルが完了するとACTIVEになります。スケールダウン オペレーションにラベルの更新が含まれている場合、更新が反映されないことがあります。
キャンセル リクエストのステータスを確認するには、gcloud dataproc operations describe コマンドを実行するか、Dataproc API operations.get リクエストを発行します。キャンセル オペレーションが成功すると、内部オペレーションのステータスは「CANCELLED」になります。