Le plug-in Dataproc Ranger Cloud Storage, disponible avec les versions d'image Dataproc 1.5 et 2.0, active un service d'autorisation sur chaque VM de cluster Dataproc. Le service d'autorisation évalue les requêtes du connecteur Cloud Storage par rapport aux règles Ranger et, si la requête est autorisée, renvoie un jeton d'accès pour le compte de service de VM du cluster.
Le plug-in Ranger Cloud Storage s'appuie sur Kerberos pour l'authentification et s'intègre à la compatibilité du connecteur Cloud Storage pour les jetons de délégation. Les jetons de délégation sont stockés dans une base de données MySQL sur le nœud maître du cluster. Le mot de passe racine de la base de données est spécifié dans les propriétés du cluster lorsque vous créez le cluster Dataproc.
Avant de commencer
Attribuez les rôles Créateur de jetons du compte de service et Administrateur de rôle IAM au compte de service de la VM Dataproc dans votre projet.
Installer le plug-in Ranger Cloud Storage
Exécutez les commandes suivantes dans une fenêtre de terminal local ou dans Cloud Shell pour installer le plug-in Ranger Cloud Storage lorsque vous créez un cluster Dataproc.
Définir des variables d'environnement
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
Remarques :
- CLUSTER_NAME : nom du nouveau cluster.
- REGION : région dans laquelle le cluster sera créé (par exemple,
us-west1). - KERBEROS_KMS_KEY_URI et KERBEROS_PASSWORD_URI : consultez Configurer le mot de passe principal racine Kerberos.
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI et RANGER_ADMIN_PASSWORD_GCS_URI : consultez Configurer votre mot de passe administrateur Ranger.
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI et RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI : configurez un mot de passe MySQL en suivant la même procédure que celle utilisée pour configurer un mot de passe administrateur Ranger.
Créer un cluster Dataproc
Exécutez la commande suivante pour créer un cluster Dataproc et installer le plug-in Ranger Cloud Storage sur le cluster.
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
Remarques :
- Version d'image 1.5 : si vous créez un cluster de version d'image 1.5 (voir Sélectionner des versions), ajoutez l'indicateur
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higherpour installer la version requise du connecteur.
Vérifier l'installation du plug-in Ranger Cloud Storage
Une fois la création du cluster terminée, un type de service GCS nommé gcs-dataproc s'affiche dans l'interface Web d'administration Ranger.
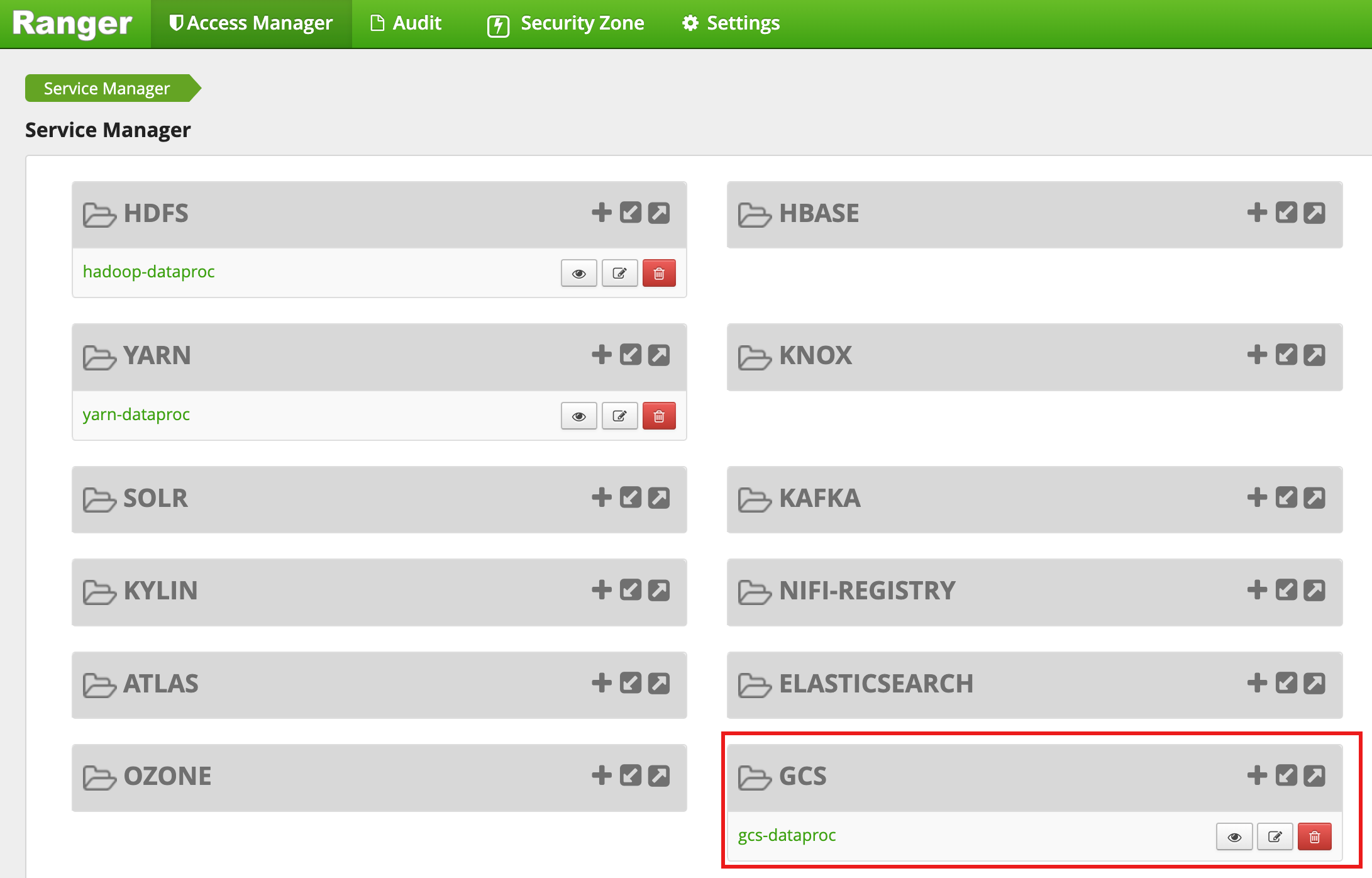
Règles par défaut du plug-in Ranger Cloud Storage
Le service gcs-dataproc par défaut comporte les règles suivantes :
Règles de lecture et d'écriture dans les buckets de préproduction et temporaires du cluster Dataproc
Une règle
all - bucket, object-path, qui permet à tous les utilisateurs d'accéder aux métadonnées de tous les objets. Cet accès est nécessaire pour permettre au connecteur Cloud Storage d'effectuer des opérations HCFS (Hadoop Compatible Filesystem).
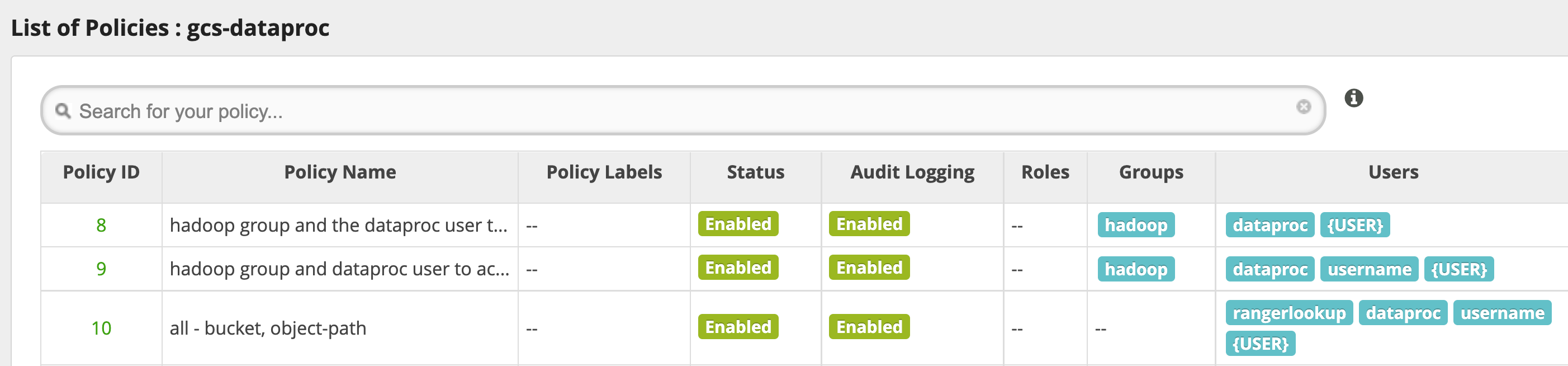
Conseils d'utilisation
Accès des applications aux dossiers de bucket
Pour les applications qui créent des fichiers intermédiaires dans un bucket Cloud Storage, vous pouvez accorder les autorisations Modify Objects, List Objects et Delete Objects sur le chemin d'accès au bucket Cloud Storage, puis sélectionner le mode recursive pour étendre les autorisations aux sous-chemins d'accès au chemin d'accès spécifié.
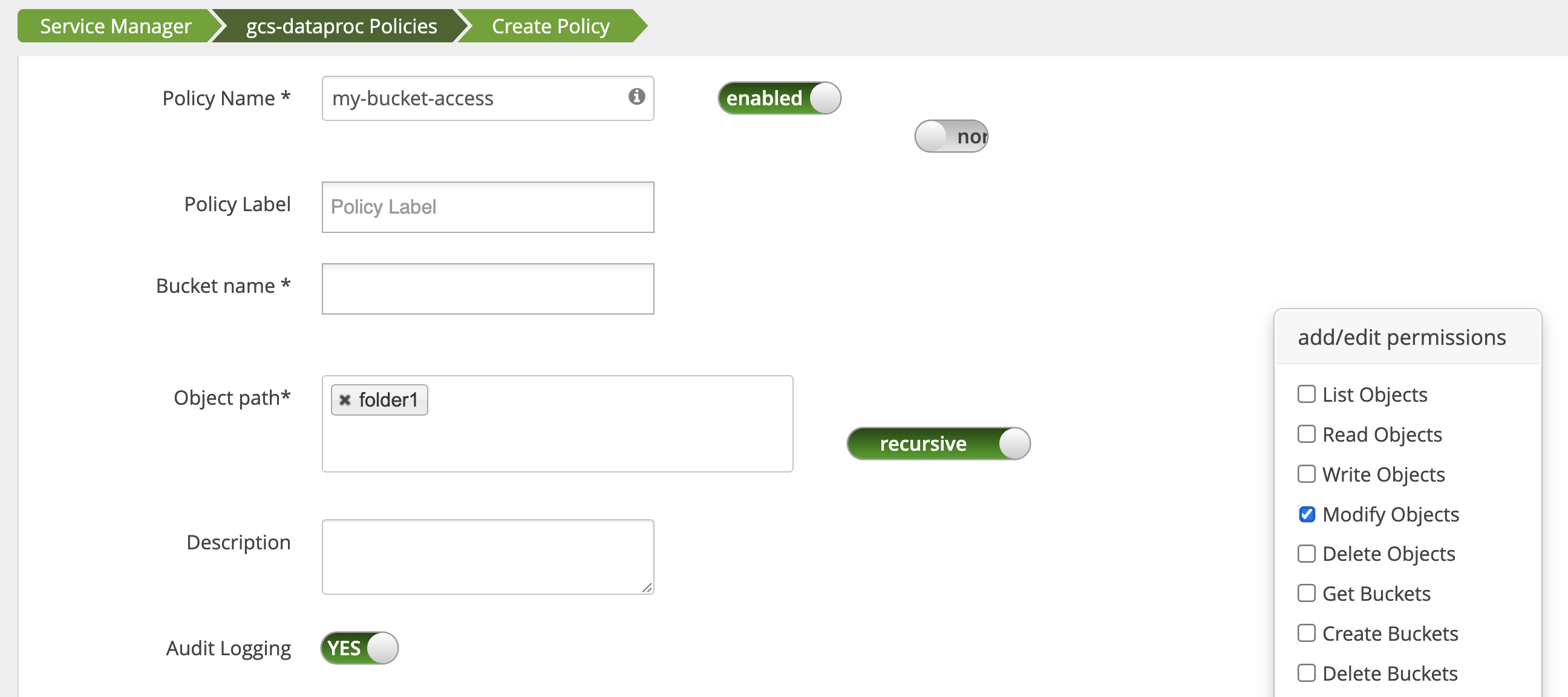
Mesures de protection
Pour éviter le contournement du plug-in :
Accordez au compte de service de la VM l'accès aux ressources de vos buckets Cloud Storage pour lui permettre d'accorder l'accès à ces ressources avec des jetons d'accès à champ restreint (voir Autorisations IAM pour Cloud Storage). De plus, supprimez l'accès des utilisateurs aux ressources de bucket pour éviter qu'ils n'y accèdent directement.
Désactivez
sudoet les autres moyens d'accès root sur les VM du cluster, y compris la mise à jour du fichiersudoer, pour empêcher l'usurpation d'identité ou les modifications apportées aux paramètres d'authentification et d'autorisation. Pour en savoir plus, consultez les instructions Linux permettant d'ajouter ou de supprimer les droits d'accès de l'utilisateursudo.Utilisez
iptablepour bloquer les demandes d'accès direct à Cloud Storage à partir des VM du cluster. Par exemple, vous pouvez bloquer l'accès au serveur de métadonnées de la VM pour empêcher l'accès aux identifiants ou au jeton d'accès du compte de service de la VM utilisés pour authentifier et autoriser l'accès à Cloud Storage (voirblock_vm_metadata_server.sh, un script d'initialisation qui utilise des règlesiptablepour bloquer l'accès au serveur de métadonnées de la VM).
Tâches Spark, Hive-on-MapReduce et Hive-on-Tez
Pour protéger les informations sensibles d'authentification des utilisateurs et réduire la charge sur le centre de distribution de clés (KDC), le pilote Spark ne distribue pas les identifiants Kerberos aux exécuteurs. Au lieu de cela, le pilote Spark obtient un jeton de délégation à partir du plug-in Ranger Cloud Storage, puis le distribue aux exécuteurs. Les exécutants utilisent le jeton de délégation pour s'authentifier auprès du plug-in Ranger Cloud Storage, en l'échangeant contre un jeton d'accès Google qui permet d'accéder à Cloud Storage.
Les jobs Hive-on-MapReduce et Hive-on-Tez utilisent également des jetons pour accéder à Cloud Storage. Utilisez les propriétés suivantes pour obtenir des jetons permettant d'accéder à des buckets Cloud Storage spécifiques lorsque vous envoyez les types de jobs suivants :
Tâches Spark :
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
Tâches Hive-on-MapReduce :
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
Tâches Hive-on-Tez :
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
Scénario de job Spark
Une tâche Spark de décompte de mots échoue lorsqu'elle est exécutée à partir d'une fenêtre de terminal sur une VM de cluster Dataproc sur laquelle le plug-in Ranger Cloud Storage est installé.
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
Remarques :
- FILE_BUCKET : bucket Cloud Storage pour l'accès à Spark.
Erreur :
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
Remarques :
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}est requis dans un environnement compatible avec Kerberos.
Erreur :
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
Une règle est modifiée à l'aide du gestionnaire d'accès dans l'interface Web d'administration Ranger pour ajouter username à la liste des utilisateurs disposant des autorisations List Objects et d'autres autorisations de bucket temp.
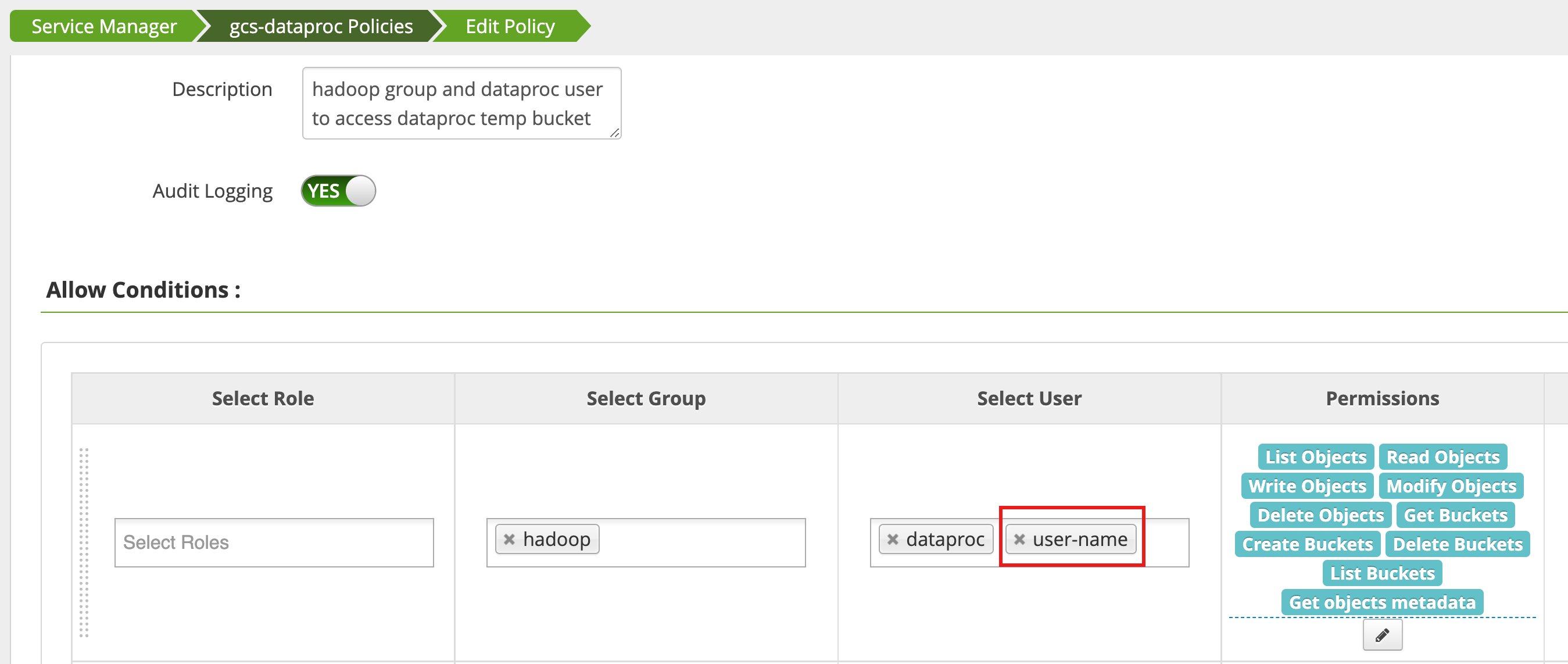
L'exécution du job génère une nouvelle erreur.
Erreur :
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
Une règle est ajoutée pour accorder à l'utilisateur un accès en lecture au chemin d'accès Cloud Storage wordcount.text.
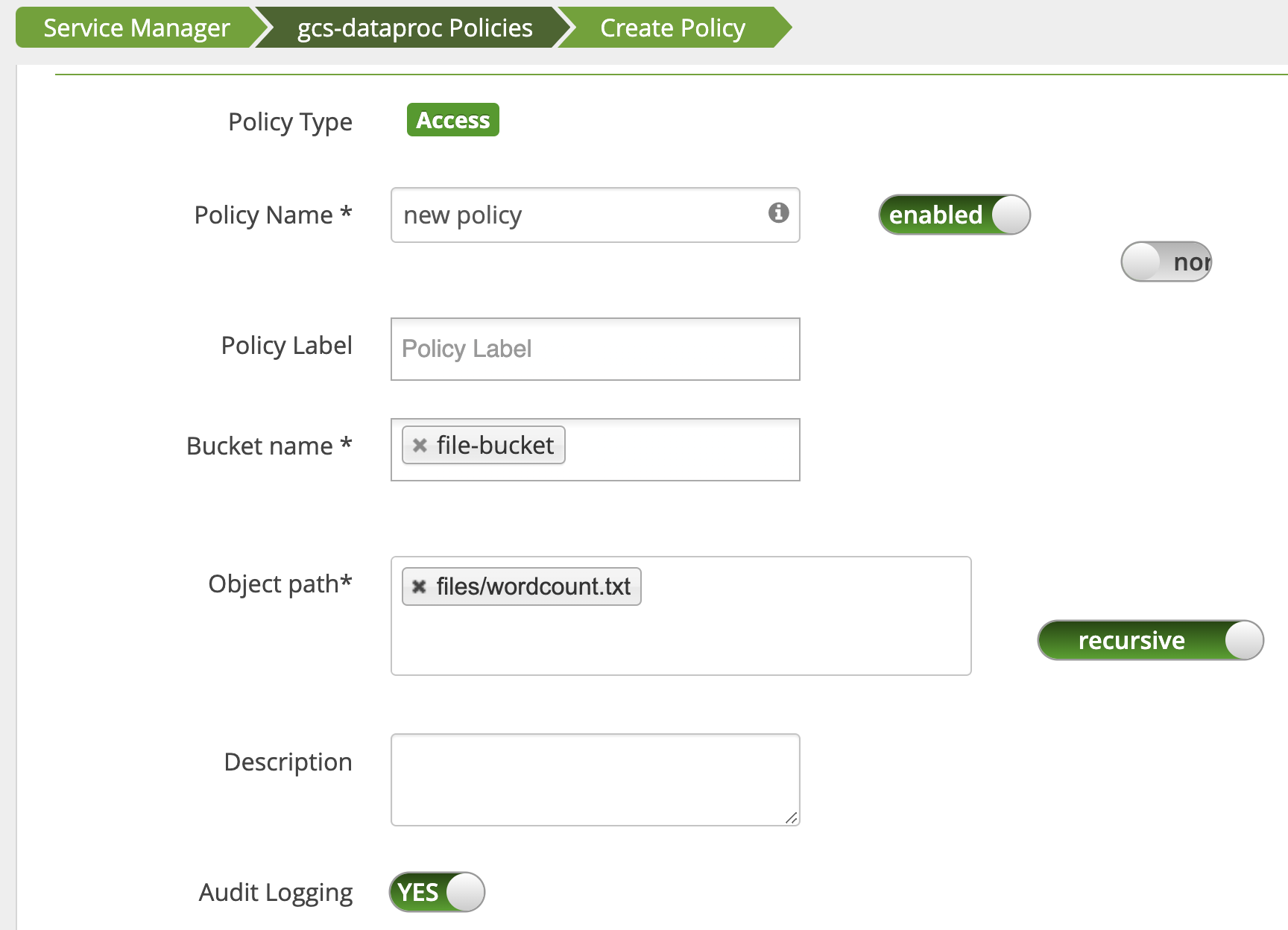
Le job s'exécute et se termine correctement.
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped