Les exemples suivants créent et utilisent un cluster Dataproc compatible Kerberos avec des composants Ranger et Solr pour contrôler l'accès des utilisateurs aux ressources Hadoop, YARN et HIVE.
Remarques :
L'interface utilisateur Web de Ranger est accessible via la passerelle des composants.
Dans un cluster Ranger avec Kerberos, Dataproc mappe un utilisateur Kerberos à l'utilisateur système en supprimant le domaine et l'instance de l'utilisateur Kerberos. Par exemple, le principal
user1/cluster-m@MY.REALMKerberos est mappé sur le systèmeuser1, et les règles Ranger sont définies pour autoriser ou refuser les autorisations pouruser1.
Créez le cluster.
- La commande
gcloudsuivante peut être exécutée en local dans une fenêtre de terminal ou à partir du Cloud Shell d'un projet.gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=SOLR,RANGER \ --enable-component-gateway \ --properties="dataproc:ranger.kms.key.uri=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key,dataproc:ranger.admin.password.uri=gs://bucket/admin-password.encrypted" \ --kerberos-root-principal-password-uri=gs://bucket/kerberos-root-principal-password.encrypted \ --kerberos-kms-key=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key
- La commande
Une fois le cluster en cours d'exécution, accédez à la page Clusters Dataproc de la console Google Cloud , puis sélectionnez le nom du cluster pour ouvrir la page Détails du cluster. Cliquez sur l'onglet Web Interfaces (Interfaces Web) pour afficher la liste des liens de la passerelle des composants vers les interfaces Web des composants par défaut et facultatifs installés sur le cluster. Cliquez sur le lien Ranger.
Connectez-vous à Ranger en saisissant le nom d'utilisateur "admin" et le mot de passe administrateur Ranger.
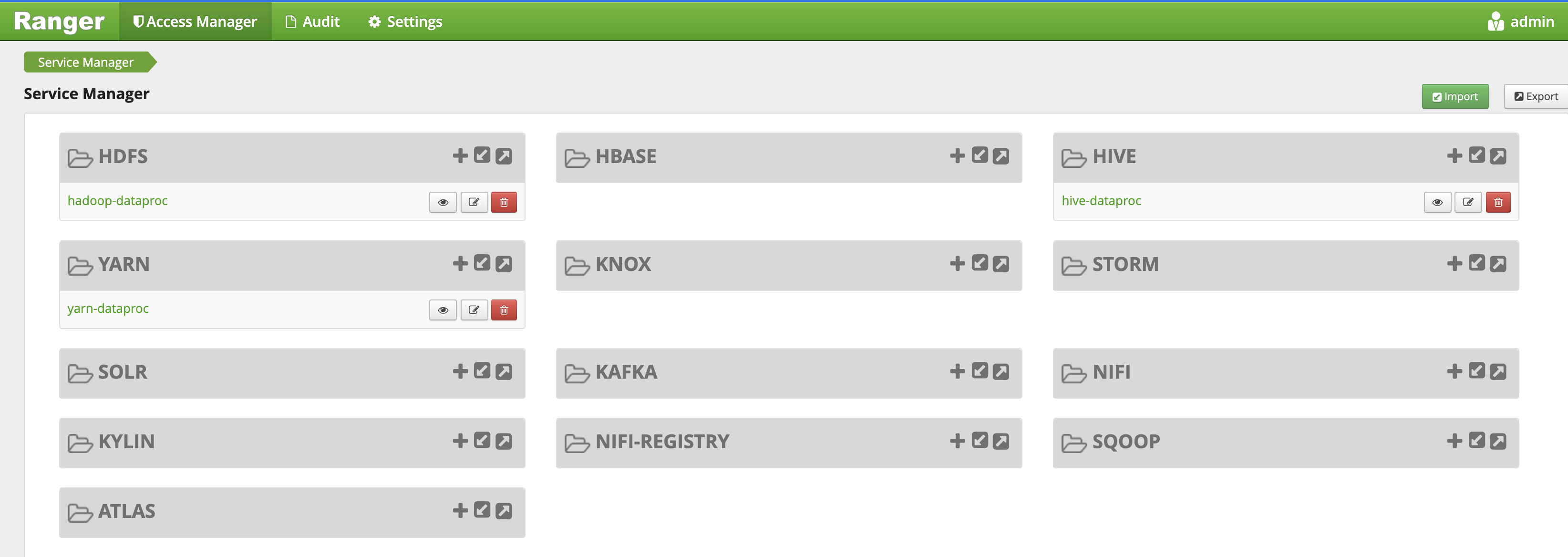
L'interface administration Ranger s'ouvre dans un navigateur local.
Règles d'accès YARN
Cet exemple crée une règle Ranger pour autoriser et refuser l'accès des utilisateurs à la file d'attente root.default de YARN.
Sélectionnez
yarn-dataprocdans l'interface administration Ranger.
Sur la page yarn-dataproc Policies (Règles yarn-dataproc), cliquez sur Add New Policy(Ajouter une nouvelle règle). Sur la page Create Policy (Créer une règle), les champs suivants sont saisis ou sélectionnés :
Policy Name: "yarn-policy-1"Queue: "root.default"Audit Logging: "Yes"Allow Conditions:Select User: "userone"Permissions: "Select All" pour accorder toutes les autorisations
Deny ConditionsSelect User: "usertwo"Permissions: "Select All" pour refuser toutes les autorisations
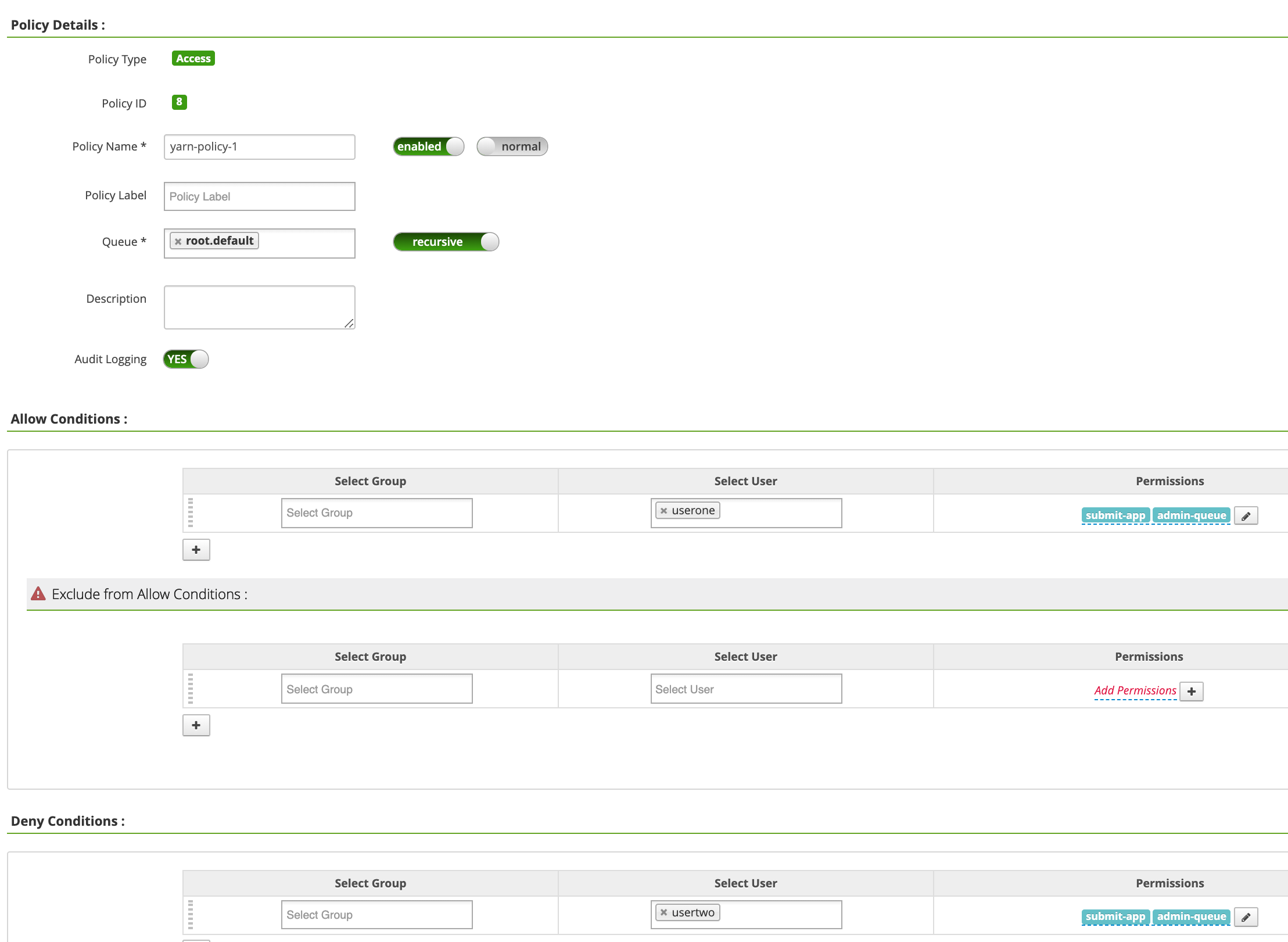
Cliquez sur Add (Ajouter) pour enregistrer la règle. La règle est répertoriée sur la page yarn-dataproc Policies :
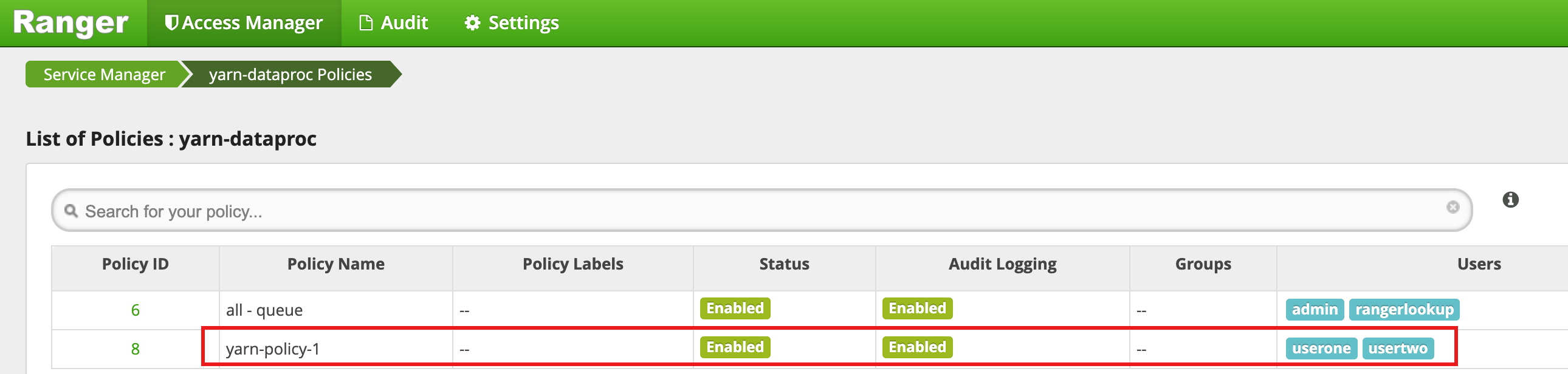
Exécutez une tâche Hadoop mapreduce dans la fenêtre de session SSH maître en tant que userone :
userone@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- L'interface utilisateur Ranger indique que
useronea été autorisé à envoyer la tâche.
- L'interface utilisateur Ranger indique que
Exécutez la tâche Hadoop mapreduce depuis la fenêtre de session SSH maître en tant que
usertwo:usertwo@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- L'interface utilisateur de Ranger indique que
usertwos'est vu refuser l'accès pour envoyer la tâche.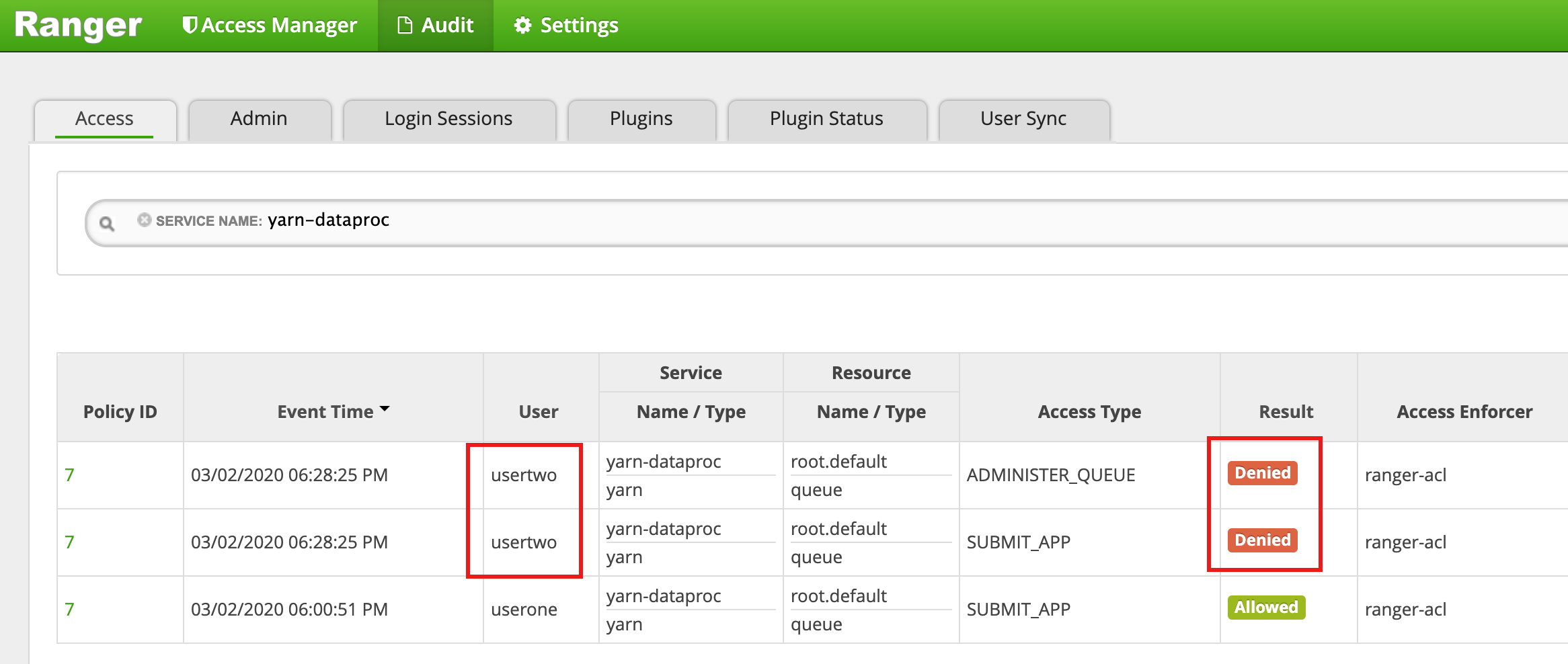
- L'interface utilisateur de Ranger indique que
Règles d'accès HDFS
Cet exemple crée une règle Ranger pour autoriser et refuser l'accès utilisateur au répertoire /tmp HDFS.
Sélectionnez
hadoop-dataprocdans l'interface administration Ranger.
Sur la page hadoop-dataproc Policies (Règles hadoop-dataproc), cliquez sur Add New Policy(Ajouter une nouvelle règle). Sur la page Create Policy (Créer une règle), les champs suivants sont saisis ou sélectionnés :
Policy Name: "hadoop-policy-1"Resource Path: "/tmp"Audit Logging: "Yes"Allow Conditions:Select User: "userone"Permissions: "Select All" pour accorder toutes les autorisations
Deny ConditionsSelect User: "usertwo"Permissions: "Select All" pour refuser toutes les autorisations
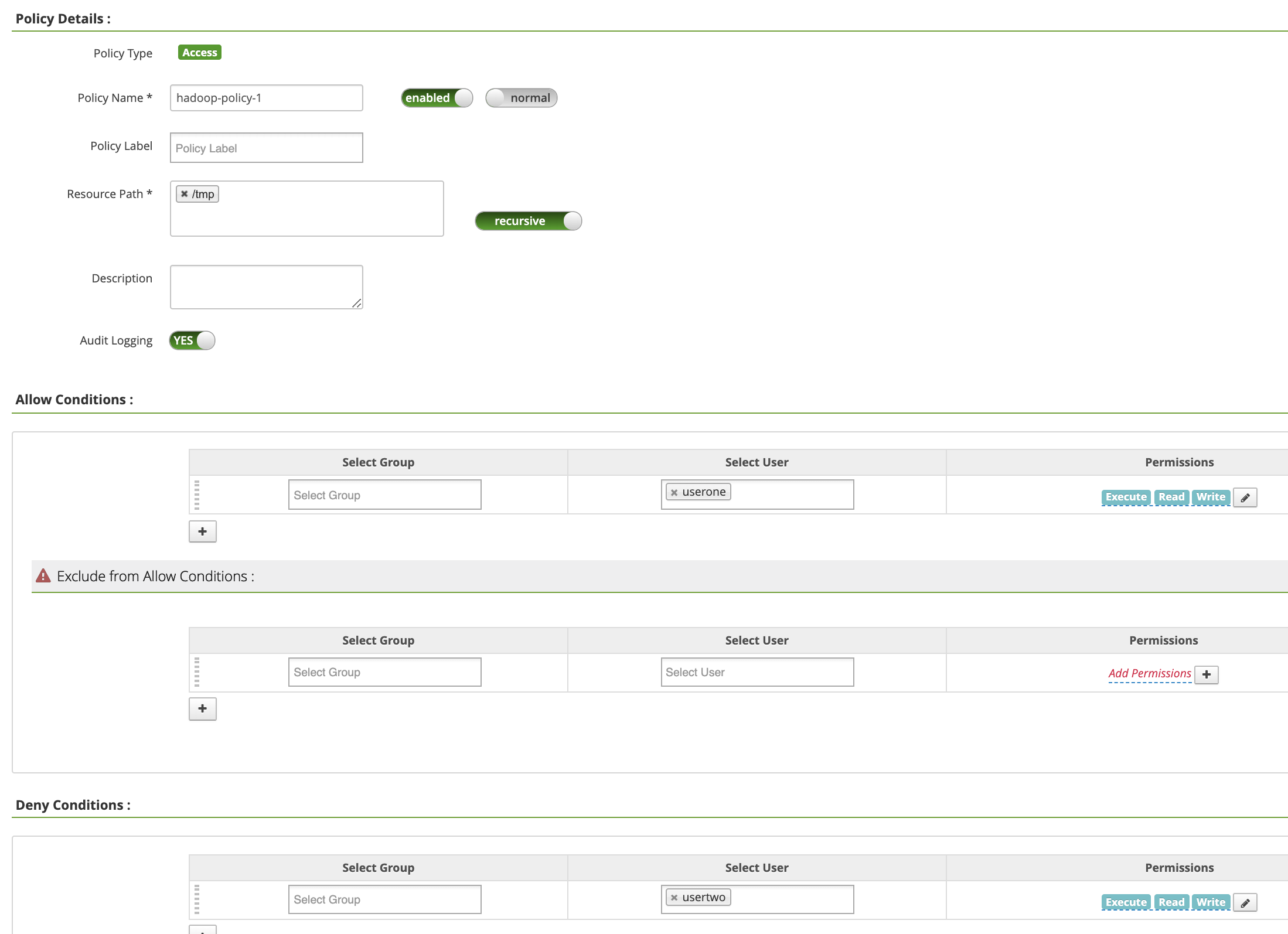
Cliquez sur Add (Ajouter) pour enregistrer la règle. La règle est répertoriée sur la page hadoop-dataproc Policies :
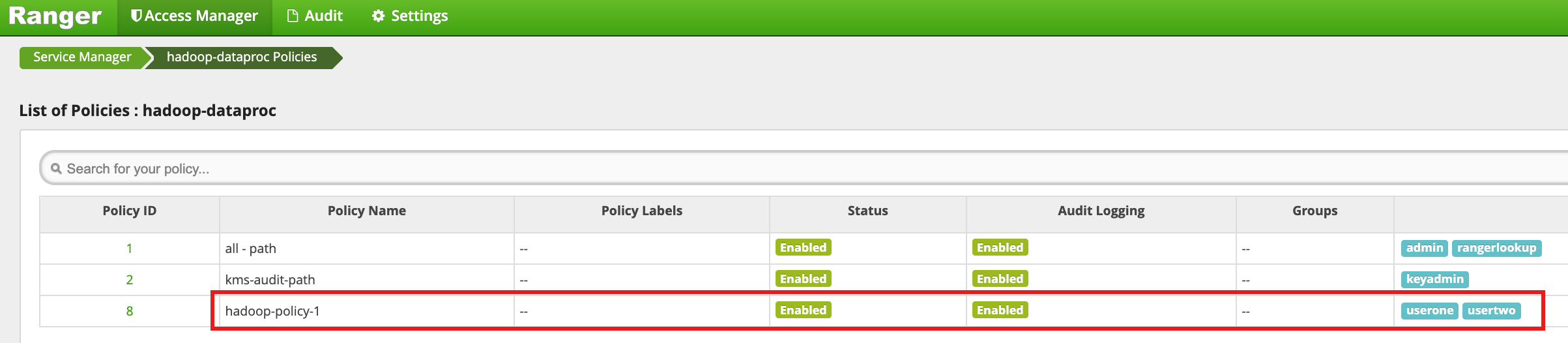
Accédez au répertoire
/tmpHDFS en tant que userone :userone@example-cluster-m:~$ hadoop fs -ls /tmp
- L'interface utilisateur Ranger indique que
useroneétait autorisé à accéder au répertoire HDFS /tmp.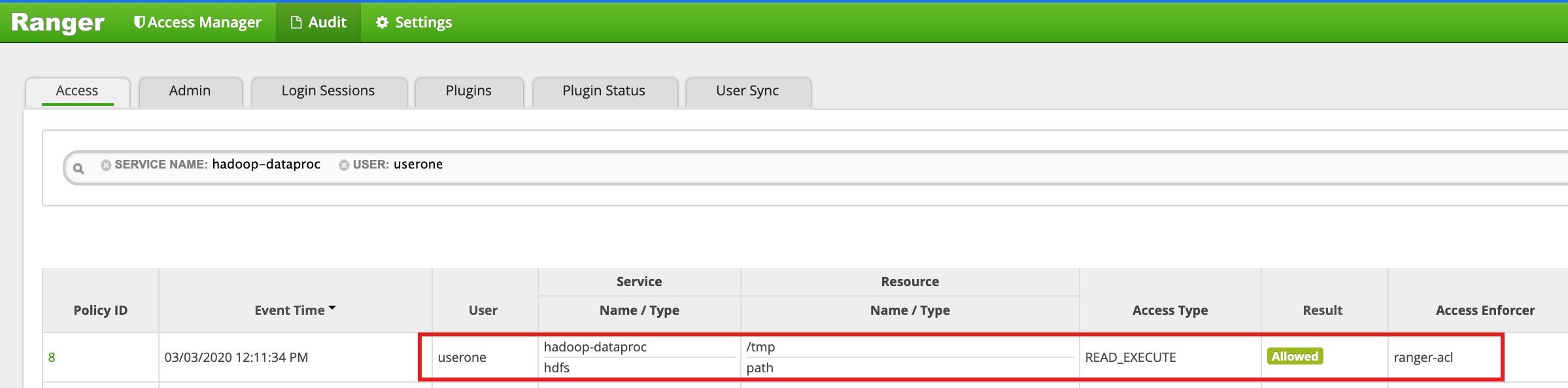
- L'interface utilisateur Ranger indique que
Accédez au répertoire
/tmpHDFS en tant queusertwo:usertwo@example-cluster-m:~$ hadoop fs -ls /tmp
- L'interface utilisateur Ranger indique que
usertwos'est vu refuser l'accès au répertoire HDFS /tmp.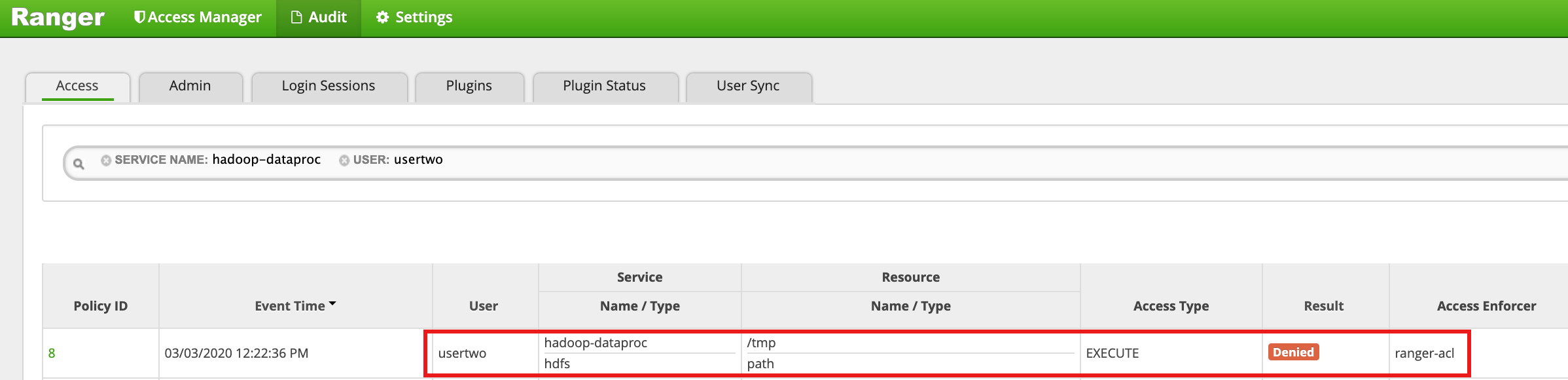
- L'interface utilisateur Ranger indique que
Règles d'accès Hive
Cet exemple crée une règle Ranger pour autoriser et refuser l'accès d'un utilisateur à un tableau Hive.
Créez un petit tableau
employeeà l'aide de la CLI Hive sur l'instance maître.hive> CREATE TABLE IF NOT EXISTS employee (eid int, name String); INSERT INTO employee VALUES (1 , 'bob') , (2 , 'alice'), (3 , 'john');
Sélectionnez
hive-dataprocdans l'interface administration Ranger.
Sur la page hive-dataproc Policies (Règles hive-dataproc), cliquez sur Add New Policy(Ajouter une nouvelle règle). Sur la page Create Policy (Créer une règle), les champs suivants sont saisis ou sélectionnés :
Policy Name: "hive-policy-1"database: "default"table: "employee"Hive Column: "*"Audit Logging: "Yes"Allow Conditions:Select User: "userone"Permissions: "Select All" pour accorder toutes les autorisations
Deny ConditionsSelect User: "usertwo"Permissions: "Select All" pour refuser toutes les autorisations
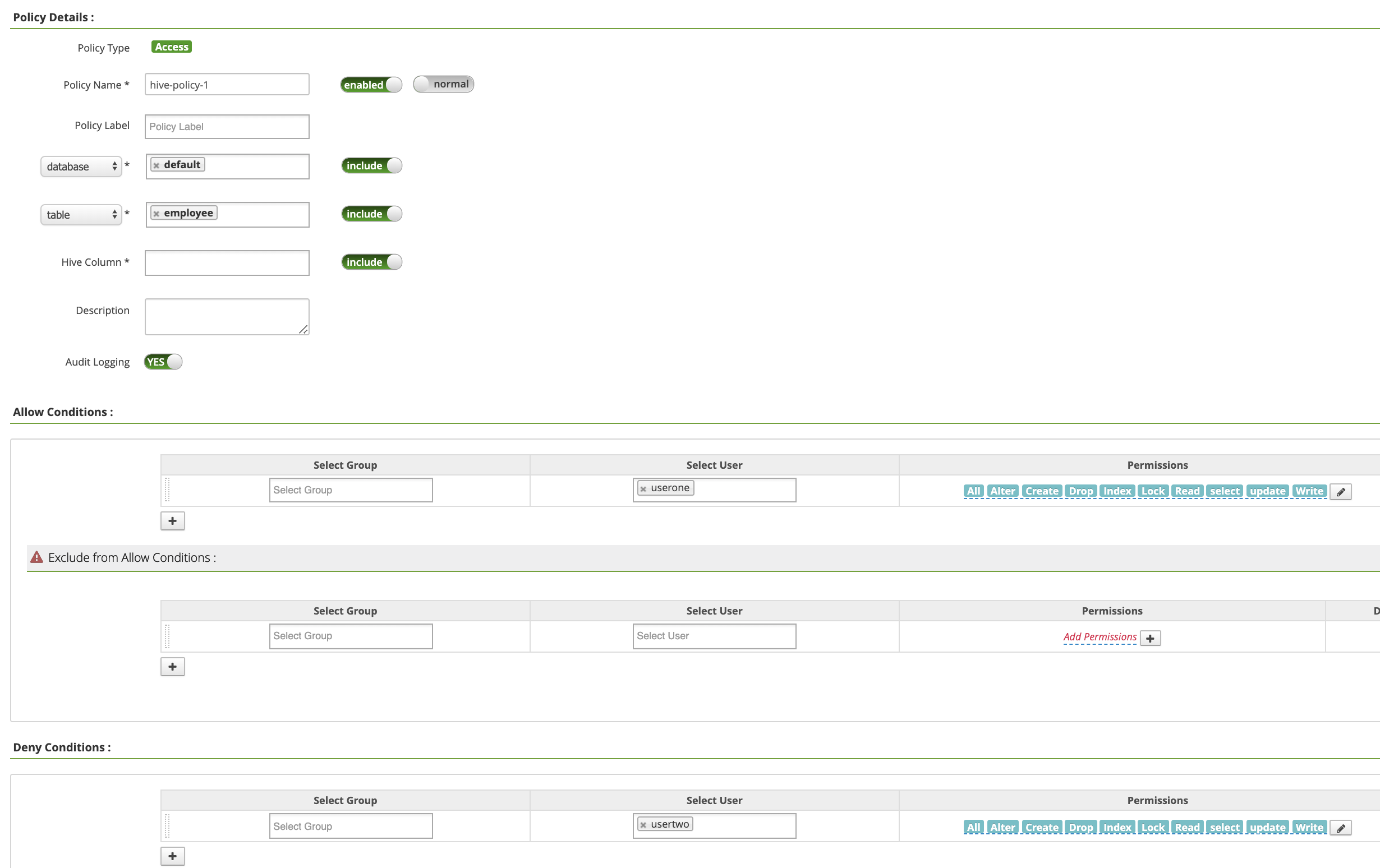
Cliquez sur Add (Ajouter) pour enregistrer la règle. La règle est répertoriée sur la page hive-dataproc Policies :
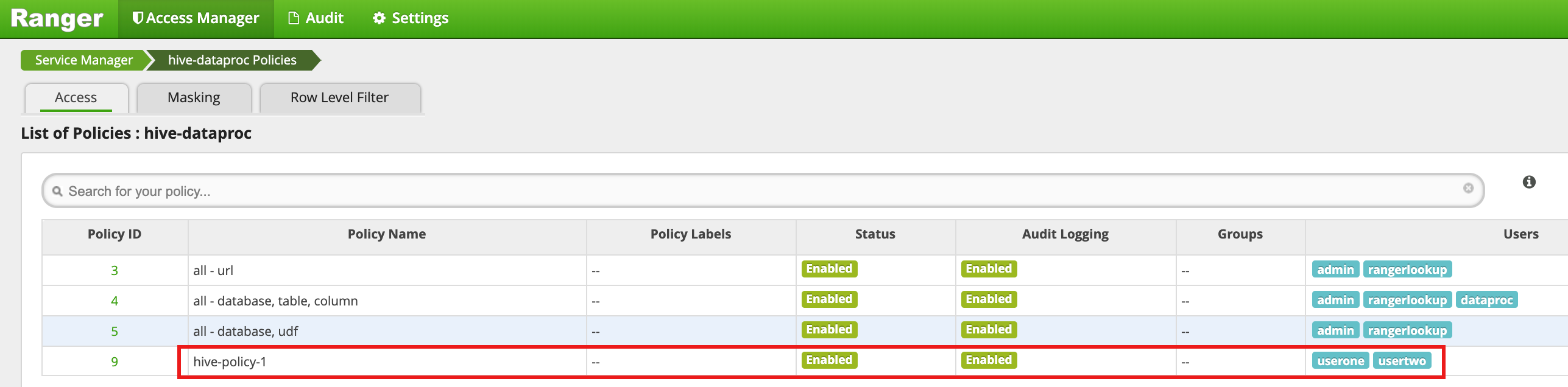
Exécutez une requête à partir de la session SSH maître de la VM sur le tableau des employés Hive en tant que userone :
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- La requête de userone aboutit :
Connected to: Apache Hive (version 2.3.6) Driver: Hive JDBC (version 2.3.6) Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 1 | bob | | 2 | alice | | 3 | john | +---------------+----------------+ 3 rows selected (2.033 seconds)
- La requête de userone aboutit :
Exécutez une requête à partir de la session SSH maître de la VM sur le tableau des employés Hive en tant que usertwo :
usertwo@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- usertwo se voit refuser l'accès au tableau :
Error: Could not open client transport with JDBC Uri: ... Permission denied: user=usertwo, access=EXECUTE, inode="/tmp/hive"
- usertwo se voit refuser l'accès au tableau :
Accès ultra-précis à Hive
Ranger est compatible avec les filtres de masquage et de niveau de ligne sur Hive. Cet exemple s'appuie sur le précédent hive-policy-1 en ajoutant des règles de masquage et de filtrage.
Sélectionnez
hive-dataprocdans l'interface administrateur Ranger, puis cliquez sur l'onglet Masking (Masquage), puis sur Add New Policy (Ajouter une nouvelle règle).
Sur la page Create Policy (Créer une règle), les champs suivants sont saisis ou sélectionnés pour créer une règle permettant de masquer (annuler) la colonne de nom des employés :
Policy Name: "hive-masking policy"database: "default"table: "employee"Hive Column: "name"Audit Logging: "Yes"Mask Conditions:Select User: "userone"Access Types: "select" ajouter/modifier des autorisationsSelect Masking Option: "nullify"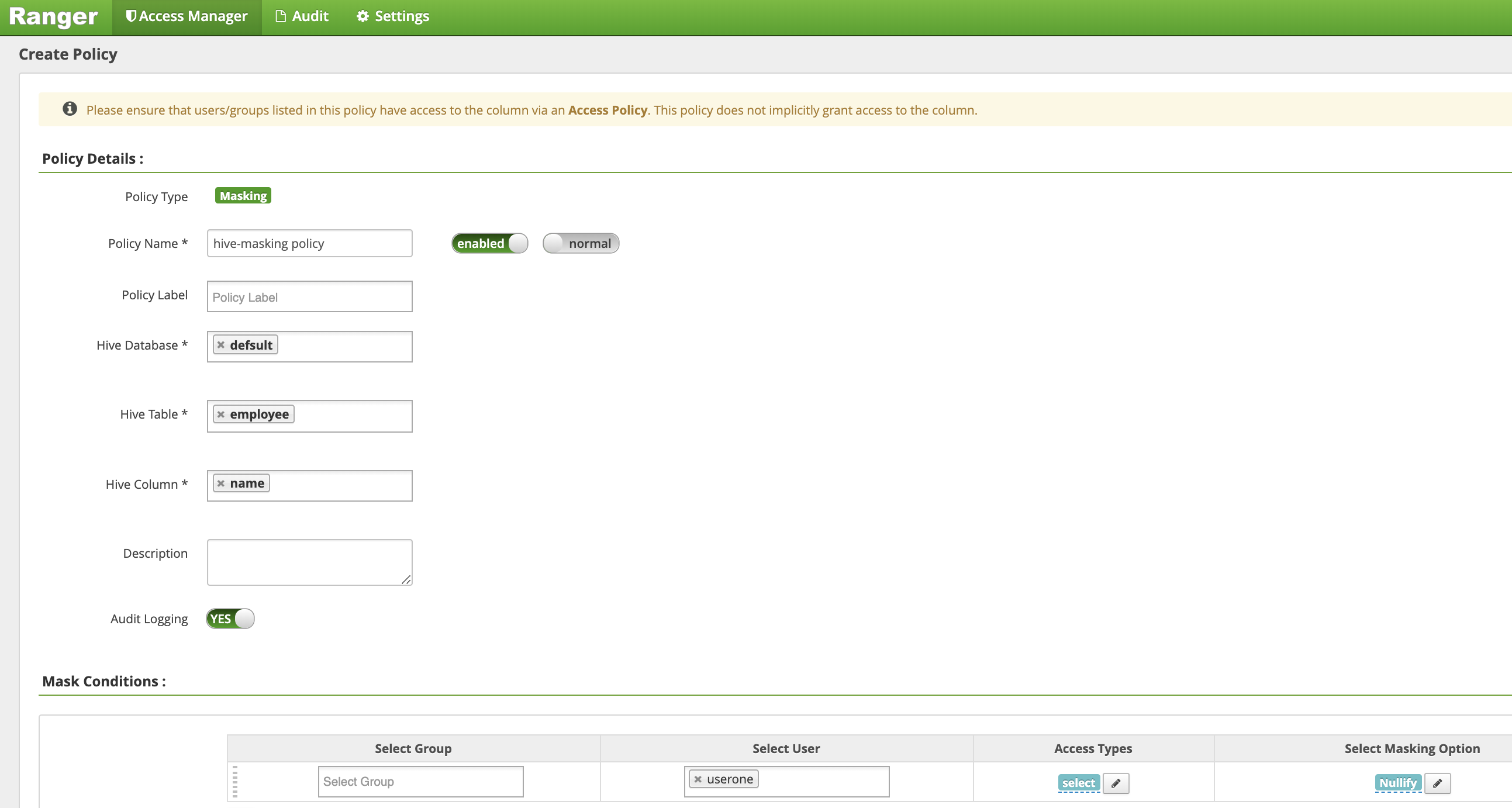
Cliquez sur Add (Ajouter) pour enregistrer la règle.
Sélectionnez
hive-dataprocdans l'interface administrateur Ranger, puis cliquez sur l'onglet Row Level Filter (Filtre au niveau des lignes), puis sur Add New Policy (Ajouter une nouvelle règle).
Sur la page Create Policy (Créer une règle), les champs suivants sont saisis ou sélectionnés pour créer une règle permettant de filtrer (afficher) les lignes où
eidn'est pas égal à1:Policy Name: "hive-filter policy"Hive Database: "default"Hive Table: "employee"Audit Logging: "Yes"Mask Conditions:Select User: "userone"Access Types: "select" ajouter/modifier des autorisationsRow Level Filter: "eid != 1" expression de filtre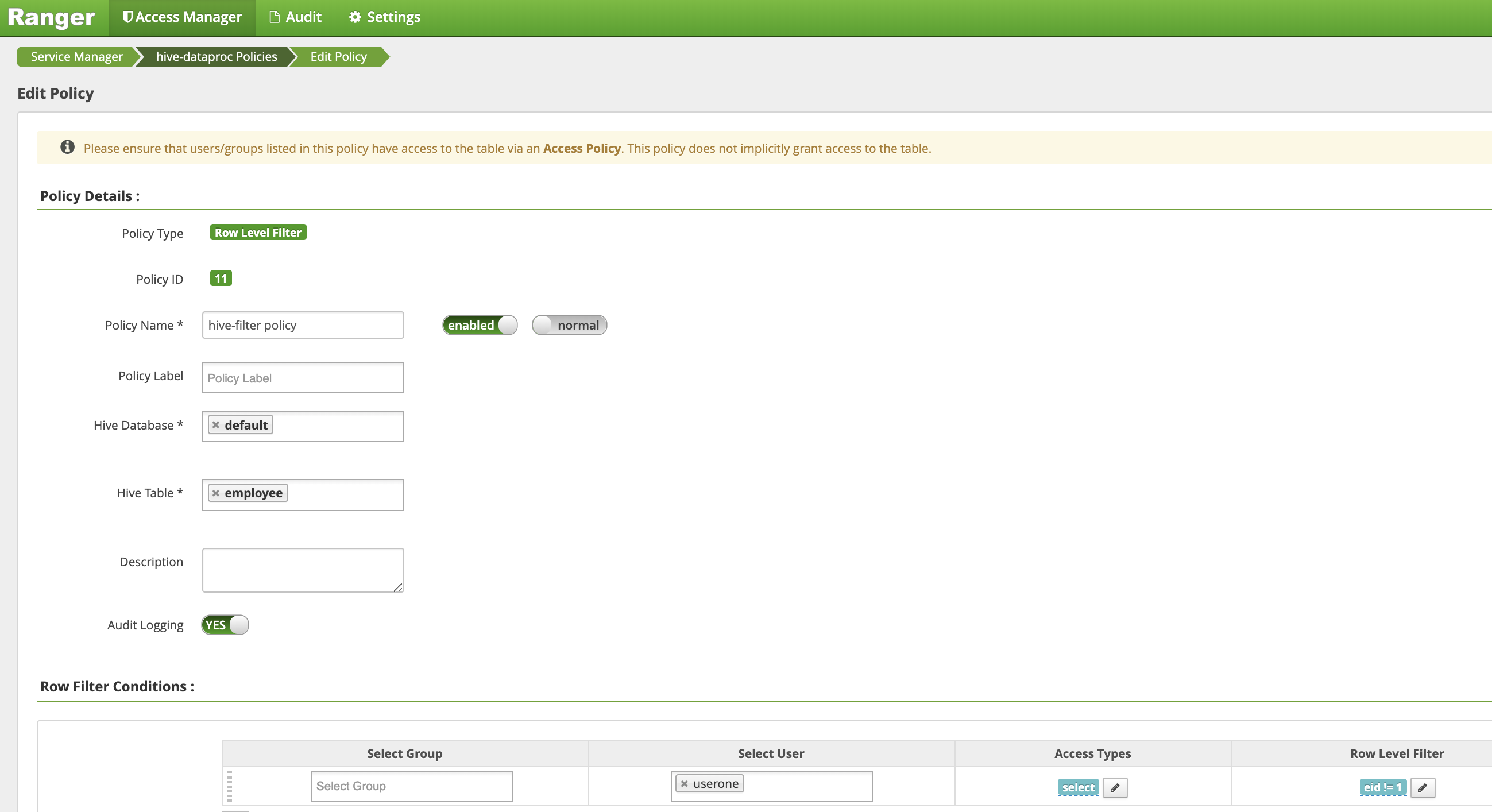
Cliquez sur Add (Ajouter) pour enregistrer la règle.
Répétez la requête précédente depuis la session SSH maître de la VM avec le tableau des employés Hive en tant que userone :
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- La requête renvoie avec la colonne de nom masquée et le filtre (eid=1) dans les résultats :
Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 2 | NULL | | 3 | NULL | +---------------+----------------+ 2 rows selected (0.47 seconds)
- La requête renvoie avec la colonne de nom masquée et le filtre (eid=1) dans les résultats :