선택적 HBase 구성요소 설치는 이미지 버전 1.5 또는 2.0으로 생성된 Dataproc 클러스터로 제한됩니다.
Google Cloud 는 자체 관리형 Apache HBase를 배포할 수 있는 다양한 서비스를 제공하지만 Bigtable은 HBase 및 워크로드 이식성을 갖춘 개방형 API를 제공하므로 최적의 옵션이 되는 경우가 많습니다. HBase 데이터베이스 테이블은 기본 데이터 관리를 위해 Bigtable로 마이그레이션될 수 있지만 Spark와 같이 이전에 HBase와 상호 작용한 애플리케이션은 Dataproc에 있어 Bigtable과 안전하게 연결될 수 있습니다. 이 가이드에서는 Bigtable를 시작하는 개략적인 단계와 데이터를 Dataproc HBase 배포에서 Bigtable로 마이그레이션하는 데 사용할 수 있는 참조를 제공합니다.
Bigtable 시작하기
Cloud Bigtable은 HBase 워크로드에 Apache HBase API 클라이언트 호환성과 이동성을 제공하는 확장성과 성능이 우수한 NoSQL 플랫폼입니다. 이 클라이언트는 HBase API 버전 1.x 및 2.x와 호환되며 Bigtable에서 읽기 및 쓰기를 위해 기존 애플리케이션에 포함될 수 있습니다. 기존 HBase 애플리케이션은 Bigtable HBase 클라이언트 라이브러리를 추가하여 Bigtable에 저장된 데이터를 읽고 쓸 수 있습니다.
Bigtable에서 HBase 애플리케이션을 구성하는 방법에 대한 자세한 내용은 Bigtable 및 HBase API를 참조하세요.
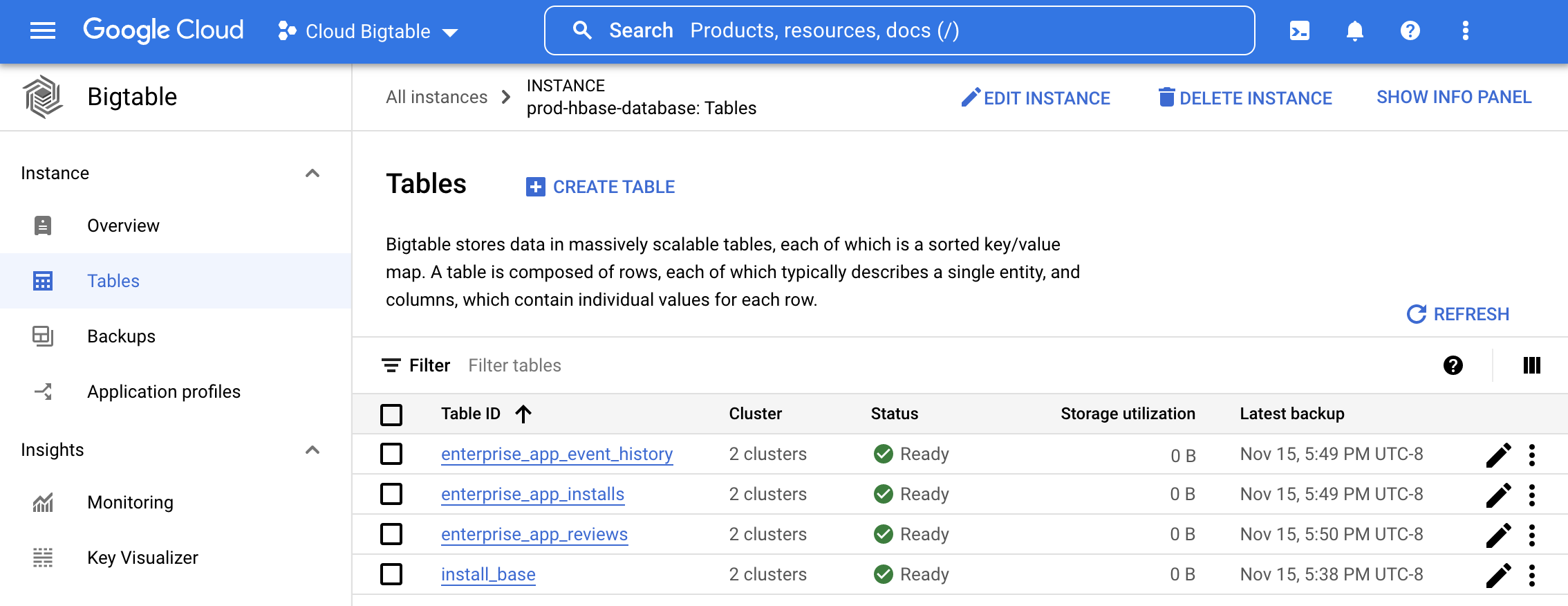
Bigtable 클러스터 만들기
이전에 HBase에 저장된 데이터를 저장할 클러스터와 테이블을 만들어 Bigtable을 사용할 수 있습니다. HBase 테이블과 동일한 스키마를 사용하여 인스턴스, 클러스터 및 테이블을 만들려면 Bigtable 문서의 단계를 따르세요. HBase 테이블 DDL에서 자동으로 테이블을 만드는 방법은 스키마 변환기 도구를 참조하세요.
Google Cloud 콘솔에서 Bigtable 인스턴스를 열어 초당 행, 지연 시간, 처리량 등 테이블 및 서버 측 모니터링 차트를 보고 새로 프로비저닝된 테이블을 관리합니다. 자세한 내용은 Monitoring을 참조하세요.
Dataproc에서 Bigtable로 데이터 마이그레이션
Bigtable에서 테이블을 만든 후 Google Cloud 의 HBase를 Bigtable로 마이그레이션의 안내에 따라 데이터를 가져오고 데이터를 검증할 수 있습니다. 데이터를 마이그레이션한 후 Bigtable에 읽기 및 쓰기를 전송하도록 애플리케이션을 업데이트할 수 있습니다.
다음 단계
- Wordcount Spark 예시를 참조하여 Bigtable에서 Spark를 실행하는 방법 알아보기
- HBase에서 Bigtable로 라이브 복제를 사용하여 온라인 마이그레이션 옵션 검토
- Box가 NoSQL 데이터베이스를 현대화한 방법을 시청하여 다른 이점 이해