
Managed Service for Apache Spark (in precedenza Dataproc)
Il nuovo modo di usare Spark: più facile, più smart, più veloce
Esegui workload Apache Spark con Spark serverless zero-ops o cluster gestiti. Accelera lo sviluppo con flussi di lavoro di AI agentica e migliora le prestazioni con Lightning Engine.
I nuovi clienti ricevono 300 $ di crediti senza costi per provare Managed Service for Apache Spark e altri prodotti Google Cloud.
Apache Spark è un marchio di Apache Software Foundation.

Funzionalità
Prestazioni leader del settore con Lightning Engine
Accelera i workload ETL e SQL su larga scala fino a 4,9 volte più velocemente rispetto ad Apache Spark open source senza modifiche al codice. Lightning Engine utilizza un motore di esecuzione vettoriale C++ nativo, memorizzazione nella cache intelligente e shuffling colonnare ottimizzato. Combina questo con l'ottimizzazione automatica intelligente di Spark per eliminare l'onere dell'ottimizzazione manuale, migliorando la gestione della memoria e prevenendo automaticamente gli errori di esaurimento.
*Le query derivano dallo standard TPC-DS e dallo standard TPC-H
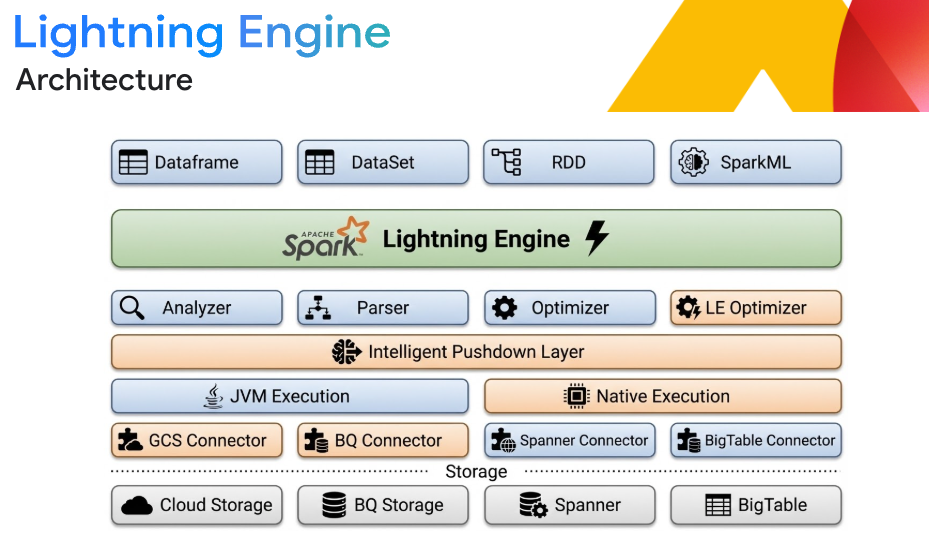
Interoperabilità flessibile della lakehouse
Crea un'architettura open lakehouse che garantisca l'indipendenza dal motore. Elabora i dati in formati aperti come Apache Iceberg direttamente da Google Cloud Storage. Integra senza problemi con BigQuery e Knowledge Catalog (in precedenza Dataplex) per analisi e governance unificate, garantendo una vera interoperabilità multi-motore senza livelli di traduzione.
Esperienza di sviluppo unificata basata sull'AI
Smaltisci il lavoro arretrato con agenti di dati che agiscono, non si limitano a rispondere alle domande. Accelera il tuo workflow utilizzando Gemini integrato nell'estensione agentica VSCode per una maggiore produttività dei workload Spark dallo sviluppo alla produzione oppure utilizza l'IDE che preferisci. Sfrutta Data Engineering Agent e Data Science Agent per automatizzare il data wrangling, creare pipeline dal linguaggio naturale e generare il codice PySpark. Risolvi automaticamente i problemi relativi ai job Spark interrotti con Gemini Cloud Assist. Combina SQL e Spark in un singolo notebook unificato AI-first.
Predisposizione per AI/ML di livello enterprise
Crea e metti in funzione l'intero ciclo di vita del machine learning. Accelera l'addestramento e l'inferenza dei modelli con il supporto GPU, basato su NVIDIA RAPIDS e runtime ML preconfigurati per PyTorch e XGBoost. Integra con l'ecosistema AI Google Cloud per orchestrare MLOps end-to-end e gestire gli asset con l'integrazione di Gemini Enterprise Agent Platform Model Registry.
Migrazioni sicure, scalabili e senza interruzioni
Integra senza problemi la tua security posture utilizzando IAM, i Controlli di servizio VPC e Kerberos. Esegui facilmente la migrazione dei workload Spark legacy e cloud utilizzando i modelli e gli strumenti di Managed Service for Apache Spark. Esegui il lift-and-shift dei workload con il supporto per Spark 2.x fino a Spark 4.0 senza refactoring immediato del codice.
Efficienza multi-tenant e controlli FinOps
Massimizza l'utilizzo delle risorse e riduci i costi di inattività. Fai il deployment di cluster Spark multi-tenant che consentono a un massimo di 800 utenti di condividere risorse di calcolo mantenendo al contempo un rigoroso isolamento dei dati e dell'ambiente. Tieni sotto controllo i costi con funzionalità di scalabilità fino a zero, fatturazione al secondo e supporto per VM spot per workload flessibili.
Ecosistema aperto e flessibile
Nessun vincolo al fornitore. Sebbene ottimizzati per Apache Spark, i nostri cluster gestiti supportano oltre 30 strumenti open source come Apache Hadoop, Flink e Trino. Si integrano senza problemi con orchestratori come Managed Service for Apache Airflow e si estendono con Kubernetes e Docker per la massima flessibilità.
Opzioni di deployment
| Opzioni di deployment | Scegli tra il controllo granulare dei cluster gestiti o la semplicità zero-ops di un'esperienza serverless per l'opzione migliore per il tuo carico di lavoro. | ||
|---|---|---|---|
| Modalità di deployment | Descrizione | Ideale per | Paga per: |
Serverless | Job Spark as a Service. Managed Spark, infrastruttura gestita. | Nuove pipeline, analisi interattive e workload con picchi in cui è preferibile utilizzare un modello zero-ops con pagamento per job. | Tempo di esecuzione del job |
Cluster | Cluster Spark as a Service. Managed Spark, la tua infrastruttura. | Migrazione di workload Spark o OSS legacy, esecuzione di cluster persistenti o necessità di personalizzazione open source approfondita. | Uptime del cluster |
Opzioni di deployment
Scegli tra il controllo granulare dei cluster gestiti o la semplicità zero-ops di un'esperienza serverless per l'opzione migliore per il tuo carico di lavoro.
Serverless
Job Spark as a Service.
Managed Spark, infrastruttura gestita.
Nuove pipeline, analisi interattive e workload con picchi in cui è preferibile utilizzare un modello zero-ops con pagamento per job.
Tempo di esecuzione del job
Cluster
Cluster Spark as a Service.
Managed Spark, la tua infrastruttura.
Migrazione di workload Spark o OSS legacy, esecuzione di cluster persistenti o necessità di personalizzazione open source approfondita.
Uptime del cluster
Come funziona
Semplifica Spark con cluster serverless zero-ops o gestiti. Lavora in modo più intelligente con Gemini nell'IDE che preferisci, utilizzando l'AI agentica per accelerare lo sviluppo PySpark. Esegui i job più velocemente con Lightning Engine, mantenendo al contempo una governance unificata nella tua open lakehouse con Knowledge Catalog.
Semplifica Spark con cluster serverless zero-ops o gestiti. Lavora in modo più intelligente con Gemini nell'IDE che preferisci, utilizzando l'AI agentica per accelerare lo sviluppo PySpark. Esegui i job più velocemente con Lightning Engine, mantenendo al contempo una governance unificata nella tua open lakehouse con Knowledge Catalog.
Data engineering su larga scala
Pipeline ETL automatizzate
Pipeline ETL automatizzate
Crea pipeline ETL Spark robuste e basate su eventi che si scalano automaticamente su richiesta. Sfrutta l'esecuzione serverless per workload con picchi di attività o cluster gestiti per job persistenti. Utilizza i template di workflow per automatizzare i tuoi job di elaborazione dati più critici a livello di produzione dall'inizio alla fine.
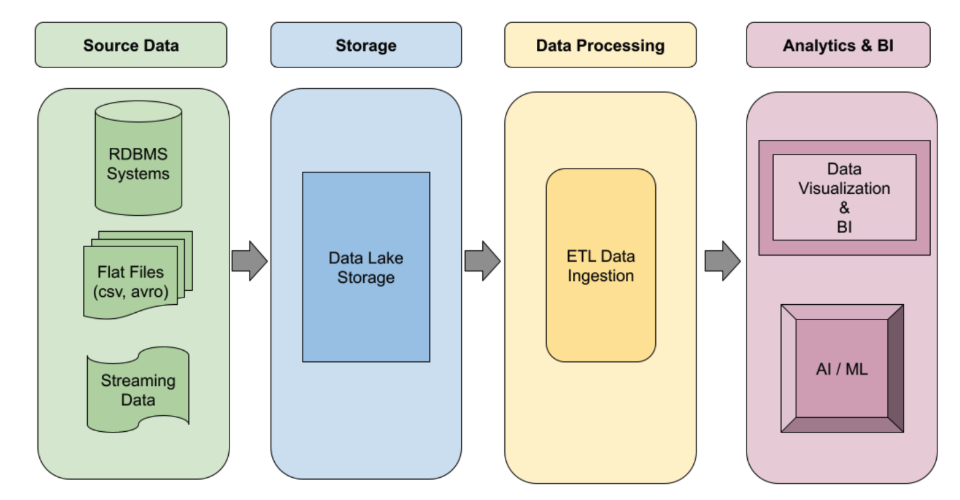


Tutorial, guide rapide e lab
Pipeline ETL automatizzate
Pipeline ETL automatizzate
Crea pipeline ETL Spark robuste e basate su eventi che si scalano automaticamente su richiesta. Sfrutta l'esecuzione serverless per workload con picchi di attività o cluster gestiti per job persistenti. Utilizza i template di workflow per automatizzare i tuoi job di elaborazione dati più critici a livello di produzione dall'inizio alla fine.
Data science e machine learning
Data science interattiva
Data science interattiva
Consenti ai data scientist di esplorare i dati e di eseguire l'iterazione sui modelli Spark ML. Unifica SQL e Spark utilizzando Gemini con l'estensione agentica VSCode o l'IDE che preferisci, passando senza problemi dall'esplorazione dei dati alla creazione di modelli con PySpark usando l'esecuzione serverless. Collega le GPU con un singolo comando.


Tutorial, guide rapide e lab
Data science interattiva
Data science interattiva
Consenti ai data scientist di esplorare i dati e di eseguire l'iterazione sui modelli Spark ML. Unifica SQL e Spark utilizzando Gemini con l'estensione agentica VSCode o l'IDE che preferisci, passando senza problemi dall'esplorazione dei dati alla creazione di modelli con PySpark usando l'esecuzione serverless. Collega le GPU con un singolo comando.
Modernizzazione del lakehouse
Open data lakehouse
Open data lakehouse
Utilizza Managed Service for Apache Spark come motore di elaborazione per il tuo data lakehouse moderno. Elabora i dati in formati aperti come Apache Iceberg direttamente dal tuo data lake, eliminando i silos di dati. Integra con BigQuery e Lakehouse for Apache Iceberg per una piattaforma di analisi unificata e multi-motore.
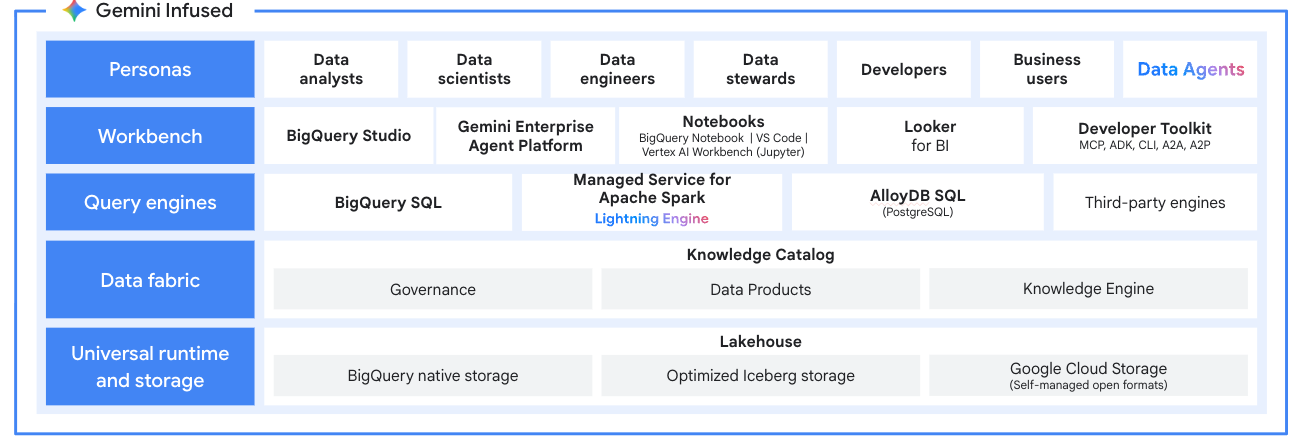

Tutorial, guide rapide e lab
Open data lakehouse
Open data lakehouse
Utilizza Managed Service for Apache Spark come motore di elaborazione per il tuo data lakehouse moderno. Elabora i dati in formati aperti come Apache Iceberg direttamente dal tuo data lake, eliminando i silos di dati. Integra con BigQuery e Lakehouse for Apache Iceberg per una piattaforma di analisi unificata e multi-motore.
Prezzi
| Come funzionano i prezzi di Managed Service for Apache Spark | Il prezzo dipende dal modello di deployment scelto. Serverless fattura per esecuzione del job, mentre cluster per calcolo sottostante e uptime. | |
|---|---|---|
| Modalità di deployment: | Cosa paghi: | Cosa paghi: |
Serverless | Paghi solo per quello che usi. Fatturazione al secondo per calcolo, GPU e spazio di archiviazione shuffle. La scalabilità fino a zero ti garantisce di non pagare mai per la capacità inattiva. | A partire da 0,06 $ per DCU/ora |
Livello Premium e acceleratori: Accedi a Lightning Engine per prestazioni fino a 4,9 volte più veloci o collega le GPU NVIDIA per i workload AI/ML. | A partire da 0,089 $ per DCU/ora Livello Premium serverless | |
Cluster | Paga per l'uptime del cluster. Vengono addebitati i costi delle risorse Compute Engine sottostanti più una tariffa di gestione fissa. Sfrutta le VM spot e la scalabilità zero per ottimizzare i costi. | A partire da 0,01 $ per ora di vCPU Costi di gestione |
Componente aggiuntivo Lightning Engine: Offri prestazioni rivoluzionarie ai tuoi cluster. Sperimenta un'esecuzione fino a 4,9 volte più veloce rispetto a Spark open source. | A partire da $ 0,0025 per ora vCPU | |
Scopri di più sui prezzi di Managed Service for Apache Spark. Visualizza tutti i dettagli sui prezzi
Come funzionano i prezzi di Managed Service for Apache Spark
Il prezzo dipende dal modello di deployment scelto. Serverless fattura per esecuzione del job, mentre cluster per calcolo sottostante e uptime.
Serverless
Paghi solo per quello che usi. Fatturazione al secondo per calcolo, GPU e spazio di archiviazione shuffle. La scalabilità fino a zero ti garantisce di non pagare mai per la capacità inattiva.
Starting at
0,06 $ per DCU/ora
Livello Premium e acceleratori:
Accedi a Lightning Engine per prestazioni fino a 4,9 volte più veloci o collega le GPU NVIDIA per i workload AI/ML.
Starting at
0,089 $ per DCU/ora
Livello Premium serverless
Cluster
Paga per l'uptime del cluster. Vengono addebitati i costi delle risorse Compute Engine sottostanti più una tariffa di gestione fissa. Sfrutta le VM spot e la scalabilità zero per ottimizzare i costi.
Starting at
0,01 $ per ora di vCPU
Costi di gestione
Componente aggiuntivo Lightning Engine:
Offri prestazioni rivoluzionarie ai tuoi cluster. Sperimenta un'esecuzione fino a 4,9 volte più veloce rispetto a Spark open source.
Starting at
$ 0,0025 per ora vCPU
Scopri di più sui prezzi di Managed Service for Apache Spark. Visualizza tutti i dettagli sui prezzi
Business case
Casi di successo dei clienti

"Abbiamo visto alcuni dei nostri controlli di qualità passare da 11 ore a pochi minuti".
Michael Manos, Chief Technology Officer di Dun & Bradstreet
La migrazione a Google Cloud ha aiutato Dun & Bradstreet ad aumentare in modo significativo la velocità dei flussi di dati, riducendo i processi di controllo della qualità da ore a minuti e dimezzando il tempo necessario per pubblicare nuovi dati. Questa solida base di dati consente inoltre a Dun & Bradstreet di sfruttare tutta la potenza dell'ecosistema Google Cloud, comprese le tecnologie di dati e AI all'avanguardia.



La differenza di Managed Service for Apache Spark
Produttività zero-ops con opzioni di deployment flessibili. Scegli l'esecuzione serverless o cluster completamente gestiti per eliminare l'overhead dell'infrastruttura e la necessità di ottimizzazione manuale.
Sviluppo dell'AI agentica. Accelera il tuo workflow con Gemini integrato nell'estensione agentica VSCode o con l'IDE di tua scelta insieme ad agenti di dati che automatizzano la programmazione PySpark, il data wrangling e la risoluzione dei problemi dei job in un notebook unificato.
Prestazioni leader del settore. Basate su Lightning Engine. Accelera fino a 4,9 volte i tuoi workload ETL e di data science più impegnativi, riducendo in modo significativo il costo totale di proprietà










Risorse aggiuntive:
Domande frequenti
Che cosa è successo a Dataproc e a Serverless Spark?
Per semplificare la tua esperienza, abbiamo unificato Dataproc e Google Cloud Serverless per Apache Spark in un unico prodotto: Managed Service for Apache Spark. Ottieni le stesse potenti funzionalità, ma ora puoi scegliere in tutta semplicità il modello di deployment che preferisci (serverless zero-ops o cluster completamente gestiti) da un'unica interfaccia unificata. Confronta le due modalità di deployment in maggiore dettaglio.
Quando devo scegliere tra serverless e cluster gestiti?
Scegli il modello serverless quando vuoi concentrarti esclusivamente sul codice senza dover gestire l'infrastruttura, l'ideale per nuove pipeline e analisi ad hoc. Scegli i cluster gestiti quando hai bisogno di un controllo granulare, stai migrando Spark legacy o cloud o altri workload OSS oppure hai bisogno di cluster persistenti con diversi strumenti open source.
Che cos'è Lightning Engine?
Lightning Engine è il motore di esecuzione nativo e altamente ottimizzato di Google Cloud. Realizzato con librerie C++, ottimizza ogni livello, dai connettori di archiviazione a throughput elevato alla memorizzazione intelligente nella cache. Offre prestazioni fino a 4,9 volte migliori rispetto a Spark standard e un rapporto prezzo/prestazioni due volte migliore rispetto alla principale alternativa Spark ad alta velocità, integrandosi perfettamente nei tuoi deployment serverless o di cluster senza alcuna modifica al codice.
Devo installare le mie librerie ML come PyTorch?
No. Se esegui workload AI/ML, puoi utilizzare i nostri runtime ML preconfigurati. Questi ambienti sono dotati di librerie comuni come PyTorch, XGBoost e scikit-learn integrate, oltre a driver GPU NVIDIA ottimizzati, eliminando la necessità di una configurazione complessa.
Managed Service for Apache Spark è completamente compatibile con l'open source?
Sì. Forniamo un ambiente Apache Spark compatibile al 100% con l'open source. Puoi eseguire il codice Spark esistente senza modifiche, garantendo la completa portabilità dei workload ed evitando qualsiasi vincolo a un fornitore.
In che modo Gemini AI aiuta nello sviluppo di Spark?
Gemini AI può essere integrata direttamente nell'IDE che preferisci per fungere da copilota AI. Ti aiuta a scrivere ed eseguire il debug del codice PySpark più velocemente, mentre Gemini Cloud Assist fornisce analisi automatizzate della causa principale e consigli per la risoluzione dei problemi per i job non riusciti.
Posso utilizzare questo servizio per creare un open data lakehouse?
Certo. Managed Service for Apache Spark è un motore di elaborazione principale per il lakehouse aperto di Google Cloud. Consente di elaborare i dati in formati aperti come Apache Iceberg direttamente da Cloud Storage, integrandosi perfettamente con BigQuery e Knowledge Catalog per Apache Iceberg.
Come funzionano i livelli di prezzo standard e premium?
Attualmente i livelli Standard e Premium si applicano solo ai deployment serverless. Il livello Standard è ideale per svolgere in modo economicamente vantaggioso attività di elaborazione batch ed ETL per uso generico. Il livello Premium, progettato per i workload più impegnativi, permette di beneficiare di prestazioni potenziate di 4,9 volte rispetto ad Apache Spark open source con Lightning Engine e fornisce l'accesso a funzionalità di AI/ML accelerate da GPU.











