Esta página descreve a gestão do controlo de acesso quando implementa e executa um pipeline que usa clusters do Dataproc noutro Google Cloud projeto.
Cenário
Por predefinição, quando uma instância do Cloud Data Fusion é iniciada num Google Cloud projeto, implementa e executa pipelines usando clusters do Dataproc no mesmo projeto. No entanto, a sua organização pode exigir que use clusters noutro projeto. Para este exemplo de utilização, tem de gerir o acesso entre os projetos. A página seguinte descreve como pode alterar as configurações de base (predefinição) e aplicar os controlos de acesso adequados.
Antes de começar
Para compreender as soluções neste exemplo de utilização, precisa do seguinte contexto:
- Familiaridade com os conceitos básicos do Cloud Data Fusion
- Familiaridade com a gestão de identidade e de acesso (IAM) para o Cloud Data Fusion
- Familiaridade com as redes do Cloud Data Fusion
Pressupostos e âmbito
Este exemplo de utilização tem os seguintes requisitos:
- Uma instância privada do Cloud Data Fusion. Por motivos de segurança, uma organização pode exigir que use este tipo de instância.
- Uma origem e um destino do BigQuery.
- Controlo de acesso com IAM, não controlo de acesso baseado em funções (CABF).
Solução
Esta solução compara a arquitetura e a configuração específicas do valor de referência e do exemplo de utilização.
Arquitetura
Os diagramas seguintes comparam a arquitetura do projeto para criar uma instância do Cloud Data Fusion e executar pipelines quando usa clusters no mesmo projeto (base) e num projeto diferente através da VPC do projeto de inquilino.
Arquitetura de base
Este diagrama mostra a arquitetura de base dos projetos:
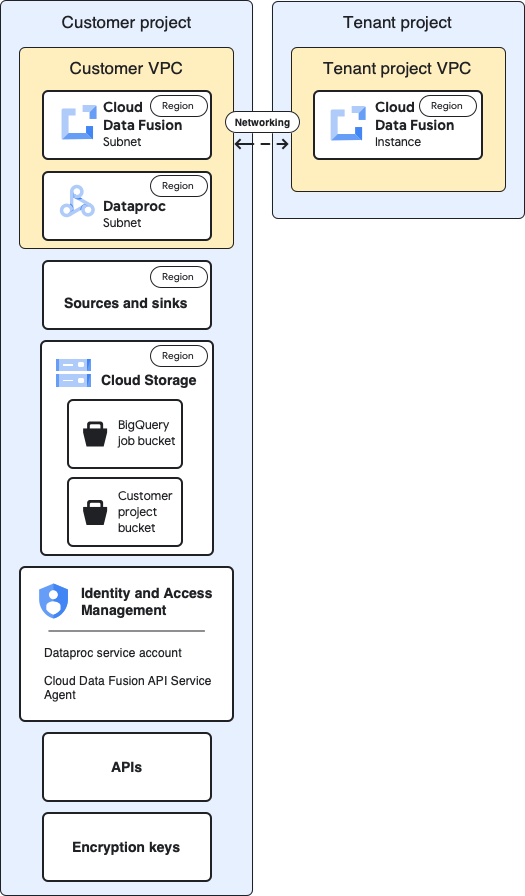
Para a configuração de base, cria uma instância privada do Cloud Data Fusion e executa um pipeline sem personalização adicional:
- Usar um dos perfis de computação integrados
- A origem e o destino estão no mesmo projeto que a instância
- Não foram concedidas funções adicionais a nenhuma das contas de serviço
Para mais informações acerca dos projetos de inquilinos e clientes, consulte a secção Redes.
Arquitetura de exemplos de utilização
Este diagrama mostra a arquitetura do projeto quando usa clusters noutro projeto:
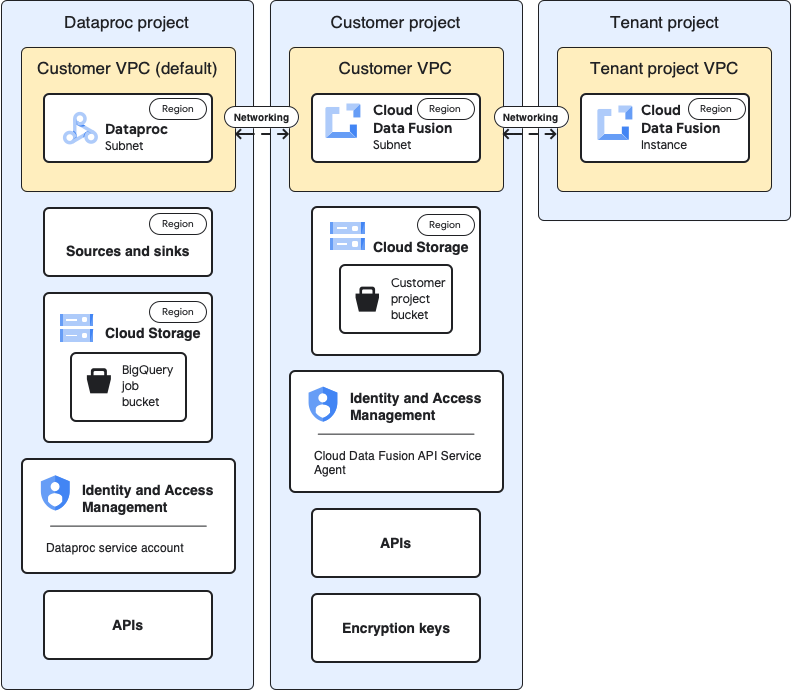
Configurações
As secções seguintes comparam as configurações de base com as configurações específicas do exemplo de utilização para usar clusters do Dataproc num projeto diferente através da VPC do projeto de inquilino predefinido.
Nas descrições de exemplos de utilização seguintes, o projeto do cliente é onde a instância do Cloud Data Fusion é executada e o projeto do Dataproc é onde o cluster do Dataproc é iniciado.
VPC e instância do projeto de inquilino
| Base | Exemplo de utilização |
|---|---|
No diagrama de arquitetura de base anterior, o projeto de inquilino
contém os seguintes componentes:
|
Não é necessária nenhuma configuração adicional para este exemplo de utilização. |
Projeto de cliente
| Base | Exemplo de utilização |
|---|---|
| O Google Cloud projeto é onde implementa e executa pipelines. Por predefinição, os clusters do Dataproc são iniciados neste projeto quando executa os pipelines. | Neste exemplo de utilização, gere dois projetos. Nesta página, o
projeto do cliente refere-se ao local onde a instância do Cloud Data Fusion
é executada. O projeto do Dataproc refere-se ao local onde os clusters do Dataproc são iniciados. |
VPC do cliente
| Base | Exemplo de utilização |
|---|---|
Do seu ponto de vista (o do cliente), a VPC do cliente é onde o Cloud Data Fusion está logicamente situado. Ponto principal: pode encontrar os detalhes da VPC do cliente na página de redes VPC do seu projeto. |
Não é necessária nenhuma configuração adicional para este exemplo de utilização. |
Sub-rede do Cloud Data Fusion
| Base | Exemplo de utilização |
|---|---|
Do seu ponto de vista (do cliente), esta sub-rede é onde o Cloud Data Fusion está logicamente situado. Principal conclusão: a região desta sub-rede é a mesma que a localização da instância do Cloud Data Fusion no projeto do inquilino. |
Não é necessária nenhuma configuração adicional para este exemplo de utilização. |
Sub-rede do Dataproc
| Base | Exemplo de utilização |
|---|---|
A sub-rede onde os clusters do Dataproc são iniciados quando executa um pipeline. Principais pontos a reter:
|
Esta é uma nova sub-rede onde os clusters do Dataproc são iniciados quando executa um pipeline. Principais pontos a reter:
|
Ganhos e despesas
| Base | Exemplo de utilização |
|---|---|
As origens de onde os dados são extraídos e os destinos onde os dados são carregados, como origens e destinos do BigQuery. Principais pontos a reter:
|
As configurações de controlo de acesso específicas do exemplo de utilização nesta página destinam-se a origens e destinos do BigQuery. |
Cloud Storage
| Base | Exemplo de utilização |
|---|---|
O contentor de armazenamento no projeto do cliente que ajuda a transferir ficheiros entre o Cloud Data Fusion e o Dataproc. Principais pontos a reter:
|
Não é necessária nenhuma configuração adicional para este exemplo de utilização. |
Recipientes temporários usados pela origem e pelo destino
| Base | Exemplo de utilização |
|---|---|
Os contentores temporários criados por plug-ins para as suas origens e destinos, como as tarefas de carregamento iniciadas pelo plug-in BigQuery Sink. Principais pontos a reter:
|
Para este exemplo de utilização, o contentor pode ser criado em qualquer projeto. |
Recipientes que são origens ou destinos de dados para plug-ins
| Base | Exemplo de utilização |
|---|---|
| Contentores de clientes, que especifica nas configurações dos plug-ins, como o plug-in do Cloud Storage e o plug-in FTP para Cloud Storage. | Não é necessária nenhuma configuração adicional para este exemplo de utilização. |
IAM: Agente de serviço da API Cloud Data Fusion
| Base | Exemplo de utilização |
|---|---|
Quando a API Cloud Data Fusion está ativada, a
função de agente do serviço da API Cloud
Data Fusion
( Principais pontos a reter:
|
Para este exemplo de utilização, conceda a função de agente de serviço da API Cloud Data Fusion à conta de serviço no projeto do Dataproc. Em seguida, conceda as seguintes funções nesse projeto:
|
IAM: conta de serviço do Dataproc
| Base | Exemplo de utilização |
|---|---|
A conta de serviço usada para executar o pipeline como uma tarefa no cluster do Dataproc. Por predefinição, é a conta de serviço do Compute Engine. Opcional: na configuração de base, pode alterar a conta de serviço predefinida para outra conta de serviço do mesmo projeto. Conceda as seguintes funções do IAM à nova conta de serviço:
|
Este exemplo de utilização pressupõe que usa a conta de serviço do Compute Engine predefinida ( Conceda as seguintes funções à conta de serviço do Compute Engine predefinida no projeto do Dataproc.
Conceda a função de utilizador da conta de serviço à conta de serviço do Cloud Data Fusion na conta de serviço do Compute Engine predefinida do projeto do Dataproc. Esta ação tem de ser realizada no projeto do Dataproc. Adicione a conta de serviço predefinida do Compute Engine do projeto do Dataproc ao projeto do Cloud Data Fusion. Atribua também as seguintes funções:
|
APIs
| Base | Exemplo de utilização |
|---|---|
Quando ativa a API Cloud Data Fusion, as seguintes APIs também são ativadas: Para mais informações sobre estas APIs, aceda à
página APIs e serviços no seu projeto.
Quando ativa a API Cloud Data Fusion, as seguintes contas de serviço são adicionadas automaticamente ao seu projeto:
|
Para este exemplo de utilização, ative as seguintes APIs no projeto que
contém o projeto do Dataproc:
|
Chaves de encriptação
| Base | Exemplo de utilização |
|---|---|
Na configuração base, as chaves de encriptação podem ser geridas pela Google ou CMEK Principais pontos a reter: Se usar as CMEK, a configuração de base requer o seguinte:
Consoante os serviços usados no seu pipeline, como o BigQuery ou o Cloud Storage, as contas de serviço também têm de receber a função de encriptador/desencriptador de CryptoKey do Cloud KMS:
|
Se não usar as CMEK, não são necessárias alterações adicionais para este exemplo de utilização. Se usar a CMEK, a função de encriptador/desencriptador de CryptoKey do Cloud KMS tem de ser fornecida à seguinte conta de serviço ao nível da chave no projeto onde é criada:
Consoante os serviços usados no seu pipeline, como o BigQuery ou o Cloud Storage, também tem de conceder a função de encriptar/desencriptar do CryptoKey do Cloud KMS a outras contas de serviço ao nível da chave. Por exemplo:
|
Depois de fazer estas configurações específicas do exemplo de utilização, o pipeline de dados pode começar a ser executado em clusters noutro projeto.
O que se segue?
- Saiba mais sobre as redes no Cloud Data Fusion.
- Consulte a referência de funções básicas e predefinidas do IAM.