本指南介绍如何部署、配置和运行使用 SAP OData 插件的数据流水线。
您可以使用 Open Data Protocol (OData) 将 SAP 用作在 Cloud Data Fusion 中基于批次的数据提取的来源。借助 SAP OData 插件,您无需编写代码即可配置和执行从 SAP OData Catalog Service 开始的数据转移。
如需详细了解受支持的 SAP OData Catalog 服务和数据源,请参阅支持详情。如需详细了解 SAP on Google Cloud,请参阅 SAP on Google Cloud 概览。
目标
- 配置 SAP ERP 系统(在 SAP 中激活 DataSource)。
- 在 Cloud Data Fusion 环境中部署插件。
- 从 Cloud Data Fusion 下载 SAP 传输文件并将其安装在 SAP 中。
- 使用 Cloud Data Fusion 和 SAP OData 创建用于集成 SAP 数据的数据流水线。
准备工作
要使用此插件,您需要具备以下方面的领域知识:
- 在 Cloud Data Fusion 中构建流水线
- 使用 IAM 管理访问权限
- 配置 SAP Cloud 和本地企业资源规划 (ERP) 系统
用户角色
此页面上的任务由 Google Cloud 或 SAP 系统中具有以下角色的人员执行:
| 用户类型 | 说明 |
|---|---|
| Google Cloud 管理员 | 获分此角色的用户是 Google Cloud 帐号的管理员。 |
| Cloud Data Fusion 用户 | 获分此角色的用户有权设计和运行数据流水线。他们至少被授予了 Data Fusion Viewer (roles/datafusion.viewer) 角色。如果您使用的是基于角色的访问权限控制,则可能需要其他角色。 |
| SAP 管理员 | 分配到此角色的用户是 SAP 系统的管理员。他们拥有从 SAP 服务网站下载软件的权限。它不是 IAM 角色。 |
| SAP 用户 | 获分此角色的用户有权连接到 SAP 系统。它不是 IAM 角色。 |
OData 提取的前提条件
必须在 SAP 系统中激活 OData Catalog 服务。
必须在 OData 服务中填充数据。
SAP 系统的前提条件
在 SAP NetWeaver 版本 7.02 到 SAP NetWeaver 版本 7.31 中,OData 和 SAP Gateway 功能随以下 SAP 软件组件提供:
IW_FNDGW_COREIW_BEP
在 SAP NetWeaver 版本 7.40 及更高版本中,所有功能都在组件
SAP_GWFND中提供,该组件必须在 SAP NetWeaver 中可用。
可选:安装 SAP 传输文件
对 SAP 进行负载均衡调用所需的 SAP 组件以 SAP 传输文件的形式提供,这些传输文件以 zip 文件的形式归档(一个传输请求,由一个 cofile 和一个数据文件组成)。根据 SAP 中的可用工作流,您可以使用此步骤限制对 SAP 的多次并行调用。
当您在 Cloud Data Fusion Hub 中部署插件时,可以下载 ZIP 文件。
下表提供了 SAP 传输请求 ID 和关联文件:
| 传输 ID | Cofile | 数据文件 | 内容 |
|---|---|---|---|
| ED1K900360 | K900360.ED1 | R900360.ED1 | 通过 OData 公开的 RFC 函数模块 |
将传输文件导入 SAP 时,系统会创建以下 SAP OData 项目:
OData 项目
/GOOG/GET_STATISTIC/GOOG/TH_WPINFO
ICF 服务节点:
GOOG
如需安装 SAP 传输,请按照以下步骤操作:
第 1 步:上传传输请求文件
- 登录 SAP 实例的操作系统。
- 使用 SAP 事务代码
AL11获取DIR_TRANS文件夹的路径。通常,该路径为/usr/sap/trans/。 - 将 cofile 复制到
DIR_TRANS/cofiles文件夹。 - 将数据文件复制到
DIR_TRANS/data文件夹。 - 将“用户和组”以及数据文件设置为
<sid>adm和sapsys。
第 2 步:导入传输请求文件
SAP 管理员可以使用以下任一选项导入传输请求文件:
选项 1:使用 SAP 传输管理系统导入传输请求文件
- 以 SAP 管理员身份登录 SAP 系统。
- 输入事务 STMS。
- 点击 Overview > Imports。
- 在队列列中,双击当前 SID。
- 依次点击附加服务 > 其他请求 > 添加。
- 选择传输请求 ID,然后点击继续。
- 在导入队列中选择传输请求,然后点击 Request > Import。
- 输入客户端编号。
在选项标签页上,选择覆盖原始文件和忽略无效的组件版本(如果有)。
(可选)如需安排稍后重新导入传输,请选择 Leaveport requests in 队列中以供稍后导入和再次导入传输请求。这对于 SAP 系统升级和备份恢复非常有用。
点击继续。
要验证导入作业,请使用
SE80和SU01等事务。
选项 2:在操作系统级层导入传输请求文件
- 以 SAP 系统管理员身份登录 SAP 系统。
通过运行以下命令向导入缓冲区添加适当的请求:
tp addtobuffer TRANSPORT_REQUEST_ID SID例如:
tp addtobuffer IB1K903958 DD1通过运行以下命令导入传输请求:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238将
NNN替换为客户端编号。例如:tp import IB1K903958 DD1 client=800 U1238使用适当的事务(如
SE80和SU01)验证函数模块和授权角色是否已成功导入。
获取 SAP 目录服务的可过滤列列表
只有部分 DataSource 列可用于过滤条件(这是设计上的 SAP 限制)。
如需获取 SAP 目录服务的可过滤列列表,请按照以下步骤操作:
- 登录 SAP 系统。
- 转到事务代码 (t-code)
SEGW。 输入 OData 项目名称,即服务名称的子字符串。例如:
- 服务名称:
MM_PUR_POITEMS_MONI_SRV - 项目名称:
MM_PUR_POITEMS_MONI
- 服务名称:
点击 Enter。
转到要过滤的实体,然后选择属性。
您可以使用属性中显示的字段作为过滤条件。支持的操作包括等于和介于(范围)。

如需查看表达式语言支持的运算符列表,请参阅 OData 开源文档:URI 惯例(OData 版本 2.0)。
包含过滤条件的 URI 示例:
/sap/opu/odata/sap/MM_PUR_POITEMS_MONI_SRV/C_PurchaseOrderItemMoni(P_DisplayCurrency='USD')/Results/?$filter=(PurchaseOrder eq '4500000000')
配置 SAP ERP 系统
SAP OData 插件使用一项 OData 服务,该服务会在提取数据的每个 SAP Server 上激活。此 OData 服务可以是 SAP 提供的标准,也可以是在您的 SAP 系统上开发的自定义 OData 服务。
第 1 步:安装 SAP Gateway 2.0
SAP (Basis) 管理员必须验证 SAP Gateway 2.0 组件在 SAP 源系统中是否可用,具体取决于 NetWeaver 版本。如需详细了解如何安装 SAP Gateway 2.0,请登录 SAP ONE Support Launchpad,并参阅备注 1569624(需要登录)。
第 2 步:激活 OData 服务
在源系统上激活所需的 OData 服务。如需了解详情,请参阅前端服务器:激活 OData 服务。
第 3 步:创建授权角色
如需连接到 DataSource,请在 SAP 中创建具有所需授权的授权角色,然后将其授予 SAP 用户。
如需在 SAP 中创建授权角色,请按以下步骤操作:
- 在 SAP GUI 中,输入事务代码 PFCG 以打开角色维护窗口。
在角色字段中,输入角色的名称。
例如:
ZODATA_AUTH点击单个角色。
此时会打开创建角色窗口。
在说明字段中,输入说明,然后点击保存。
例如:
Authorizations for SAP OData plugin。点击授权标签页。窗口的标题将更改为更改角色。
在编辑授权数据并生成配置文件下,点击 更改授权数据。
这时会打开选择模板窗口。
点击不选择模板。
这时会打开更改角色:授权窗口。
点击手动。
提供以下 SAP 授权表中显示的授权。
点击保存。
要激活授权角色,请点击生成图标。
SAP 授权
| 对象类 | 对象类文本 | 授权对象 | 授权对象文本 | 授权 | 文本 | 值 |
|---|---|---|---|---|---|---|
| AAAB | 跨应用授权对象 | S_SERVICE | 在外部服务开始时检查 | SRV_NAME | 程序、事务或函数模块名称 | * |
| AAAB | 跨应用授权对象 | S_SERVICE | 在外部服务开始时检查 | SRV_TYPE | 检查标志和授权默认值的类型 | HT |
| FI | 财务会计 | F_UNI_HIER | 通用层次结构访问权限 | ACTVT | 活动 | 03 |
| FI | 财务会计 | F_UNI_HIER | 通用层次结构访问权限 | HRYTYPE | 层次结构类型 | * |
| FI | 财务会计 | F_UNI_HIER | 通用层次结构访问权限 | HRYID | 层次结构 ID | * |
如需在 Cloud Data Fusion 中设计和运行数据流水线(作为 Cloud Data Fusion 用户),您需要 SAP 用户凭据(用户名和密码)来配置插件以连接到 DataSource。
SAP 用户必须是 Communications 或 Dialog 类型。为避免使用 SAP 对话框资源,建议使用 Communications 类型。可以使用 SAP 事务代码 SU01 来创建用户。
可选:第 4 步:保护连接
您可以通过网络保护在私有 Cloud Data Fusion 实例和 SAP 之间的通信。
如需保护连接,请按以下步骤操作:
- SAP 管理员必须生成 X509 证书。如需生成证书,请参阅创建 SSL 服务器 PSE。
- Google Cloud 管理员必须将 X509 文件复制到与 Cloud Data Fusion 实例位于同一项目中的可读 Cloud Storage 存储桶,并将存储桶路径提供给 Cloud Data Fusion 用户,用户会在配置插件时输入路径。
- Google Cloud 管理员必须将 X509 文件的读取权限授予设计和运行流水线的 Cloud Data Fusion 用户。
可选:第 5 步:创建自定义 OData 服务
您可以通过在 SAP 中创建自定义 OData 服务来自定义提取数据的方式:
- 如需创建自定义 OData 服务,请参阅为新手创建 OData 服务。
- 如需使用核心数据服务 (CDS) 视图来创建自定义 OData 服务,请参阅如何创建 OData 服务并将 CDS 视图公开为 OData 服务。
- 任何自定义 OData 服务都必须支持
$top、$skip和$count查询。通过这些查询,插件可以对数据进行分区,以进行依序和并行提取。如果使用了$filter、$expand或$select查询,还必须支持。
设置 Cloud Data Fusion
确保 Cloud Data Fusion 实例和 SAP 服务器之间启用了通信。对于专用实例,请设置网络对等互连。在与托管 SAP 系统的项目建立网络对等互连后,无需额外配置即可连接到 Cloud Data Fusion 实例。SAP 系统和 Cloud Data Fusion 实例需要位于同一项目中。
第 1 步:设置 Cloud Data Fusion 环境
要为插件配置 Cloud Data Fusion 环境,请执行以下操作:
前往实例详情:
在 Google Cloud 控制台中,转到 Cloud Data Fusion 页面。
点击实例,然后点击相应实例的名称以转到实例详情页面。
检查实例是否已升级到 6.4.0 或更高版本。如果实例为早期版本,则需要升级。
点击查看实例。当 Cloud Data Fusion 界面打开后,点击中心。
选择 SAP 标签页 > SAP OData。
如果 SAP 标签页未显示,请参阅排查 SAP 集成问题。
点击部署 SAP OData 插件。
该插件现在会显示在 Studio 页面的来源菜单中。
第 2 步:配置插件
SAP OData 插件读取 SAP DataSource 的内容。
如需过滤记录,您可以在“SAP OData 属性”页面上配置以下属性。
| 属性名称 | 说明 |
|---|---|
| 基本 | |
| 参考名称 | 用于唯一识别此来源以进行沿袭,注释元数据等操作的名称。 |
| SAP OData 基本网址 | SAP Gateway OData Base 网址(使用完整的网址路径,类似于 https://ADDRESS:PORT/sap/opu/odata/sap/)。 |
| OData 版本 | 支持的 SAP OData 版本。 |
| 服务名称 | 您要从中提取实体的 SAP OData 服务的名称。 |
| 实体名称 | 要提取的实体的名称,例如 Results。您可以使用前缀,例如 C_PurchaseOrderItemMoni/Results。此字段支持“类别”和“实体”参数。示例:
|
| 获取架构按钮 | 根据来自 SAP 的元数据生成架构,并自动将 SAP 数据类型映射到相应的 Cloud Data Fusion 数据类型(与验证按钮的功能相同)。 |
| 凭据* | |
| SAP 类型 | 基本(通过用户名和密码)。 |
| SAP 登录用户名 | SAP 用户名 建议:如果 SAP 登录用户名定期更改,请使用宏。 |
| SAP 登录密码 | SAP 用户密码 推荐:针对密码等敏感值使用安全宏。 |
| SAP X.509 客户端证书 (请参阅在 SAP NetWeaver 应用服务器上为 ABAP 使用 X.509 客户端证书。 |
|
| GCP 项目 ID | 项目的全局唯一标识符。如果 X.509 证书 Cloud Storage 路径字段不包含宏值,则此字段为必填字段。 |
| GCS 路径 | 包含用户上传的 X.509 证书的 Cloud Storage 存储桶路径,该证书对应于 SAP 应用服务器,用于根据您的要求进行安全调用(请参阅保护连接步骤)。 |
| 密码 | 与提供的 X.509 证书对应的口令。 |
| 高级 | |
| “过滤”选项 | 表示字段必须读取的值。使用此过滤条件来限制输出数据量。例如:“Price Gt 200”会选择“Price”字段值大于“200”的记录。(请参阅获取 SAP 目录服务的可过滤列列表。) |
| 选择字段 | 要在提取的数据中保留的字段(例如:类别、价格、名称、供应商/地址)。 |
| 展开字段 | 要在提取的输出数据中展开的复杂字段(例如:产品/供应商)的列表。 |
| 要跳过的行数 | 要跳过的总行数(例如:10)。 |
| 要提取的行数 | 要提取的总行数。 |
| 要生成的分片数 | 用于对输入数据进行分区的分片数量。分区越多,并行程度越高,但需要的资源和开销也越多。 如果留空,插件会选择一个最佳值(推荐)。 |
| 批次大小 | 在每次对 SAP 的网络调用中要提取的行数。大小较小会导致频繁的网络调用重复相关开销。大小较大可能会减慢数据检索速度,并导致 SAP 中过度使用资源。如果该值设置为 0,则默认值为 2500,每批可提取的行数上限为 5000。 |
支持的 OData 类型
下表显示了在 SAP 应用和 Cloud Data Fusion 数据类型中使用的 OData v2 数据类型之间的映射。
| OData 类型 | 说明 (SAP) | Cloud Data Fusion 数据类型 |
|---|---|---|
| 数字 | ||
| SByte | 有符号的 8 位整数值 | int |
| Byte | 无符号的 8 位整数值 | int |
| Int16 | 有符号的 16 位整数值 | int |
| Int32 | 有符号的 32 位整数值 | int |
| Int64 | 有符号的 64 位整数值,附加以下字符:“L” 示例: 64L、-352L |
long |
| 单精度型 | 精度为 7 位的浮点数,可表示近似范围 ± 1.18e -38 至 ± 3.40e +38,后跟字符“f” 示例: 2.0f |
float |
| 双精度型 | 精度为 15 位的浮点数,可表示近似范围 ± 2.23e -308 至 ± 1.79e +308,后跟字符“d” 示例: 1E+10d、2.029d、2.0d |
double |
| 十进制 | 具有固定精度和标度的数值,范围从负 10^255 + 1 到正 10^255 -1,后跟字符“M”或“m” 示例: 2.345M |
decimal |
| 字符 | ||
| Guid | 16 个字节(128 位)唯一标识符值,以“guid”字符开头 示例: guid'12345678-aaaa-bbbb-cccc-ddddeeeeffff' |
string |
| 字符串 | 采用 UTF-8 编码的固定或可变长度字符数据 | string |
| Byte | ||
| 二进制 | 固定或可变长度的二进制数据,以“X”或“binary”(均区分大小写)开头 示例: X'23AB'、binary'23ABFF' |
bytes |
| 逻辑 | ||
| 布尔值 | 二进制值逻辑的数学概念 | boolean |
| 日期/时间 | ||
| 日期/时间 | 日期和时间,范围为 1753 年 1 月 1 日中午 12:00:00 到 1999 年 12 月 31 日晚上 11:59:59 | timestamp |
| 时间 | 值介于 0:00:00.x 到 23:59:59.y 之间的时间,其中“x”和“y”取决于精度 | time |
| DateTimeOffset | 以与格林尼治标准时间 (GMT) 相隔分钟数的偏移量表示的日期和时间,范围为 1753 年 1 月 1 日中午 12:00:00 到 9999 年 12 月 31 日晚上 11:59:59 | timestamp |
| 综合体 | ||
| 导航和非导航属性(乘法 = *) | 简单类型的集合,具有一对多的乘数。 | array、string、int 等等 |
| 属性(乘数 = 0.1) | 对具有一对一乘数的其他复杂类型的引用 | record |
验证
点击右上角的验证,或者点击获取架构。
该插件会验证属性,并根据 SAP 中的元数据生成架构。它还会自动将 SAP 数据类型映射到相应的 Cloud Data Fusion 数据类型。
运行数据流水线
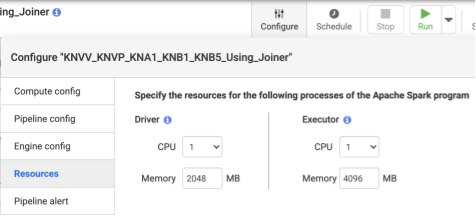
- 部署流水线后,请点击顶部中心面板上的配置。
- 选择资源。
- 如果需要,请根据整体数据大小和流水线中使用的转换数量来更改执行器 CPU 和内存。
- 点击保存。
- 如需启动数据流水线,请点击运行。
性能
该插件使用 Cloud Data Fusion 的同时载入功能。以下指南可帮助您配置运行时环境,以便为运行时引擎提供足够的资源,以实现预期的并行度和性能。
优化插件配置
建议:除非您熟悉 SAP 系统的内存设置,否则请将 Number of Splits to Generate 和 Batch Size 留空(未指定)。
为了在运行流水线时获得更好的性能,请使用以下配置:
要生成的拆分数量:推荐使用
8和16之间的值。但如果在 SAP 端进行适当的配置(为 SAP 中的工作进程分配适当的内存资源),则它们可以增加到32,甚至64。此配置可改善 Cloud Data Fusion 端的并行性。运行时引擎会在提取记录时创建指定数量的分区(和 SAP 连接)。如果配置服务(在您导入 SAP 传输文件时插件附带)可用:插件默认采用 SAP 系统的配置。这些拆分占 SAP 中可用对话框工作流程的 50%。注意:配置服务只能从 S4HANA 系统导入。
如果配置服务不可用,则默认值为
7分块。无论是哪种情况,如果您指定不同的值,则您提供的值将优先于默认拆分值,只不过它受到 SAP 中可用对话框进程的限制(减去两个拆分)。
如果要提取的记录数小于
2500,则拆分数为1。
批次大小:这是每次对 SAP 进行网络调用时要提取的记录数。较小的批次大小会导致频繁的网络调用,从而重复相关的开销。默认情况下,最小计数为
1000,最大值为50000。
如需了解详情,请参阅 OData 实体限制。
Cloud Data Fusion 资源设置
推荐:每个执行器使用 1 个 CPU 和 4 GB 内存(此值适用于每个执行器进程)。请在配置 > 资源对话框中设置这些资源。
Dataproc 集群设置
推荐:分配的最少 CPU 总数(在多个工作器之间)要大于预期的分片数量(请参阅插件配置)。
在 Dataproc 设置中,每个工作器必须为每个 CPU 分配 6.5 GB 或更多内存(这意味着每个 Cloud Data Fusion Executor 的可用内存为 4 GB 或更多)。其他设置可以保留默认值。
推荐:使用永久性 Dataproc 集群来减少数据流水线运行时(这消除了可能需要几分钟或更长时间的预配步骤)。在 Compute Engine 配置部分中设置此项。
示例配置和吞吐量
开发和测试配置示例
- 具有 8 个工作器的 Dataproc 集群,每个工作器具有 4 个 CPU 和 26 GB 内存。最多生成 28 个拆分。
- 具有 2 个工作器的 Dataproc 集群,每个工作器具有 8 个 CPU 和 52 GB 内存。最多可生成 12 个拆分。
示例生产配置和吞吐量
- 具有 8 个工作器的 Dataproc 集群,每个工作器具有 8 个 CPU 和 32 GB 内存。最多生成 32 个分块(可用 CPU 的一半)。
- 具有 16 个工作器的 Dataproc 集群,每个工作器具有 8 个 CPU 和 32 GB 内存。最多生成 64 个分块(可用 CPU 的一半)。
SAP S4HANA 1909 生产源系统的示例吞吐量
下表包含示例吞吐量。除非另有说明,否则显示的吞吐量不带过滤器选项。使用过滤选项时,吞吐量会降低。
| 批次大小 | 分片 | OData 服务 | 总行数 | 提取的行数 | 吞吐量(每秒行数) |
|---|---|---|---|---|---|
| 1000 | 4 | ZACDOCA_CDS | 5,370 万 | 5,370 万 | 1069 |
| 2500 | 10 | ZACDOCA_CDS | 5,370 万 | 5,370 万 | 3384 |
| 5000 | 8 | ZACDOCA_CDS | 5,370 万 | 5,370 万 | 4630 |
| 5000 | 9 | ZACDOCA_CDS | 5,370 万 | 5,370 万 | 4817 |
SAP S4HANA 云生产源系统的示例吞吐量
| 批次大小 | 分片 | OData 服务 | 总行数 | 提取的行数 | 吞吐量(GB/小时) |
|---|---|---|---|---|---|
| 2500 | 40 | TEST_04_UOM_ODATA_CDS/ | 2.01 亿 | 1,000 万 | 25.48 岁 |
| 5000 | 50 | TEST_04_UOM_ODATA_CDS/ | 2.01 亿 | 1,000 万 | 26.78 |
支持服务详情
支持的 SAP 产品和版本
支持的来源包括 SAP S4/HANA 1909 及更高版本、S4/HANA on SAP Cloud,以及任何能够公开 OData 服务的 SAP 应用。
包含用于对 SAP 调用进行负载均衡的自定义 OData 服务的传输文件必须导入 S4/HANA 1909 及更高版本。该服务有助于计算插件可以并行读取的分块(数据分区)数量(请参阅分块数量)。
支持 OData 版本 2。
该插件已使用在 Google Cloud 上部署的 SAP S/4HANA 服务器进行测试。
支持从 SAP OData Catalog Services 提取数据
该插件支持以下 DataSource 类型:
- 交易数据
- 通过 OData 公开的 CDS 视图
主数据
- 特性
- 文本
- 层次结构
SAP 说明
提取前不需要 SAP 说明,但 SAP 系统必须具有 SAP Gateway。如需了解详情,请参阅备注 1560585(此外部网站需要 SAP 登录)。
数据量或记录宽度的限制
对提取的数据量没有定义限制。我们已经测试了在一次调用中提取多达 600 万行,记录宽度为 1 KB。对于云端 SAP S4/HANA,我们已通过一次调用提取多达 1,000 万行,记录宽度为 1 KB。
预期的插件吞吐量
对于根据性能部分中的准则配置的环境,插件每小时可提取大约 38 GB 的数据。实际性能可能会因 Cloud Data Fusion 和 SAP 系统负载或网络流量而异。
增量(更改的数据)提取
不支持增量提取。
错误场景
在运行时,该插件会将日志条目写入 Cloud Data Fusion 数据流水线日志。为方便您识别,这些条目带有 CDF_SAP 前缀。
在设计时,当您验证插件设置时,消息会显示在 Properties 标签页中,并以红色突出显示。
下表列出了一些常见的错误消息
| 消息 ID | 消息 | 推荐执行的操作 |
|---|---|---|
| 无 | 连接类型“ |
输入实际值或宏变量。 |
| 无 | 属性“ |
输入一个非负整数(0 或更大的数,不含小数)或宏变量。 |
| CDF_SAP_ODATA_01505 | 未能准备 Cloud Data Fusion 输出架构。请检查提供的运行时宏值。 | 确保提供的宏值正确无误。 |
| 不适用 | SAP X509 证书“<UI input in GCS Path>”缺失。请确保将所需的 X509 证书上传到您指定的 Google Cloud Storage 存储桶“<GCS bucket name>”。 | 确保提供的 Cloud Storage 路径正确无误。 |
| CDF_SAP_ODATA_01532 | 与 SAP OData 连接问题相关的通用错误代码 无法调用给定的 SAP OData 服务。根本原因:<SAP OData service root cause message> |
请查看消息中显示的根本原因,并采取相应措施。 |
| CDF_SAP_ODATA_01534 | 与 SAP OData 服务错误相关的通用错误代码。 服务验证失败。根本原因: |
请查看消息中显示的根本原因,并采取相应措施。 |
| CDF_SAP_ODATA_01503 | 未能从 <SAP OData service entity name> 中提取可用记录总数。根本原因:<SAP Odata service root cause message> | 请查看消息中显示的根本原因,并采取相应措施。 |
| CDF_SAP_ODATA_01506 | 在 <SAP OData service entity name> 中找不到要提取的记录。请确保提供的实体包含记录。 | 请查看消息中显示的根本原因,并采取相应措施。 |
| CDF_SAP_ODATA_01537 | 无法处理 <SAP OData service entity name> 的记录。根本原因:<SAP OData service root cause message> | 请查看消息中显示的根本原因,并采取相应措施。 |
| CDF_SAP_ODATA_01536 | 无法从 <SAP OData service entity name> 中拉取记录。根本原因:<SAP OData service root cause message> | 请查看消息中显示的根本原因,并采取相应措施。 |
| CDF_SAP_ODATA_01504 | 无法为给定的 OData 服务 <SAP OData service name> 生成编码的元数据字符串。根本原因:<SAP OData service root cause message> | 请查看消息中显示的根本原因,并采取相应措施。 |
| CDF_SAP_ODATA_01533 | 无法对服务 <SAP OData service name> 的给定编码元数据字符串中的元数据进行解码。根本原因:<SAP OData service root cause message> | 请查看消息中显示的根本原因,并采取相应措施。 |
后续步骤
- 详细了解 Cloud Data Fusion。
- 详细了解 SAP on Google Cloud。