このページでは、既存の Dataproc クラスタに対して Cloud Data Fusion でパイプラインを実行する方法について説明します。
デフォルトでは、Cloud Data Fusion はパイプラインごとにエフェメラル クラスタを作成します。パイプライン実行の開始時点でクラスタを作成し、パイプラインの実行が完了した後に削除します。この動作では、必要な場合にのみリソースが作成されるようにすることでコストを抑えられますが、次の状況では、このデフォルトの動作が望ましくない場合があります。
すべてのパイプライン用の新しいクラスタの作成にかかる時間が、ユースケースに適していない場合。
組織でクラスタを集中管理する必要がある場合。たとえば、すべての Dataproc クラスタに特定のポリシーを適用したい場合などです。
このような場合は、次の手順で既存のクラスタに対してパイプラインを実行します。
始める前に
必要なもの:
Cloud Data Fusion インスタンス。
既存の Dataproc クラスタ。
Cloud Data Fusion バージョン 6.2 でパイプラインを実行する場合は、Hadoop 2.x で実行される古い Dataproc イメージ(1.5-debian10 など)を使用するか、Cloud Data Fusion の最新バージョンにアップグレードします。
既存のクラスタに接続する
Cloud Data Fusion バージョン 6.2.1 以降では、新しい Compute Engine プロファイルを作成するときに既存の Dataproc クラスタに接続できます。
インスタンスに移動します:
Google Cloud コンソールで、Cloud Data Fusion のページに移動します。
Cloud Data Fusion Studio でインスタンスを開くには、[インスタンス]、[インスタンスを表示] の順にクリックします。
[System Admin] をクリックします。
[構成] タブをクリックします。
[システム コンピューティング プロファイル] をクリックします。
[Create New Profile] をクリックします。 プロビジョナーのページが開きます。
[既存の Dataproc] をクリックします。
プロファイル、クラスタ、モニタリングの情報を入力します。
[作成] をクリックします。
カスタム プロファイルを使用するようにパイプラインを構成する
インスタンスに移動します:
Google Cloud コンソールで、Cloud Data Fusion のページに移動します。
Cloud Data Fusion Studio でインスタンスを開くには、[インスタンス]、[インスタンスを表示] の順にクリックします。
[Studio] ページでパイプラインに移動します。
[構成] をクリックします。
[Compute config] をクリックします。
作成したプロファイルをクリックします。
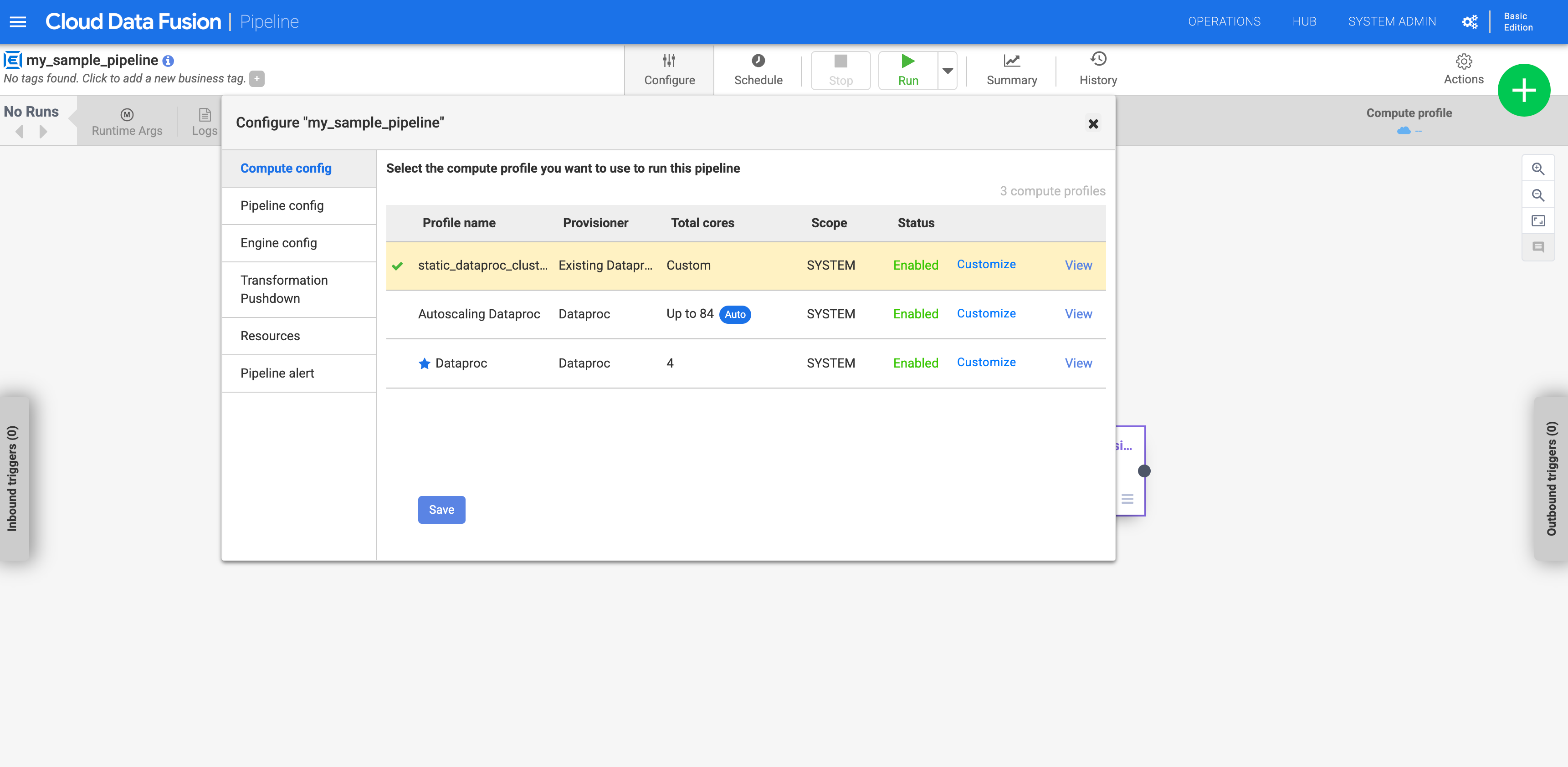
図 1: カスタム プロファイルをクリックする パイプラインを実行します。既存の Dataproc クラスタに対して実行されます。