Cloud Composer 1 | Cloud Composer 2
このページでは、Cloud Composer 環境のモニタリング ダッシュボードにアクセスして使用する方法について説明します。
主要な環境指標のモニタリングに関するチュートリアルについては、主要な指標で環境の健全性とパフォーマンスをモニタリングするをご覧ください。
特定の指標の詳細については、Cloud Monitoring で環境をモニタリングするをご覧ください。
モニタリング ダッシュボードにアクセスする
このモニタリング用ダッシュボードには、環境内の DAG 実行の傾向をモニタリングし、Airflow コンポーネントと Cloud Composer リソースに関する問題を特定するための指標とグラフが用意されています。
環境のモニタリング ダッシュボードにアクセスするには:
Google Cloud コンソールで [環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[Monitoring] タブに移動します。
指標のアラートを設定する
モニタリング カードの隅にあるベルのアイコンをクリックすると、指標のアラートを設定できます。
Monitoring で指標を表示する
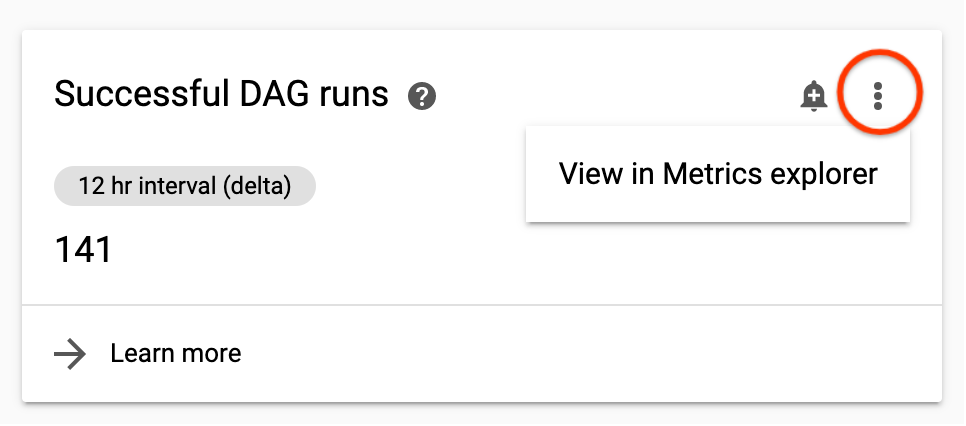
Monitoring で指標を表示すると、指標を詳しく確認できます。
Cloud Composer のモニタリング ダッシュボードから移動するには、指標カードの右上にあるその他アイコンをクリックして、[Metrics Explorer で表示] を選択します。
指標の説明
各 Cloud Composer 環境には独自のモニタリング ダッシュボードがあります。 特定の環境のモニタリング ダッシュボードに表示される指標は、この環境だけの DAG 実行、Airflow コンポーネント、環境の詳細しか追跡しません。たとえば、2 つの環境がある場合、ダッシュボードには両方の環境の指標は集計されません。
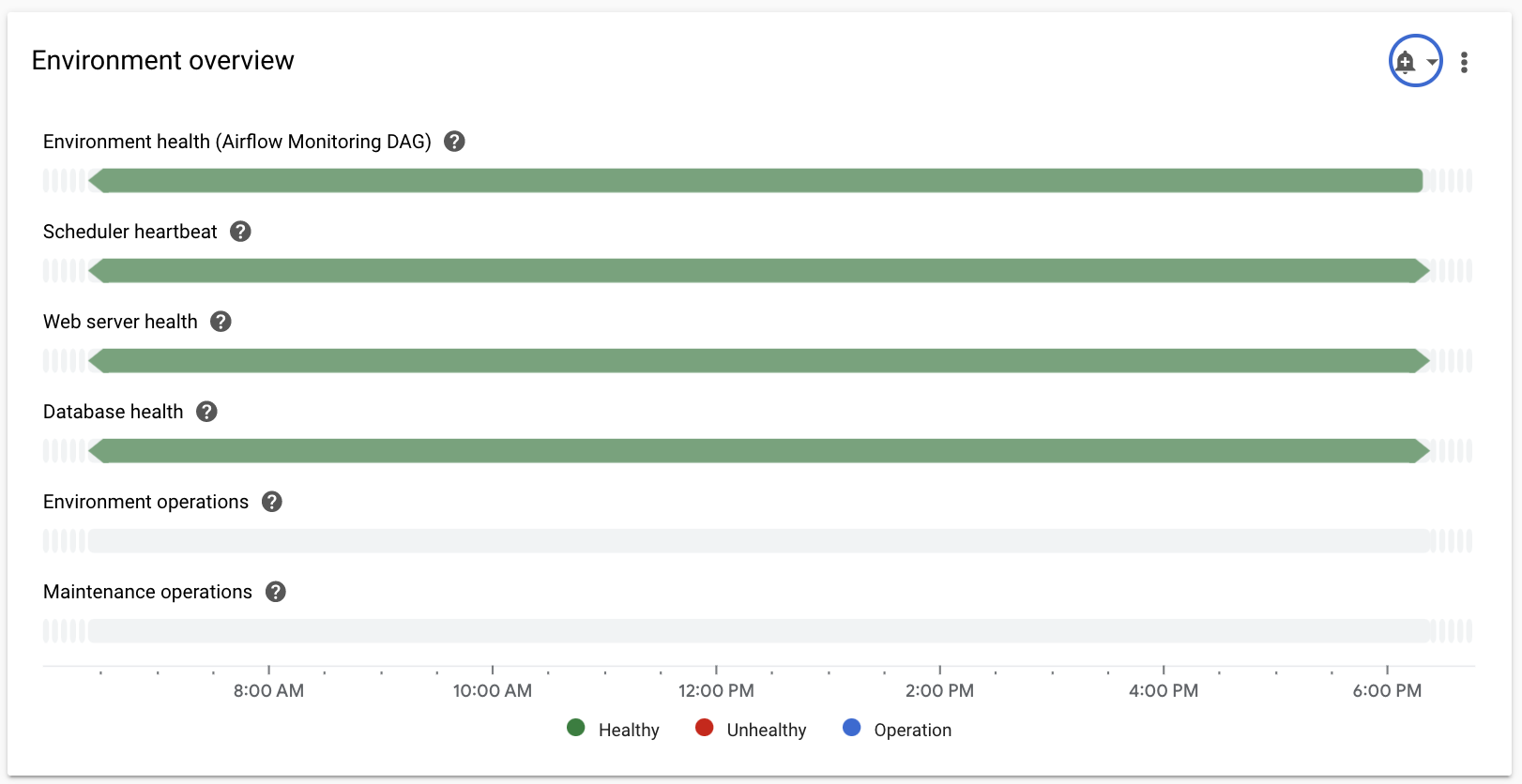
環境の概要
| 環境の指標 | 説明 |
|---|---|
| 環境のヘルス(Airflow Monitoring DAG) | Composer のデプロイの正常性を示すタイムライン。緑色のステータスには、Composer のデプロイのステータスのみが反映されます。これは、すべての Airflow コンポーネントが動作可能であり、DAG を実行できるという意味ではありません。 |
| スケジューラのハートビート | Airflow スケジューラのハートビートを示すタイムライン。Airflow スケジューラの問題を特定するには、赤い領域を確認します。環境に複数のスケジューラがある場合、少なくとも 1 つのスケジューラが応答している限り、ハートビート ステータスは正常です。 |
| ウェブサーバーのヘルス | Airflow ウェブサーバーのステータスを示すタイムライン。このステータスは、Airflow ウェブサーバーから返される HTTP ステータス コードに基づいて生成されます。 |
| データベースのヘルス | Airflow DB をホストする Cloud SQL インスタンスへの接続のステータスを示すタイムライン。 |
| 環境オペレーション | 構成の更新や環境のスナップショットの読み込みなど、環境を変更するオペレーションを示すタイムライン。 |
| メンテナンス オペレーション | 環境のクラスタでメンテナンス オペレーションが行われる期間を示すタイムライン。 |
| 環境の依存関係 | 環境のオペレーションに関するネットワーク到達性チェックと権限チェックのステータスを示すタイムライン。 |
DAG の統計情報
| 環境の指標 | 説明 |
|---|---|
| 成功した DAG 実行 | 選択した期間中に環境内のすべての DAG について成功した実行の合計回数。成功した DAG 実行の数が想定したレベルを下回る場合は、失敗(失敗した DAG 実行を参照)またはスケジューリングの問題を示していることがあります。 |
| 失敗した DAG 実行 失敗したタスク | 選択した期間中に環境内のすべての DAG について失敗した実行の合計回数。 選択した期間に環境内で失敗したタスクの合計数。失敗したタスクが常に DAG 実行の失敗の原因となるわけではありませんが、DAG エラーのトラブルシューティングを行う際に有用なシグナルであることが考えられます。 |
| 完了済みの DAG 実行 | 選択した期間におけるさまざまな間隔での DAG の成功数と失敗数。これにより、DAG 実行に関する一時的な問題を特定し、ワーカー Pod の強制排除などの他のイベントと関連付けることができます。 |
| 完了したタスク | 環境内で完了したタスクの数。成功したタスクと失敗したタスクの内訳が表示されます。 |
| DAG 実行時間の中央値 | DAG 実行時間の中央値。このグラフは、パフォーマンスの問題を特定し、DAG の実行時間に関する傾向を特定する際に有用な可能性があります。 |
| Airflow タスク | 特定の時点において、実行中、キューで待機中、または保留状態のタスクの数。Airflow タスクは Airflow でキューに格納された状態のタスクであり、Celery または Kubernetes Executor のブローカー キューに移動できます。Celery キューに入れられたタスクは、Celery ブローカーのキューに入れられたタスク インスタンスです。 |
| 強制終了したゾンビタスク | 短い時間枠で強制終了されたゾンビタスクの数。ゾンビタスクは、多くの場合、外部での Airflow プロセスの終了によって発生します。Airflow スケジューラは、ゾンビタスクを定期的に強制終了します。それは、このグラフに反映されています。 |
| DAG バッグサイズ | 環境のバケットにデプロイされ、特定の時間に Airflow によって処理される DAG の数。これは、パフォーマンスのボトルネックを分析する際に有用です。たとえば、DAG のデプロイ数が増大すると、過負荷によりパフォーマンスが低下する場合があります。 |
| DAG プロセッサのエラー | DAG ファイルの処理中に発生したエラーとタイムアウト(1 秒あたり)の数。この値は、DAG プロセッサによって報告されるエラーの頻度を示します(失敗した DAG の数とは異なる値です)。 |
| すべての DAG の合計解析時間 | Airflow が環境内のすべての DAG を処理するために必要な合計時間を示すグラフ。解析時間が増大すると、スケジューリングの効率に影響する可能性があります。詳しくは、DAG 解析時間と DAG 実行時間の差をご覧ください。 |
スケジューラの統計情報
| 環境の指標 | 説明 |
|---|---|
| スケジューラのハートビート | 環境の概要をご覧ください。 |
| スケジューラの CPU 使用率の合計 | すべての Airflow スケジューラ Pod で実行されているコンテナによる vCPU コアの合計使用量と、すべてのスケジューラの合計 vCPU 上限。 |
| スケジューラのメモリ使用量の合計 | すべての Airflow スケジューラ Pod で実行されているコンテナによるメモリの合計使用量と、すべてのスケジューラの合計 vCPU 上限。 |
| スケジューラのディスク使用量の合計 | すべての Airflow スケジューラ Pod で実行されているコンテナによるディスク容量の合計使用量と、すべてのスケジューラの合計ディスク容量の上限。 |
| スケジューラ コンテナの再起動 | 個々のスケジューラ コンテナの再起動の総数。 |
| スケジューラ Pod のエビクション | Airflow スケジューラ Pod のエビクションの数。Pod のエビクションは、環境内のクラスタ内の特定の Pod がリソース上限に達すると発生します。 |
ワーカーの統計情報
| 環境の指標 | 説明 |
|---|---|
| ワーカーの合計 CPU 使用率 | すべての Airflow ワーカー Pod で実行されているコンテナによる vCPU コアの合計使用量と、すべてのワーカーの合計 vCPU 上限。 |
| ワーカーの合計メモリ使用量 | すべての Airflow ワーカー Pod で実行されているコンテナによるメモリの合計使用量と、すべてのワーカーの合計 vCPU 上限。 |
| ワーカーの合計ディスク使用量 | すべての Airflow ワーカー Pod で実行されているコンテナによるディスク容量の合計使用量と、すべてのワーカーの合計ディスク容量の上限。 |
| アクティブ ワーカー数 | 環境内の現在のワーカー数。Cloud Composer 2 では、アクティブなワーカーの数は環境によって自動的にスケーリングされます。 |
| ワーカー コンテナの再起動 | 個々のワーカー コンテナが再起動する合計回数。 |
| ワーカーポッドの強制排除 | Airflow ワーカー Pod の強制排除の数。Pod のエビクションは、環境内のクラスタ内の特定の Pod がリソース上限に達すると発生します。Airflow ワーカー Pod が強制排除されると、その Pod で実行されているすべてのタスク インスタンスは中断され、後で Airflow によって失敗としてマークされます。 |
| Airflow タスク | 環境の概要をご覧ください。 |
| Celery ブローカーの公開タイムアウト |
Celery Broker にタスクを公開したときに発生した AirflowTaskTimeout エラーの合計数。この指標は、celery.task_timeout_error Airflow の指標に対応します。 |
| Celery 実行コマンドの失敗 |
Celery タスクのゼロ以外の終了コードの合計数。この指標は、celery.execute_command.failure Airflow の指標に対応します。 |
| システムによって終了したタスク | タスクランナーが SIGKILL で終了したワークフロー タスクの数(ワーカーのメモリやハートビートの問題など)。 |
ウェブサーバーの統計情報
| 環境の指標 | 説明 |
|---|---|
| ウェブサーバーのヘルス | 環境の概要をご覧ください。 |
| ウェブサーバーの CPU 使用率 | すべての Airflow ウェブサーバー インスタンスで実行されているコンテナによる vCPU コアの合計使用量と、すべてのウェブサーバーの合計 vCPU 上限。 |
| ウェブサーバーのメモリ使用量 | すべての Airflow ウェブサーバー インスタンスで実行されているコンテナによるメモリの合計使用量と、すべてのウェブサーバーの合計 vCPU 上限。 |
| ウェブサーバーの合計ディスク使用量 | すべての Airflow ウェブサーバー インスタンスで実行されているコンテナによるディスク容量の合計使用量と、すべてのウェブサーバーの合計ディスク容量の上限。 |
SQL データベースの統計情報
| 環境の指標 | 説明 |
|---|---|
| データベースのヘルス | 環境の概要をご覧ください。 |
| データベースの CPU 使用率 | 環境の Cloud SQL データベース インスタンスによる CPU コアの使用量。 |
| データベースのメモリ使用量 | 環境の Cloud SQL データベース インスタンスによるメモリの合計使用量。 |
| データベースのディスク使用量 | 環境の Cloud SQL データベース インスタンスによるメモリの合計使用量。 |
| データベース接続 | データベースへのアクティブな接続の合計数と合計接続数の上限。 |
| Airflow メタデータ データベースのサイズ | Airflow メタデータ データベースのサイズ。Airflow メタデータ データベースのメンテナンスの詳細については、Airflow データベースをクリーンアップするをご覧ください。 |
DAG 解析時間と DAG 実行時間の差
環境のモニタリング ダッシュボードには、Cloud Composer 環境内のすべての DAG の解析に必要な時間の合計と、DAG の実行にかかる平均時間が表示されます。
DAG の解析と実行のために DAG からタスクのスケジュールを設定するのは次の 2 つのオペレーションで、Airflow スケジューラによって実行されます。
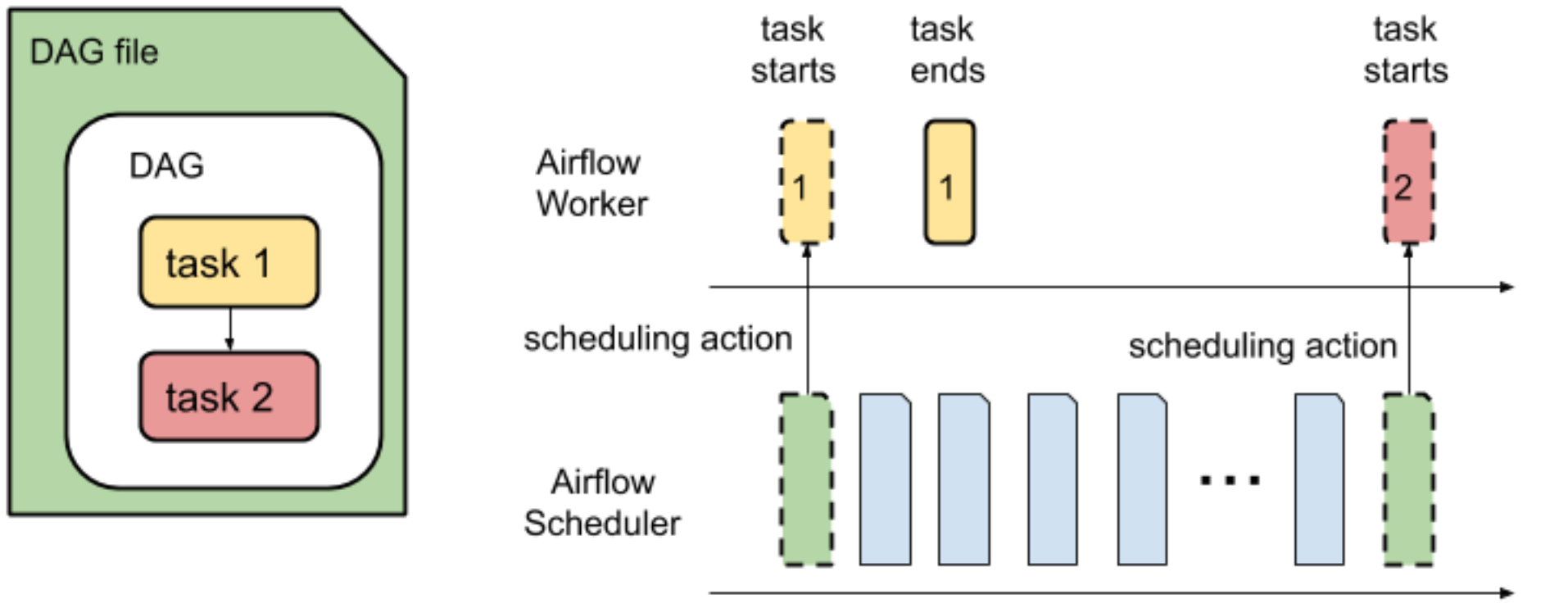
DAG 解析時間は、Airflow Scheduler が DAG ファイルを読み取り、解析するのにかかる時間です。
Airflow スケジューラは、DAG からタスクのスケジュールを設定する前に、DAG ファイルを解析して DAG の構造と定義済みのタスクを検出する必要があります。DAG ファイルの解析後、スケジューラは DAG からタスクのスケジュール設定を開始できます。
DAG 実行時間は、DAG のすべてのタスクが実行する時間の合計です。
DAG から特定の Airflow タスクを実行するのにかかる時間を確認するには、Airflow ウェブ インターフェースで DAG を選択して [Task duration] タブを開きます。このタブには、最新のものから指定した数の DAG 実行のタスク実行時間が表示されます。